 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspectives on Sim2Real Transfer for Robotics: A Summary of the R:SS 2020 Workshop
Dec 07, 2020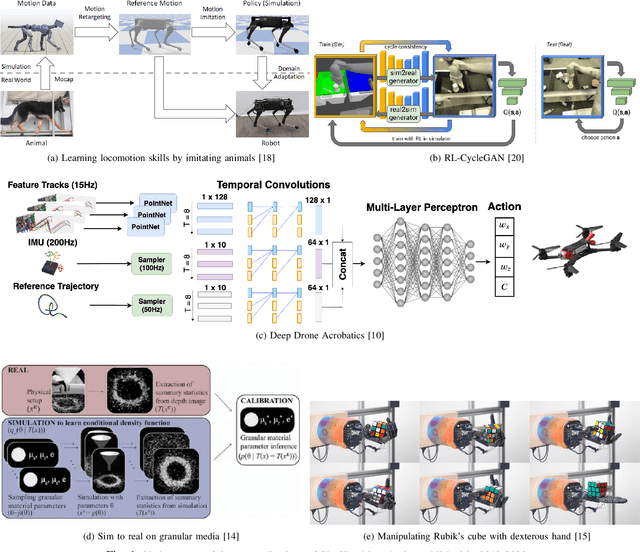
This report presents the debates, posters, and discussions of the Sim2Real workshop held in conjunction with the 2020 edition of the "Robotics: Science and System" conference. Twelve leaders of the field took competing debate positions on the definition, viability, and importance of transferring skills from simulation to the real world in the context of robotics problems. The debaters also joined a large panel discussion, answering audience questions and outlining the future of Sim2Real in robotics. Furthermore, we invited extended abstracts to this workshop which are summarized in this report. Based on the workshop, this report concludes with directions for practitioners exploiting this technology and for researchers further exploring open problems in this area.
Object Rearrangement Using Learned Implicit Collision Functions
Nov 21, 2020
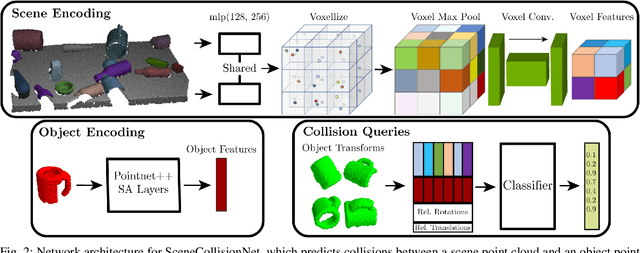
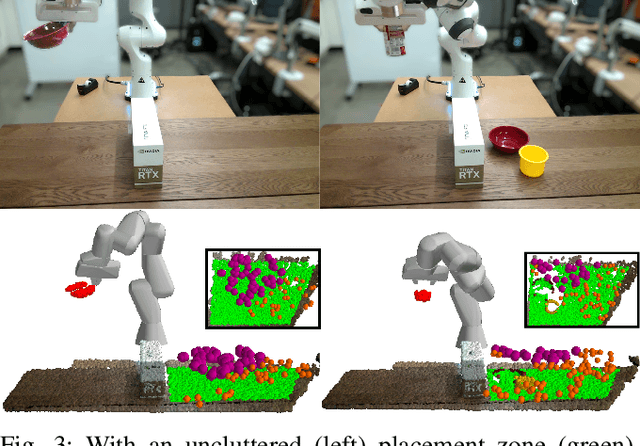
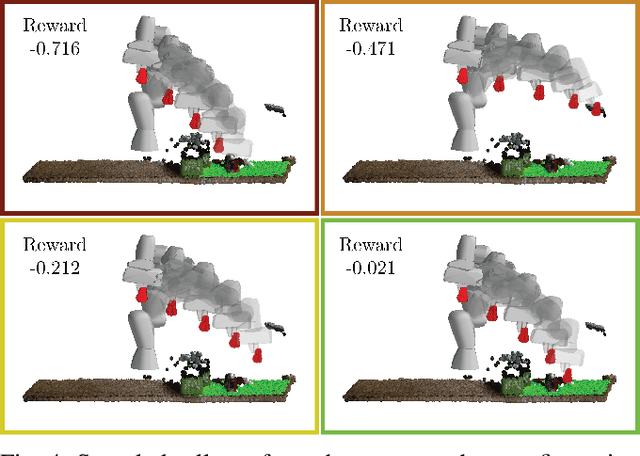
Robotic object rearrangement combines the skills of picking and placing objects. When object models are unavailable, typical collision-checking models may be unable to predict collisions in partial point clouds with occlusions, making generation of collision-free grasping or placement trajectories challenging. We propose a learned collision model that accepts scene and