 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqTrack: Sequence to Sequence Learning for Visual Object Tracking
Apr 27, 2023In this paper, we present a new sequence-to-sequence learning framework for visual tracking, dubbed SeqTrack. It casts visual tracking as a sequence generation problem, which predicts object bounding boxes in an autoregressive fashion. This is different from prior Siamese trackers and transformer trackers, which rely on designing complicated head networks, such as classification and regression heads. SeqTrack only adopts a simple encoder-decoder transformer architecture. The encoder extracts visual features with a bidirectional transformer, while the decoder generates a sequence of bounding box values autoregressively with a causal transformer. The loss function is a plain cross-entropy. Such a sequence learning paradigm not only simplifies tracking framework, but also achieves competitive performance on benchmarks. For instance, SeqTrack gets 72.5% AUC on LaSOT, establishing a new state-of-the-art performance. Code and models are available at here.
MDDL: A Framework for Reinforcement Learning-based Position Allocation in Multi-Channel Feed
Apr 17, 2023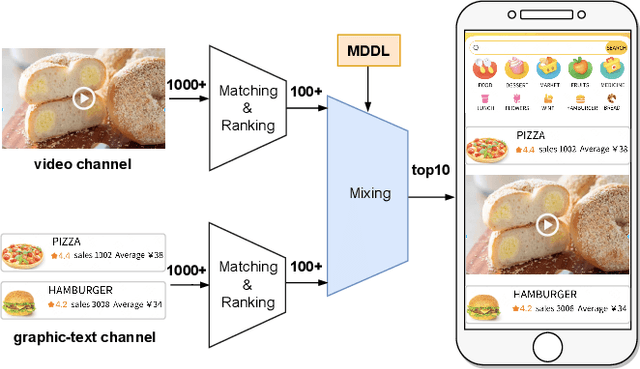

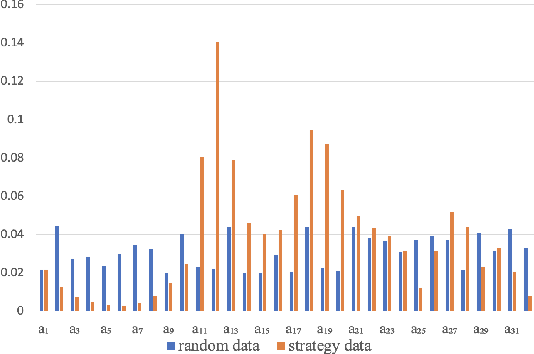
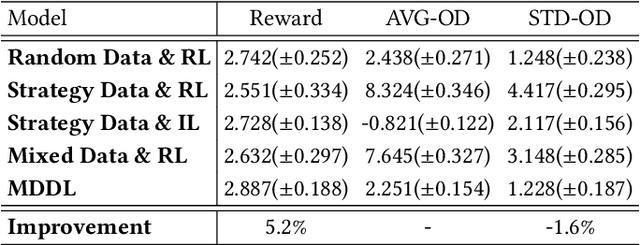
Nowadays, the mainstream approach in position allocation system is to utilize a reinforcement learning model to allocate appropriate locations for items in various channels and then mix them into the feed. There are two types of data employed to train reinforcement learning (RL) model for position allocation, named strategy data and random data. Strategy data is collected from the current online model, it suffers from an imbalanced distribution of state-action pairs, resulting in severe overestimation problems during training. On the other hand, random data offers a more uniform distribution of state-action pairs, but is challenging to obtain in industrial scenarios as it could negatively impact platform revenue and user experience due to random exploration. As the two types of data have different distributions, designing an effective strategy to leverage both types of data to enhance the efficacy of the RL model training has become a highly challenging problem. In this study, we propose a framework named Multi-Distribution Data Learning (MDDL) to address the challenge of effectively utilizing both strategy and random data for training RL models on mixed multi-distribution data. Specifically, MDDL incorporates a novel imitation learning signal to mitigate overestimation problems in strategy data and maximizes the RL signal for random data to facilitate effective learning. In our experiments, we evaluated the proposed MDDL framework in a real-world position allocation system and demonstrated its superior performance compared to the previous baseline. MDDL has been fully deployed on the Meituan food delivery platform and currently serves over 300 million users.
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
Apr 11, 2023Talking head generation aims to generate faces that maintain the identity information of the source image and imitate the motion of the driving image. Most pioneering methods rely primarily on 2D representations and thus will inevitably suffer from face distortion when large head rotations are encountered. Recent works instead employ explicit 3D structural representations or implicit neural rendering to improve performance under large pose changes. Nevertheless, the fidelity of identity and expression is not so desirable, especially for novel-view synthesis. In this paper, we propose HiDe-NeRF, which achieves high-fidelity and free-view talking-head synthesis. Drawing on the recently proposed Deformable Neural Radiance Fields, HiDe-NeRF represents the 3D dynamic scene into a canonical appearance field and an implicit deformation field, where the former comprises the canonical source face and the latter models the driving pose and expression. In particular, we improve fidelity from two aspects: (i) to enhance identity expressiveness, we design a generalized appearance module that leverages multi-scale volume features to preserve face shape and details; (ii) to improve expression preciseness, we propose a lightweight deformation module that explicitly decouples the pose and expression to enable precise expression modeling. Extensive experiments demonstrate that our proposed approach can generate better results than previous works. Project page: https://www.waytron.net/hidenerf/
ViewRefer: Grasp the Multi-view Knowledge for 3D Visual Grounding with GPT and Prototype Guidance
Apr 06, 2023Understanding 3D scenes from multi-view inputs has been proven to alleviate the view discrepancy issue in 3D visual grounding. However, existing methods normally neglect the view cues embedded in the text modality and fail to weigh the relative importance of different views. In this paper, we propose ViewRefer, a multi-view framework for 3D visual grounding exploring how to grasp the view knowledge from both text and 3D modalities. For the text branch, ViewRefer leverages the diverse linguistic knowledge of large-scale language models, e.g., GPT, to expand a single grounding text to multiple geometry-consistent descriptions. Meanwhile, in the 3D modality, a transformer fusion module with inter-view attention is introduced to boost the interaction of objects across views. On top of that, we further present a set of learnable multi-view prototypes, which memorize scene-agnostic knowledge for different views, and enhance the framework from two perspectives: a view-guided attention module for more robust text features, and a view-guided scoring strategy during the final prediction. With our designed paradigm, ViewRefer achieves superior performance on three benchmarks and surpasses the second-best by +2.8%, +1.2%, and +0.73% on Sr3D, Nr3D, and ScanRefer. Code will be released at https://github.com/ZiyuGuo99/ViewRefer3D.
Towards Nonlinear-Motion-Aware and Occlusion-Robust Rolling Shutter Correction
Apr 04, 2023



