 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechniques for proving Asynchronous Convergence results for Markov Chain Monte Carlo methods
Jun 03, 2018
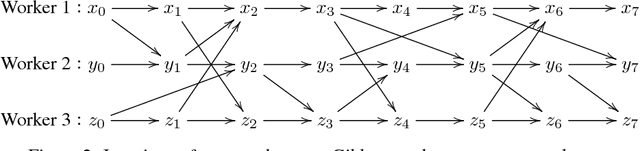
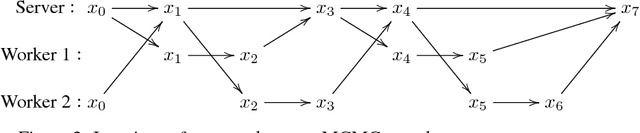
Markov Chain Monte Carlo (MCMC) methods such as Gibbs sampling are finding widespread use in applied statistics and machine learning. These often lead to difficult computational problems, which are increasingly being solved on parallel and distributed systems such as compute clusters. Recent work has proposed running iterative algorithms such as gradient descent and MCMC in parallel asynchronously for increased performance, with good empirical results in certain problems. Unfortunately, for MCMC this parallelization technique requires new convergence theory, as it has been explicitly demonstrated to lead to divergence on some examples. Recent theory on Asynchronous Gibbs sampling describes why these algorithms can fail, and provides a way to alter them to make them converge. In this article, we describe how to apply this theory in a generic setting, to understand the asynchronous behavior of any MCMC algorithm, including those implemented using parameter servers, and those not based on Gibbs sampling.
Rethinking Knowledge Graph Propagation for Zero-Shot Learning
May 31, 2018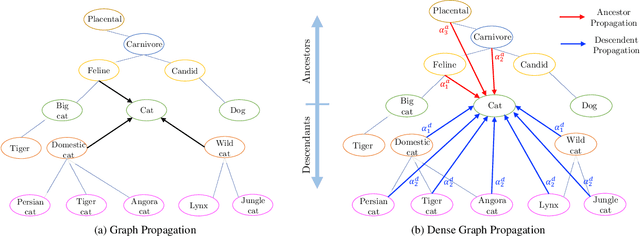
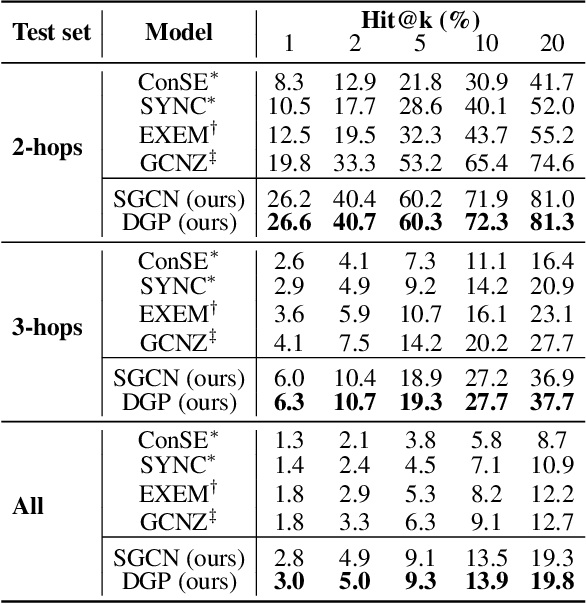
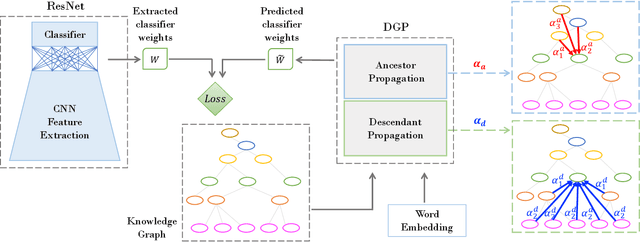
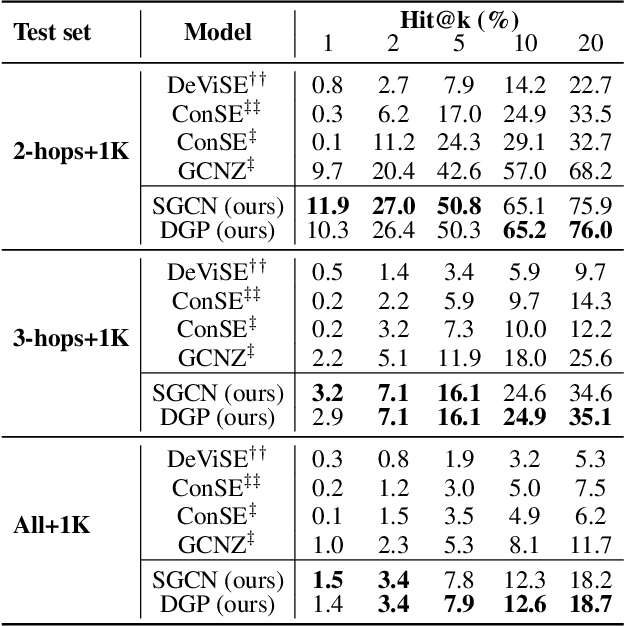
The potential of graph convolutional neural networks for the task of zero-shot learning has been demonstrated recently. These models are highly sample efficient as related concepts in the graph structure share statistical strength allowing generalization to new classes when faced with a lack of data. However, knowledge from distant nodes can get diluted when propagating through intermediate nodes, because current approaches to zero-shot learning use graph propagation schemes that perform Laplacian smoothing at each layer. We show that extensive smoothing does not help the task of regressing classifier weights in zero-shot learning. In order to still incorporate information from distant nodes and utilize the graph structure, we propose an Attentive Dense Graph Propagation Module (ADGPM). ADGPM allows us to exploit the hierarchical graph structure of the knowledge graph through additional connections. These connections are added based on a node's relationship to its ancestors and descendants and an attention scheme is further used to weigh their contribution depending on the distance to the node. Finally, we illustrate that finetuning of the feature representation after training the ADGPM leads to considerable improvements. Our method achieves competitive results, outperforming previous zero-shot learning approaches.
Unsupervised Text Style Transfer using Language Models as Discriminators
May 31, 2018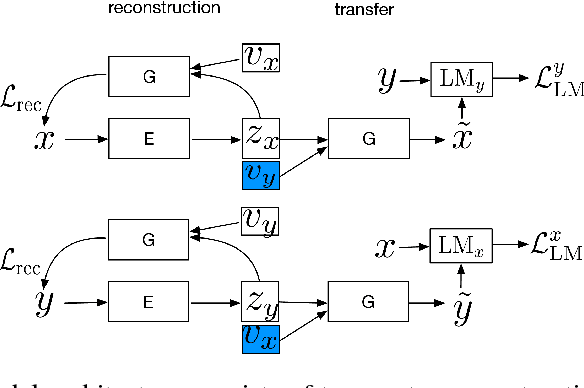
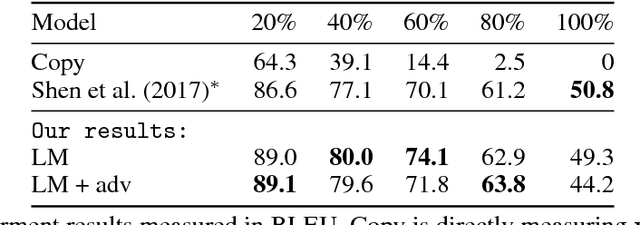
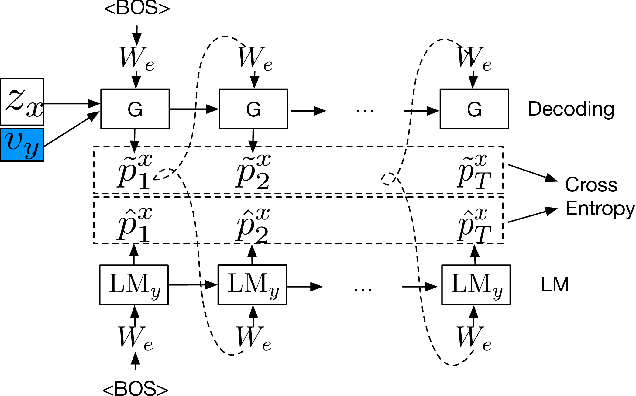
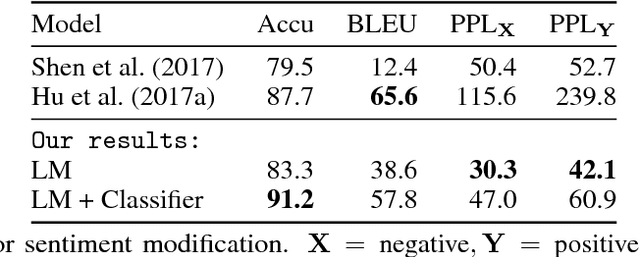
Binary classifiers are often employed as discriminators in GAN-based unsupervised style transfer systems to ensure that transferred sentences are similar to sentences in the target domain. One difficulty with this approach is that the error signal provided by the discriminator can be unstable and is sometimes insufficient to train the generator to produce fluent language. In this paper, we propose a new technique that uses a target domain language model as the discriminator, providing richer and more stable token-level feedback during the learning process. We train the generator to minimize the negative log likelihood (NLL) of generated sentences, evaluated by the language model. By using a continuous approximation of discrete sampling