query object point clouds and predicts collisions for 6DOF object poses within the scene. We train the model on a synthetic set of 1 million scene/object point cloud pairs and 2 billion collision queries. We leverage the learned collision model as part of a model predictive path integral (MPPI) policy in a tabletop rearrangement task and show that the policy can plan collision-free grasps and placements for objects unseen in training in both simulated and physical cluttered scenes with a Franka Panda robot. The learned model outperforms both traditional pipelines and learned ablations by 9.8% in accuracy on a dataset of simulated collision queries and is 75x faster than the best-performing baseline. Videos and supplementary material are available at https://sites.google.com/nvidia.com/scenecollisionnet.
ACRONYM: A Large-Scale Grasp Dataset Based on Simulation
Nov 18, 2020
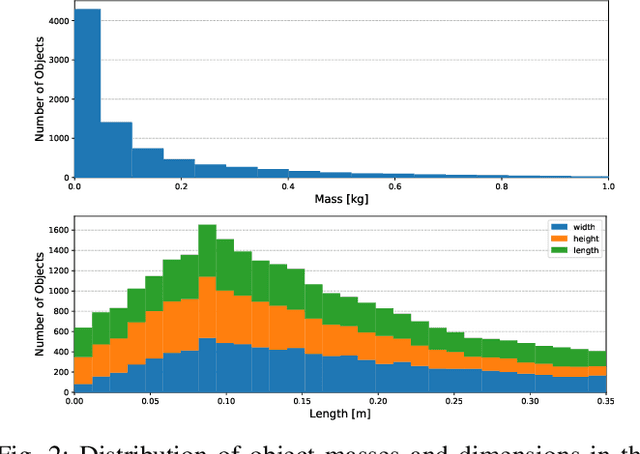
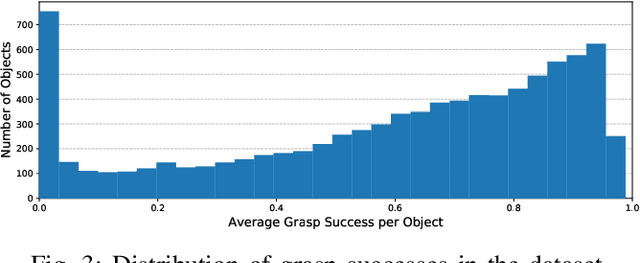

We introduce ACRONYM, a dataset for robot grasp planning based on physics simulation. The dataset contains 17.7M parallel-jaw grasps, spanning 8872 objects from 262 different categories, each labeled with the grasp result obtained from a physics simulator. We show the value of this large and diverse dataset by using it to train two state-of-the-art learning-based grasp planning algorithms. Grasp performance improves significantly when compared to the original smaller dataset. Data and tools can be accessed at https://sites.google.com/nvidia.com/graspdataset.
