 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Decision Transformer for Offline Safe Reinforcement Learning
Feb 14, 2023



Safe reinforcement learning (RL) trains a constraint satisfaction policy by interacting with the environment. We aim to tackle a more challenging problem: learning a safe policy from an offline dataset. We study the offline safe RL problem from a novel multi-objective optimization perspective and propose the $\epsilon$-reducible concept to characterize problem difficulties. The inherent trade-offs between safety and task performance inspire us to propose the constrained decision transformer (CDT) approach, which can dynamically adjust the trade-offs during deployment. Extensive experiments show the advantages of the proposed method in learning an adaptive, safe, robust, and high-reward policy. CDT outperforms its variants and strong offline safe RL baselines by a large margin with the same hyperparameters across all tasks, while keeping the zero-shot adaptation capability to different constraint thresholds, making our approach more suitable for real-world RL under constraints.
Interpolation for Robust Learning: Data Augmentation on Geodesics
Feb 07, 2023We propose to study and promote the robustness of a model as per its performance through the interpolation of training data distributions. Specifically, (1) we augment the data by finding the worst-case Wasserstein barycenter on the geodesic connecting subpopulation distributions of different categories. (2) We regularize the model for smoother performance on the continuous geodesic path connecting subpopulation distributions. (3) Additionally, we provide a theoretical guarantee of robustness improvement and investigate how the geodesic location and the sample size contribute, respectively. Experimental validations of the proposed strategy on four datasets, including CIFAR-100 and ImageNet, establish the efficacy of our method, e.g., our method improves the baselines' certifiable robustness on CIFAR10 up to $7.7\%$, with $16.8\%$ on empirical robustness on CIFAR-100. Our work provides a new perspective of model robustness through the lens of Wasserstein geodesic-based interpolation with a practical off-the-shelf strategy that can be combined with existing robust training methods.
Learning to View: Decision Transformers for Active Object Detection
Jan 23, 2023



Active perception describes a broad class of techniques that couple planning and perception systems to move the robot in a way to give the robot more information about the environment. In most robotic systems, perception is typically independent of motion planning. For example, traditional object detection is passive: it operates only on the images it receives. However, we have a chance to improve the results if we allow planning to consume detection signals and move the robot to collect views that maximize the quality of the results. In this paper, we use reinforcement learning (RL) methods to control the robot in order to obtain images that maximize the detection quality. Specifically, we propose using a Decision Transformer with online fine-tuning, which first optimizes the policy with a pre-collected expert dataset and then improves the learned policy by exploring better solutions in the environment. We evaluate the performance of proposed method on an interactive dataset collected from an indoor scenario simulator. Experimental results demonstrate that our method outperforms all baselines, including expert policy and pure offline RL methods. We also provide exhaustive analyses of the reward distribution and observation space.
Transfer Knowledge from Natural Language to Electrocardiography: Can We Detect Cardiovascular Disease Through Language Models?
Jan 21, 2023



Recent advancements in Large Language Models (LLMs) have drawn increasing attention since the learned embeddings pretrained on large-scale datasets have shown powerful ability in various downstream applications. However, whether the learned knowledge by LLMs can be transferred to clinical cardiology remains unknown. In this work, we aim to bridge this gap by transferring the knowledge of LLMs to clinical Electrocardiography (ECG). We propose an approach for cardiovascular disease diagnosis and automatic ECG diagnosis report generation. We also introduce an additional loss function by Optimal Transport (OT) to align the distribution between ECG and language embedding. The learned embeddings are evaluated on two downstream tasks: (1) automatic ECG diagnosis report generation, and (2) zero-shot cardiovascular disease detection. Our approach is able to generate high-quality cardiac diagnosis reports and also achieves competitive zero-shot classification performance even compared with supervised baselines, which proves the feasibility of transferring knowledge from LLMs to the cardiac domain.
Are Multimodal Models Robust to Image and Text Perturbations?
Dec 15, 2022



Multimodal image-text models have shown remarkable performance in the past few years. However, evaluating their robustness against distribution shifts is crucial before adopting them in real-world applications. In this paper, we investigate the robustness of 9 popular open-sourced image-text models under common perturbations on five tasks (image-text retrieval, visual reasoning, visual entailment, image captioning, and text-to-image generation). In particular, we propose several new multimodal robustness benchmarks by applying 17 image perturbation and 16 text perturbation techniques on top of existing datasets. We observe that multimodal models are not robust to image and text perturbations, especially to image perturbations. Among the tested perturbation methods, character-level perturbations constitute the most severe distribution shift for text, and zoom blur is the most severe shift for image data. We also introduce two new robustness metrics (MMI and MOR) for proper evaluations of multimodal models. We hope our extensive study sheds light on new directions for the development of robust multimodal models.
Curriculum Reinforcement Learning using Optimal Transport via Gradual Domain Adaptation
Oct 18, 2022

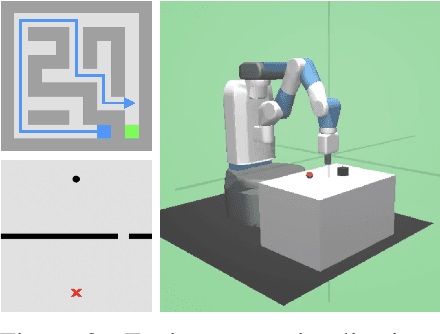
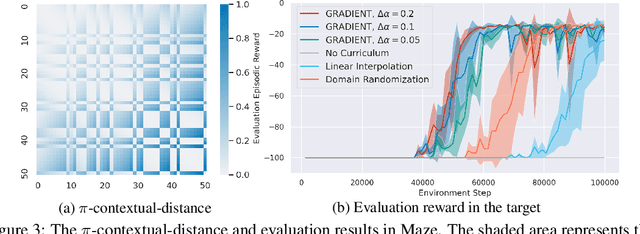
Curriculum Reinforcement Learning (CRL) aims to create a sequence of tasks, starting from easy ones and gradually learning towards difficult tasks. In this work, we focus on the idea of framing CRL as interpolations between a source (auxiliary) and a target task distribution. Although existing studies have shown the great potential of this idea, it remains unclear how to formally quantify and generate the movement between task distributions. Inspired by the insights from gradual domain adaptation in semi-supervised learning, we create a natural curriculum by breaking down the potentially large task distributional shift in CRL into smaller shifts. We propose GRADIENT, which formulates CRL as an optimal transport problem with a tailored distance metric between tasks. Specifically, we generate a sequence of task distributions as a geodesic interpolation (i.e., Wasserstein barycenter) between the source and target distributions. Different from many existing methods, our algorithm considers a task-dependent contextual distance metric and is capable of handling nonparametric distributions in both continuous and discrete context settings. In addition, we theoretically show that GRADIENT enables smooth transfer between subsequent stages in the curriculum under certain conditions. We conduct extensive experiments in locomotion and manipulation tasks and show that our proposed GRADIENT achieves higher performance than baselines in terms of learning efficiency and asymptotic performance.
LiveSeg: Unsupervised Multimodal Temporal Segmentation of Long Livestream Videos
Oct 12, 2022
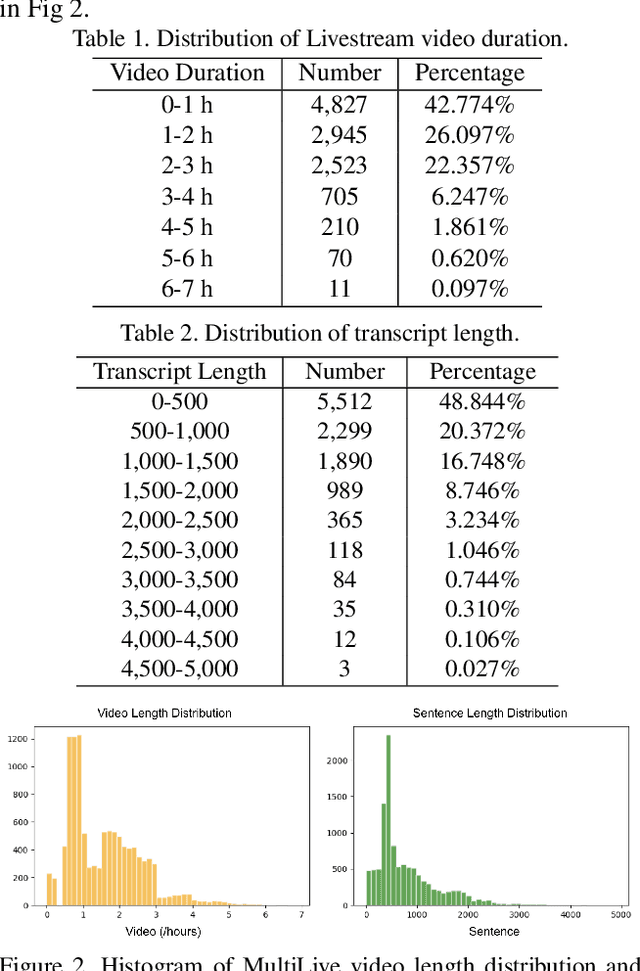
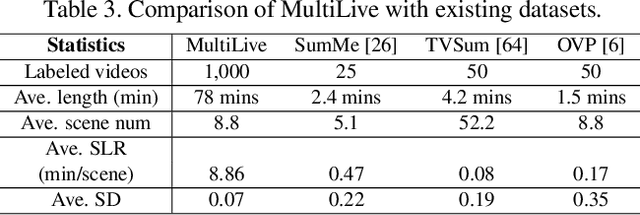
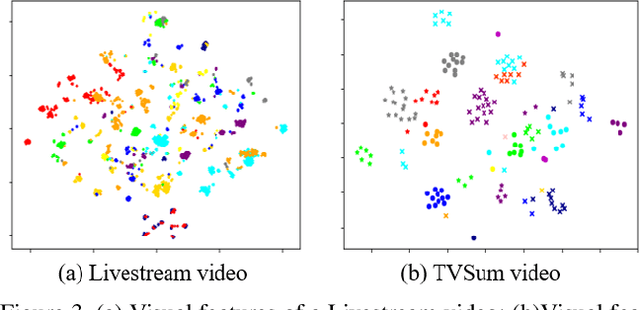
