 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Resolve Alliance Dilemmas in Many-Player Zero-Sum Games
Feb 27, 2020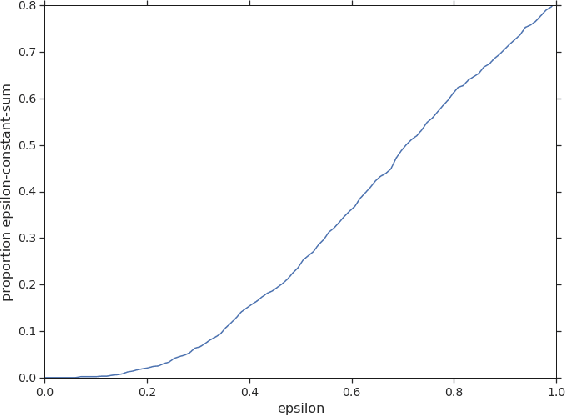
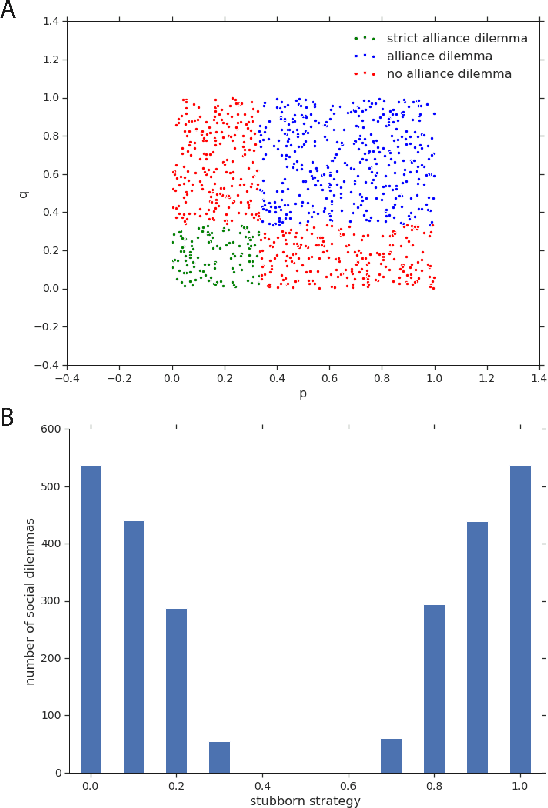
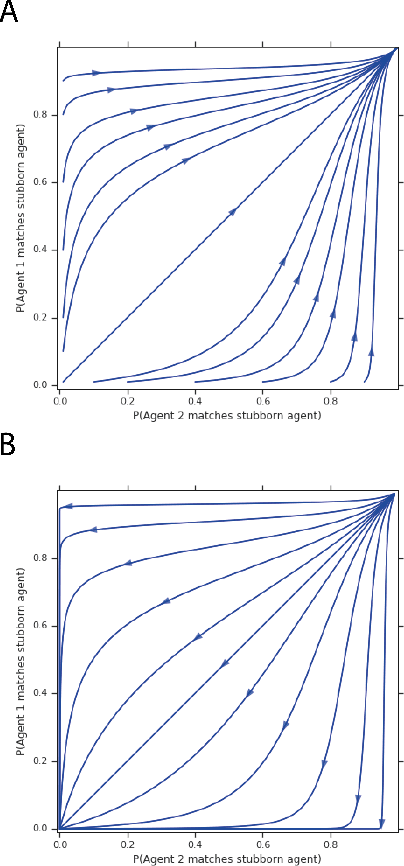
Zero-sum games have long guided artificial intelligence research, since they possess both a rich strategy space of best-responses and a clear evaluation metric. What's more, competition is a vital mechanism in many real-world multi-agent systems capable of generating intelligent innovations: Darwinian evolution, the market economy and the AlphaZero algorithm, to name a few. In two-player zero-sum games, the challenge is usually viewed as finding Nash equilibrium strategies, safeguarding against exploitation regardless of the opponent. While this captures the intricacies of chess or Go, it avoids the notion of cooperation with co-players, a hallmark of the major transitions leading from unicellular organisms to human civilization. Beyond two players, alliance formation often confers an advantage; however this requires trust, namely the promise of mutual cooperation in the face of incentives to defect. Successful play therefore requires adaptation to co-players rather than the pursuit of non-exploitability. Here we argue that a systematic study of many-player zero-sum games is a crucial element of artificial intelligence research. Using symmetric zero-sum matrix games, we demonstrate formally that alliance formation may be seen as a social dilemma, and empirically that na\"ive multi-agent reinforcement learning therefore fails to form alliances. We introduce a toy model of economic competition, and show how reinforcement learning may be augmented with a peer-to-peer contract mechanism to discover and enforce alliances. Finally, we generalize our agent model to incorporate temporally-extended contracts, presenting opportunities for further work.
