 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupling Retrieval and Meta-Learning for Context-Dependent Semantic Parsing
Jun 17, 2019
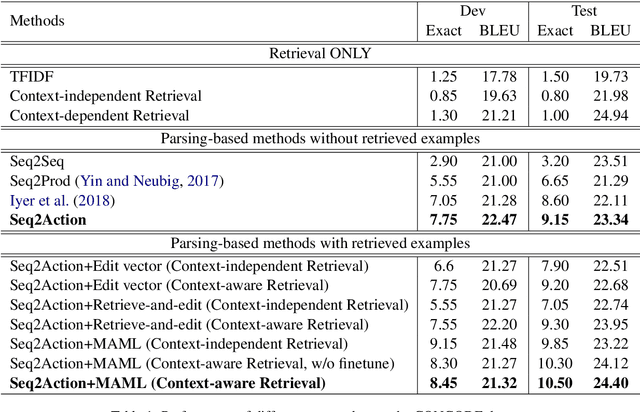
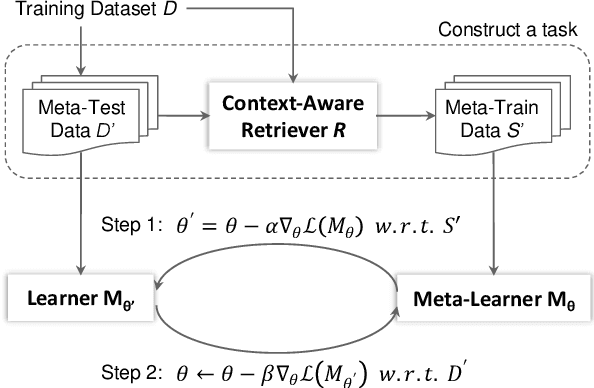
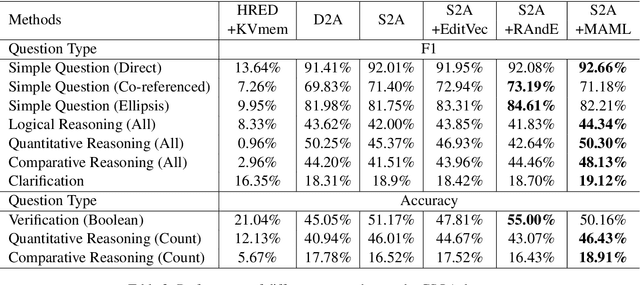
In this paper, we present an approach to incorporate retrieved datapoints as supporting evidence for context-dependent semantic parsing, such as generating source code conditioned on the class environment. Our approach naturally combines a retrieval model and a meta-learner, where the former learns to find similar datapoints from the training data, and the latter considers retrieved datapoints as a pseudo task for fast adaptation. Specifically, our retriever is a context-aware encoder-decoder model with a latent variable which takes context environment into consideration, and our meta-learner learns to utilize retrieved datapoints in a model-agnostic meta-learning paradigm for fast adaptation. We conduct experiments on CONCODE and CSQA datasets, where the context refers to class environment in JAVA codes and conversational history, respectively. We use sequence-to-action model as the base semantic parser, which performs the state-of-the-art accuracy on both datasets. Results show that both the context-aware retriever and the meta-learning strategy improve accuracy, and our approach performs better than retrieve-and-edit baselines.
Deep Reason: A Strong Baseline for Real-World Visual Reasoning
May 24, 2019
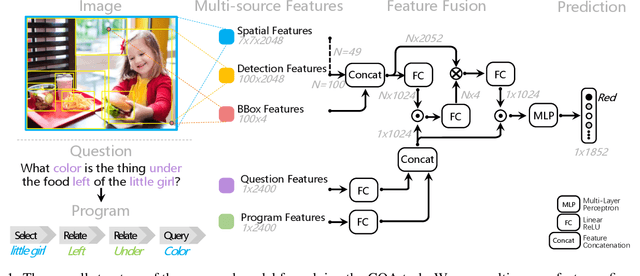


This paper presents a strong baseline for real-world visual reasoning (GQA), which achieves 60.93% in GQA 2019 challenge and won the sixth place. GQA is a large dataset with 22M questions involving spatial understanding and multi-step inference. To help further research in this area, we identified three crucial parts that improve the performance, namely: multi-source features, fine-grained encoder, and score-weighted ensemble. We provide a series of analysis on their impact on performance.
