 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerVLA: Steering Vision-Language-Action Models in Long-Tail Driving Scenarios
Feb 09, 2026A fundamental challenge in autonomous driving is the integration of high-level, semantic reasoning for long-tail events with low-level, reactive control for robust driving. While large vision-language models (VLMs) trained on web-scale data offer powerful common-sense reasoning, they lack the grounded experience necessary for safe vehicle control. We posit that an effective autonomous agent should leverage the world knowledge of VLMs to guide a steerable driving policy toward robust control in driving scenarios. To this end, we propose SteerVLA, which leverages the reasoning capabilities of VLMs to produce fine-grained language instructions that steer a vision-language-action (VLA) driving policy. Key to our method is this rich language interface between the high-level VLM and low-level VLA, which allows the high-level policy to more effectively ground its reasoning in the control outputs of the low-level policy. To provide fine-grained language supervision aligned with vehicle control, we leverage a VLM to augment existing driving data with detailed language annotations, which we find to be essential for effective reasoning and steerability. We evaluate SteerVLA on a challenging closed-loop benchmark, where it outperforms state-of-the-art methods by 4.77 points in overall driving score and by 8.04 points on a long-tail subset. The project website is available at: https://steervla.github.io/.
TQL: Scaling Q-Functions with Transformers by Preventing Attention Collapse
Feb 01, 2026Despite scale driving substantial recent advancements in machine learning, reinforcement learning (RL) methods still primarily use small value functions. Naively scaling value functions -- including with a transformer architecture, which is known to be highly scalable -- often results in learning instability and worse performance. In this work, we ask what prevents transformers from scaling effectively for value functions? Through empirical analysis, we identify the critical failure mode in this scaling: attention scores collapse as capacity increases. Our key insight is that we can effectively prevent this collapse and stabilize training by controlling the entropy of the attention scores, thereby enabling the use of larger models. To this end, we propose Transformer Q-Learning (TQL), a method that unlocks the scaling potential of transformers in learning value functions in RL. Our approach yields up to a 43% improvement in performance when scaling from the smallest to the largest network sizes, while prior methods suffer from performance degradation.
RoboCade: Gamifying Robot Data Collection
Dec 24, 2025Imitation learning from human demonstrations has become a dominant approach for training autonomous robot policies. However, collecting demonstration datasets is costly: it often requires access to robots and needs sustained effort in a tedious, long process. These factors limit the scale of data available for training policies. We aim to address this scalability challenge by involving a broader audience in a gamified data collection experience that is both accessible and motivating. Specifically, we develop a gamified remote teleoperation platform, RoboCade, to engage general users in collecting data that is beneficial for downstream policy training. To do this, we embed gamification strategies into the design of the system interface and data collection tasks. In the system interface, we include components such as visual feedback, sound effects, goal visualizations, progress bars, leaderboards, and badges. We additionally propose principles for constructing gamified tasks that have overlapping structure with useful downstream target tasks. We instantiate RoboCade on three manipulation tasks -- including spatial arrangement, scanning, and insertion. To illustrate the viability of gamified robot data collection, we collect a demonstration dataset through our platform, and show that co-training robot policies with this data can improve success rate on non-gamified target tasks (+16-56%). Further, we conduct a user study to validate that novice users find the gamified platform significantly more enjoyable than a standard non-gamified platform (+24%). These results highlight the promise of gamified data collection as a scalable, accessible, and engaging method for collecting demonstration data.
EXPO: Stable Reinforcement Learning with Expressive Policies
Jul 10, 2025We study the problem of training and fine-tuning expressive policies with online reinforcement learning (RL) given an offline dataset. Training expressive policy classes with online RL present a unique challenge of stable value maximization. Unlike simpler Gaussian policies commonly used in online RL, expressive policies like diffusion and flow-matching policies are parameterized by a long denoising chain, which hinders stable gradient propagation from actions to policy parameters when optimizing against some value function. Our key insight is that we can address stable value maximization by avoiding direct optimization over value with the expressive policy and instead construct an on-the-fly RL policy to maximize Q-value. We propose Expressive Policy Optimization (EXPO), a sample-efficient online RL algorithm that utilizes an on-the-fly policy to maximize value with two parameterized policies -- a larger expressive base policy trained with a stable imitation learning objective and a light-weight Gaussian edit policy that edits the actions sampled from the base policy toward a higher value distribution. The on-the-fly policy optimizes the actions from the base policy with the learned edit policy and chooses the value maximizing action from the base and edited actions for both sampling and temporal-difference (TD) backup. Our approach yields up to 2-3x improvement in sample efficiency on average over prior methods both in the setting of fine-tuning a pretrained policy given offline data and in leveraging offline data to train online.