Social diversity and social preferences in mixed-motive reinforcement learning
Feb 12, 2020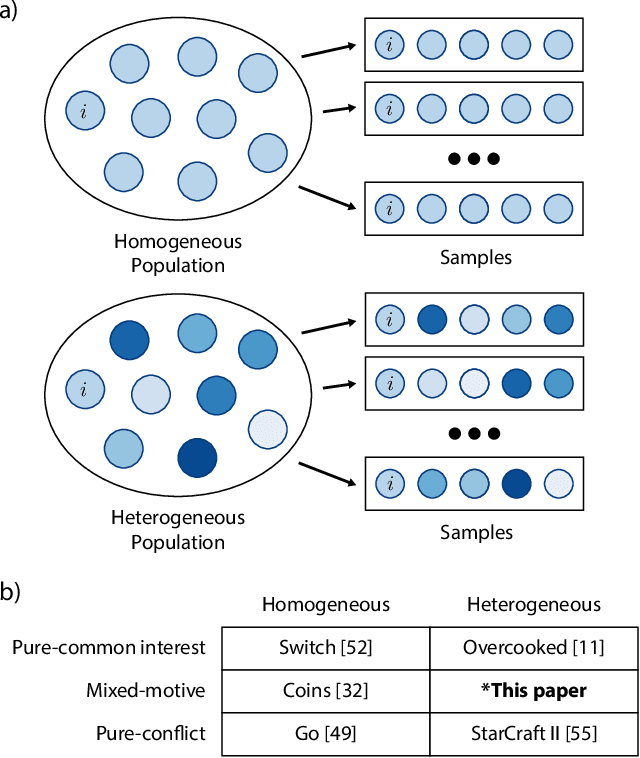
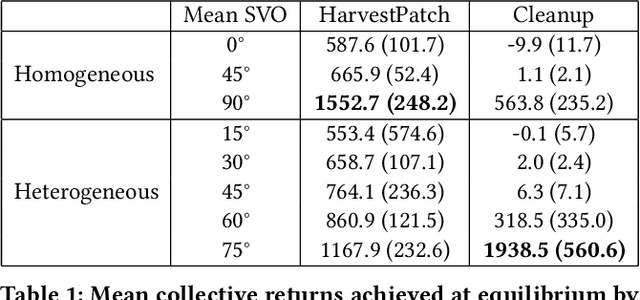
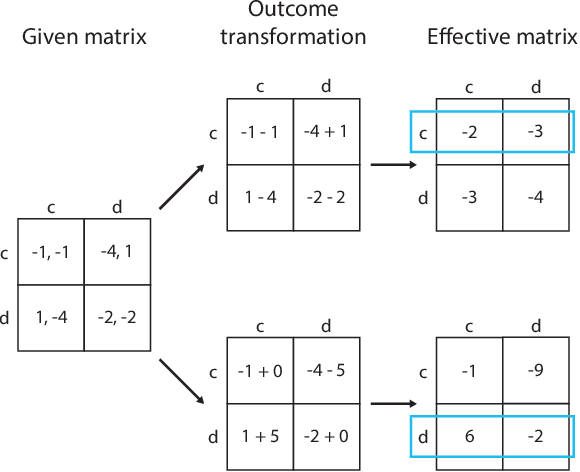
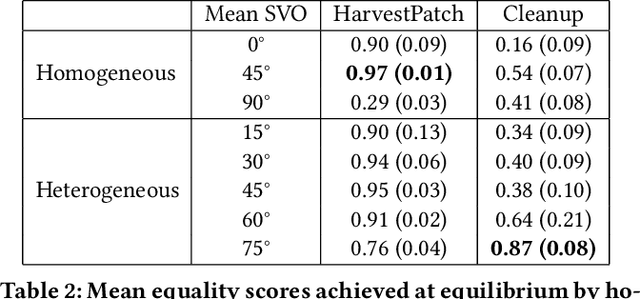
Recent research on reinforcement learning in pure-conflict and pure-common interest games has emphasized the importance of population heterogeneity. In contrast, studies of reinforcement learning in mixed-motive games have primarily leveraged homogeneous approaches. Given the defining characteristic of mixed-motive games--the imperfect correlation of incentives between group members--we study the effect of population heterogeneity on mixed-motive reinforcement learning. We draw on interdependence theory from social psychology and imbue reinforcement learning agents with Social Value Orientation (SVO), a flexible formalization of preferences over group outcome distributions. We subsequently explore the effects of diversity in SVO on populations of reinforcement learning agents in two mixed-motive Markov games. We demonstrate that heterogeneity in SVO generates meaningful and complex behavioral variation among agents similar to that suggested by interdependence theory. Empirical results in these mixed-motive dilemmas suggest agents trained in heterogeneous populations develop particularly generalized, high-performing policies relative to those trained in homogeneous populations.