A User's Guide to Calibrating Robotics Simulators
Nov 17, 2020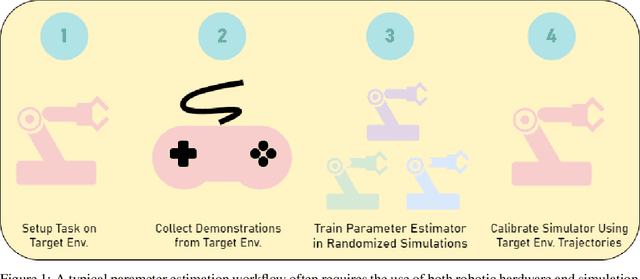



Simulators are a critical component of modern robotics research. Strategies for both perception and decision making can be studied in simulation first before deployed to real world systems, saving on time and costs. Despite significant progress on the development of sim-to-real algorithms, the analysis of different methods is still conducted in an ad-hoc manner, without a consistent set of tests and metrics for comparison. This paper fills this gap and proposes a set of benchmarks and a framework for the study of various algorithms aimed to transfer models and policies learnt in simulation to the real world. We conduct experiments on a wide range of well known simulated environments to characterize and offer insights into the performance of different algorithms. Our analysis can be useful for practitioners working in this area and can help make informed choices about the behavior and main properties of sim-to-real algorithms. We open-source the benchmark, training data, and trained models, which can be found at https://github.com/NVlabs/sim-parameter-estimation.
Reactive Human-to-Robot Handovers of Arbitrary Objects
Nov 17, 2020
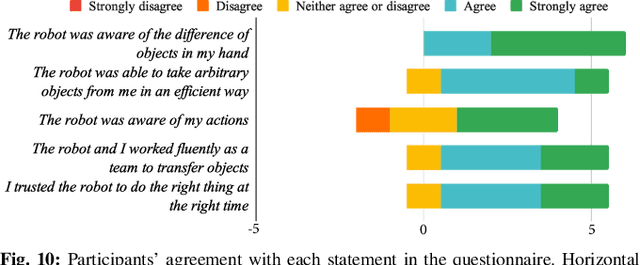
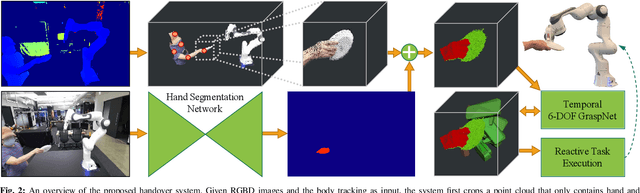

Human-robot object handovers have been an actively studied area of robotics over the past decade; however, very few techniques and systems have addressed the challenge of handing over diverse objects with arbitrary appearance, size, shape, and rigidity. In this paper, we present a vision-based system that enables reactive human-to-robot handovers of unknown objects. Our approach combines closed-loop motion planning with real-time, temporally-consistent grasp generation to ensure reactivity and motion smoothness. Our system is robust to different object positions and orientations, and can grasp both rigid and non-rigid objects. We demonstrate the generalizability, usability, and robustness of our approach on a novel benchmark set of 26 diverse household objects, a user study with naive users (N=6) handing over a subset of 15 objects, and a systematic evaluation examining different ways of handing objects. More results and videos can be found at https://sites.google.com/nvidia.com/handovers-of-arbitrary-objects.
Sim-to-Real Task Planning and Execution from Perception via Reactivity and Recovery
Nov 17, 2020
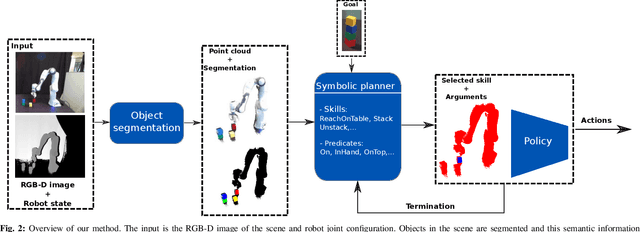

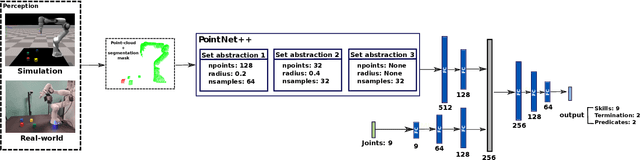
Zero-shot execution of unseen robotic tasks is an important problem in robotics. One potential approach is through task planning: combining known skills based on their preconditions and effects to achieve a user-specified goal. In this work, we propose such a task planning approach to build a reactive system for multi-step manipulation tasks that can be trained on simulation data and applied in the real-world. We explore a block-stacking task because it has a clear structure, where multiple skills must be chained together: pick up a block, place it on top of another block, etc. We learn these skills, along with a set of predicate preconditions and termination conditions, entirely in simulation. All components are learned as PointNet++ models, parameterized by the masks of relevant objects. The predicates allow us to create high-level plans combining different skills. They also serve as precondition functions for the skills, which enables the system to recognize failures and accomplish long-horizon tasks from perceptual input, which is critical for real-world execution. We evaluate our proposed approach in both simulation and in the real-world, showing an increase in success rate from 91.6% to 98% in simulation and from 10% to 80% success rate in the real-world as compared with naive baselines.