Scaffolding Dexterous Manipulation with Vision-Language Models
Jun 24, 2025



Dexterous robotic hands are essential for performing complex manipulation tasks, yet remain difficult to train due to the challenges of demonstration collection and high-dimensional control. While reinforcement learning (RL) can alleviate the data bottleneck by generating experience in simulation, it typically relies on carefully designed, task-specific reward functions, which hinder scalability and generalization. Thus, contemporary works in dexterous manipulation have often bootstrapped from reference trajectories. These trajectories specify target hand poses that guide the exploration of RL policies and object poses that enable dense, task-agnostic rewards. However, sourcing suitable trajectories - particularly for dexterous hands - remains a significant challenge. Yet, the precise details in explicit reference trajectories are often unnecessary, as RL ultimately refines the motion. Our key insight is that modern vision-language models (VLMs) already encode the commonsense spatial and semantic knowledge needed to specify tasks and guide exploration effectively. Given a task description (e.g., "open the cabinet") and a visual scene, our method uses an off-the-shelf VLM to first identify task-relevant keypoints (e.g., handles, buttons) and then synthesize 3D trajectories for hand motion and object motion. Subsequently, we train a low-level residual RL policy in simulation to track these coarse trajectories or "scaffolds" with high fidelity. Across a number of simulated tasks involving articulated objects and semantic understanding, we demonstrate that our method is able to learn robust dexterous manipulation policies. Moreover, we showcase that our method transfers to real-world robotic hands without any human demonstrations or handcrafted rewards.
ProVox: Personalization and Proactive Planning for Situated Human-Robot Collaboration
Jun 13, 2025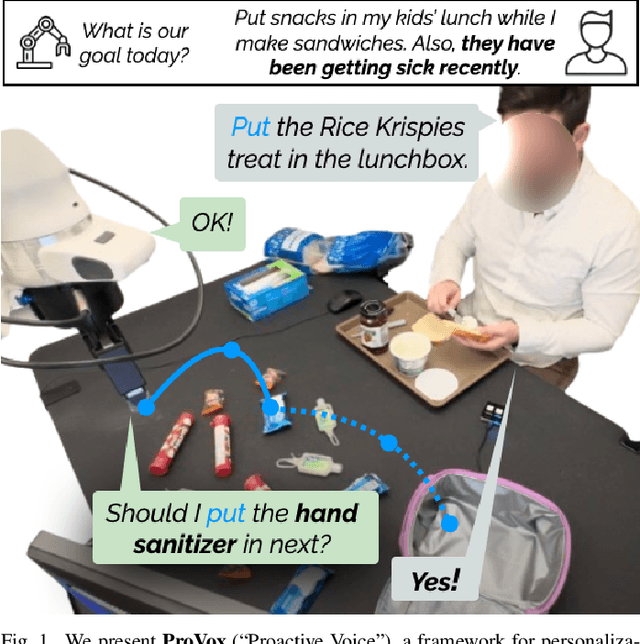
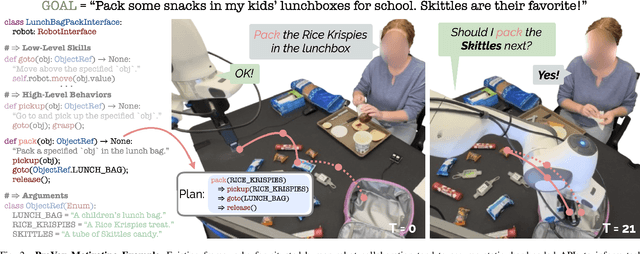
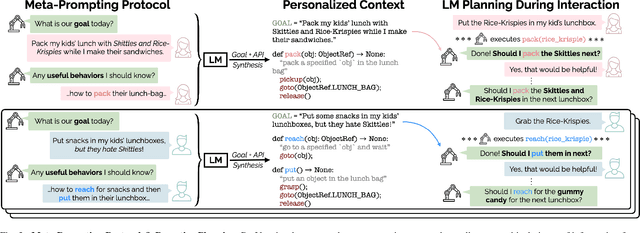

Collaborative robots must quickly adapt to their partner's intent and preferences to proactively identify helpful actions. This is especially true in situated settings where human partners can continually teach robots new high-level behaviors, visual concepts, and physical skills (e.g., through demonstration), growing the robot's capabilities as the human-robot pair work together to accomplish diverse tasks. In this work, we argue that robots should be able to infer their partner's goals from early interactions and use this information to proactively plan behaviors ahead of explicit instructions from the user. Building from the strong commonsense priors and steerability of large language models, we introduce ProVox ("Proactive Voice"), a novel framework that enables robots to efficiently personalize and adapt to individual collaborators. We design a meta-prompting protocol that empowers users to communicate their distinct preferences, intent, and expected robot behaviors ahead of starting a physical interaction. ProVox then uses the personalized prompt to condition a proactive language model task planner that anticipates a user's intent from the current interaction context and robot capabilities to suggest helpful actions; in doing so, we alleviate user burden, minimizing the amount of time partners spend explicitly instructing and supervising the robot. We evaluate ProVox through user studies grounded in household manipulation tasks (e.g., assembling lunch bags) that measure the efficiency of the collaboration, as well as features such as perceived helpfulness, ease of use, and reliability. Our analysis suggests that both meta-prompting and proactivity are critical, resulting in 38.7% faster task completion times and 31.9% less user burden relative to non-active baselines. Supplementary material, code, and videos can be found at https://provox-2025.github.io.