Smooth markets: A basic mechanism for organizing gradient-based learners
Jan 18, 2020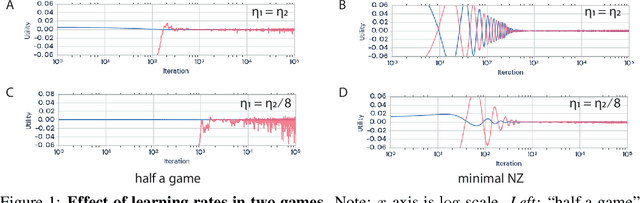
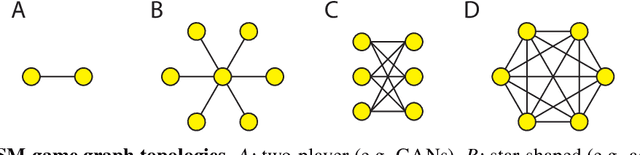
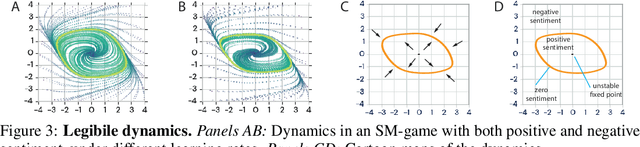
With the success of modern machine learning, it is becoming increasingly important to understand and control how learning algorithms interact. Unfortunately, negative results from game theory show there is little hope of understanding or controlling general n-player games. We therefore introduce smooth markets (SM-games), a class of n-player games with pairwise zero sum interactions. SM-games codify a common design pattern in machine learning that includes (some) GANs, adversarial training, and other recent algorithms. We show that SM-games are amenable to analysis and optimization using first-order methods.
* 18 pages, 3 figures
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019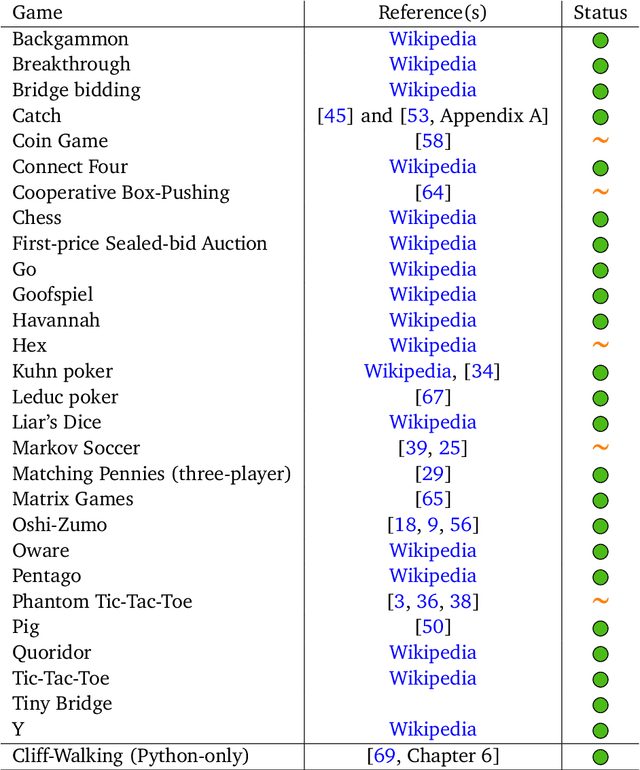
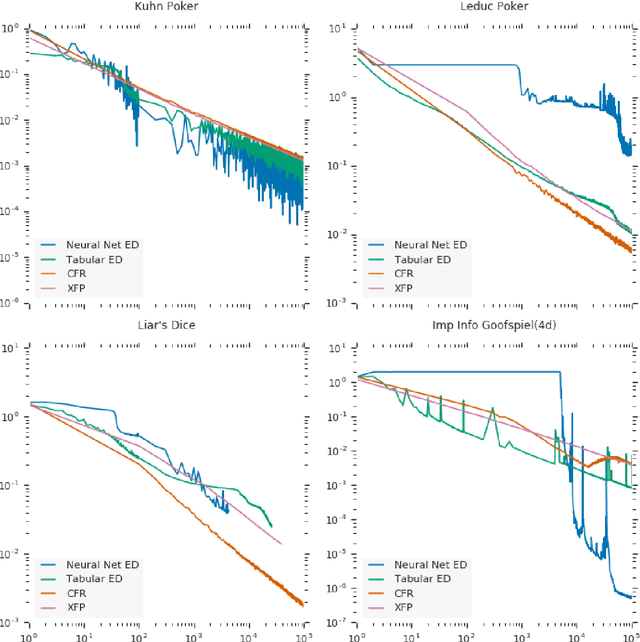
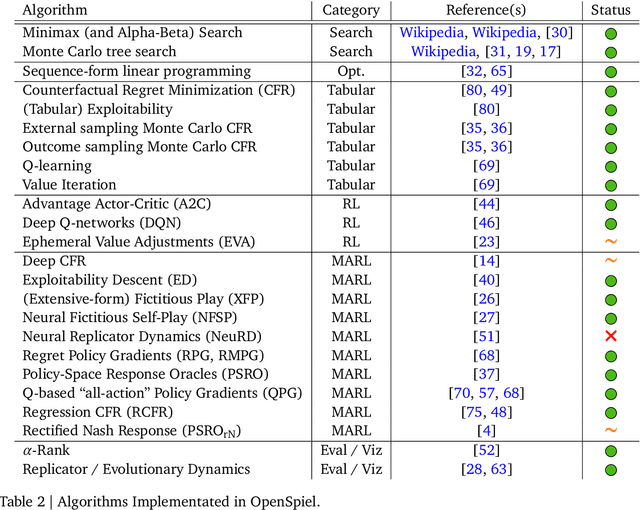
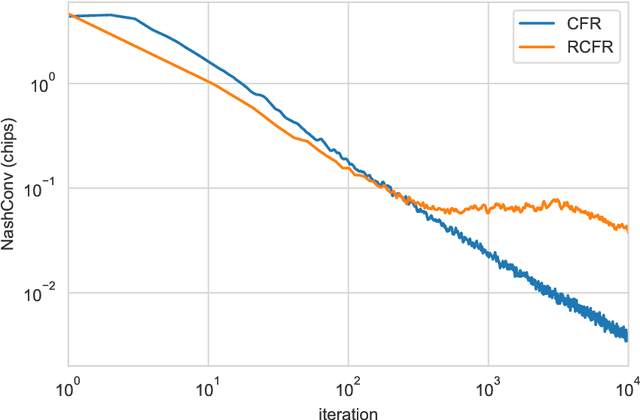
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
A Generalized Training Approach for Multiagent Learning
Sep 27, 2019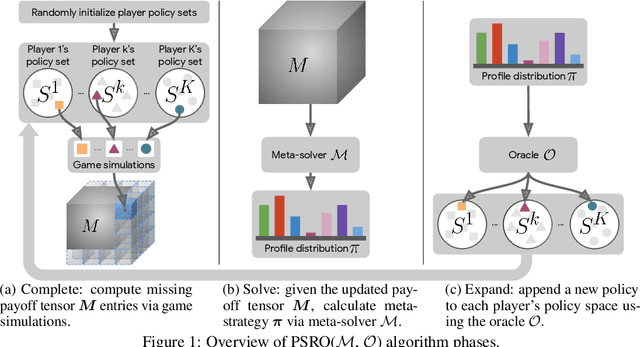
