 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Detective: Seek Critical Clues Recurrently to Answer Question from Long Videos
Dec 19, 2025Long Video Question-Answering (LVQA) presents a significant challenge for Multi-modal Large Language Models (MLLMs) due to immense context and overloaded information, which could also lead to prohibitive memory consumption. While existing methods attempt to address these issues by reducing visual tokens or extending model's context length, they may miss useful information or take considerable computation. In fact, when answering given questions, only a small amount of crucial information is required. Therefore, we propose an efficient question-aware memory mechanism, enabling MLLMs to recurrently seek these critical clues. Our approach, named VideoDetective, simplifies this task by iteratively processing video sub-segments. For each sub-segment, a question-aware compression strategy is employed by introducing a few special memory tokens to achieve purposefully compression. This allows models to effectively seek critical clues while reducing visual tokens. Then, due to history context could have a significant impact, we recurrently aggregate and store these memory tokens to update history context, which would be reused for subsequent sub-segments. Furthermore, to more effectively measure model's long video understanding ability, we introduce GLVC (Grounding Long Video Clues), a long video question-answering dataset, which features grounding critical and concrete clues scattered throughout entire videos. Experimental results demonstrate our method enables MLLMs with limited context length of 32K to efficiently process 100K tokens (3600 frames, an hour-long video sampled at 1fps), requiring only 2 minutes and 37GB GPU memory usage. Evaluation results across multiple long video benchmarks illustrate our method can more effectively seek critical clues from massive information.
Understanding Stigmatizing Language Lexicons: A Comparative Analysis in Clinical Contexts
Sep 09, 2025Stigmatizing language results in healthcare inequities, yet there is no universally accepted or standardized lexicon defining which words, terms, or phrases constitute stigmatizing language in healthcare. We conducted a systematic search of the literature to identify existing stigmatizing language lexicons and then analyzed them comparatively to examine: 1) similarities and discrepancies between these lexicons, and 2) the distribution of positive, negative, or neutral terms based on an established sentiment dataset. Our search identified four lexicons. The analysis results revealed moderate semantic similarity among them, and that most stigmatizing terms are related to judgmental expressions by clinicians to describe perceived negative behaviors. Sentiment analysis showed a predominant proportion of negatively classified terms, though variations exist across lexicons. Our findings underscore the need for a standardized lexicon and highlight challenges in defining stigmatizing language in clinical texts.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025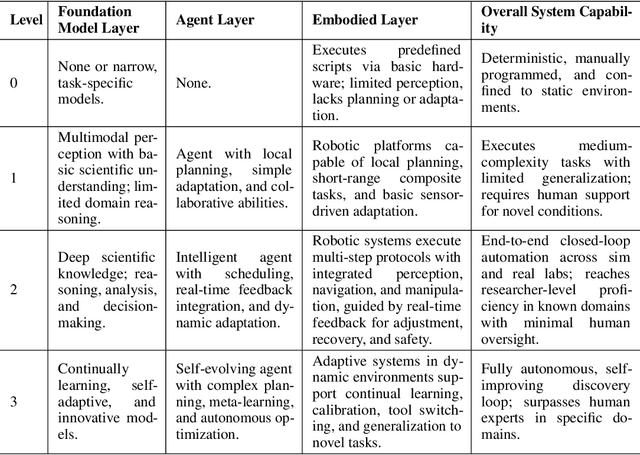
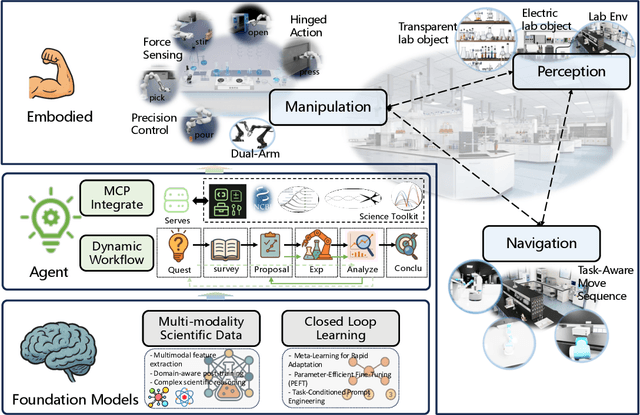
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
RollingQ: Reviving the Cooperation Dynamics in Multimodal Transformer
Jun 13, 2025Multimodal learning faces challenges in effectively fusing information from diverse modalities, especially when modality quality varies across samples. Dynamic fusion strategies, such as attention mechanism in Transformers, aim to address such challenge by adaptively emphasizing modalities based on the characteristics of input data. However, through amounts of carefully designed experiments, we surprisingly observed that the dynamic adaptability of widely-used self-attention models diminishes. Model tends to prefer one modality regardless of data characteristics. This bias triggers a self-reinforcing cycle that progressively overemphasizes the favored modality, widening the distribution gap in attention keys across modalities and deactivating attention mechanism's dynamic properties. To revive adaptability, we propose a simple yet effective method Rolling Query (RollingQ), which balances attention allocation by rotating the query to break the self-reinforcing cycle and mitigate the key distribution gap. Extensive experiments on various multimodal scenarios validate the effectiveness of RollingQ and the restoration of cooperation dynamics is pivotal for enhancing the broader capabilities of widely deployed multimodal Transformers. The source code is available at https://github.com/GeWu-Lab/RollingQ_ICML2025.
