 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Foundation VLM Robustness to Missing Modality: Scalable Diffusion for Bi-directional Feature Restoration
Feb 03, 2026Vision Language Models (VLMs) typically assume complete modality input during inference. However, their effectiveness drops sharply when certain modalities are unavailable or incomplete. Current research primarily faces two dilemmas: Prompt-based methods struggle to restore missing yet indispensable features and impair generalization of VLMs. Imputation-based approaches, lacking effective guidance, are prone to generating semantically irrelevant noise. Restoring precise semantics while sustaining VLM generalization remains challenging. Therefore, we propose a general missing modality restoration strategy in this paper. We introduce an enhanced diffusion model as a pluggable mid-stage training module to effectively restore missing features. Our strategy introduces two key innovations: (I) Dynamic Modality Gating, which adaptively leverages conditional features to steer the generation of semantically consistent features; (II) Cross-Modal Mutual Learning mechanism, which bridges the semantic spaces of dual encoders to achieve bidirectional alignment. Zero-shot evaluations across benchmark datasets demonstrate that our approach outperforms existing baseline methods. Extensive experiments and ablation studies confirm our model as a robust and scalable extension for VLMs in missing modality scenarios, ensuring reliability across diverse missing rates and environments. Our code and models will be publicly available.
HeadHunt-VAD: Hunting Robust Anomaly-Sensitive Heads in MLLM for Tuning-Free Video Anomaly Detection
Dec 23, 2025



Video Anomaly Detection (VAD) aims to locate events that deviate from normal patterns in videos. Traditional approaches often rely on extensive labeled data and incur high computational costs. Recent tuning-free methods based on Multimodal Large Language Models (MLLMs) offer a promising alternative by leveraging their rich world knowledge. However, these methods typically rely on textual outputs, which introduces information loss, exhibits normalcy bias, and suffers from prompt sensitivity, making them insufficient for capturing subtle anomalous cues. To address these constraints, we propose HeadHunt-VAD, a novel tuning-free VAD paradigm that bypasses textual generation by directly hunting robust anomaly-sensitive internal attention heads within the frozen MLLM. Central to our method is a Robust Head Identification module that systematically evaluates all attention heads using a multi-criteria analysis of saliency and stability, identifying a sparse subset of heads that are consistently discriminative across diverse prompts. Features from these expert heads are then fed into a lightweight anomaly scorer and a temporal locator, enabling efficient and accurate anomaly detection with interpretable outputs. Extensive experiments show that HeadHunt-VAD achieves state-of-the-art performance among tuning-free methods on two major VAD benchmarks while maintaining high efficiency, validating head-level probing in MLLMs as a powerful and practical solution for real-world anomaly detection.
What Your Features Reveal: Data-Efficient Black-Box Feature Inversion Attack for Split DNNs
Nov 19, 2025Split DNNs enable edge devices by offloading intensive computation to a cloud server, but this paradigm exposes privacy vulnerabilities, as the intermediate features can be exploited to reconstruct the private inputs via Feature Inversion Attack (FIA). Existing FIA methods often produce limited reconstruction quality, making it difficult to assess the true extent of privacy leakage. To reveal the privacy risk of the leaked features, we introduce FIA-Flow, a black-box FIA framework that achieves high-fidelity image reconstruction from intermediate features. To exploit the semantic information within intermediate features, we design a Latent Feature Space Alignment Module (LFSAM) to bridge the semantic gap between the intermediate feature space and the latent space. Furthermore, to rectify distributional mismatch, we develop Deterministic Inversion Flow Matching (DIFM), which projects off-manifold features onto the target manifold with one-step inference. This decoupled design simplifies learning and enables effective training with few image-feature pairs. To quantify privacy leakage from a human perspective, we also propose two metrics based on a large vision-language model. Experiments show that FIA-Flow achieves more faithful and semantically aligned feature inversion across various models (AlexNet, ResNet, Swin Transformer, DINO, and YOLO11) and layers, revealing a more severe privacy threat in Split DNNs than previously recognized.
Invisible Triggers, Visible Threats! Road-Style Adversarial Creation Attack for Visual 3D Detection in Autonomous Driving
Nov 14, 2025Modern autonomous driving (AD) systems leverage 3D object detection to perceive foreground objects in 3D environments for subsequent prediction and planning. Visual 3D detection based on RGB cameras provides a cost-effective solution compared to the LiDAR paradigm. While achieving promising detection accuracy, current deep neural network-based models remain highly susceptible to adversarial examples. The underlying safety concerns motivate us to investigate realistic adversarial attacks in AD scenarios. Previous work has demonstrated the feasibility of placing adversarial posters on the road surface to induce hallucinations in the detector. However, the unnatural appearance of the posters makes them easily noticeable by humans, and their fixed content can be readily targeted and defended. To address these limitations, we propose the AdvRoad to generate diverse road-style adversarial posters. The adversaries have naturalistic appearances resembling the road surface while compromising the detector to perceive non-existent objects at the attack locations. We employ a two-stage approach, termed Road-Style Adversary Generation and Scenario-Associated Adaptation, to maximize the attack effectiveness on the input scene while ensuring the natural appearance of the poster, allowing the attack to be carried out stealthily without drawing human attention. Extensive experiments show that AdvRoad generalizes well to different detectors, scenes, and spoofing locations. Moreover, physical attacks further demonstrate the practical threats in real-world environments.
Learning Fourier shapes to probe the geometric world of deep neural networks
Nov 07, 2025



While both shape and texture are fundamental to visual recognition, research on deep neural networks (DNNs) has predominantly focused on the latter, leaving their geometric understanding poorly probed. Here, we show: first, that optimized shapes can act as potent semantic carriers, generating high-confidence classifications from inputs defined purely by their geometry; second, that they are high-fidelity interpretability tools that precisely isolate a model's salient regions; and third, that they constitute a new, generalizable adversarial paradigm capable of deceiving downstream visual tasks. This is achieved through an end-to-end differentiable framework that unifies a powerful Fourier series to parameterize arbitrary shapes, a winding number-based mapping to translate them into the pixel grid required by DNNs, and signal energy constraints that enhance optimization efficiency while ensuring physically plausible shapes. Our work provides a versatile framework for probing the geometric world of DNNs and opens new frontiers for challenging and understanding machine perception.
SAM-UNet:Enhancing Zero-Shot Segmentation of SAM for Universal Medical Images
Aug 19, 2024



Segment Anything Model (SAM) has demonstrated impressive performance on a wide range of natural image segmentation tasks. However, its performance significantly deteriorates when directly applied to medical domain, due to the remarkable differences between natural images and medical images. Some researchers have attempted to train SAM on large scale medical datasets. However, poor zero-shot performance is observed from the experimental results. In this context, inspired by the superior performance of U-Net-like models in medical image segmentation, we propose SAMUNet, a new foundation model which incorporates U-Net to the original SAM, to fully leverage the powerful contextual modeling ability of convolutions. To be specific, we parallel a convolutional branch in the image encoder, which is trained independently with the vision Transformer branch frozen. Additionally, we employ multi-scale fusion in the mask decoder, to facilitate accurate segmentation of objects with different scales. We train SAM-UNet on SA-Med2D-16M, the largest 2-dimensional medical image segmentation dataset to date, yielding a universal pretrained model for medical images. Extensive experiments are conducted to evaluate the performance of the model, and state-of-the-art result is achieved, with a dice similarity coefficient score of 0.883 on SA-Med2D-16M dataset. Specifically, in zero-shot segmentation experiments, our model not only significantly outperforms previous large medical SAM models across all modalities, but also substantially mitigates the performance degradation seen on unseen modalities. It should be highlighted that SAM-UNet is an efficient and extensible foundation model, which can be further fine-tuned for other downstream tasks in medical community. The code is available at https://github.com/Hhankyangg/sam-unet.
Dual-branch PolSAR Image Classification Based on GraphMAE and Local Feature Extraction
Aug 08, 2024


