 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Making Real Progress in Simulated Environments? Measuring the Sim2Real Gap in Embodied Visual Navigation
Dec 13, 2019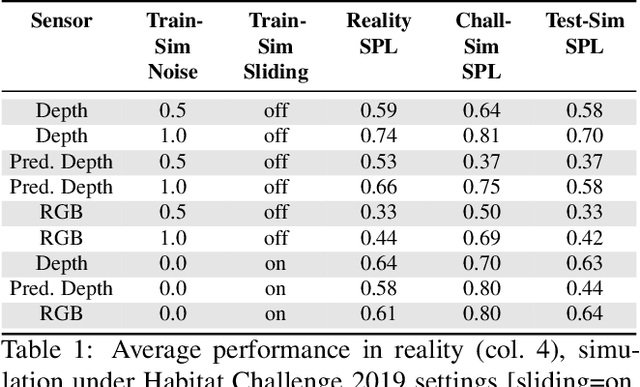

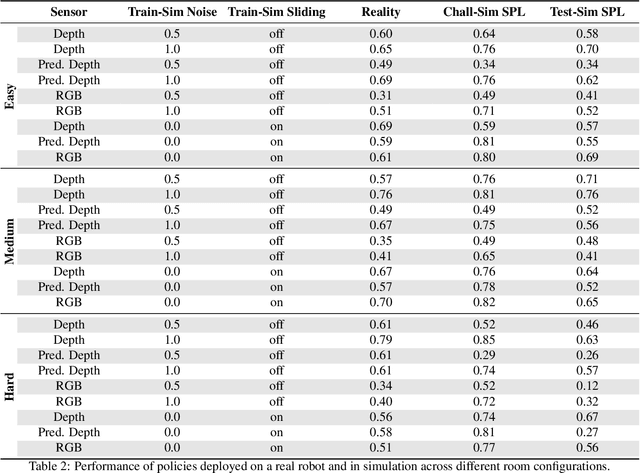

Does progress in simulation translate to progress in robotics? Specifically, if method A outperforms method B in simulation, how likely is the trend to hold in reality on a robot? We examine this question for embodied (PointGoal) navigation, developing engineering tools and a research paradigm for evaluating a simulator by its sim2real predictivity, revealing surprising findings about prior work. First, we develop Habitat-PyRobot Bridge (HaPy), a library for seamless execution of identical code on a simulated agent and a physical robot. Habitat-to-Locobot transfer with HaPy involves just one line change in config, essentially treating reality as just another simulator! Second, we investigate sim2real predictivity of Habitat-Sim for PointGoal navigation. We 3D-scan a physical lab space to create a virtualized replica, and run parallel tests of 9 different models in reality and simulation. We present a new metric called Sim-vs-Real Correlation Coefficient (SRCC) to quantify sim2real predictivity. Our analysis reveals several important findings. We find that SRCC for Habitat as used for the CVPR19 challenge is low (0.18 for the success metric), which suggests that performance improvements for this simulator-based challenge would not transfer well to a physical robot. We find that this gap is largely due to AI agents learning to 'cheat' by exploiting simulator imperfections: specifically, the way Habitat allows for 'sliding' along walls on collision. Essentially, the virtual robot is capable of cutting corners, leading to unrealistic shortcuts through non-navigable spaces. Naturally, such exploits do not work in the real world where the robot stops on contact with walls. Our experiments show that it is possible to optimize simulation parameters to enable robots trained in imperfect simulators to generalize learned skills to reality (e.g. improving $SRCC_{Succ}$ from 0.18 to 0.844).