Robotic Policy Learning via Human-assisted Action Preference Optimization
Jun 08, 2025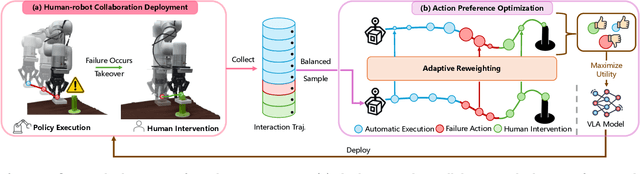



Establishing a reliable and iteratively refined robotic system is essential for deploying real-world applications. While Vision-Language-Action (VLA) models are widely recognized as the foundation model for such robotic deployment, their dependence on expert demonstrations hinders the crucial capabilities of correction and learning from failures. To mitigate this limitation, we introduce a Human-assisted Action Preference Optimization method named HAPO, designed to correct deployment failures and foster effective adaptation through preference alignment for VLA models. This method begins with a human-robot collaboration framework for reliable failure correction and interaction trajectory collection through human intervention. These human-intervention trajectories are further employed within the action preference optimization process, facilitating VLA models to mitigate failure action occurrences while enhancing corrective action adaptation. Specifically, we propose an adaptive reweighting algorithm to address the issues of irreversible interactions and token probability mismatch when introducing preference optimization into VLA models, facilitating model learning from binary desirability signals derived from interactions. Through combining these modules, our human-assisted action preference optimization method ensures reliable deployment and effective learning from failure for VLA models. The experiments conducted in simulation and real-world scenarios prove superior generalization and robustness of our framework across a variety of manipulation tasks.
MokA: Multimodal Low-Rank Adaptation for MLLMs
Jun 05, 2025



In this paper, we reveal that most current efficient multimodal fine-tuning methods are hindered by a key limitation: they are directly borrowed from LLMs, often neglecting the intrinsic differences of multimodal scenarios and even affecting the full utilization of all modalities. Inspired by our empirical observation, we argue that unimodal adaptation and cross-modal adaptation are two essential parts for the effective fine-tuning of MLLMs. From this perspective, we propose Multimodal low-rank Adaptation (MokA), a multimodal-aware efficient fine-tuning strategy that takes multimodal characteristics into consideration. It compresses unimodal information by modality-specific parameters while explicitly enhancing cross-modal interaction, ensuring both unimodal and cross-modal adaptation. Extensive experiments cover three representative multimodal scenarios (audio-visual-text, visual-text, and speech-text), and multiple LLM backbones (LLaMA2/3, Qwen2, Qwen2.5-VL, etc). Consistent improvements indicate the efficacy and versatility of the proposed method. Ablation studies and efficiency evaluation are also conducted to fully asses our method. Overall, we think MokA provides a more targeted solution for efficient adaptation of MLLMs, paving the way for further exploration. The project page is at https://gewu-lab.github.io/MokA.
