 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployment and Evaluation of an EHR-integrated, Large Language Model-Powered Tool to Triage Surgical Patients
Mar 18, 2026Surgical co-management (SCM) is an evidence-based model in which hospitalists jointly manage medically complex perioperative patients alongside surgical teams. Despite its clinical and financial value, SCM is limited by the need to manually identify eligible patients. To determine whether SCM triage can be automated, we conducted a prospective, unblinded study at Stanford Health Care in which an LLM-based, electronic health record (EHR)-integrated triage tool (SCM Navigator) provided SCM recommendations followed by physician review. Using pre-operative documentation, structured data, and clinical criteria for perioperative morbidity, SCM Navigator categorized patients as appropriate, not appropriate, or possibly appropriate for SCM. Faculty indicated their clinical judgment and provided free-text feedback when they disagreed. Sensitivity, specificity, positive predictive value, and negative predictive value were measured using physician determinations as a reference. Free-text reasons were thematically categorized, and manual chart review was conducted on all false-negative cases and 30 randomly selected cases from the largest false-positive category. Since deployment, 6,193 cases have been triaged, of which 1,582 (23%) were recommended for hospitalist consultation. SCM Navigator displayed high sensitivity (0.94, 95% CI 0.91-0.96) and moderate specificity (0.74, 95% CI 0.71-0.77). Post-hoc chart review suggested most discrepancies reflect modifiable gaps in clinical criteria, institutional workflow, or physician practice variability rather than LLM misclassification, which accounted for 2 of 19 (11%) false-negative cases. These findings demonstrate that an LLM-powered, EHR-integrated, human-in-the-loop AI system can accurately and safely triage surgical patients for SCM, and that AI-enabled screening tools can augment and potentially automate time-intensive clinical workflows.
Automated Detection of Gait Events and Travel Distance Using Waist-worn Accelerometers Across a Typical Range of Walking and Running Speeds
Jul 10, 2023



Background: Estimation of temporospatial clinical features of gait (CFs), such as step count and length, step duration, step frequency, gait speed and distance traveled is an important component of community-based mobility evaluation using wearable accelerometers. However, challenges arising from device complexity and availability, cost and analytical methodology have limited widespread application of such tools. Research Question: Can accelerometer data from commercially-available smartphones be used to extract gait CFs across a broad range of attainable gait velocities in children with Duchenne muscular dystrophy (DMD) and typically developing controls (TDs) using machine learning (ML)-based methods Methods: Fifteen children with DMD and 15 TDs underwent supervised clinical testing across a range of gait speeds using 10 or 25m run/walk (10MRW, 25MRW), 100m run/walk (100MRW), 6-minute walk (6MWT) and free-walk (FW) evaluations while wearing a mobile phone-based accelerometer at the waist near the body's center of mass. Gait CFs were extracted from the accelerometer data using a multi-step machine learning-based process and results were compared to ground-truth observation data. Results: Model predictions vs. observed values for step counts, distance traveled, and step length showed a strong correlation (Pearson's r = -0.9929 to 0.9986, p<0.0001). The estimates demonstrated a mean (SD) percentage error of 1.49% (7.04%) for step counts, 1.18% (9.91%) for distance traveled, and 0.37% (7.52%) for step length compared to ground truth observations for the combined 6MWT, 100MRW, and FW tasks. Significance: The study findings indicate that a single accelerometer placed near the body's center of mass can accurately measure CFs across different gait speeds in both TD and DMD peers, suggesting that there is potential for accurately measuring CFs in the community with consumer-level smartphones.
DiscoGen: Learning to Discover Gene Regulatory Networks
Apr 12, 2023Accurately inferring Gene Regulatory Networks (GRNs) is a critical and challenging task in biology. GRNs model the activatory and inhibitory interactions between genes and are inherently causal in nature. To accurately identify GRNs, perturbational data is required. However, most GRN discovery methods only operate on observational data. Recent advances in neural network-based causal discovery methods have significantly improved causal discovery, including handling interventional data, improvements in performance and scalability. However, applying state-of-the-art (SOTA) causal discovery methods in biology poses challenges, such as noisy data and a large number of samples. Thus, adapting the causal discovery methods is necessary to handle these challenges. In this paper, we introduce DiscoGen, a neural network-based GRN discovery method that can denoise gene expression measurements and handle interventional data. We demonstrate that our model outperforms SOTA neural network-based causal discovery methods.
Beyond Bayes-optimality: meta-learning what you know you don't know
Oct 12, 2022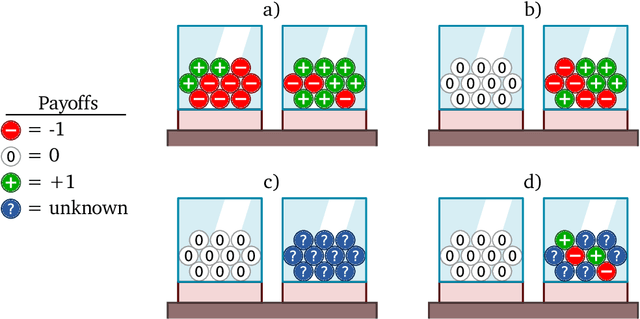



Meta-training agents with memory has been shown to culminate in Bayes-optimal agents, which casts Bayes-optimality as the implicit solution to a numerical optimization problem rather than an explicit modeling assumption. Bayes-optimal agents are risk-neutral, since they solely attune to the expected return, and ambiguity-neutral, since they act in new situations as if the uncertainty were known. This is in contrast to risk-sensitive agents, which additionally exploit the higher-order moments of the return, and ambiguity-sensitive agents, which act differently when recognizing situations in which they lack knowledge. Humans are also known to be averse to ambiguity and sensitive to risk in ways that aren't Bayes-optimal, indicating that such sensitivity can confer advantages, especially in safety-critical situations. How can we extend the meta-learning protocol to generate risk- and ambiguity-sensitive agents? The goal of this work is to fill this gap in the literature by showing that risk- and ambiguity-sensitivity also emerge as the result of an optimization problem using modified meta-training algorithms, which manipulate the experience-generation process of the learner. We empirically test our proposed meta-training algorithms on agents exposed to foundational classes of decision-making experiments and demonstrate that they become sensitive to risk and ambiguity.
Learning to Induce Causal Structure
Apr 11, 2022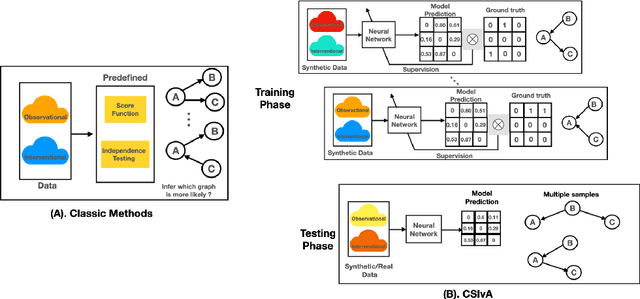
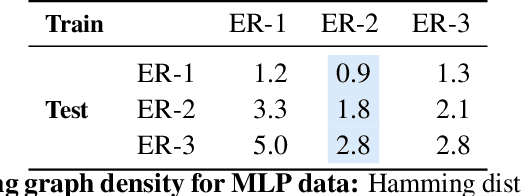
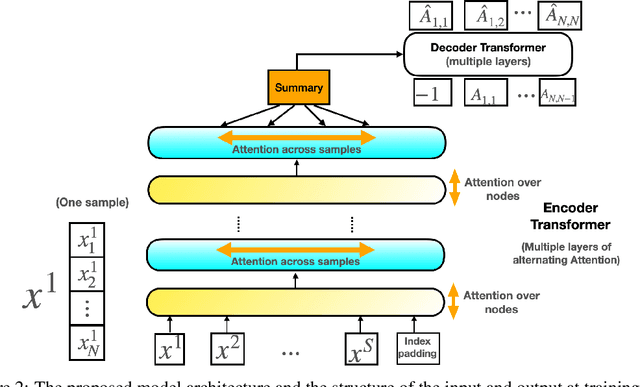
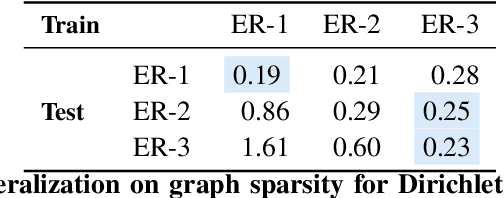
The fundamental challenge in causal induction is to infer the underlying graph structure given observational and/or interventional data. Most existing causal induction algorithms operate by generating candidate graphs and then evaluating them using either score-based methods (including continuous optimization) or independence tests. In this work, instead of proposing scoring function or independence tests, we treat the inference process as a black box and design a neural network architecture that learns the mapping from both observational and interventional data to graph structures via supervised training on synthetic graphs. We show that the proposed model generalizes not only to new synthetic graphs but also to naturalistic graphs.