Improving Question Answering by Commonsense-Based Pre-Training
Oct 05, 2018
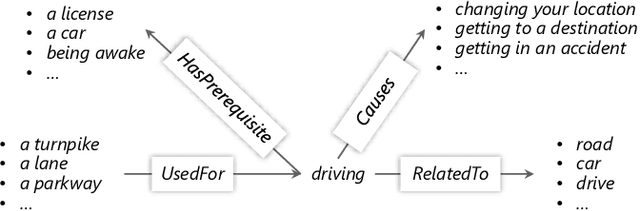
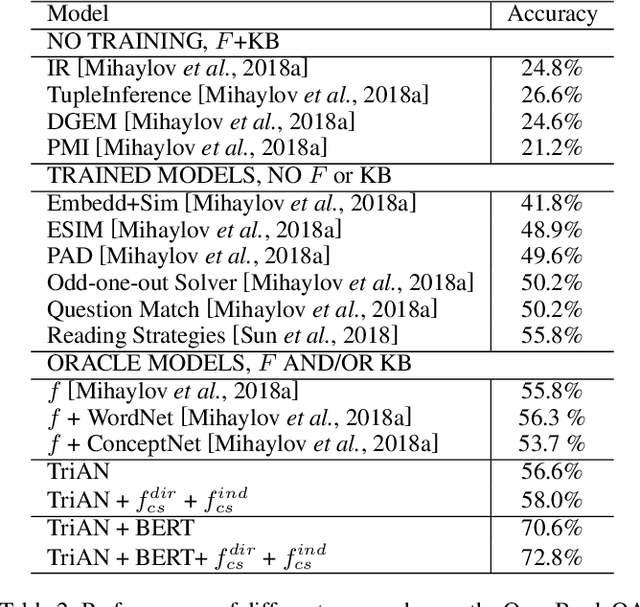
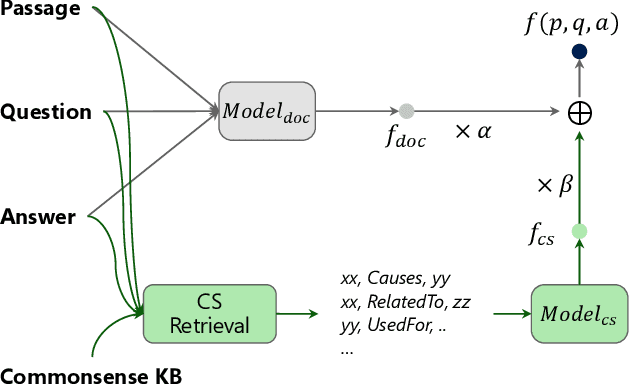
Although neural network approaches achieve remarkable success on a variety of NLP tasks, many of them struggle to answer questions that require commonsense knowledge. We believe the main reason is the lack of commonsense connections between concepts. To remedy this, we provide a simple and effective method that leverages external commonsense knowledge base such as ConceptNet. We pre-train direct and indirect relational functions between concepts, and show that these pre-trained functions could be easily added to existing neural network models. Results show that incorporating commonsense-based function improves the state-of-the-art on two question answering tasks that require commonsense reasoning. Further analysis shows that our system discovers and leverages useful evidences from an external commonsense knowledge base, which is missing in existing neural network models and help derive the correct answer.