Geometric Fabrics for the Acceleration-based Design of Robotic Motion
Nov 11, 2020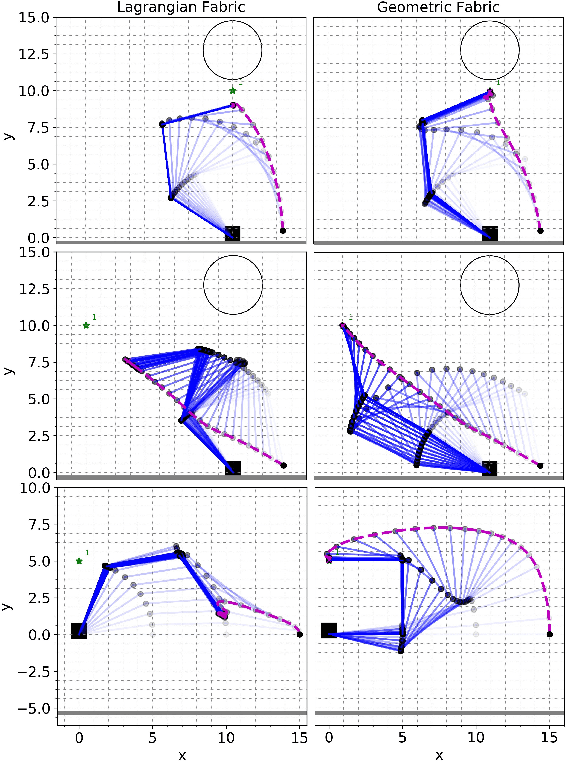

This paper describes the pragmatic design and construction of geometric fabrics for shaping a robot's task-independent nominal behavior, capturing behavioral components such as obstacle avoidance, joint limit avoidance, redundancy resolution, global navigation heuristics, etc. Geometric fabrics constitute the most concrete incarnation of a new mathematical formulation for reactive behavior called optimization fabrics. Fabrics generalize recent work on Riemannian Motion Policies (RMPs); they add provable stability guarantees and improve design consistency while promoting the intuitive acceleration-based principles of modular design that make RMPs successful. We describe a suite of mathematical modeling tools that practitioners can employ in practice and demonstrate both how to mitigate system complexity by constructing behaviors layer-wise and how to employ these tools to design robust, strongly-generalizing, policies that solve practical problems one would expect to find in industry applications. Our system exhibits intelligent global navigation behaviors expressed entirely as fabrics with zero planning or state machine governance.