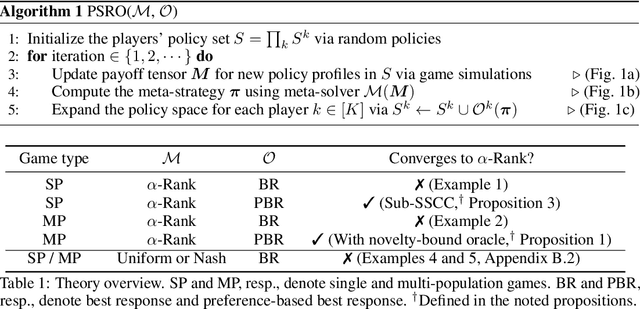
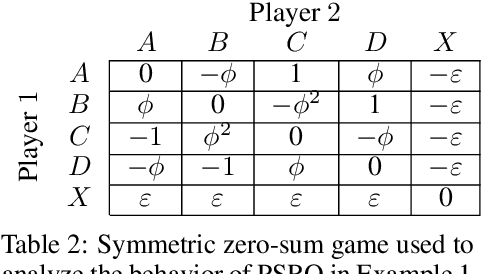
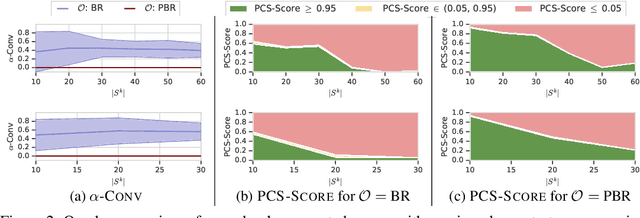
This paper investigates a population-based training regime based on game-theoretic principles called Policy-Spaced Response Oracles (PSRO). PSRO is general in the sense that it (1) encompasses well-known algorithms such as fictitious play and double oracle as special cases, and (2) in principle applies to general-sum, many-player games. Despite this, prior studies of PSRO have been focused on two-player zero-sum games, a regime wherein Nash equilibria are tractably computable. In moving from two-player zero-sum games to more general settings, computation of Nash equilibria quickly becomes infeasible. Here, we extend the theoretical underpinnings of PSRO by considering an alternative solution concept, {\alpha}-Rank, which is unique (thus faces no equilibrium selection issues, unlike Nash) and tractable to compute in general-sum, many-player settings. We establish convergence guarantees in several games classes, and identify links between Nash equilibria and {\alpha}-Rank. We demonstrate the competitive performance of {\alpha}-Rank-based PSRO against an exact Nash solver-based PSRO in 2-player