Knowledge-Aware Conversational Semantic Parsing Over Web Tables
Sep 12, 2018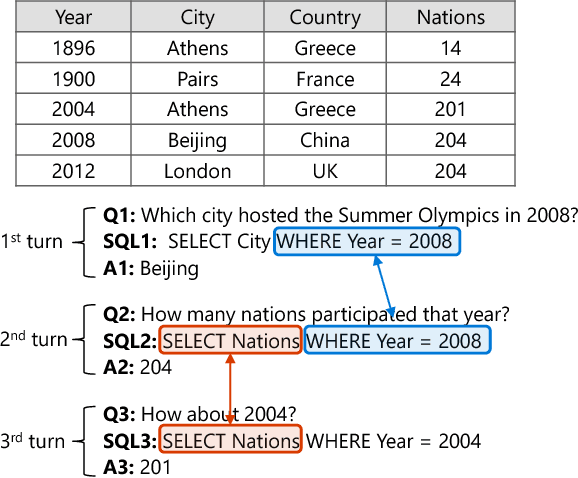

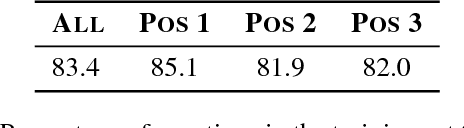
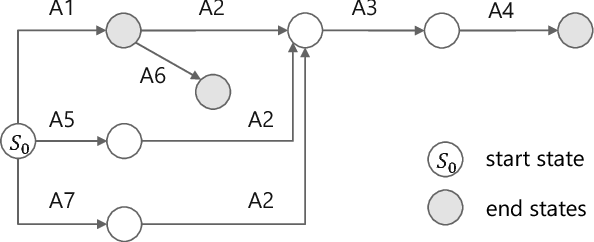
Conversational semantic parsing over tables requires knowledge acquiring and reasoning abilities, which have not been well explored by current state-of-the-art approaches. Motivated by this fact, we propose a knowledge-aware semantic parser to improve parsing performance by integrating various types of knowledge. In this paper, we consider three types of knowledge, including grammar knowledge, expert knowledge, and external resource knowledge. First, grammar knowledge empowers the model to effectively replicate previously generated logical form, which effectively handles the co-reference and ellipsis phenomena in conversation Second, based on expert knowledge, we propose a decomposable model, which is more controllable compared with traditional end-to-end models that put all the burdens of learning on trial-and-error in an end-to-end way. Third, external resource knowledge, i.e., provided by a pre-trained language model or an entity typing model, is used to improve the representation of question and table for a better semantic understanding. We conduct experiments on the SequentialQA dataset. Results show that our knowledge-aware model outperforms the state-of-the-art approaches. Incremental experimental results also prove the usefulness of various knowledge. Further analysis shows that our approach has the ability to derive the meaning representation of a context-dependent utterance by leveraging previously generated outcomes.
