 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fourier shapes to probe the geometric world of deep neural networks
Nov 07, 2025



While both shape and texture are fundamental to visual recognition, research on deep neural networks (DNNs) has predominantly focused on the latter, leaving their geometric understanding poorly probed. Here, we show: first, that optimized shapes can act as potent semantic carriers, generating high-confidence classifications from inputs defined purely by their geometry; second, that they are high-fidelity interpretability tools that precisely isolate a model's salient regions; and third, that they constitute a new, generalizable adversarial paradigm capable of deceiving downstream visual tasks. This is achieved through an end-to-end differentiable framework that unifies a powerful Fourier series to parameterize arbitrary shapes, a winding number-based mapping to translate them into the pixel grid required by DNNs, and signal energy constraints that enhance optimization efficiency while ensuring physically plausible shapes. Our work provides a versatile framework for probing the geometric world of DNNs and opens new frontiers for challenging and understanding machine perception.
DINOv2 Driven Gait Representation Learning for Video-Based Visible-Infrared Person Re-identification
Nov 06, 2025Video-based Visible-Infrared person re-identification (VVI-ReID) aims to retrieve the same pedestrian across visible and infrared modalities from video sequences. Existing methods tend to exploit modality-invariant visual features but largely overlook gait features, which are not only modality-invariant but also rich in temporal dynamics, thus limiting their ability to model the spatiotemporal consistency essential for cross-modal video matching. To address these challenges, we propose a DINOv2-Driven Gait Representation Learning (DinoGRL) framework that leverages the rich visual priors of DINOv2 to learn gait features complementary to appearance cues, facilitating robust sequence-level representations for cross-modal retrieval. Specifically, we introduce a Semantic-Aware Silhouette and Gait Learning (SASGL) model, which generates and enhances silhouette representations with general-purpose semantic priors from DINOv2 and jointly optimizes them with the ReID objective to achieve semantically enriched and task-adaptive gait feature learning. Furthermore, we develop a Progressive Bidirectional Multi-Granularity Enhancement (PBMGE) module, which progressively refines feature representations by enabling bidirectional interactions between gait and appearance streams across multiple spatial granularities, fully leveraging their complementarity to enhance global representations with rich local details and produce highly discriminative features. Extensive experiments on HITSZ-VCM and BUPT datasets demonstrate the superiority of our approach, significantly outperforming existing state-of-the-art methods.
Generating Surface for Text-to-3D using 2D Gaussian Splatting
Oct 08, 2025Recent advancements in Text-to-3D modeling have shown significant potential for the creation of 3D content. However, due to the complex geometric shapes of objects in the natural world, generating 3D content remains a challenging task. Current methods either leverage 2D diffusion priors to recover 3D geometry, or train the model directly based on specific 3D representations. In this paper, we propose a novel method named DirectGaussian, which focuses on generating the surfaces of 3D objects represented by surfels. In DirectGaussian, we utilize conditional text generation models and the surface of a 3D object is rendered by 2D Gaussian splatting with multi-view normal and texture priors. For multi-view geometric consistency problems, DirectGaussian incorporates curvature constraints on the generated surface during optimization process. Through extensive experiments, we demonstrate that our framework is capable of achieving diverse and high-fidelity 3D content creation.