Kuhn and Leduc Poker. We then go beyond the reach of prior PSRO applications by considering 3- to 5-player poker games, yielding instances where {\alpha}-Rank achieves faster convergence than approximate Nash solvers, thus establishing it as a favorable general games solver. We also carry out an initial empirical validation in MuJoCo soccer, illustrating the feasibility of the proposed approach in another complex domain.
Learning Reciprocity in Complex Sequential Social Dilemmas
Mar 19, 2019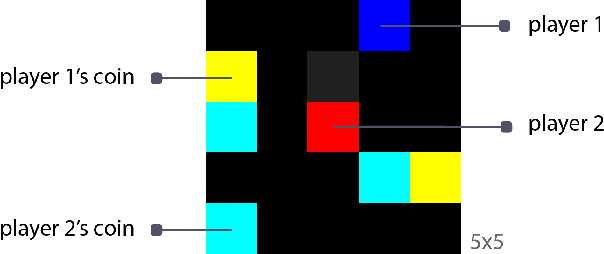
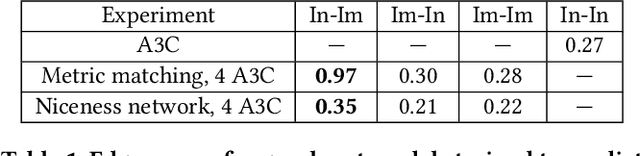
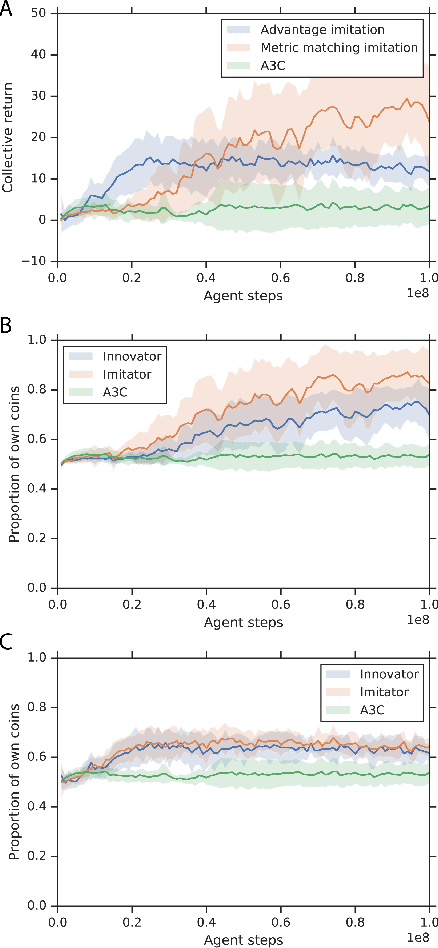
Reciprocity is an important feature of human social interaction and underpins our cooperative nature. What is more, simple forms of reciprocity have proved remarkably resilient in matrix game social dilemmas. Most famously, the tit-for-tat strategy performs very well in tournaments of Prisoner's Dilemma. Unfortunately this strategy is not readily applicable to the real world, in which options to cooperate or defect are temporally and spatially extended. Here, we present a general online reinforcement learning algorithm that displays reciprocal behavior towards its co-players. We show that it can induce