Knowledge Based Machine Reading Comprehension
Sep 12, 2018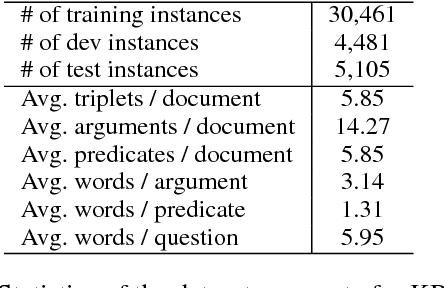
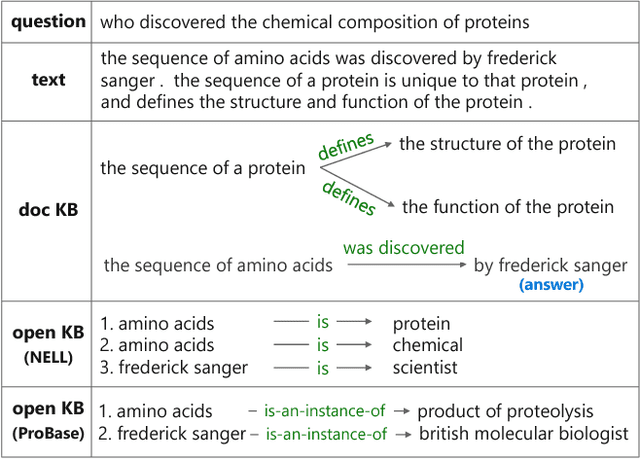
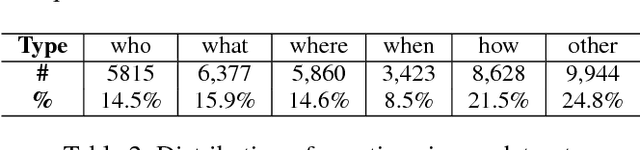
Machine reading comprehension (MRC) requires reasoning about both the knowledge involved in a document and knowledge about the world. However, existing datasets are typically dominated by questions that can be well solved by context matching, which fail to test this capability. To encourage the progress on knowledge-based reasoning in MRC, we present knowledge-based MRC in this paper, and build a new dataset consisting of 40,047 question-answer pairs. The annotation of this dataset is designed so that successfully answering the questions requires understanding and the knowledge involved in a document. We implement a framework consisting of both a question answering model and a question generation model, both of which take the knowledge extracted from the document as well as relevant facts from an external knowledge base such as Freebase/ProBase/Reverb/NELL. Results show that incorporating side information from external KB improves the accuracy of the baseline question answer system. We compare it with a standard MRC model BiDAF, and also provide the difficulty of the dataset and lay out remaining challenges.
Question Generation from SQL Queries Improves Neural Semantic Parsing
Aug 27, 2018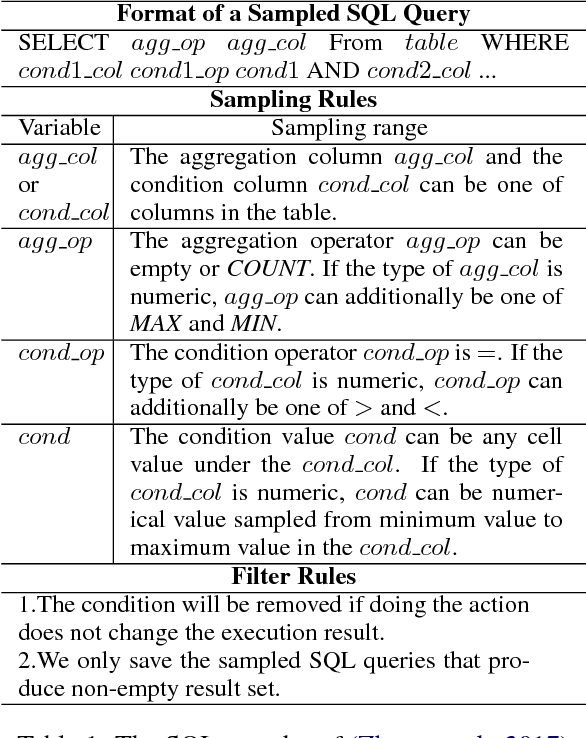
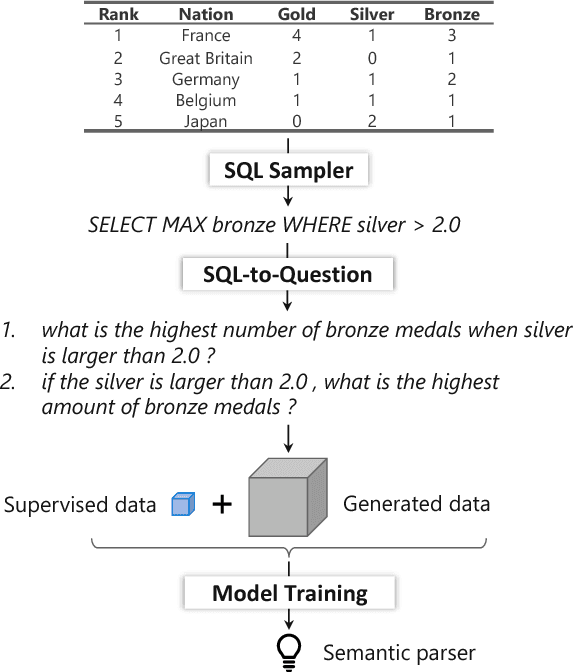
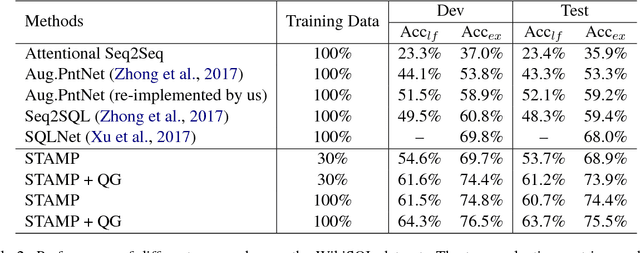
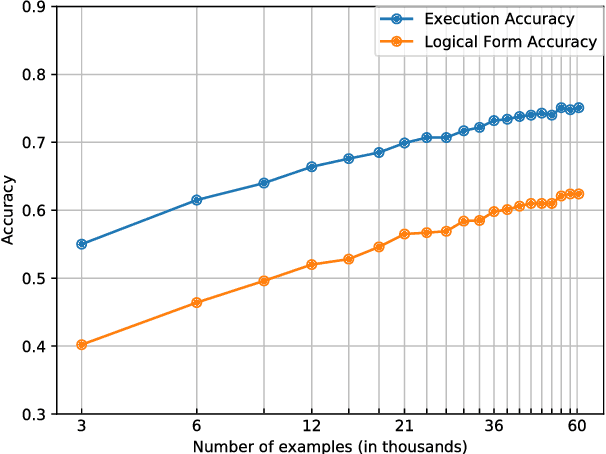