Decentralized Distributed PPO: Solving PointGoal Navigation
Nov 01, 2019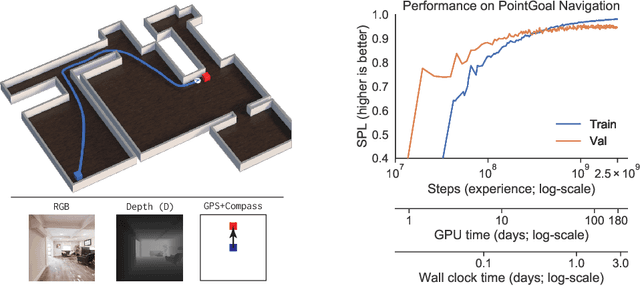

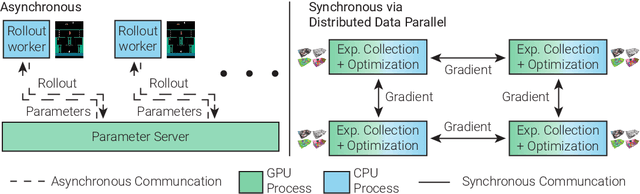
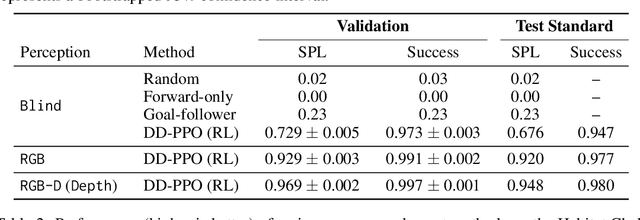
We present Decentralized Distributed Proximal Policy Optimization (DD-PPO), a method for distributed reinforcement learning in resource-intensive simulated environments. DD-PPO is distributed (uses multiple machines), decentralized (lacks a centralized server), and synchronous (no computation is ever "stale"), making it conceptually simple and easy to implement. In our experiments on training virtual robots to navigate in Habitat-Sim, DD-PPO exhibits near-linear scaling -- achieving a speedup of 107x on 128 GPUs over a serial implementation. We leverage this scaling to train an agent for 2.5 Billion steps of experience (the equivalent of 80 years of human experience) -- over 6 months of GPU-time training in under 3 days of wall-clock time with 64 GPUs. This massive-scale training not only sets the state of art on Habitat Autonomous Navigation Challenge 2019, but essentially "solves" the task -- near-perfect autonomous navigation in an unseen environment without access to a map, directly from an RGB-D camera and a GPS+Compass sensor. Fortuitously, error vs computation exhibits a power-law-like distribution; thus, 90% of peak performance is obtained relatively early (at 100 million steps) and relatively cheaply (under 1 day with 8 GPUs). Finally, we show that the scene understanding and navigation policies learned can be transferred to other navigation tasks -- the analog of "ImageNet pre-training + task-specific fine-tuning" for embodied AI. Our model outperforms ImageNet pre-trained CNNs on these transfer tasks and can serve as a universal resource (all models + code will be publicly available).
The Replica Dataset: A Digital Replica of Indoor Spaces
Jun 13, 2019


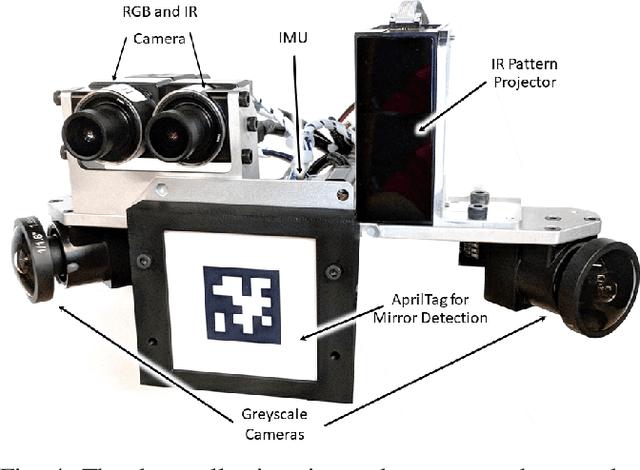
We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, high-resolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world - for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is `Habitat-compatible', i.e. can be natively used with AI Habitat for training and testing embodied agents.