pro-social outcomes for the wider group when learning alongside selfish agents, both in a $2$-player Markov game, and in $5$-player intertemporal social dilemmas. We analyse the resulting policies to show that the reciprocating agents are strongly influenced by their co-players' behavior.
Autocurricula and the Emergence of Innovation from Social Interaction: A Manifesto for Multi-Agent Intelligence Research
Mar 11, 2019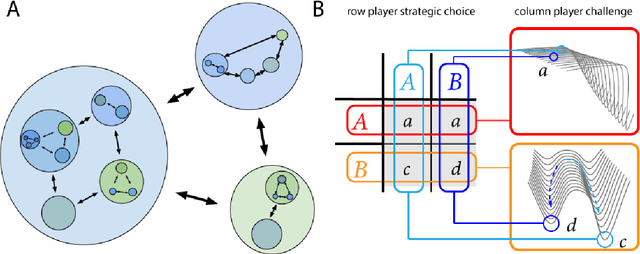
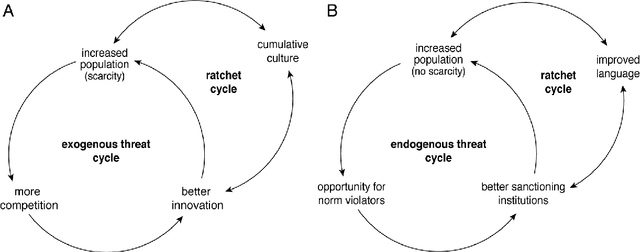
Evolution has produced a multi-scale mosaic of interacting adaptive units. Innovations arise when perturbations push parts of the system away from stable equilibria into new regimes where previously well-adapted solutions no longer work. Here we explore the hypothesis that multi-agent systems sometimes display intrinsic dynamics arising from competition and cooperation that provide a naturally emergent curriculum, which we term an autocurriculum. The solution of one social task often begets new social tasks, continually generating novel challenges, and thereby promoting innovation. Under certain conditions these challenges may become increasingly complex over time, demanding that agents accumulate ever more innovations.