under the generator, our model can be trained using back-propagation in an end- to-end fashion. Moreover, our empirical results show that when using a language model as a structured discriminator, it is possible to forgoe adversarial steps during training, making the process more stable. We compare our model with previous work using convolutional neural networks (CNNs) as discriminators and show that our approach leads to improved performance on three tasks: word substitution decipherment, sentiment modification, and related language translation.
Hybrid Retrieval-Generation Reinforced Agent for Medical Image Report Generation
May 21, 2018
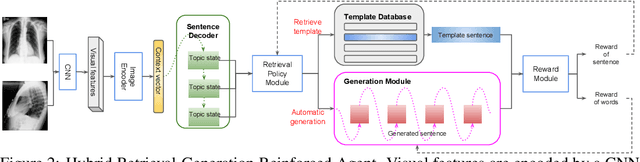
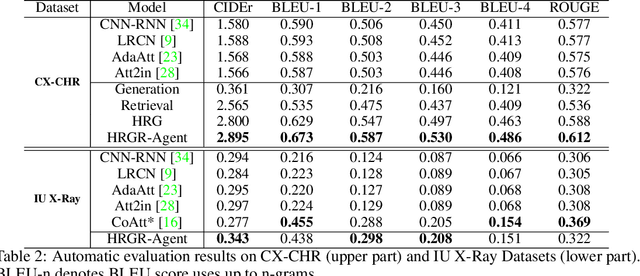
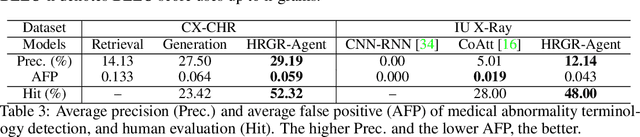
Generating long and coherent reports to describe medical images poses challenges to bridging visual patterns with informative human linguistic descriptions. We propose a novel Hybrid Retrieval-Generation Reinforced Agent (HRGR-Agent) which reconciles traditional retrieval-based approaches populated with human prior knowledge, with modern learning-based approaches to achieve structured, robust, and diverse report generation. HRGR-Agent employs a hierarchical decision-making procedure. For each sentence, a high-level retrieval policy module chooses to either retrieve a template sentence from an off-the-shelf template database, or invoke a low-level generation module to generate a new sentence. HRGR-Agent is updated via reinforcement learning, guided by sentence-level and word-level rewards. Experiments show that our approach achieves the state-of-the-art results on two medical report datasets, generating well-balanced structured sentences with robust coverage of heterogeneous medical report contents. In addition, our model achieves the highest detection accuracy of medical terminologies, and improved human evaluation performance.
Image-derived generative modeling of pseudo-macromolecular structures - towards the statistical assessment of Electron CryoTomography template matching
May 12, 2018



Cellular Electron CryoTomography (CECT) is a 3D imaging technique that captures information about the structure and spatial organization of macromolecular complexes within single cells, in near-native state and at sub-molecular resolution. Although template matching is often used to locate macromolecules in a CECT image, it is insufficient as it only measures the relative structural similarity. Therefore, it is preferable to assess the statistical credibility of the decision through hypothesis testing, requiring many templates derived from a diverse population of macromolecular structures. Due to the very limited number of known structures, we need a generative model to efficiently and reliably sample pseudo-structures from the complex distribution of macromolecular structures. To address this challenge, we propose a novel image-derived approach for performing hypothesis testing for template matching by constructing generative models using the generative adversarial network. Finally, we conducted hypothesis testing experiments for template matching on both simulated and experimental subtomograms, allowing us to conclude the identity of subtomograms with high statistical credibility and significantly reducing false positives.
DTR-GAN: Dilated Temporal Relational Adversarial Network for Video Summarization
Apr 30, 2018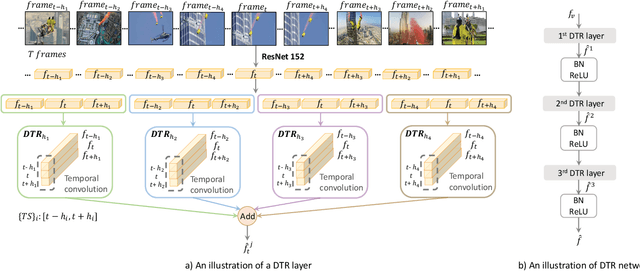
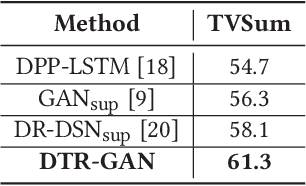
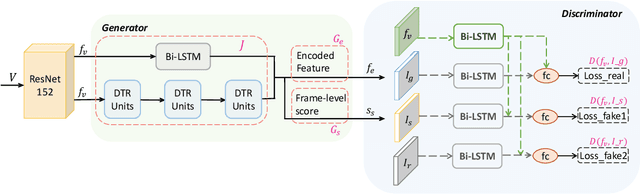

The large amount of videos popping up every day, make it is more and more critical that key information within videos can be extracted and understood in a very short time. Video summarization, the task of finding the smallest subset of frames, which still conveys the whole story of a given video, is thus of great significance to improve efficiency of video understanding. In this paper, we propose a novel Dilated Temporal Relational Generative Adversarial Network (DTR-GAN) to achieve frame-level video summarization. Given a video, it can select a set of key frames, which contains the most meaningful and compact information. Specifically, DTR-GAN learns a dilated temporal relational generator and a discriminator with three-player loss in an adversarial manner. A new dilated temporal relation (DTR) unit is introduced for enhancing temporal representation capturing. The generator aims to select key frames by using DTR units to effectively exploit global multi-scale temporal context and to complement the commonly used Bi-LSTM. To ensure that the summaries capture enough key video representation from a global perspective rather than a trivial randomly shorten sequence, we present a discriminator that learns to enforce both the information completeness and compactness of summaries via a three-player loss. The three-player loss includes the generated summary loss, the random summary loss, and the real summary (ground-truth) loss, which play important roles for better regularizing the learned model to obtain useful summaries. Comprehensive experiments on two public datasets SumMe and TVSum show the superiority of our DTR-GAN over the state-of-the-art approaches.
