 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesthetic Image Captioning with Saliency Enhanced MLLMs
Sep 04, 2025Aesthetic Image Captioning (AIC) aims to generate textual descriptions of image aesthetics, becoming a key research direction in the field of computational aesthetics. In recent years, pretrained Multimodal Large Language Models (MLLMs) have advanced rapidly, leading to a significant increase in image aesthetics research that integrates both visual and textual modalities. However, most existing studies on image aesthetics primarily focus on predicting aesthetic ratings and have shown limited application in AIC. Existing AIC works leveraging MLLMs predominantly rely on fine-tuning methods without specifically adapting MLLMs to focus on target aesthetic content. To address this limitation, we propose the Aesthetic Saliency Enhanced Multimodal Large Language Model (ASE-MLLM), an end-to-end framework that explicitly incorporates aesthetic saliency into MLLMs. Within this framework, we introduce the Image Aesthetic Saliency Module (IASM), which efficiently and effectively extracts aesthetic saliency features from images. Additionally, we design IAS-ViT as the image encoder for MLLMs, this module fuses aesthetic saliency features with original image features via a cross-attention mechanism. To the best of our knowledge, ASE-MLLM is the first framework to integrate image aesthetic saliency into MLLMs specifically for AIC tasks. Extensive experiments demonstrated that our approach significantly outperformed traditional methods and generic MLLMs on current mainstream AIC benchmarks, achieving state-of-the-art (SOTA) performance.
AinnoSeg: Panoramic Segmentation with High Perfomance
Jul 21, 2020
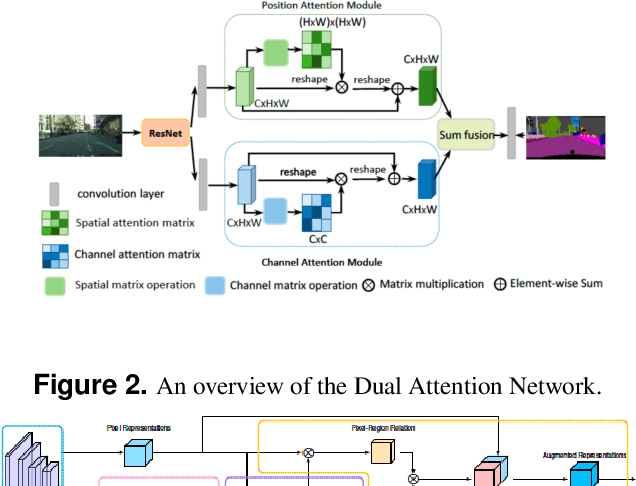

Panoramic segmentation is a scene where image segmentation tasks is more difficult. With the development of CNN networks, panoramic segmentation tasks have been sufficiently developed.However, the current panoramic segmentation algorithms are more concerned with context semantics, but the details of image are not processed enough. Moreover, they cannot solve the problems which contains the accuracy of occluded object segmentation,little object segmentation,boundary pixel in object segmentation etc. Aiming to address these issues, this paper presents some useful tricks. (a) By changing the basic segmentation model, the model can take into account the large objects and the boundary pixel classification of image details. (b) Modify the loss function so that it can take into account the boundary pixels of multiple objects in the image. (c) Use a semi-supervised approach to regain control of the training process. (d) Using multi-scale training and reasoning. All these operations named AinnoSeg, AinnoSeg can achieve state-of-art performance on the well-known dataset ADE20K.