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019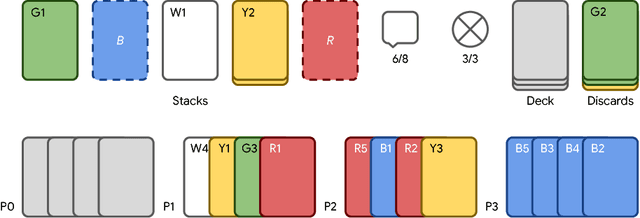
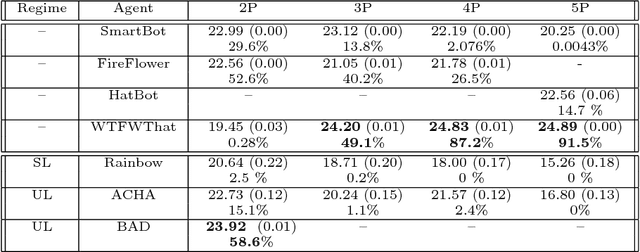
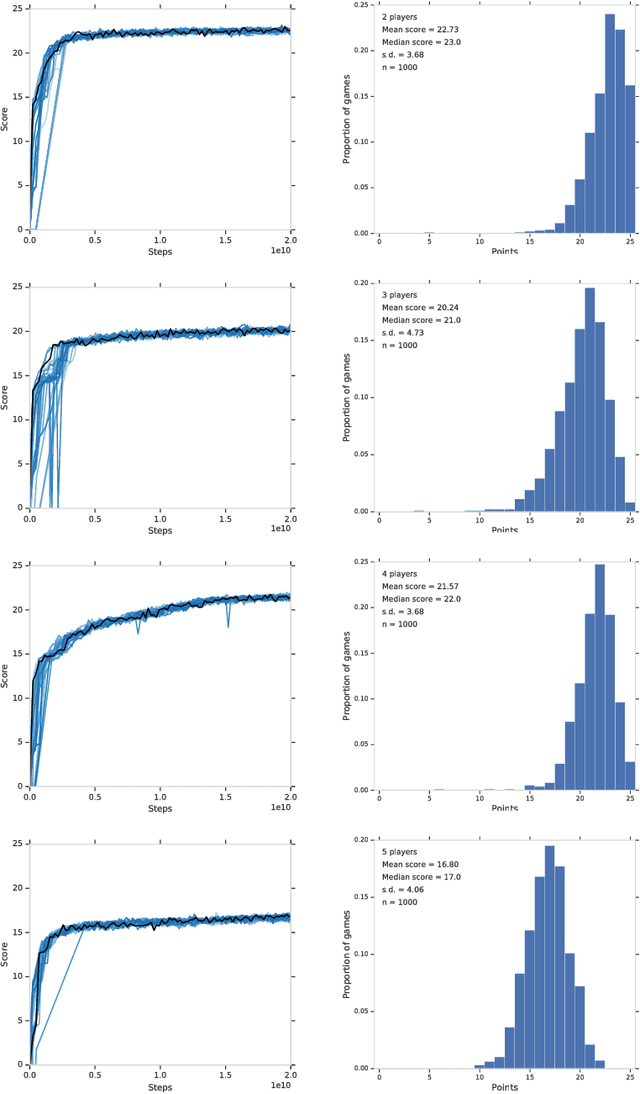
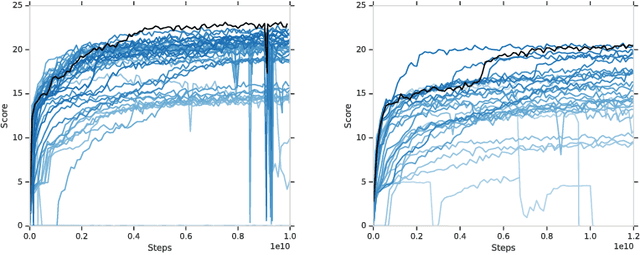
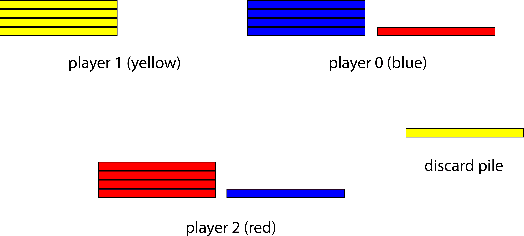
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
Causal Reasoning from Meta-reinforcement Learning
Jan 23, 2019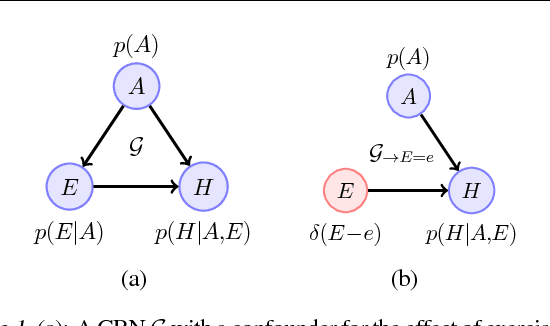


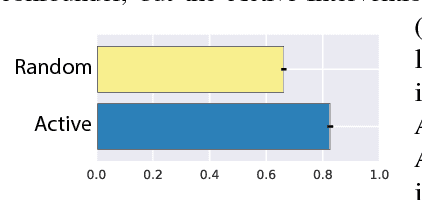
Discovering and exploiting the causal structure in the environment is a crucial challenge for intelligent agents. Here we explore whether causal reasoning can emerge via meta-reinforcement learning. We train a recurrent network with model-free reinforcement learning to solve a range of problems that each contain causal structure. We find that the trained agent can perform causal reasoning in novel situations in order to obtain rewards. The agent can select informative interventions, draw causal inferences from observational data, and make counterfactual predictions. Although established formal causal reasoning algorithms also exist, in this paper we show that such reasoning can arise from model-free reinforcement learning, and suggest that causal reasoning in complex settings may benefit from the more end-to-end learning-based approaches presented here. This work also offers new strategies for structured exploration in reinforcement learning, by providing agents with the ability to perform -- and interpret -- experiments.