Identifiability of Nonparametric Mixture Models and Bayes Optimal Clustering
Apr 22, 2018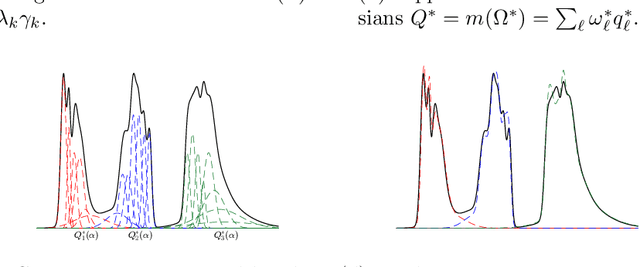
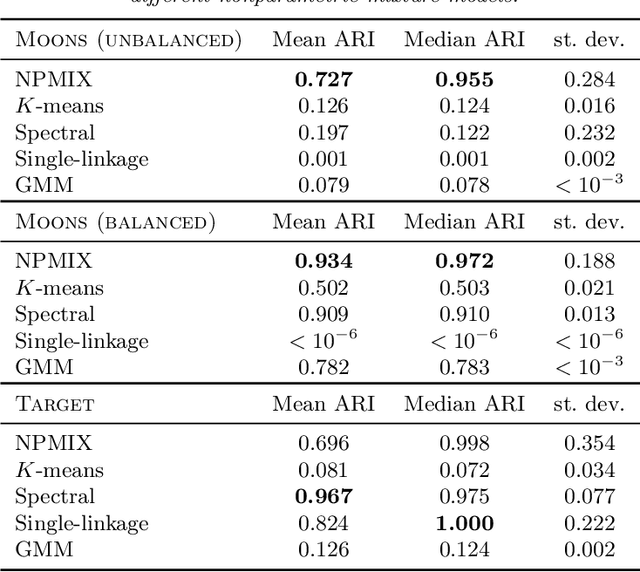
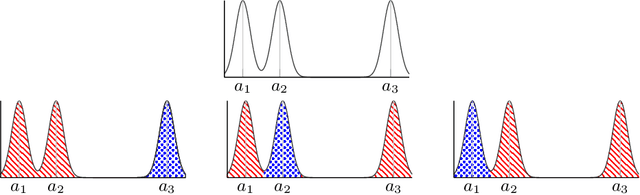
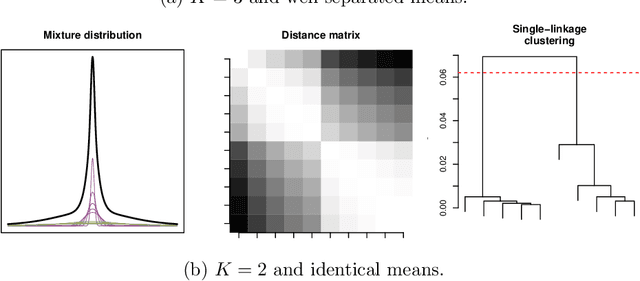
Motivated by problems in data clustering, we establish general conditions under which families of nonparametric mixture models are identifiable by introducing a novel framework for clustering overfitted \emph{parametric} (i.e. misspecified) mixture models. These conditions generalize existing conditions in the literature, and are flexible enough to include for example mixtures of Gaussian mixtures. In contrast to the recent literature on estimating nonparametric mixtures, we allow for general nonparametric mixture components, and instead impose regularity assumptions on the underlying mixing measure. As our primary application, we apply these results to partition-based clustering, generalizing the well-known notion of a Bayes optimal partition from classical model-based clustering to nonparametric settings. Furthermore, this framework is constructive in that it yields a practical algorithm for learning identified mixtures, which is illustrated through several examples. The key conceptual device in the analysis is the convex, metric geometry of probability distributions on metric spaces and its connection to optimal transport and the Wasserstein convergence of mixing measures. The result is a flexible framework for nonparametric clustering with formal consistency guarantees.
ConnNet: A Long-Range Relation-Aware Pixel-Connectivity Network for Salient Segmentation
Apr 20, 2018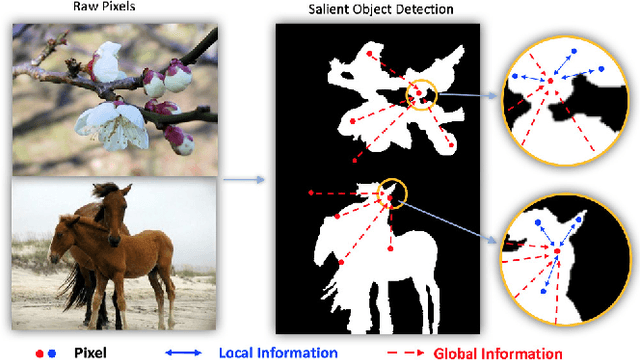
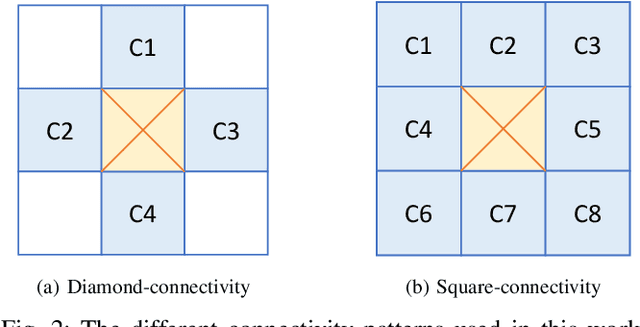
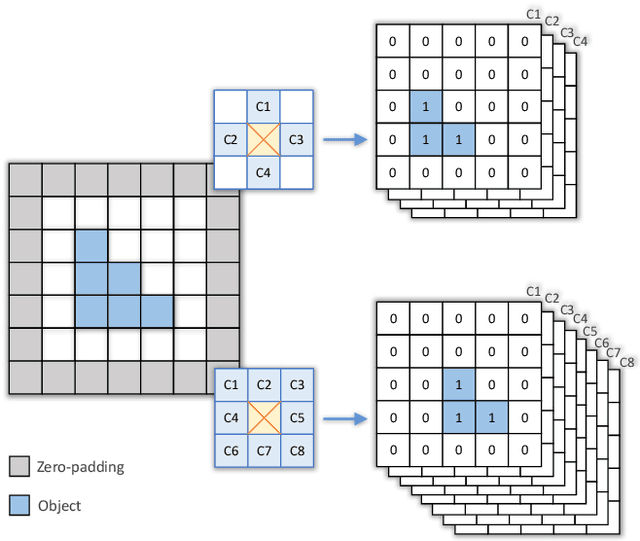
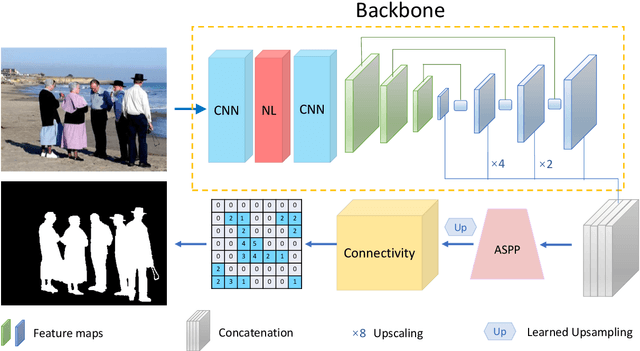
Salient segmentation aims to segment out attention-grabbing regions, a critical yet challenging task and the foundation of many high-level computer vision applications. It requires semantic-aware grouping of pixels into salient regions and benefits from the utilization of global multi-scale contexts to achieve good local reasoning. Previous works often address it as two-class segmentation problems utilizing complicated multi-step procedures including refinement networks and complex graphical models. We argue that semantic salient segmentation can instead be effectively resolved by reformulating it as a simple yet intuitive pixel-pair based connectivity prediction task. Following the intuition that salient objects can be naturally grouped via semantic-aware connectivity between neighboring pixels, we propose a pure Connectivity Net (ConnNet). ConnNet predicts connectivity probabilities of each pixel with its neighboring pixels by leveraging multi-level cascade contexts embedded in the image and long-range pixel relations. We investigate our approach on two tasks, namely salient object segmentation and salient instance-level segmentation, and illustrate that improvements can be obtained by modeling these tasks as connectivity instead of binary segmentation tasks. We achieve state-of-the-art performance, outperforming or being comparable to existing approaches while reducing training time due to our less complex approach.