Embodied Question Answering in Photorealistic Environments with Point Cloud Perception
Apr 06, 2019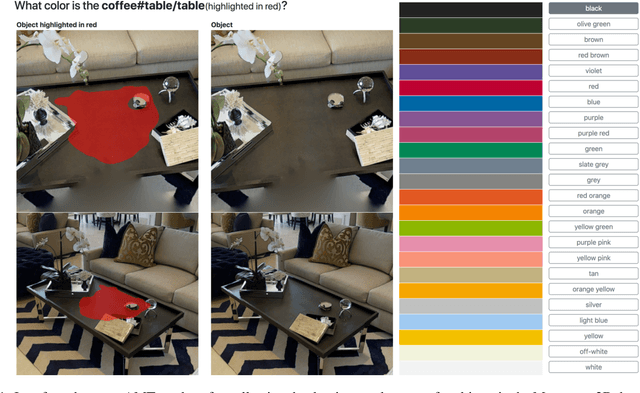
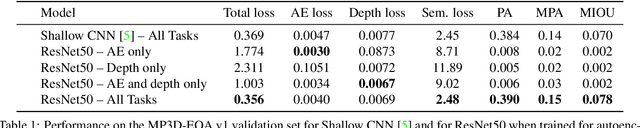
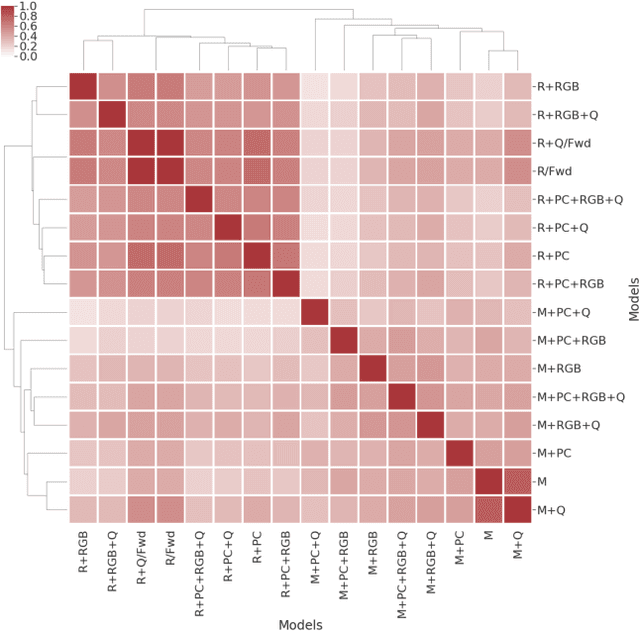
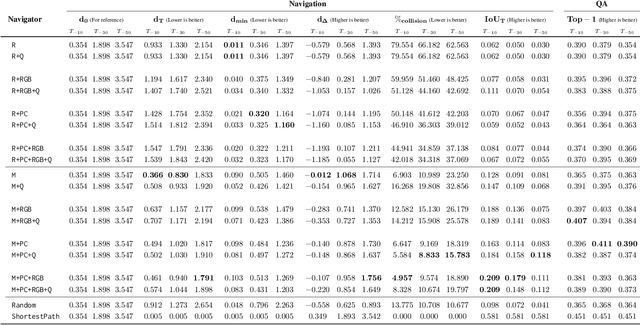
To help bridge the gap between internet vision-style problems and the goal of vision for embodied perception we instantiate a large-scale navigation task -- Embodied Question Answering [1] in photo-realistic environments (Matterport 3D). We thoroughly study navigation policies that utilize 3D point clouds, RGB images, or their combination. Our analysis of these models reveals several key findings. We find that two seemingly naive navigation baselines, forward-only and random, are strong navigators and challenging to outperform, due to the specific choice of the evaluation setting presented by [1]. We find a novel loss-weighting scheme we call Inflection Weighting to be important when training recurrent models for navigation with behavior cloning and are able to out perform the baselines with this technique. We find that point clouds provide a richer signal than RGB images for learning obstacle avoidance, motivating the use (and continued study) of 3D deep learning models for embodied navigation.
Habitat: A Platform for Embodied AI Research
Apr 02, 2019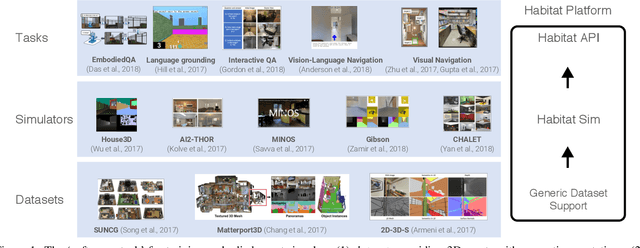
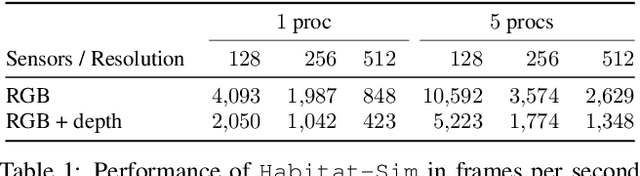

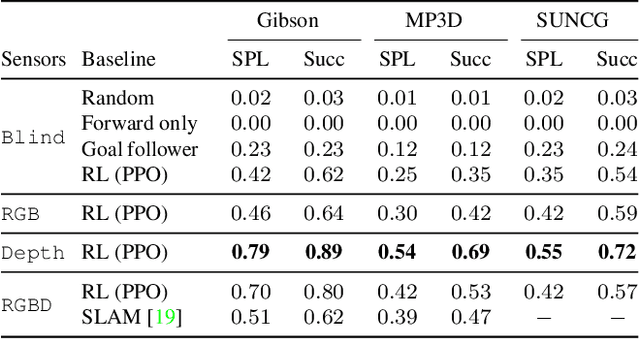
We present Habitat, a new platform for research in embodied artificial intelligence (AI). Habitat enables training embodied agents (virtual robots) in highly efficient photorealistic 3D simulation, before transferring the learned skills to reality. Specifically, Habitat consists of the following: 1. Habitat-Sim: a flexible, high-performance 3D simulator with configurable agents, multiple sensors, and generic 3D dataset handling (with built-in support for SUNCG, Matterport3D, Gibson datasets). Habitat-Sim is fast -- when rendering a scene from the Matterport3D dataset, Habitat-Sim achieves several thousand frames per second (fps) running single-threaded, and can reach over 10,000 fps multi-process on a single GPU, which is orders of magnitude faster than the closest simulator. 