This paper addresses the problem of rolling shutter correction in complex nonlinear and dynamic scenes with extreme occlusion. Existing methods suffer from two main drawbacks. Firstly, they face challenges in estimating the accurate correction field due to the uniform velocity assumption, leading to significant image correction errors under complex motion. Secondly, the drastic occlusion in dynamic scenes prevents current solutions from achieving better image quality because of the inherent difficulties in aligning and aggregating multiple frames. To tackle these challenges, we model the curvilinear trajectory of pixels analytically and propose a geometry-based Quadratic Rolling Shutter (QRS) motion solver, which precisely estimates the high-order correction field of individual pixel. Besides, to reconstruct high-quality occlusion frames in dynamic scenes, we present a 3D video architecture that effectively Aligns and Aggregates multi-frame context, namely, RSA^2-Net. We evaluate our method across a broad range of cameras and video sequences, demonstrating its significant superiority. Specifically, our method surpasses the state-of-the-arts by +4.98, +0.77, and +4.33 of PSNR on Carla-RS, Fastec-RS, and BS-RSC datasets, respectively.
Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement
Apr 03, 2023



The popularity of Contrastive Language-Image Pre-training (CLIP) has propelled its application to diverse downstream vision tasks. To improve its capacity on downstream tasks, few-shot learning has become a widely-adopted technique. However, existing methods either exhibit limited performance or suffer from excessive learnable parameters. In this paper, we propose APE, an Adaptive Prior rEfinement method for CLIP's pre-trained knowledge, which achieves superior accuracy with high computational efficiency. Via a prior refinement module, we analyze the inter-class disparity in the downstream data and decouple the domain-specific knowledge from the CLIP-extracted cache model. On top of that, we introduce two model variants, a training-free APE and a training-required APE-T. We explore the trilateral affinities between the test image, prior cache model, and textual representations, and only enable a lightweight category-residual module to be trained. For the average accuracy over 11 benchmarks, both APE and APE-T attain state-of-the-art and respectively outperform the second-best by +1.59% and +1.99% under 16 shots with x30 less learnable parameters.
Fully Self-Supervised Depth Estimation from Defocus Clue
Mar 27, 2023