The annotation of polarimetric synthetic aperture radar (PolSAR) images is a labor-intensive and time-consuming process. Therefore, classifying PolSAR images with limited labels is a challenging task in remote sensing domain. In recent years, self-supervised learning approaches have proven effective in PolSAR image classification with sparse labels. However, we observe a lack of research on generative selfsupervised learning in the studied task. Motivated by this, we propose a dual-branch classification model based on generative self-supervised learning in this paper. The first branch is a superpixel-branch, which learns superpixel-level polarimetric representations using a generative self-supervised graph masked autoencoder. To acquire finer classification results, a convolutional neural networks-based pixel-branch is further incorporated to learn pixel-level features. Classification with fused dual-branch features is finally performed to obtain the predictions. Experimental results on the benchmark Flevoland dataset demonstrate that our approach yields promising classification results.
PolSAR Image Classification Based on Robust Low-Rank Feature Extraction and Markov Random Field
Sep 13, 2020
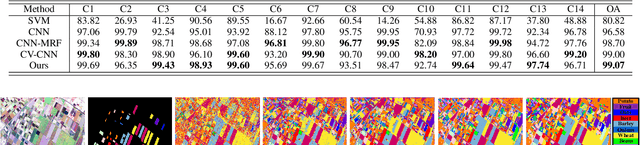
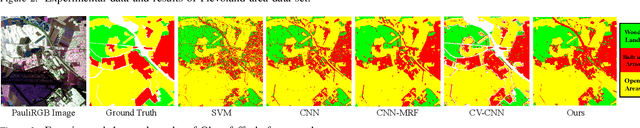
Polarimetric synthetic aperture radar (PolSAR) image classification has been investigated vigorously in various remote sensing applications. However, it is still a challenging task nowadays. One significant barrier lies in the speckle effect embedded in the PolSAR imaging process, which greatly degrades the quality of the images and further complicates the classification. To this end, we present a novel PolSAR image classification method, which removes speckle noise via low-rank (LR) feature extraction and enforces smoothness priors via Markov random field (MRF). Specifically, we employ the mixture of Gaussian-based robust LR matrix factorization to simultaneously extract discriminative features and remove complex noises. Then, a classification map is obtained by applying convolutional neural network with data augmentation on the extracted features, where local consistency is implicitly involved, and the insufficient label issue is alleviated. Finally, we refine the classification map by MRF to enforce contextual smoothness. We conduct experiments on two benchmark PolSAR datasets. Experimental results indicate that the proposed method achieves promising classification performance and preferable spatial consistency.
Polarimetric SAR Image Semantic Segmentation with 3D Discrete Wavelet Transform and Markov Random Field
Aug 05, 2020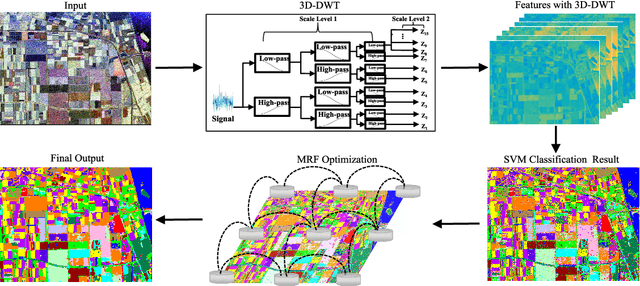

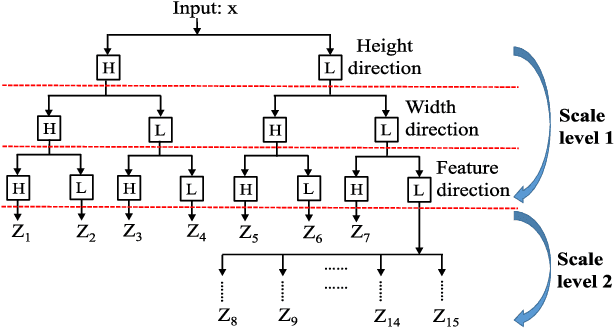

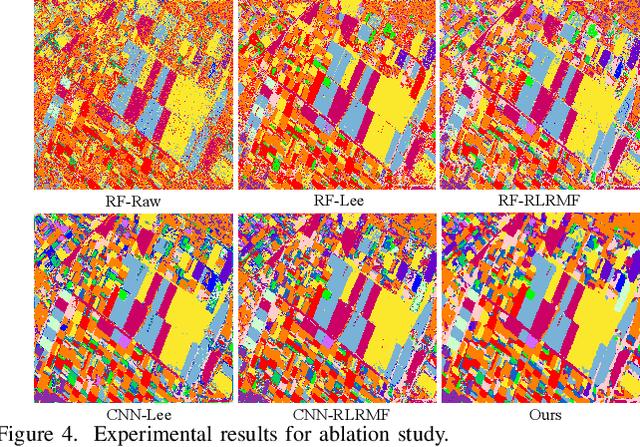
Polarimetric synthetic aperture radar (PolSAR) image segmentation is currently of great importance in image processing for remote sensing applications. However, it is a challenging task due to two main reasons. Firstly, the label information is difficult to acquire due to high annotation costs. Secondly, the speckle effect embedded in the PolSAR imaging process remarkably degrades the segmentation performance. To address these two issues, we present a contextual PolSAR image semantic segmentation method in this paper.With a newly defined channelwise consistent feature set as input, the three-dimensional discrete wavelet transform (3D-DWT) technique is employed to extract discriminative multi-scale features that are robust to speckle noise. Then Markov random field (MRF) is further applied to enforce label smoothness spatially during segmentation. By simultaneously utilizing 3D-DWT features and MRF priors for the first time, contextual information is fully integrated during the segmentation to ensure accurate and smooth segmentation. To demonstrate the effectiveness of the proposed method, we conduct extensive experiments on three real benchmark PolSAR image data sets. Experimental results indicate that the proposed method achieves promising segmentation accuracy and preferable spatial consistency using a minimal number of labeled pixels.