Livestream videos have become a significant part of online learning, where design, digital marketing, creative painting, and other skills are taught by experienced experts in the sessions, making them valuable materials. However, Livestream tutorial videos are usually hours long, recorded, and uploaded to the Internet directly after the live sessions, making it hard for other people to catch up quickly. An outline will be a beneficial solution, which requires the video to be temporally segmented according to topics. In this work, we introduced a large Livestream video dataset named MultiLive, and formulated the temporal segmentation of the long Livestream videos (TSLLV) task. We propose LiveSeg, an unsupervised Livestream video temporal Segmentation solution, which takes advantage of multimodal features from different domains. Our method achieved a $16.8\%$ F1-score performance improvement compared with the state-of-the-art method.
Semantics-Consistent Cross-domain Summarization via Optimal Transport Alignment
Oct 10, 2022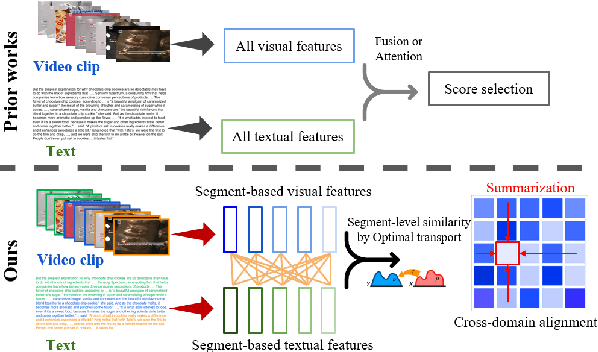
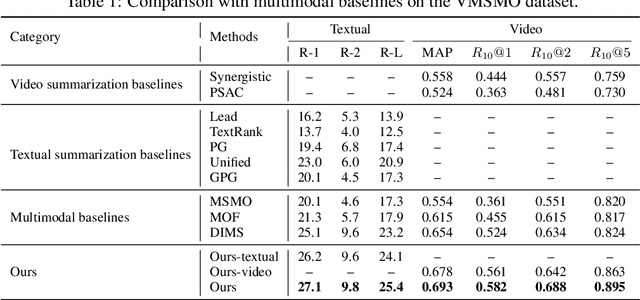
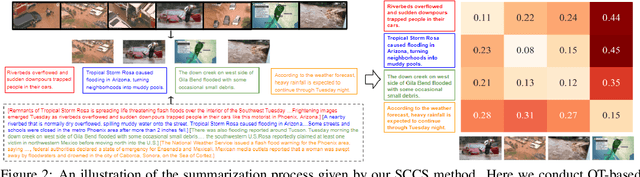
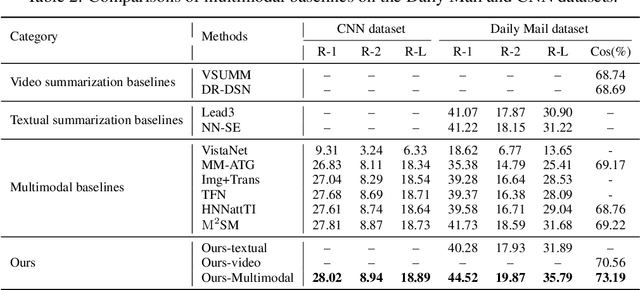
Multimedia summarization with multimodal output (MSMO) is a recently explored application in language grounding. It plays an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. However, existing methods extract features from the whole video and article and use fusion methods to select the representative one, thus usually ignoring the critical structure and varying semantics. In this work, we propose a Semantics-Consistent Cross-domain Summarization (SCCS) model based on optimal transport alignment with visual and textual segmentation. In specific, our method first decomposes both video and article into segments in order to capture the structural semantics, respectively. Then SCCS follows a cross-domain alignment objective with optimal transport distance, which leverages multimodal interaction to match and select the visual and textual summary. We evaluated our method on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.
