 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEBench: A Novel Benchmark for Understanding Mutual Exclusivity Bias in Vision-Language Models
May 26, 2025



This paper introduces MEBench, a novel benchmark for evaluating mutual exclusivity (ME) bias, a cognitive phenomenon observed in children during word learning. Unlike traditional ME tasks, MEBench further incorporates spatial reasoning to create more challenging and realistic evaluation settings. We assess the performance of state-of-the-art vision-language models (VLMs) on this benchmark using novel evaluation metrics that capture key aspects of ME-based reasoning. To facilitate controlled experimentation, we also present a flexible and scalable data generation pipeline that supports the construction of diverse annotated scenes.
Leveraging Object Priors for Point Tracking
Sep 09, 2024



Point tracking is a fundamental problem in computer vision with numerous applications in AR and robotics. A common failure mode in long-term point tracking occurs when the predicted point leaves the object it belongs to and lands on the background or another object. We identify this as the failure to correctly capture objectness properties in learning to track. To address this limitation of prior work, we propose a novel objectness regularization approach that guides points to be aware of object priors by forcing them to stay inside the the boundaries of object instances. By capturing objectness cues at training time, we avoid the need to compute object masks during testing. In addition, we leverage contextual attention to enhance the feature representation for capturing objectness at the feature level more effectively. As a result, our approach achieves state-of-the-art performance on three point tracking benchmarks, and we further validate the effectiveness of our components via ablation studies. The source code is available at: https://github.com/RehgLab/tracking_objectness
Modeling Multimodal Social Interactions: New Challenges and Baselines with Densely Aligned Representations
Mar 04, 2024



Understanding social interactions involving both verbal and non-verbal cues is essential to effectively interpret social situations. However, most prior works on multimodal social cues focus predominantly on single-person behaviors or rely on holistic visual representations that are not densely aligned to utterances in multi-party environments. They are limited in modeling the intricate dynamics of multi-party interactions. In this paper, we introduce three new challenging tasks to model the fine-grained dynamics between multiple people: speaking target identification, pronoun coreference resolution, and mentioned player prediction. We contribute extensive data annotations to curate these new challenges in social deduction game settings. Furthermore, we propose a novel multimodal baseline that leverages densely aligned language-visual representations by synchronizing visual features with their corresponding utterances. This facilitates concurrently capturing verbal and non-verbal cues pertinent to social reasoning. Experiments demonstrate the effectiveness of the proposed approach with densely aligned multimodal representations in modeling social interactions. We will release our benchmarks and source code to facilitate further research.
Low-shot Object Learning with Mutual Exclusivity Bias
Dec 06, 2023



This paper introduces Low-shot Object Learning with Mutual Exclusivity Bias (LSME), the first computational framing of mutual exclusivity bias, a phenomenon commonly observed in infants during word learning. We provide a novel dataset, comprehensive baselines, and a state-of-the-art method to enable the ML community to tackle this challenging learning task. The goal of LSME is to analyze an RGB image of a scene containing multiple objects and correctly associate a previously-unknown object instance with a provided category label. This association is then used to perform low-shot learning to test category generalization. We provide a data generation pipeline for the LSME problem and conduct a thorough analysis of the factors that contribute to its difficulty. Additionally, we evaluate the performance of multiple baselines, including state-of-the-art foundation models. Finally, we present a baseline approach that outperforms state-of-the-art models in terms of low-shot accuracy.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Multipath Graph Convolutional Neural Networks
May 04, 2021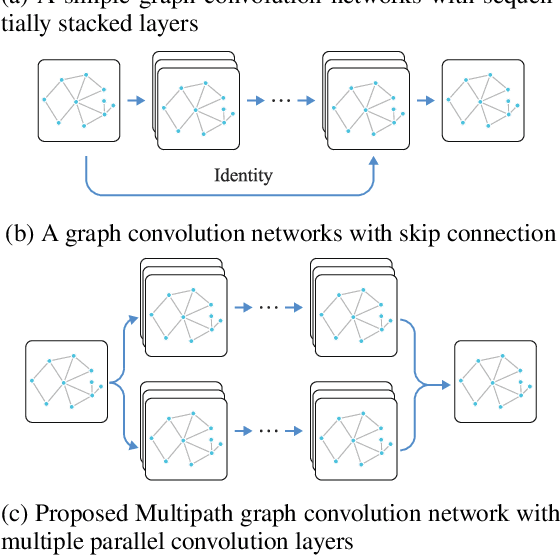
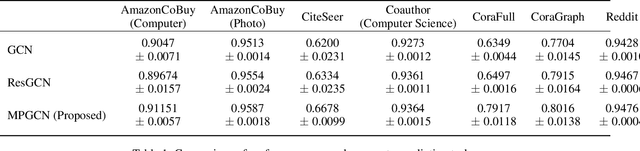
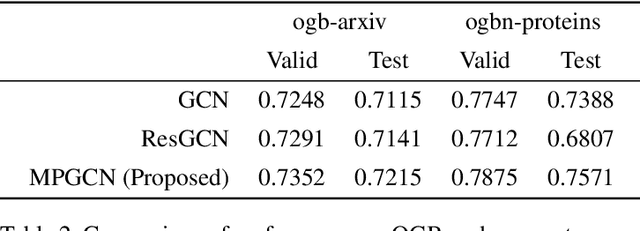
Graph convolution networks have recently garnered a lot of attention for representation learning on non-Euclidean feature spaces. Recent research has focused on stacking multiple layers like in convolutional neural networks for the increased expressive power of graph convolution networks. However, simply stacking multiple graph convolution layers lead to issues like vanishing gradient, over-fitting and over-smoothing. Such problems are much less when using shallower networks, even though the shallow networks have lower expressive power. In this work, we propose a novel Multipath Graph convolutional neural network that aggregates the output of multiple different shallow networks. We train and test our model on various benchmarks datasets for the task of node property prediction. Results show that the proposed method not only attains increased test accuracy but also requires fewer training epochs to converge. The full implementation is available at https://github.com/rangan2510/MultiPathGCN