Orthogonality-Promoting Distance Metric Learning: Convex Relaxation and Theoretical Analysis
Feb 16, 2018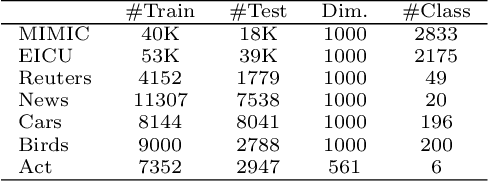

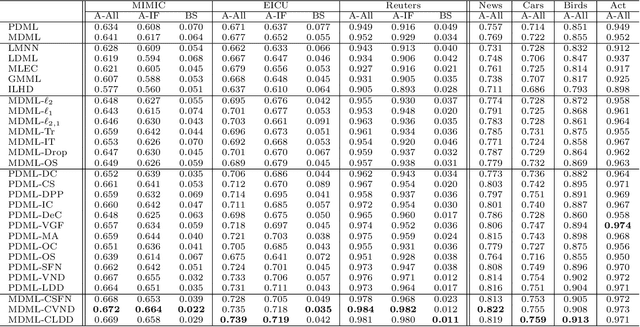
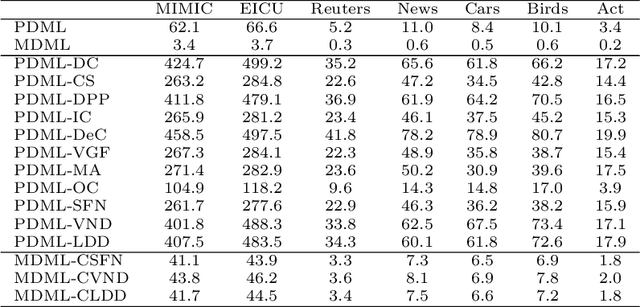
Distance metric learning (DML), which learns a distance metric from labeled "similar" and "dissimilar" data pairs, is widely utilized. Recently, several works investigate orthogonality-promoting regularization (OPR), which encourages the projection vectors in DML to be close to being orthogonal, to achieve three effects: (1) high balancedness -- achieving comparable performance on both frequent and infrequent classes; (2) high compactness -- using a small number of projection vectors to achieve a "good" metric; (3) good generalizability -- alleviating overfitting to training data. While showing promising results, these approaches suffer three problems. First, they involve solving non-convex optimization problems where achieving the global optimal is NP-hard. Second, it lacks a theoretical understanding why OPR can lead to balancedness. Third, the current generalization error analysis of OPR is not directly on the regularizer. In this paper, we address these three issues by (1) seeking convex relaxations of the original nonconvex problems so that the global optimal is guaranteed to be achievable; (2) providing a formal analysis on OPR's capability of promoting balancedness; (3) providing a theoretical analysis that directly reveals the relationship between OPR and generalization performance. Experiments on various datasets demonstrate that our convex methods are more effective in promoting balancedness, compactness, and generalization, and are computationally more efficient, compared with the nonconvex methods.
Bayesian Nonparametric Kernel-Learning
Jan 30, 2018

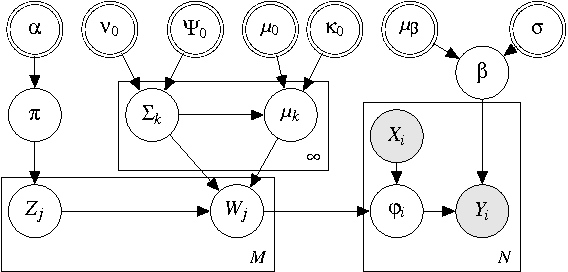

Kernel methods are ubiquitous tools in machine learning. However, there is often little reason for the common practice of selecting a kernel a priori. Even if a universal approximating kernel is selected, the quality of the finite sample estimator may be greatly affected by the choice of kernel. Furthermore, when directly applying kernel methods, one typically needs to compute a $N \times N$ Gram matrix of pairwise kernel evaluations to work with a dataset of $N$ instances. The computation of this Gram matrix precludes the direct application of kernel methods on large datasets, and makes kernel learning especially difficult. In this paper we introduce Bayesian nonparmetric kernel-learning (BaNK), a generic, data-driven framework for scalable learning of kernels. BaNK places a nonparametric prior on the spectral distribution of random frequencies allowing it to both learn kernels and scale to large datasets. We show that this framework can be used for large scale regression and classification tasks. Furthermore, we show that BaNK outperforms several other scalable approaches for kernel learning on a variety of real world datasets.