DHG-Bench: A Comprehensive Benchmark on Deep Hypergraph Learning
Aug 17, 2025Although conventional deep graph models have achieved great success in relational learning, their focus on pairwise relationships limits their capacity to learn pervasive higher-order interactions in real-world complex systems, which can be naturally modeled as hypergraphs. To tackle this, hypergraph neural networks (HNNs), the dominant approach in deep hypergraph learning (DHGL), has garnered substantial attention in recent years. Despite the proposal of numerous HNN methods, there is no comprehensive benchmark for HNNs, which creates a great obstacle to understanding the progress of DHGL in several aspects: (i) insufficient coverage of datasets, algorithms, and tasks; (ii) a narrow evaluation of algorithm performance; and (iii) inconsistent dataset usage, preprocessing, and experimental setups that hinder comparability. To fill the gap, we introduce DHG-Bench, the first comprehensive benchmark for DHGL. Specifically, DHG-Bench integrates 20 diverse datasets spanning node-, edge-, and graph-level tasks, along with 16 state-of-the-art HNN algorithms, under consistent data processing and experimental protocols. Our benchmark systematically investigates the characteristics of HNNs in terms of four dimensions: effectiveness, efficiency, robustness, and fairness. Further, to facilitate reproducible research, we have developed an easy-to-use library for training and evaluating different HNN methods. Extensive experiments conducted with DHG-Bench reveal both the strengths and inherent limitations of existing algorithms, offering valuable insights and directions for future research. The code is publicly available at: https://github.com/Coco-Hut/DHG-Bench.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
HiProbe-VAD: Video Anomaly Detection via Hidden States Probing in Tuning-Free Multimodal LLMs
Jul 23, 2025



Video Anomaly Detection (VAD) aims to identify and locate deviations from normal patterns in video sequences. Traditional methods often struggle with substantial computational demands and a reliance on extensive labeled datasets, thereby restricting their practical applicability. To address these constraints, we propose HiProbe-VAD, a novel framework that leverages pre-trained Multimodal Large Language Models (MLLMs) for VAD without requiring fine-tuning. In this paper, we discover that the intermediate hidden states of MLLMs contain information-rich representations, exhibiting higher sensitivity and linear separability for anomalies compared to the output layer. To capitalize on this, we propose a Dynamic Layer Saliency Probing (DLSP) mechanism that intelligently identifies and extracts the most informative hidden states from the optimal intermediate layer during the MLLMs reasoning. Then a lightweight anomaly scorer and temporal localization module efficiently detects anomalies using these extracted hidden states and finally generate explanations. Experiments on the UCF-Crime and XD-Violence datasets demonstrate that HiProbe-VAD outperforms existing training-free and most traditional approaches. Furthermore, our framework exhibits remarkable cross-model generalization capabilities in different MLLMs without any tuning, unlocking the potential of pre-trained MLLMs for video anomaly detection and paving the way for more practical and scalable solutions.
Dual Prompting Image Restoration with Diffusion Transformers
Apr 24, 2025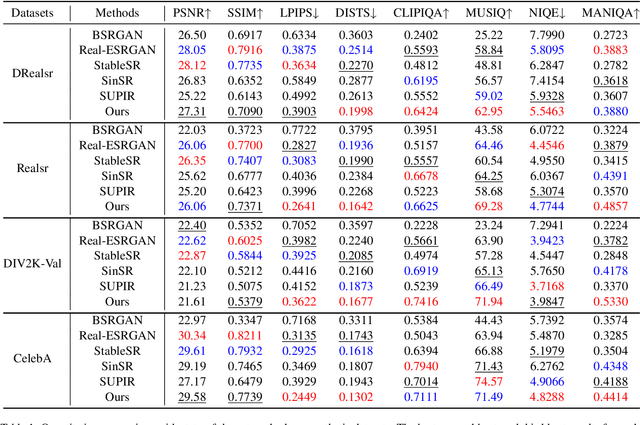
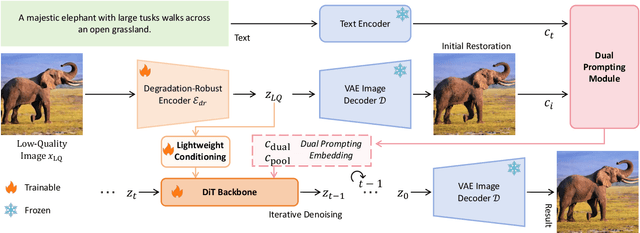
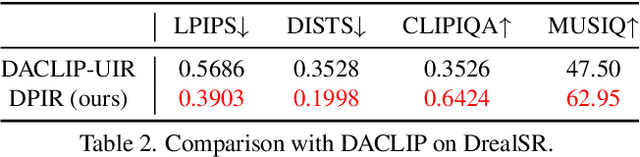
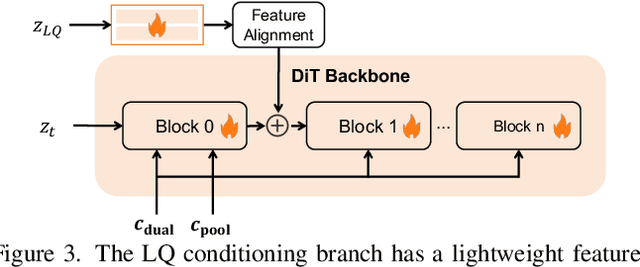
Recent state-of-the-art image restoration methods mostly adopt latent diffusion models with U-Net backbones, yet still facing challenges in achieving high-quality restoration due to their limited capabilities. Diffusion transformers (DiTs), like SD3, are emerging as a promising alternative because of their better quality with scalability. In this paper, we introduce DPIR (Dual Prompting Image Restoration), a novel image restoration method that effectivly extracts conditional information of low-quality images from multiple perspectives. Specifically, DPIR consits of two branches: a low-quality image conditioning branch and a dual prompting control branch. The first branch utilizes a lightweight module to incorporate image priors into the DiT with high efficiency. More importantly, we believe that in image restoration, textual description alone cannot fully capture its rich visual characteristics. Therefore, a dual prompting module is designed to provide DiT with additional visual cues, capturing both global context and local appearance. The extracted global-local visual prompts as extra conditional control, alongside textual prompts to form dual prompts, greatly enhance the quality of the restoration. Extensive experimental results demonstrate that DPIR delivers superior image restoration performance.