We study how to learn a semantic parser of state-of-the-art accuracy with less supervised training data. We conduct our study on WikiSQL, the largest hand-annotated semantic parsing dataset to date. First, we demonstrate that question generation is an effective method that empowers us to learn a state-of-the-art neural network based semantic parser with thirty percent of the supervised training data. Second, we show that applying question generation to the full supervised training data further improves the state-of-the-art model. In addition, we observe that there is a logarithmic relationship between the accuracy of a semantic parser and the amount of training data.
Table-to-Text: Describing Table Region with Natural Language
May 29, 2018
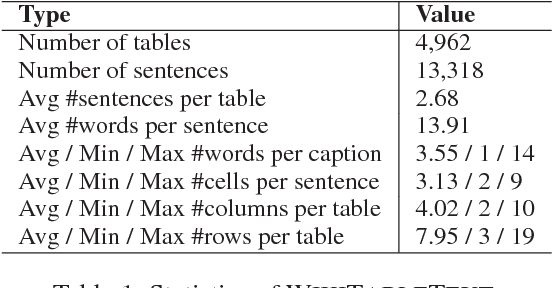
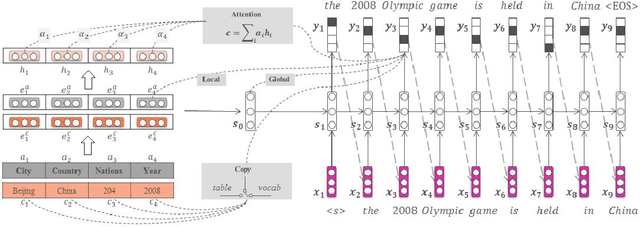

In this paper, we present a generative model to generate a natural language sentence describing a table region, e.g., a row. The model maps a row from a table to a continuous vector and then generates a natural language sentence by leveraging the semantics of a table. To deal with rare words appearing in a table, we develop a flexible copying mechanism that selectively replicates contents from the table in the output sequence. Extensive experiments demonstrate the accuracy of the model and the power of the copying mechanism. On two synthetic datasets, WIKIBIO and SIMPLEQUESTIONS, our model improves the current state-of-the-art BLEU-4 score from 34.70 to 40.26 and from 33.32 to 39.12, respectively. Furthermore, we introduce an open-domain dataset WIKITABLETEXT including 13,318 explanatory sentences for 4,962 tables. Our model achieves a BLEU-4 score of 38.23, which outperforms template based and language model based approaches.