An Artificial Intelligence Dataset for Solar Energy Locations in India
Jan 31, 2022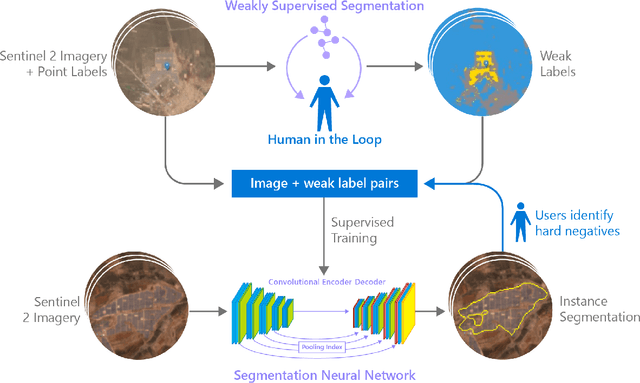
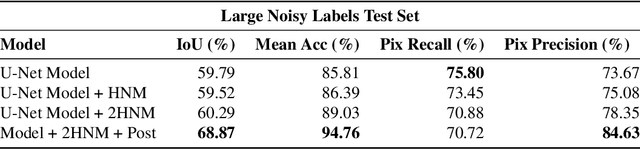


Rapid development of renewable energy sources, particularly solar photovoltaics, is critical to mitigate climate change. As a result, India has set ambitious goals to install 300 gigawatts of solar energy capacity by 2030. Given the large footprint projected to meet these renewable energy targets the potential for land use conflicts over environmental and social values is high. To expedite development of solar energy, land use planners will need access to up-to-date and accurate geo-spatial information of PV infrastructure. The majority of recent studies use either predictions of resource suitability or databases that are either developed thru crowdsourcing that often have significant sampling biases or have time lags between when projects are permitted and when location data becomes available. Here, we address this shortcoming by developing a spatially explicit machine learning model to map utility-scale solar projects across India. Using these outputs, we provide a cumulative measure of the solar footprint across India and quantified the degree of land modification associated with land cover types that may cause conflicts. Our analysis indicates that over 74\% of solar development In India was built on landcover types that have natural ecosystem preservation, and agricultural values. Thus, with a mean accuracy of 92\% this method permits the identification of the factors driving land suitability for solar projects and will be of widespread interest for studies seeking to assess trade-offs associated with the global decarbonization of green-energy systems. In the same way, our model increases the feasibility of remote sensing and long-term monitoring of renewable energy deployment targets.
Causally Correct Partial Models for Reinforcement Learning
Feb 07, 2020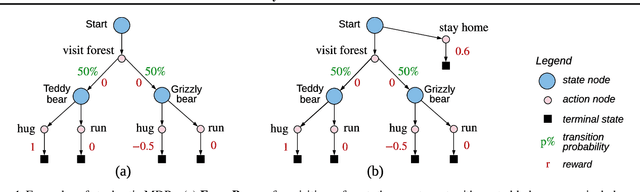


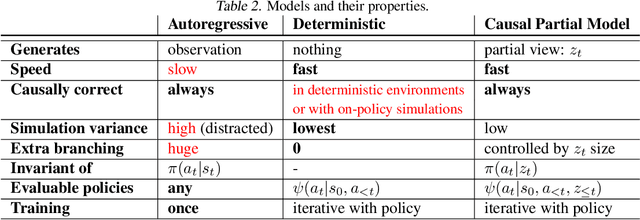
In reinforcement learning, we can learn a model of future observations and rewards, and use it to plan the agent's next actions. However, jointly modeling future observations can be computationally expensive or even intractable if the observations are high-dimensional (e.g. images). For this reason, previous works have considered partial models, which model only part of the observation. In this paper, we show that partial models can be causally incorrect: they are confounded by the observations they don't model, and can therefore lead to incorrect planning. To address this, we introduce a general family of partial models that are provably causally correct, yet remain fast because they do not need to fully model future observations.
Causal Reasoning from Meta-reinforcement Learning
Jan 23, 2019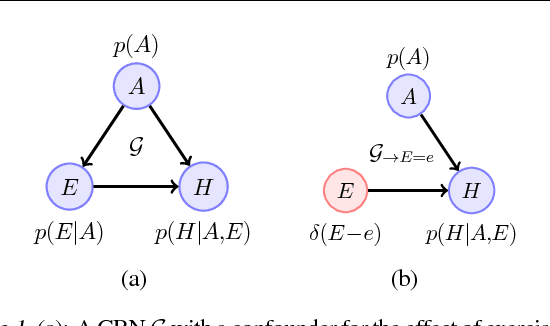


Discovering and exploiting the causal structure in the environment is a crucial challenge for intelligent agents. Here we explore whether causal reasoning can emerge via meta-reinforcement learning. We train a recurrent network with model-free reinforcement learning to solve a range of problems that each contain causal structure. We find that the trained agent can perform causal reasoning in novel situations in order to obtain rewards. The agent can select informative interventions, draw causal inferences from observational data, and make counterfactual predictions. Although established formal causal reasoning algorithms also exist, in this paper we show that such reasoning can arise from model-free reinforcement learning, and suggest that causal reasoning in complex settings may benefit from the more end-to-end learning-based approaches presented here. This work also offers new strategies for structured exploration in reinforcement learning, by providing agents with the ability to perform -- and interpret -- experiments.