Dependency Structure Augmented Contextual Scoping Framework for Multimodal Aspect-Based Sentiment Analysis
Apr 15, 2025Multimodal Aspect-Based Sentiment Analysis (MABSA) seeks to extract fine-grained information from image-text pairs to identify aspect terms and determine their sentiment polarity. However, existing approaches often fall short in simultaneously addressing three core challenges: Sentiment Cue Perception (SCP), Multimodal Information Misalignment (MIM), and Semantic Noise Elimination (SNE). To overcome these limitations, we propose DASCO (\textbf{D}ependency Structure \textbf{A}ugmented \textbf{Sco}ping Framework), a fine-grained scope-oriented framework that enhances aspect-level sentiment reasoning by leveraging dependency parsing trees. First, we designed a multi-task pretraining strategy for MABSA on our base model, combining aspect-oriented enhancement, image-text matching, and aspect-level sentiment-sensitive cognition. This improved the model's perception of aspect terms and sentiment cues while achieving effective image-text alignment, addressing key challenges like SCP and MIM. Furthermore, we incorporate dependency trees as syntactic branch combining with semantic branch, guiding the model to selectively attend to critical contextual elements within a target-specific scope while effectively filtering out irrelevant noise for addressing SNE problem. Extensive experiments on two benchmark datasets across three subtasks demonstrate that DASCO achieves state-of-the-art performance in MABSA, with notable gains in JMASA (+3.1\% F1 and +5.4\% precision on Twitter2015).
D3-Guard: Acoustic-based Drowsy Driving Detection Using Smartphones
Mar 30, 2025



Since the number of cars has grown rapidly in recent years, driving safety draws more and more public attention. Drowsy driving is one of the biggest threatens to driving safety. Therefore, a simple but robust system that can detect drowsy driving with commercial off-the-shelf devices (such as smartphones) is very necessary. With this motivation, we explore the feasibility of purely using acoustic sensors embedded in smartphones to detect drowsy driving. We first study characteristics of drowsy driving, and find some unique patterns of Doppler shift caused by three typical drowsy behaviors, i.e. nodding, yawning and operating steering wheel. We then validate our important findings through empirical analysis of the driving data collected from real driving environments. We further propose a real-time Drowsy Driving Detection system (D3-Guard) based on audio devices embedded in smartphones. In order to improve the performance of our system, we adopt an effective feature extraction method based on undersampling technique and FFT, and carefully design a high-accuracy detector based on LSTM networks for the early detection of drowsy driving. Through extensive experiments with 5 volunteer drivers in real driving environments, our system can distinguish drowsy driving actions with an average total accuracy of 93.31% in real-time. Over 80% drowsy driving actions can be detected within first 70% of action duration.
HearSmoking: Smoking Detection in Driving Environment via Acoustic Sensing on Smartphones
Mar 30, 2025



Driving safety has drawn much public attention in recent years due to the fast-growing number of cars. Smoking is one of the threats to driving safety but is often ignored by drivers. Existing works on smoking detection either work in contact manner or need additional devices. This motivates us to explore the practicability of using smartphones to detect smoking events in driving environment. In this paper, we propose a cigarette smoking detection system, named HearSmoking, which only uses acoustic sensors on smartphones to improve driving safety. After investigating typical smoking habits of drivers, including hand movement and chest fluctuation, we design an acoustic signal to be emitted by the speaker and received by the microphone. We calculate Relative Correlation Coefficient of received signals to obtain movement patterns of hands and chest. The processed data is sent into a trained Convolutional Neural Network for classification of hand movement. We also design a method to detect respiration at the same time. To improve system performance, we further analyse the periodicity of the composite smoking motion. Through extensive experiments in real driving environments, HearSmoking detects smoking events with an average total accuracy of 93.44 percent in real-time.