Robustness Certification of Visual Perception Models via Camera Motion Smoothing
Oct 04, 2022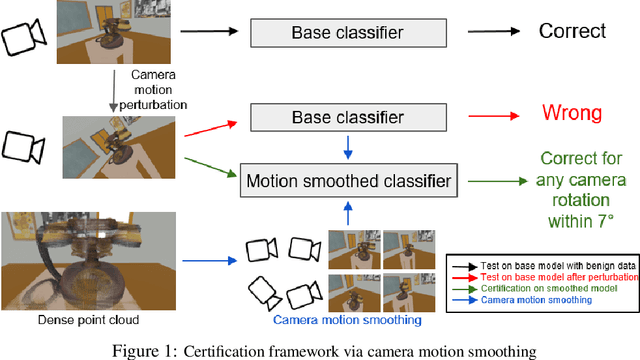
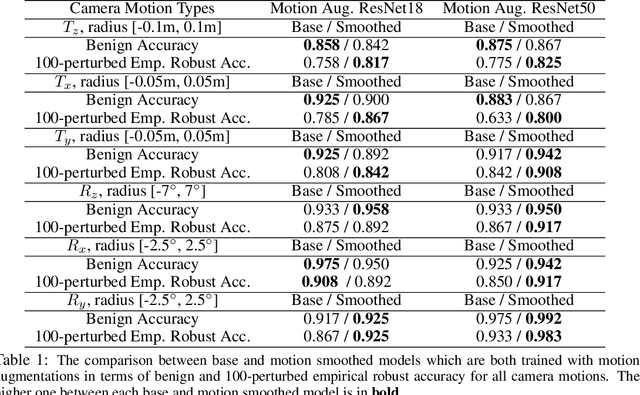
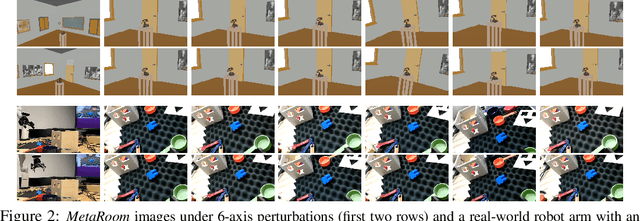
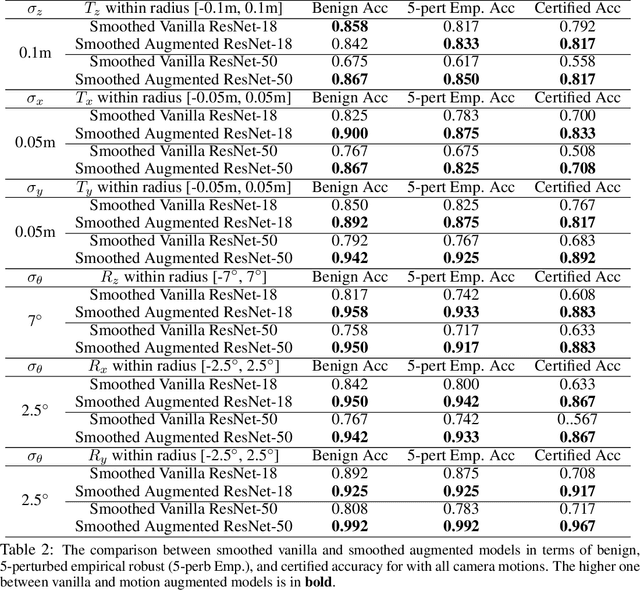
A vast literature shows that the learning-based visual perception model is sensitive to adversarial noises but few works consider the robustness of robotic perception models under widely-existing camera motion perturbations. To this end, we study the robustness of the visual perception model under camera motion perturbations to investigate the influence of camera motion on robotic perception. Specifically, we propose a motion smoothing technique for arbitrary image classification models, whose robustness under camera motion perturbations could be certified. The proposed robustness certification framework based on camera motion smoothing provides tight and scalable robustness guarantees for visual perception modules so that they are applicable to wide robotic applications. As far as we are aware, this is the first work to provide the robustness certification for the deep perception module against camera motions, which improves the trustworthiness of robotic perception. A realistic indoor robotic dataset with the dense point cloud map for the entire room, MetaRoom, is introduced for the challenging certifiable robust perception task. We conduct extensive experiments to validate the certification approach via motion smoothing against camera motion perturbations. Our framework