 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIBench: Evaluating LMMs on Multimodal Interaction
Mar 13, 2026In different multimodal scenarios, it needs to integrate and utilize information across modalities in a specific way based on the demands of the task. Different integration ways between modalities are referred to as "multimodal interaction". How well a model handles various multimodal interactions largely characterizes its multimodal ability. In this paper, we introduce MIBench, a comprehensive benchmark designed to evaluate the multimodal interaction capabilities of Large Multimodal Models (LMMs), which formulates each instance as a (con_v , con_t, task) triplet with contexts from vision and text, necessitating that LMMs employ correct forms of multimodal interaction to effectively complete the task. MIBench assesses models from three key aspects: the ability to source information from vision-centric or text-centric cues, and the ability to generate new information from their joint synergy. Each interaction capability is evaluated hierarchically across three cognitive levels: Recognition, Understanding, and Reasoning. MIBench comprises over 10,000 vision-text context pairs spanning 32 distinct tasks. Evaluation of state-of-the-art LMMs show that: (1) LMMs' ability on multimodal interaction remains constrained, despite the scaling of model parameters and training data; (2) they are easily distracted by textual modalities when processing vision information; (3) they mostly possess a basic capacity for multimodal synergy; and (4) natively trained multimodal models show noticeable deficits in fundamental interaction ability. We expect that these observations can serve as a reference for developing LMMs with more enhanced multimodal ability in the future.
GUI-ReWalk: Massive Data Generation for GUI Agent via Stochastic Exploration and Intent-Aware Reasoning
Sep 19, 2025Graphical User Interface (GUI) Agents, powered by large language and vision-language models, hold promise for enabling end-to-end automation in digital environments. However, their progress is fundamentally constrained by the scarcity of scalable, high-quality trajectory data. Existing data collection strategies either rely on costly and inconsistent manual annotations or on synthetic generation methods that trade off between diversity and meaningful task coverage. To bridge this gap, we present GUI-ReWalk: a reasoning-enhanced, multi-stage framework for synthesizing realistic and diverse GUI trajectories. GUI-ReWalk begins with a stochastic exploration phase that emulates human trial-and-error behaviors, and progressively transitions into a reasoning-guided phase where inferred goals drive coherent and purposeful interactions. Moreover, it supports multi-stride task generation, enabling the construction of long-horizon workflows across multiple applications. By combining randomness for diversity with goal-aware reasoning for structure, GUI-ReWalk produces data that better reflects the intent-aware, adaptive nature of human-computer interaction. We further train Qwen2.5-VL-7B on the GUI-ReWalk dataset and evaluate it across multiple benchmarks, including Screenspot-Pro, OSWorld-G, UI-Vision, AndroidControl, and GUI-Odyssey. Results demonstrate that GUI-ReWalk enables superior coverage of diverse interaction flows, higher trajectory entropy, and more realistic user intent. These findings establish GUI-ReWalk as a scalable and data-efficient framework for advancing GUI agent research and enabling robust real-world automation.
MokA: Multimodal Low-Rank Adaptation for MLLMs
Jun 05, 2025



In this paper, we reveal that most current efficient multimodal fine-tuning methods are hindered by a key limitation: they are directly borrowed from LLMs, often neglecting the intrinsic differences of multimodal scenarios and even affecting the full utilization of all modalities. Inspired by our empirical observation, we argue that unimodal adaptation and cross-modal adaptation are two essential parts for the effective fine-tuning of MLLMs. From this perspective, we propose Multimodal low-rank Adaptation (MokA), a multimodal-aware efficient fine-tuning strategy that takes multimodal characteristics into consideration. It compresses unimodal information by modality-specific parameters while explicitly enhancing cross-modal interaction, ensuring both unimodal and cross-modal adaptation. Extensive experiments cover three representative multimodal scenarios (audio-visual-text, visual-text, and speech-text), and multiple LLM backbones (LLaMA2/3, Qwen2, Qwen2.5-VL, etc). Consistent improvements indicate the efficacy and versatility of the proposed method. Ablation studies and efficiency evaluation are also conducted to fully asses our method. Overall, we think MokA provides a more targeted solution for efficient adaptation of MLLMs, paving the way for further exploration. The project page is at https://gewu-lab.github.io/MokA.
DeepGreen: Effective LLM-Driven Green-washing Monitoring System Designed for Empirical Testing -- Evidence from China
Apr 10, 2025This paper proposes DeepGreen, an Large Language Model Driven (LLM-Driven) system for detecting corporate green-washing behaviour. Utilizing dual-layer LLM analysis, DeepGreen preliminarily identifies potential green keywords in financial statements and then assesses their implementation degree via iterative semantic analysis of LLM. A core variable GreenImplement is derived from the ratio from the two layers' output. We extract 204 financial statements of 68 companies from A-share market over three years, comprising 89,893 words, and analyse them through DeepGreen. Our analysis, supported by violin plots and K-means clustering, reveals insights and validates the variable against the Huazheng ESG rating. It offers a novel perspective for regulatory agencies and investors, serving as a proactive monitoring tool that complements traditional methods.Empirical tests show that green implementation can significantly boost the asset return rate of companies, but there is heterogeneity in scale. Small and medium-sized companies have limited contribution to asset return via green implementation, so there is a stronger motivation for green-washing.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
Masked Face Recognition Dataset and Application
Mar 23, 2020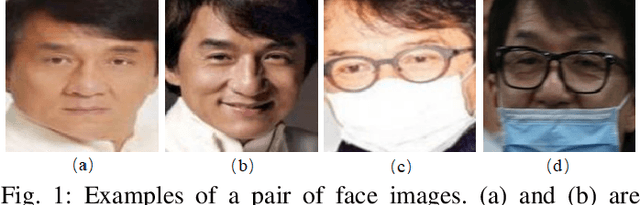
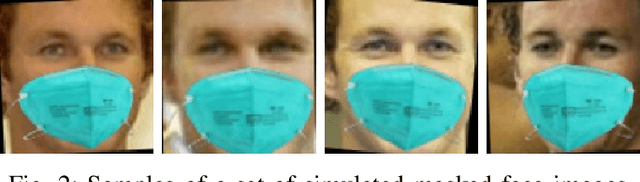
In order to effectively prevent the spread of COVID-19 virus, almost everyone wears a mask during coronavirus epidemic. This almost makes conventional facial recognition technology ineffective in many cases, such as community access control, face access control, facial attendance, facial security checks at train stations, etc. Therefore, it is very urgent to improve the recognition performance of the existing face recognition technology on the masked faces. Most current advanced face recognition approaches are designed based on deep learning, which depend on a large number of face samples. However, at present, there are no publicly available masked face recognition datasets. To this end, this work proposes three types of masked face datasets, including Masked Face Detection Dataset (MFDD), Real-world Masked Face Recognition Dataset (RMFRD) and Simulated Masked Face Recognition Dataset (SMFRD). Among them, to the best of our knowledge, RMFRD is currently theworld's largest real-world masked face dataset. These datasets are freely available to industry and academia, based on which various applications on masked faces can be developed. The multi-granularity masked face recognition model we developed achieves 95% accuracy, exceeding the results reported by the industry. Our datasets are available at: https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset.