 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotCrop$^3$: Cropping Human-Centric Images into Cinematic Triple-Shot Compositions
Jun 04, 2026Prior work on aesthetic composition typically produces a single aesthetically pleasing crop, overlooking the narrative value of composing multiple shots from one scene. In practice, multi-shot composition is critical for downstream creative workflows: commercial posters often require multiple crops with different emphases (e.g., context, subject, and emotion/product details) to present key story beats. Therefore, we propose \textbf{Triple-Shot Compositions (TSC)}, a composition task that generates a three-shot set -- establishing, medium, and close-up -- from a single human-centric image, each paired with a brief shot description to support visual narration. To learn TSC with limited expert annotations, we introduce \textbf{ShotCrop} which undergoes a three-stage training process: it first applies Chain-of-Thought supervised fine-tuning to establish basic reasoning and aesthetic shot-cropping skills, then performs semi-supervised fine-tuning with high-confidence pseudo labels to further enhance aesthetic capability, and is finally optimized with Group Relative Policy Optimization for \textbf{ShotCrop} (GRPO-S) using a composite reward tailored for it. Specifically, our pseudo-labeling strategy combines MLLM-based scoring, aesthetic assessment, and CLIP similarity to retain high-confidence training signals. In addition, we present TSC-Bench, a benchmark of 1.2k expert-annotated test cases. Notably, ShotCrop achieves an average improvement of \textbf{2.82} times over GPT-5 in shot localization accuracy.
Dual Prompting Image Restoration with Diffusion Transformers
Apr 24, 2025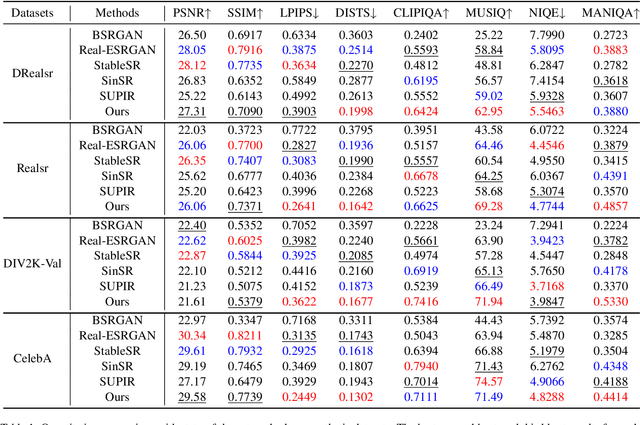
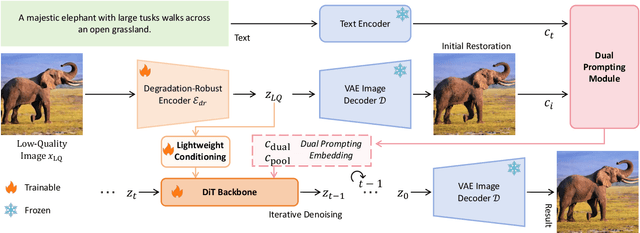
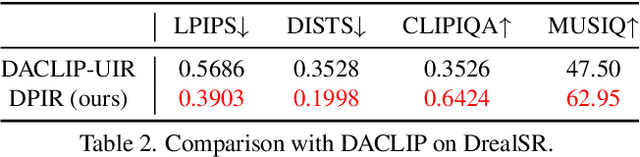
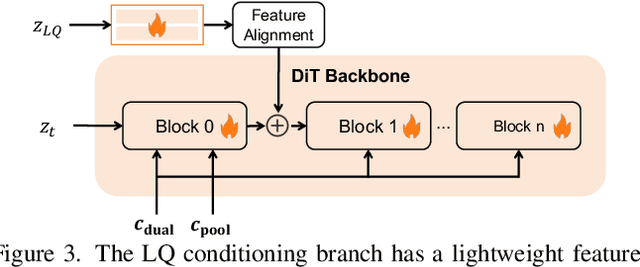
Recent state-of-the-art image restoration methods mostly adopt latent diffusion models with U-Net backbones, yet still facing challenges in achieving high-quality restoration due to their limited capabilities. Diffusion transformers (DiTs), like SD3, are emerging as a promising alternative because of their better quality with scalability. In this paper, we introduce DPIR (Dual Prompting Image Restoration), a novel image restoration method that effectivly extracts conditional information of low-quality images from multiple perspectives. Specifically, DPIR consits of two branches: a low-quality image conditioning branch and a dual prompting control branch. The first branch utilizes a lightweight module to incorporate image priors into the DiT with high efficiency. More importantly, we believe that in image restoration, textual description alone cannot fully capture its rich visual characteristics. Therefore, a dual prompting module is designed to provide DiT with additional visual cues, capturing both global context and local appearance. The extracted global-local visual prompts as extra conditional control, alongside textual prompts to form dual prompts, greatly enhance the quality of the restoration. Extensive experimental results demonstrate that DPIR delivers superior image restoration performance.
Patch is Enough: Naturalistic Adversarial Patch against Vision-Language Pre-training Models
Oct 07, 2024



Visual language pre-training (VLP) models have demonstrated significant success across various domains, yet they remain vulnerable to adversarial attacks. Addressing these adversarial vulnerabilities is crucial for enhancing security in multimodal learning. Traditionally, adversarial methods targeting VLP models involve simultaneously perturbing images and text. However, this approach faces notable challenges: first, adversarial perturbations often fail to translate effectively into real-world scenarios; second, direct modifications to the text are conspicuously visible. To overcome these limitations, we propose a novel strategy that exclusively employs image patches for attacks, thus preserving the integrity of the original text. Our method leverages prior knowledge from diffusion models to enhance the authenticity and naturalness of the perturbations. Moreover, to optimize patch placement and improve the efficacy of our attacks, we utilize the cross-attention mechanism, which encapsulates intermodal interactions by generating attention maps to guide strategic patch placements. Comprehensive experiments conducted in a white-box setting for image-to-text scenarios reveal that our proposed method significantly outperforms existing techniques, achieving a 100% attack success rate. Additionally, it demonstrates commendable performance in transfer tasks involving text-to-image configurations.
Environmental Matching Attack Against Unmanned Aerial Vehicles Object Detection
May 13, 2024Object detection techniques for Unmanned Aerial Vehicles (UAVs) rely on Deep Neural Networks (DNNs), which are vulnerable to adversarial attacks. Nonetheless, adversarial patches generated by existing algorithms in the UAV domain pay very little attention to the naturalness of adversarial patches. Moreover, imposing constraints directly on adversarial patches makes it difficult to generate patches that appear natural to the human eye while ensuring a high attack success rate. We notice that patches are natural looking when their overall color is consistent with the environment. Therefore, we propose a new method named Environmental Matching Attack(EMA) to address the issue of optimizing the adversarial patch under the constraints of color. To the best of our knowledge, this paper is the first to consider natural patches in the domain of UAVs. The EMA method exploits strong prior knowledge of a pretrained stable diffusion to guide the optimization direction of the adversarial patch, where the text guidance can restrict the color of the patch. To better match the environment, the contrast and brightness of the patch are appropriately adjusted. Instead of optimizing the adversarial patch itself, we optimize an adversarial perturbation patch which initializes to zero so that the model can better trade off attacking performance and naturalness. Experiments conducted on the DroneVehicle and Carpk datasets have shown that our work can reach nearly the same attack performance in the digital attack(no greater than 2 in mAP$\%$), surpass the baseline method in the physical specific scenarios, and exhibit a significant advantage in terms of naturalness in visualization and color difference with the environment.