Semantic Parsing with Syntax- and Table-Aware SQL Generation
Apr 23, 2018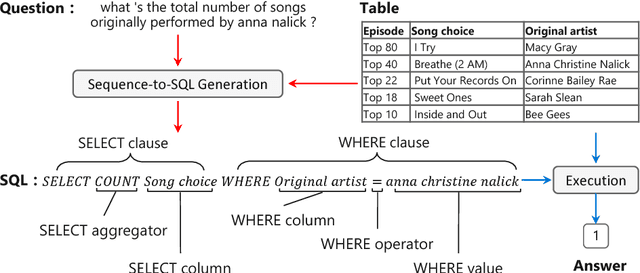
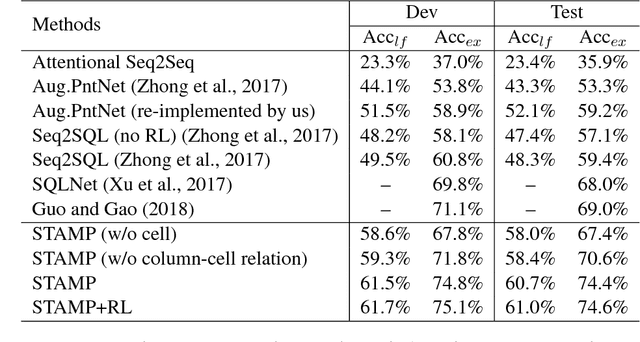
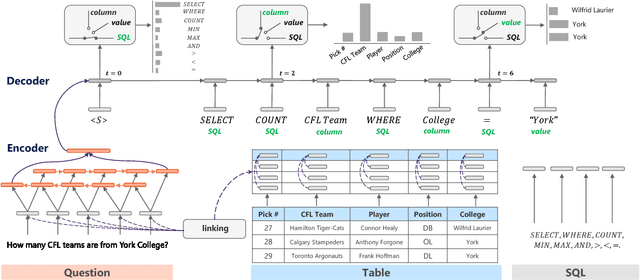

We present a generative model to map natural language questions into SQL queries. Existing neural network based approaches typically generate a SQL query word-by-word, however, a large portion of the generated results are incorrect or not executable due to the mismatch between question words and table contents. Our approach addresses this problem by considering the structure of table and the syntax of SQL language. The quality of the generated SQL query is significantly improved through (1) learning to replicate content from column names, cells or SQL keywords; and (2) improving the generation of WHERE clause by leveraging the column-cell relation. Experiments are conducted on WikiSQL, a recently released dataset with the largest question-SQL pairs. Our approach significantly improves the state-of-the-art execution accuracy from 69.0% to 74.4%.