Malthusian Reinforcement Learning
Dec 17, 2018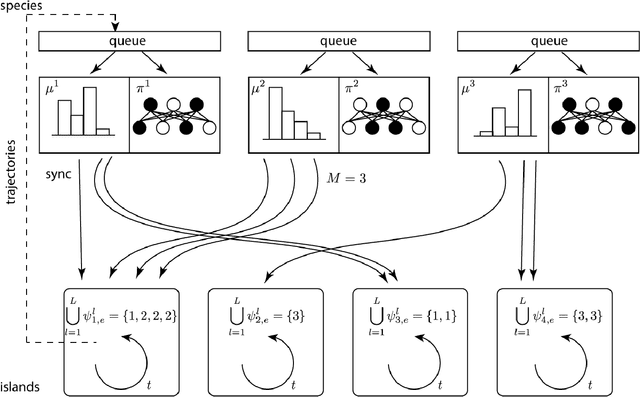
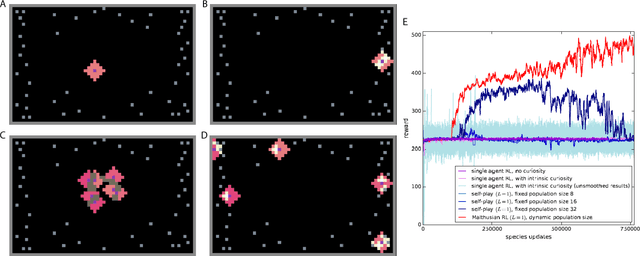
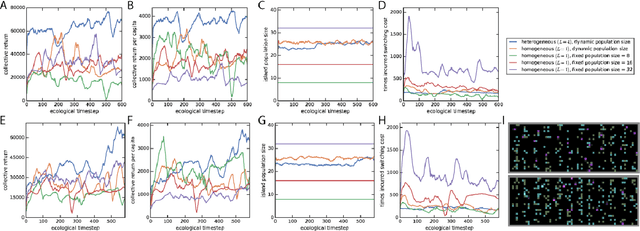
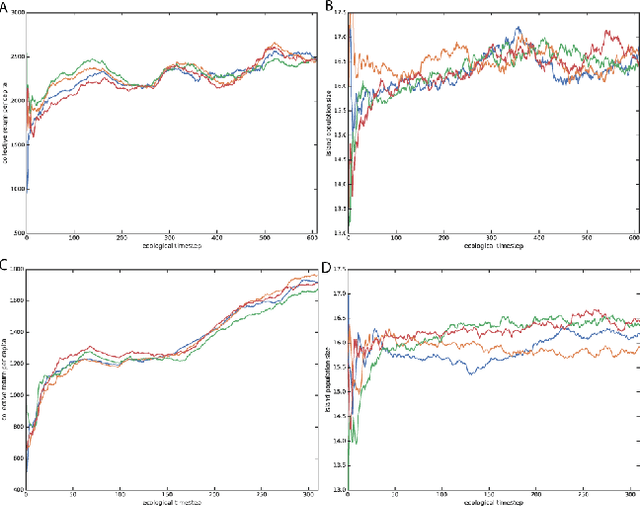
Here we explore a new algorithmic framework for multi-agent reinforcement learning, called Malthusian reinforcement learning, which extends self-play to include fitness-linked population size dynamics that drive ongoing innovation. In Malthusian RL, increases in a subpopulation's average return drive subsequent increases in its size, just as Thomas Malthus argued in 1798 was the relationship between preindustrial income levels and population growth. Malthusian reinforcement learning harnesses the competitive pressures arising from growing and shrinking population size to drive agents to explore regions of state and policy spaces that they could not otherwise reach. Furthermore, in environments where there are potential gains from specialization and division of labor, we show that Malthusian reinforcement learning is better positioned to take advantage of such synergies than algorithms based on self-play.