2. Habitat-API: a modular high-level library for end-to-end development of embodied AI algorithms -- defining embodied AI tasks (e.g. navigation, instruction following, question answering), configuring and training embodied agents (via imitation or reinforcement learning, or via classic SLAM), and benchmarking using standard metrics. These large-scale engineering contributions enable us to answer scientific questions requiring experiments that were till now impracticable or `merely' impractical. Specifically, in the context of point-goal navigation (1) we revisit the comparison between learning and SLAM approaches from two recent works and find evidence for the opposite conclusion -- that learning outperforms SLAM, if scaled to total experience far surpassing that of previous investigations, and (2) we conduct the first cross-dataset generalization experiments {train, test} x {Matterport3D, Gibson} for multiple sensors {blind, RGB, RGBD, D} and find that only agents with depth (D) sensors generalize across datasets. We hope that our open-source platform and these findings will advance research in embodied AI.
Exploiting 2D Floorplan for Building-scale Panorama RGBD Alignment
Dec 08, 2016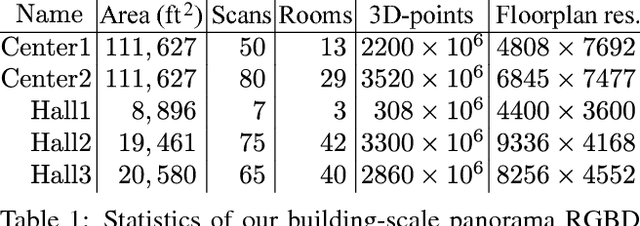
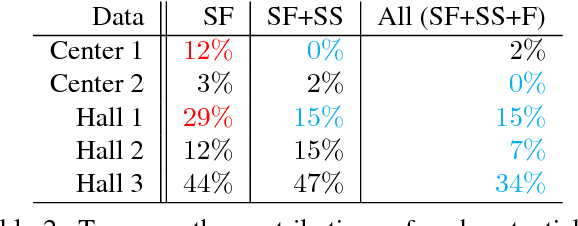
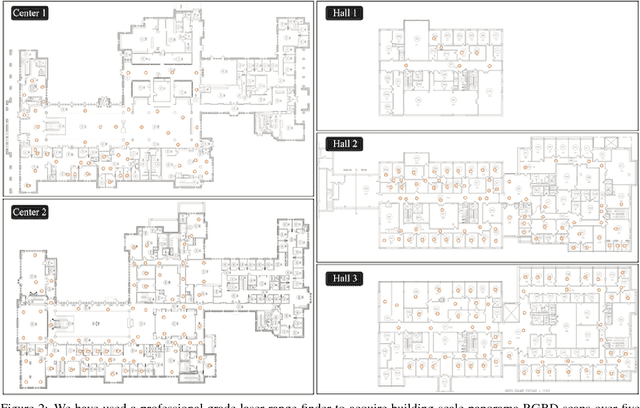

This paper presents a novel algorithm that utilizes a 2D floorplan to align panorama RGBD scans. While effective panorama RGBD alignment techniques exist, such a system requires extremely dense RGBD image sampling. Our approach can significantly reduce the number of necessary scans with the aid of a floorplan image. We formulate a novel Markov Random Field inference problem as a scan placement over the floorplan, as opposed to the conventional scan-to-scan alignment. The technical contributions lie in multi-modal image correspondence cues (between scans and schematic floorplan) as well as a novel coverage potential avoiding an inherent stacking bias. The proposed approach has been evaluated on five challenging large indoor spaces. To the best of our knowledge, we present the first effective system that utilizes a 2D floorplan image for building-scale 3D pointcloud alignment. The source code and the data will be shared with the community to further enhance indoor mapping research.