Meta-Learning by the Baldwin Effect
Jun 22, 2018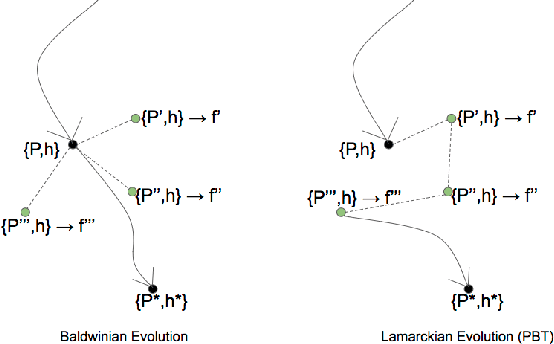
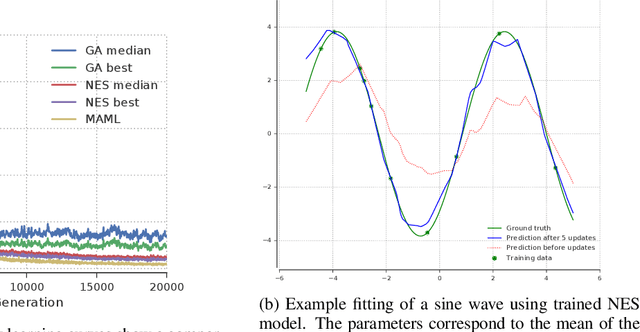
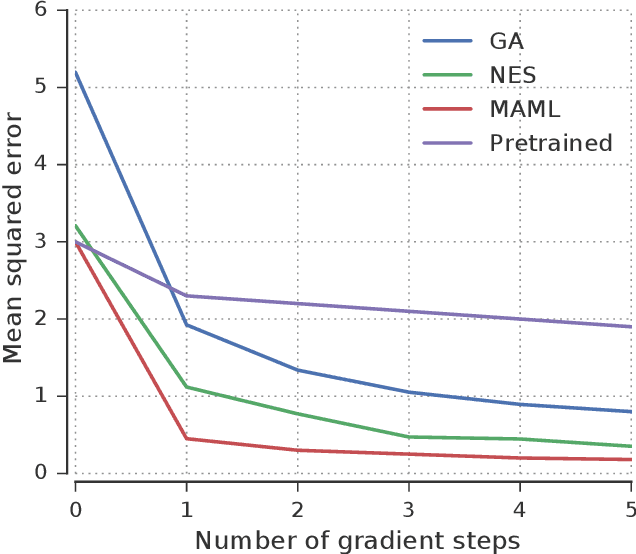
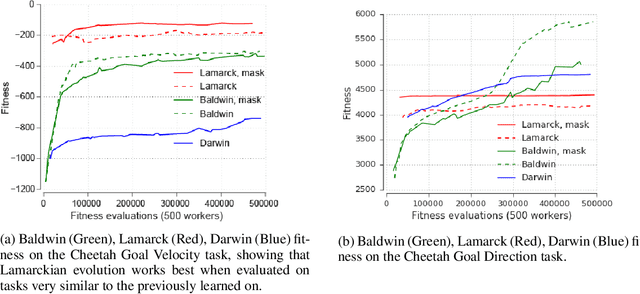
The scope of the Baldwin effect was recently called into question by two papers that closely examined the seminal work of Hinton and Nowlan. To this date there has been no demonstration of its necessity in empirically challenging tasks. Here we show that the Baldwin effect is capable of evolving few-shot supervised and reinforcement learning mechanisms, by shaping the hyperparameters and the initial parameters of deep learning algorithms. Furthermore it can genetically accommodate strong learning biases on the same set of problems as a recent machine learning algorithm called MAML "Model Agnostic Meta-Learning" which uses second-order gradients instead of evolution to learn a set of reference parameters (initial weights) that can allow rapid adaptation to tasks sampled from a distribution. Whilst in simple cases MAML is more data efficient than the Baldwin effect, the Baldwin effect is more general in that it does not require gradients to be backpropagated to the reference parameters or hyperparameters, and permits effectively any number of gradient updates in the inner loop. The Baldwin effect learns strong learning dependent biases, rather than purely genetically accommodating fixed behaviours in a learning independent manner.