guarantees the certified accuracy of 81.7% against camera translation perturbation along depth direction within -0.1m ` 0.1m. We also validate the effectiveness of our method on the real-world robot by conducting hardware experiment on the robotic arm with an eye-in-hand camera. The code is available on https://github.com/HanjiangHu/camera-motion-smoothing.
Trustworthy Reinforcement Learning Against Intrinsic Vulnerabilities: Robustness, Safety, and Generalizability
Sep 16, 2022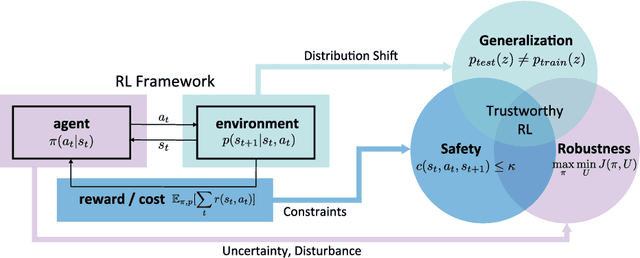
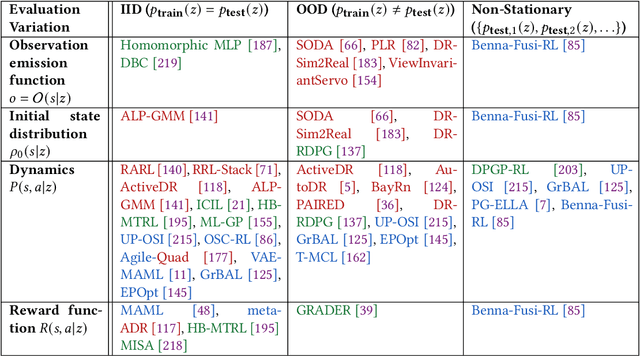
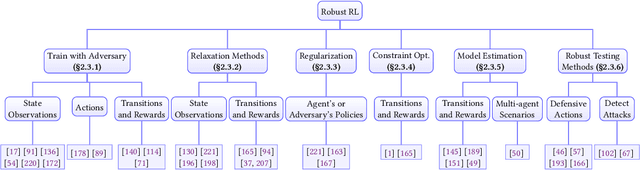
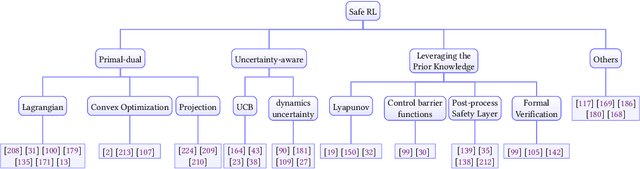
A trustworthy reinforcement learning algorithm should be competent in solving challenging real-world problems, including {robustly} handling uncertainties, satisfying {safety} constraints to avoid catastrophic failures, and {generalizing} to unseen scenarios during deployments. This study aims to overview these main perspectives of trustworthy reinforcement learning considering its intrinsic vulnerabilities on robustness, safety, and generalizability. In particular, we give rigorous formulations, categorize corresponding methodologies, and discuss benchmarks for each perspective. Moreover, we provide an outlook section to spur promising future directions with a brief discussion on extrinsic vulnerabilities considering human feedback. We hope this survey could bring together separate threads of studies together in a unified framework and promote the trustworthiness of reinforcement learning.