Bridging Perception and Action: Spatially-Grounded Mid-Level Representations for Robot Generalization
Jun 06, 2025In this work, we investigate how spatially grounded auxiliary representations can provide both broad, high-level grounding as well as direct, actionable information to improve policy learning performance and generalization for dexterous tasks. We study these mid-level representations across three critical dimensions: object-centricity, pose-awareness, and depth-awareness. We use these interpretable mid-level representations to train specialist encoders via supervised learning, then feed them as inputs to a diffusion policy to solve dexterous bimanual manipulation tasks in the real world. We propose a novel mixture-of-experts policy architecture that combines multiple specialized expert models, each trained on a distinct mid-level representation, to improve policy generalization. This method achieves an average success rate that is 11% higher than a language-grounded baseline and 24 percent higher than a standard diffusion policy baseline on our evaluation tasks. Furthermore, we find that leveraging mid-level representations as supervision signals for policy actions within a weighted imitation learning algorithm improves the precision with which the policy follows these representations, yielding an additional performance increase of 10%. Our findings highlight the importance of grounding robot policies not only with broad perceptual tasks but also with more granular, actionable representations. For further information and videos, please visit https://mid-level-moe.github.io.
What Matters for Batch Online Reinforcement Learning in Robotics?
May 12, 2025The ability to learn from large batches of autonomously collected data for policy improvement -- a paradigm we refer to as batch online reinforcement learning -- holds the promise of enabling truly scalable robot learning by significantly reducing the need for human effort of data collection while getting benefits from self-improvement. Yet, despite the promise of this paradigm, it remains challenging to achieve due to algorithms not being able to learn effectively from the autonomous data. For example, prior works have applied imitation learning and filtered imitation learning methods to the batch online RL problem, but these algorithms often fail to efficiently improve from the autonomously collected data or converge quickly to a suboptimal point. This raises the question of what matters for effective batch online RL in robotics. Motivated by this question, we perform a systematic empirical study of three axes -- (i) algorithm class, (ii) policy extraction methods, and (iii) policy expressivity -- and analyze how these axes affect performance and scaling with the amount of autonomous data. Through our analysis, we make several observations. First, we observe that the use of Q-functions to guide batch online RL significantly improves performance over imitation-based methods. Building on this, we show that an implicit method of policy extraction -- via choosing the best action in the distribution of the policy -- is necessary over traditional policy extraction methods from offline RL. Next, we show that an expressive policy class is preferred over less expressive policy classes. Based on this analysis, we propose a general recipe for effective batch online RL. We then show a simple addition to the recipe of using temporally-correlated noise to obtain more diversity results in further performance gains. Our recipe obtains significantly better performance and scaling compared to prior methods.
Diffusion Models are Secretly Exchangeable: Parallelizing DDPMs via Autospeculation
May 06, 2025Denoising Diffusion Probabilistic Models (DDPMs) have emerged as powerful tools for generative modeling. However, their sequential computation requirements lead to significant inference-time bottlenecks. In this work, we utilize the connection between DDPMs and Stochastic Localization to prove that, under an appropriate reparametrization, the increments of DDPM satisfy an exchangeability property. This general insight enables near-black-box adaptation of various performance optimization techniques from autoregressive models to the diffusion setting. To demonstrate this, we introduce \emph{Autospeculative Decoding} (ASD), an extension of the widely used speculative decoding algorithm to DDPMs that does not require any auxiliary draft models. Our theoretical analysis shows that ASD achieves a $\tilde{O} (K^{\frac{1}{3}})$ parallel runtime speedup over the $K$ step sequential DDPM. We also demonstrate that a practical implementation of autospeculative decoding accelerates DDPM inference significantly in various domains.
Latent Diffusion Planning for Imitation Learning
Apr 23, 2025Recent progress in imitation learning has been enabled by policy architectures that scale to complex visuomotor tasks, multimodal distributions, and large datasets. However, these methods often rely on learning from large amount of expert demonstrations. To address these shortcomings, we propose Latent Diffusion Planning (LDP), a modular approach consisting of a planner which can leverage action-free demonstrations, and an inverse dynamics model which can leverage suboptimal data, that both operate over a learned latent space. First, we learn a compact latent space through a variational autoencoder, enabling effective forecasting of future states in image-based domains. Then, we train a planner and an inverse dynamics model with diffusion objectives. By separating planning from action prediction, LDP can benefit from the denser supervision signals of suboptimal and action-free data. On simulated visual robotic manipulation tasks, LDP outperforms state-of-the-art imitation learning approaches, as they cannot leverage such additional data.