Depth-from-defocus (DFD), modeling the relationship between depth and defocus pattern in images, has demonstrated promising performance in depth estimation. Recently, several self-supervised works try to overcome the difficulties in acquiring accurate depth ground-truth. However, they depend on the all-in-focus (AIF) images, which cannot be captured in real-world scenarios. Such limitation discourages the applications of DFD methods. To tackle this issue, we propose a completely self-supervised framework that estimates depth purely from a sparse focal stack. We show that our framework circumvents the needs for the depth and AIF image ground-truth, and receives superior predictions, thus closing the gap between the theoretical success of DFD works and their applications in the real world. In particular, we propose (i) a more realistic setting for DFD tasks, where no depth or AIF image ground-truth is available; (ii) a novel self-supervision framework that provides reliable predictions of depth and AIF image under the challenging setting. The proposed framework uses a neural model to predict the depth and AIF image, and utilizes an optical model to validate and refine the prediction. We verify our framework on three benchmark datasets with rendered focal stacks and real focal stacks. Qualitative and quantitative evaluations show that our method provides a strong baseline for self-supervised DFD tasks.
Propagate And Calibrate: Real-time Passive Non-line-of-sight Tracking
Mar 27, 2023Non-line-of-sight (NLOS) tracking has drawn increasing attention in recent years, due to its ability to detect object motion out of sight. Most previous works on NLOS tracking rely on active illumination, e.g., laser, and suffer from high cost and elaborate experimental conditions. Besides, these techniques are still far from practical application due to oversimplified settings. In contrast, we propose a purely passive method to track a person walking in an invisible room by only observing a relay wall, which is more in line with real application scenarios, e.g., security. To excavate imperceptible changes in videos of the relay wall, we introduce difference frames as an essential carrier of temporal-local motion messages. In addition, we propose PAC-Net, which consists of alternating propagation and calibration, making it capable of leveraging both dynamic and static messages on a frame-level granularity. To evaluate the proposed method, we build and publish the first dynamic passive NLOS tracking dataset, NLOS-Track, which fills the vacuum of realistic NLOS datasets. NLOS-Track contains thousands of NLOS video clips and corresponding trajectories. Both real-shot and synthetic data are included. Our codes and dataset are available at https://againstentropy.github.io/NLOS-Track/.
Visual Prompt Multi-Modal Tracking
Mar 25, 2023



Visible-modal object tracking gives rise to a series of downstream multi-modal tracking tributaries. To inherit the powerful representations of the foundation model, a natural modus operandi for multi-modal tracking is full fine-tuning on the RGB-based parameters. Albeit effective, this manner is not optimal due to the scarcity of downstream data and poor transferability, etc. In this paper, inspired by the recent success of the prompt learning in language models, we develop Visual Prompt multi-modal Tracking (ViPT), which learns the modal-relevant prompts to adapt the frozen pre-trained foundation model to various downstream multimodal tracking tasks. ViPT finds a better way to stimulate the knowledge of the RGB-based model that is pre-trained at scale, meanwhile only introducing a few trainable parameters (less than 1% of model parameters). ViPT outperforms the full fine-tuning paradigm on multiple downstream tracking tasks including RGB+Depth, RGB+Thermal, and RGB+Event tracking. Extensive experiments show the potential of visual prompt learning for multi-modal tracking, and ViPT can achieve state-of-the-art performance while satisfying parameter efficiency. Code and models are available at https://github.com/jiawen-zhu/ViPT.
Dual Memory Aggregation Network for Event-Based Object Detection with Learnable Representation
Mar 17, 2023



Event-based cameras are bio-inspired sensors that capture brightness change of every pixel in an asynchronous manner. Compared with frame-based sensors, event cameras have microsecond-level latency and high dynamic range, hence showing great potential for object detection under high-speed motion and poor illumination conditions. Due to sparsity and asynchronism nature with event streams, most of existing approaches resort to hand-crafted methods to convert event data into 2D grid representation. However, they are sub-optimal in aggregating information from event stream for object detection. In this work, we propose to learn an event representation optimized for event-based object detection. Specifically, event streams are divided into grids in the x-y-t coordinates for both positive and negative polarity, producing a set of pillars as 3D tensor representation. To fully exploit information with event streams to detect objects, a dual-memory aggregation network (DMANet) is proposed to leverage both long and short memory along event streams to aggregate effective information for object detection. Long memory is encoded in the hidden state of adaptive convLSTMs while short memory is modeled by computing spatial-temporal correlation between event pillars at neighboring time intervals. Extensive experiments on the recently released event-based automotive detection dataset demonstrate the effectiveness of the proposed method.