Assertion-based QA with Question-Aware Open Information Extraction
Jan 23, 2018
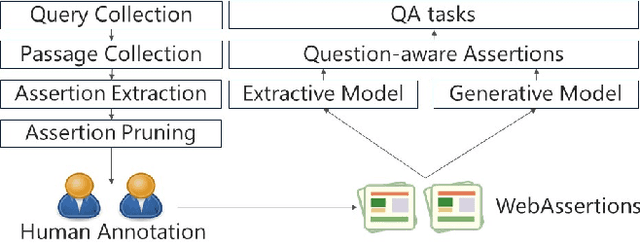

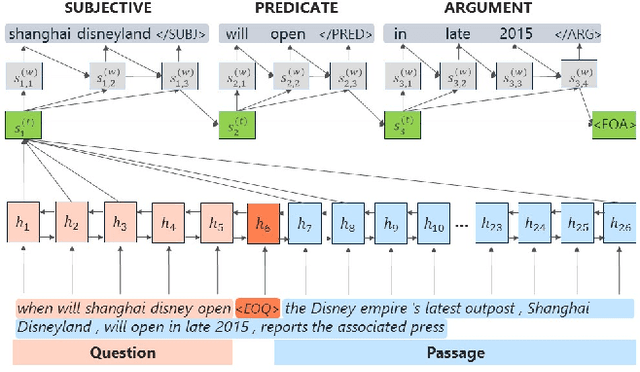
We present assertion based question answering (ABQA), an open domain question answering task that takes a question and a passage as inputs, and outputs a semi-structured assertion consisting of a subject, a predicate and a list of arguments. An assertion conveys more evidences than a short answer span in reading comprehension, and it is more concise than a tedious passage in passage-based QA. These advantages make ABQA more suitable for human-computer interaction scenarios such as voice-controlled speakers. Further progress towards improving ABQA requires richer supervised dataset and powerful models of text understanding. To remedy this, we introduce a new dataset called WebAssertions, which includes hand-annotated QA labels for 358,427 assertions in 55,960 web passages. To address ABQA, we develop both generative and extractive approaches. The backbone of our generative approach is sequence to sequence learning. In order to capture the structure of the output assertion, we introduce a hierarchical decoder that first generates the structure of the assertion and then generates the words of each field. The extractive approach is based on learning to rank. Features at different levels of granularity are designed to measure the semantic relevance between a question and an assertion. Experimental results show that our approaches have the ability to infer question-aware assertions from a passage. We further evaluate our approaches by incorporating the ABQA results as additional features in passage-based QA. Results on two datasets show that ABQA features significantly improve the accuracy on passage-based~QA.
Question Answering and Question Generation as Dual Tasks
Aug 04, 2017
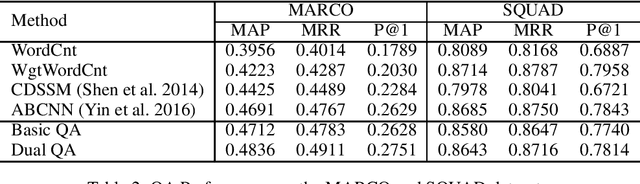

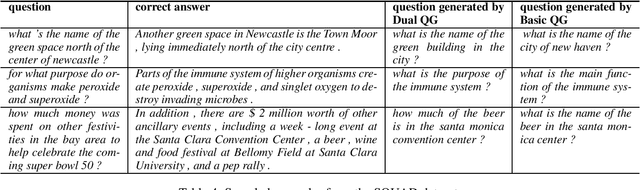
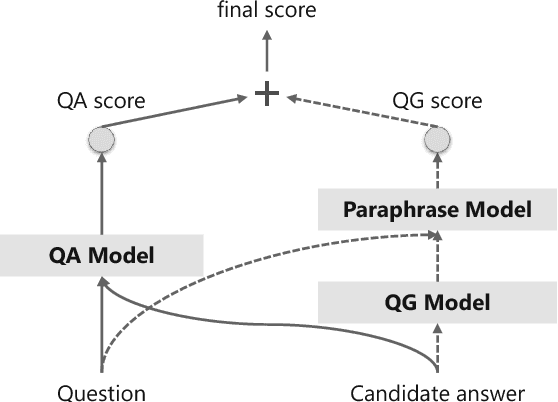
We study the problem of joint question answering (QA) and question generation (QG) in this paper. Our intuition is that QA and QG have intrinsic connections and these two tasks could improve each other. On one side, the QA model judges whether the generated question of a QG model is relevant to the answer. On the other side, the QG model provides the probability of generating a question given the answer, which is a useful evidence that in turn facilitates QA. In this paper we regard QA and QG as dual tasks. We propose a training framework that trains the models of QA and QG simultaneously, and explicitly leverages their probabilistic correlation to guide the training process of both models. We implement a QG model based on sequence-to-sequence learning, and a QA model based on recurrent neural network. As all the components of the QA and QG models are differentiable, all the parameters involved in these two models could be conventionally learned with back propagation. We conduct experiments on three datasets. Empirical results show that our training framework improves both QA and QG tasks. The improved QA model performs comparably with strong baseline approaches on all three datasets.