Phoenix: A Motion-based Self-Reflection Framework for Fine-grained Robotic Action Correction
Apr 20, 2025



Building a generalizable self-correction system is crucial for robots to recover from failures. Despite advancements in Multimodal Large Language Models (MLLMs) that empower robots with semantic reflection ability for failure, translating semantic reflection into how to correct fine-grained robotic actions remains a significant challenge. To address this gap, we build the Phoenix framework, which leverages motion instruction as a bridge to connect high-level semantic reflection with low-level robotic action correction. In this motion-based self-reflection framework, we start with a dual-process motion adjustment mechanism with MLLMs to translate the semantic reflection into coarse-grained motion instruction adjustment. To leverage this motion instruction for guiding how to correct fine-grained robotic actions, a multi-task motion-conditioned diffusion policy is proposed to integrate visual observations for high-frequency robotic action correction. By combining these two models, we could shift the demand for generalization capability from the low-level manipulation policy to the MLLMs-driven motion adjustment model and facilitate precise, fine-grained robotic action correction. Utilizing this framework, we further develop a lifelong learning method to automatically improve the model's capability from interactions with dynamic environments. The experiments conducted in both the RoboMimic simulation and real-world scenarios prove the superior generalization and robustness of our framework across a variety of manipulation tasks. Our code is released at \href{https://github.com/GeWu-Lab/Motion-based-Self-Reflection-Framework}{https://github.com/GeWu-Lab/Motion-based-Self-Reflection-Framework}.
Patch Matters: Training-free Fine-grained Image Caption Enhancement via Local Perception
Apr 09, 2025



High-quality image captions play a crucial role in improving the performance of cross-modal applications such as text-to-image generation, text-to-video generation, and text-image retrieval. To generate long-form, high-quality captions, many recent studies have employed multimodal large language models (MLLMs). However, current MLLMs often produce captions that lack fine-grained details or suffer from hallucinations, a challenge that persists in both open-source and closed-source models. Inspired by Feature-Integration theory, which suggests that attention must focus on specific regions to integrate visual information effectively, we propose a \textbf{divide-then-aggregate} strategy. Our method first divides the image into semantic and spatial patches to extract fine-grained details, enhancing the model's local perception of the image. These local details are then hierarchically aggregated to generate a comprehensive global description. To address hallucinations and inconsistencies in the generated captions, we apply a semantic-level filtering process during hierarchical aggregation. This training-free pipeline can be applied to both open-source models (LLaVA-1.5, LLaVA-1.6, Mini-Gemini) and closed-source models (Claude-3.5-Sonnet, GPT-4o, GLM-4V-Plus). Extensive experiments demonstrate that our method generates more detailed, reliable captions, advancing multimodal description generation without requiring model retraining. The source code are available at https://github.com/GeWu-Lab/Patch-Matters
Adaptive Unimodal Regulation for Balanced Multimodal Information Acquisition
Mar 24, 2025Sensory training during the early ages is vital for human development. Inspired by this cognitive phenomenon, we observe that the early training stage is also important for the multimodal learning process, where dataset information is rapidly acquired. We refer to this stage as the prime learning window. However, based on our observation, this prime learning window in multimodal learning is often dominated by information-sufficient modalities, which in turn suppresses the information acquisition of information-insufficient modalities. To address this issue, we propose Information Acquisition Regulation (InfoReg), a method designed to balance information acquisition among modalities. Specifically, InfoReg slows down the information acquisition process of information-sufficient modalities during the prime learning window, which could promote information acquisition of information-insufficient modalities. This regulation enables a more balanced learning process and improves the overall performance of the multimodal network. Experiments show that InfoReg outperforms related multimodal imbalanced methods across various datasets, achieving superior model performance. The code is available at https://github.com/GeWu-Lab/InfoReg_CVPR2025.
Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
Mar 17, 2025In recent years, numerous tasks have been proposed to encourage model to develop specified capability in understanding audio-visual scene, primarily categorized into temporal localization, spatial localization, spatio-temporal reasoning, and pixel-level understanding. Instead, human possesses a unified understanding ability for diversified tasks. Therefore, designing an audio-visual model with general capability to unify these tasks is of great value. However, simply joint training for all tasks can lead to interference due to the heterogeneity of audiovisual data and complex relationship among tasks. We argue that this problem can be solved through explicit cooperation among tasks. To achieve this goal, we propose a unified learning method which achieves explicit inter-task cooperation from both the perspectives of data and model thoroughly. Specifically, considering the labels of existing datasets are simple words, we carefully refine these datasets and construct an Audio-Visual Unified Instruction-tuning dataset with Explicit reasoning process (AV-UIE), which clarifies the cooperative relationship among tasks. Subsequently, to facilitate concrete cooperation in learning stage, an interaction-aware LoRA structure with multiple LoRA heads is designed to learn different aspects of audiovisual data interaction. By unifying the explicit cooperation across the data and model aspect, our method not only surpasses existing unified audio-visual model on multiple tasks, but also outperforms most specialized models for certain tasks. Furthermore, we also visualize the process of explicit cooperation and surprisingly find that each LoRA head has certain audio-visual understanding ability. Code and dataset: https://github.com/GeWu-Lab/Crab