Multimodal Trajectory Prediction via Topological Invariance for Navigation at Uncontrolled Intersections
Nov 08, 2020
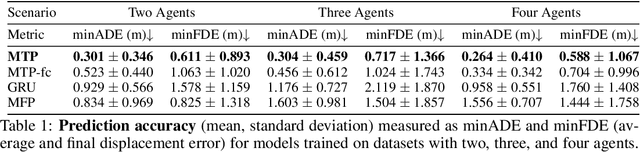
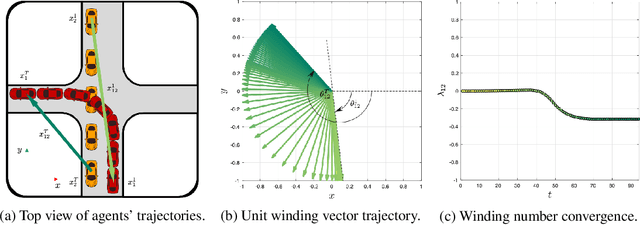
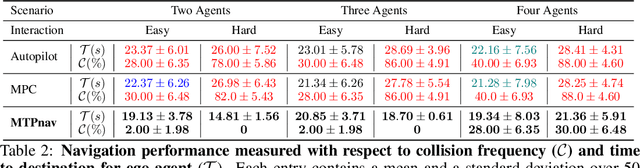
We focus on decentralized navigation among multiple non-communicating rational agents at \emph{uncontrolled} intersections, i.e., street intersections without traffic signs or signals. Avoiding collisions in such domains relies on the ability of agents to predict each others' intentions reliably, and react quickly. Multiagent trajectory prediction is NP-hard whereas the sample complexity of existing data-driven approaches limits their applicability. Our key insight is that the geometric structure of the intersection and the incentive of agents to move efficiently and avoid collisions (rationality) reduces the space of likely behaviors, effectively relaxing the problem of trajectory prediction. In this paper, we collapse the space of multiagent trajectories at an intersection into a set of modes representing different classes of multiagent behavior, formalized using a notion of topological invariance. Based on this formalism, we design Multiple Topologies Prediction (MTP), a data-driven trajectory-prediction mechanism that reconstructs trajectory representations of high-likelihood modes in multiagent intersection scenes. We show that MTP outperforms a state-of-the-art multimodal trajectory prediction baseline (MFP) in terms of prediction accuracy by 78.24% on a challenging simulated dataset. Finally, we show that MTP enables our optimization-based planner, MTPnav, to achieve collision-free and time-efficient navigation across a variety of challenging intersection scenarios on the CARLA simulator.
STReSSD: Sim-To-Real from Sound for Stochastic Dynamics
Nov 05, 2020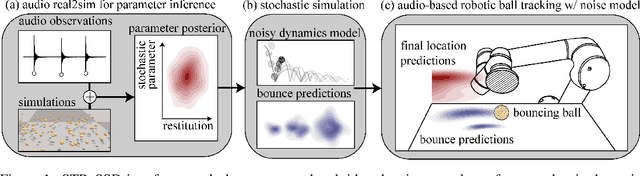
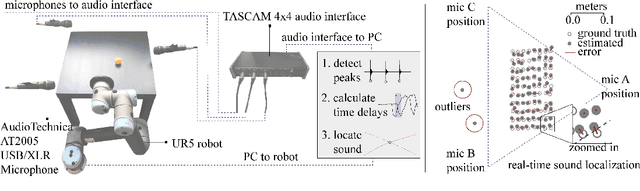
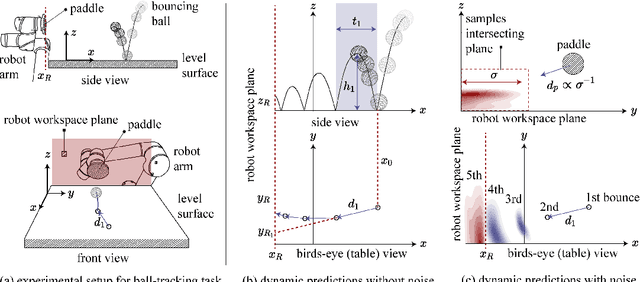
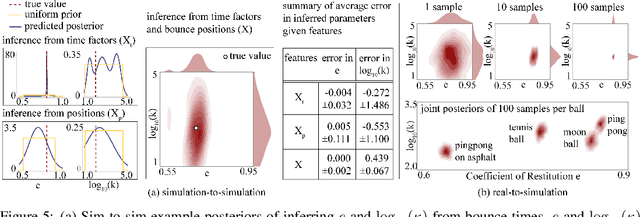
Sound is an information-rich medium that captures dynamic physical events. This work presents STReSSD, a framework that uses sound to bridge the simulation-to-reality gap for stochastic dynamics, demonstrated for the canonical case of a bouncing ball. A physically-motivated noise model is presented to capture stochastic behavior of the balls upon collision with the environment. A likelihood-free Bayesian inference framework is used to infer the parameters of the noise model, as well as a material property called the coefficient of restitution, from audio observations. The same inference framework and the calibrated stochastic simulator are then used to learn a probabilistic model of ball dynamics. The predictive capabilities of the dynamics model are tested in two robotic experiments. First, open-loop predictions anticipate probabilistic success of bouncing a ball into a cup. The second experiment integrates audio perception with a robotic arm to track and deflect a bouncing ball in real-time. We envision that this work is a step towards integrating audio-based inference for dynamic robotic tasks. Experimental results can be viewed at https://youtu.be/b7pOrgZrArk.
Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds
Oct 02, 2020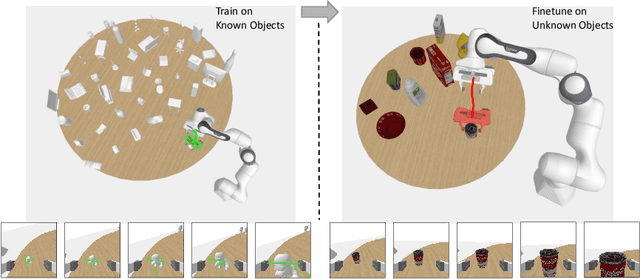
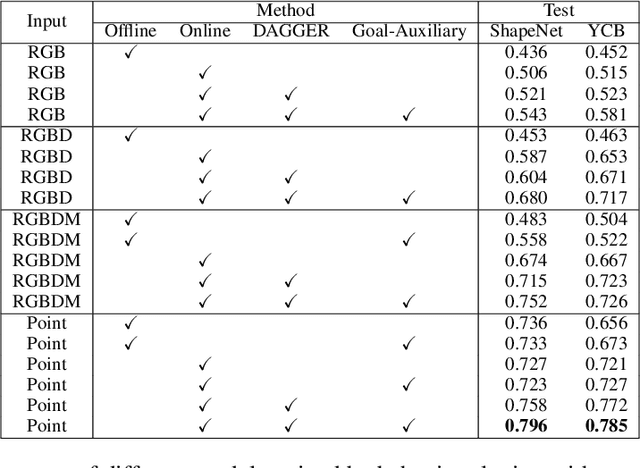
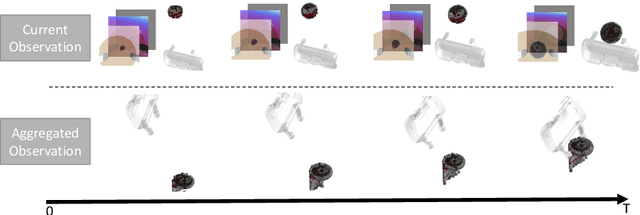
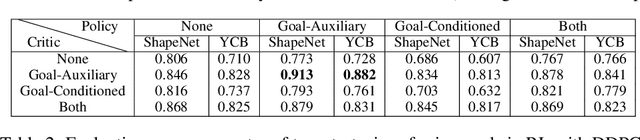
6D robotic grasping beyond top-down bin-picking scenarios is a challenging task. Previous solutions based on 6D grasp synthesis with robot motion planning usually operate in an open-loop setting without considering the dynamics and contacts of objects, which makes them sensitive to grasp synthesis errors. In this work, we propose a novel method for learning closed-loop control policies for 6D robotic grasping using point clouds from an egocentric camera. We combine imitation learning and reinforcement learning in order to grasp unseen objects and handle the continuous 6D action space, where expert demonstrations are obtained from a joint motion and grasp planner. We introduce a goal-auxiliary actor-critic algorithm, which uses grasping goal prediction as an auxiliary task to facilitate policy learning. The supervision on grasping goals can be obtained from the expert planner for known objects or from hindsight goals for unknown objects. Overall, our learned closed-loop policy achieves over 90% success rates on grasping various ShapeNet objects and YCB objects in the simulation. Our video can be found at https://www.youtube.com/watch?v=rKsCRXLykiY&t=1s .