 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes learning the right latent variables necessarily improve in-context learning?
May 29, 2024Large autoregressive models like Transformers can solve tasks through in-context learning (ICL) without learning new weights, suggesting avenues for efficiently solving new tasks. For many tasks, e.g., linear regression, the data factorizes: examples are independent given a task latent that generates the data, e.g., linear coefficients. While an optimal predictor leverages this factorization by inferring task latents, it is unclear if Transformers implicitly do so or if they instead exploit heuristics and statistical shortcuts enabled by attention layers. Both scenarios have inspired active ongoing work. In this paper, we systematically investigate the effect of explicitly inferring task latents. We minimally modify the Transformer architecture with a bottleneck designed to prevent shortcuts in favor of more structured solutions, and then compare performance against standard Transformers across various ICL tasks. Contrary to intuition and some recent works, we find little discernible difference between the two; biasing towards task-relevant latent variables does not lead to better out-of-distribution performance, in general. Curiously, we find that while the bottleneck effectively learns to extract latent task variables from context, downstream processing struggles to utilize them for robust prediction. Our study highlights the intrinsic limitations of Transformers in achieving structured ICL solutions that generalize, and shows that while inferring the right latents aids interpretability, it is not sufficient to alleviate this problem.
Demystifying amortized causal discovery with transformers
May 27, 2024



Supervised learning approaches for causal discovery from observational data often achieve competitive performance despite seemingly avoiding explicit assumptions that traditional methods make for identifiability. In this work, we investigate CSIvA (Ke et al., 2023), a transformer-based model promising to train on synthetic data and transfer to real data. First, we bridge the gap with existing identifiability theory and show that constraints on the training data distribution implicitly define a prior on the test observations. Consistent with classical approaches, good performance is achieved when we have a good prior on the test data, and the underlying model is identifiable. At the same time, we find new trade-offs. Training on datasets generated from different classes of causal models, unambiguously identifiable in isolation, improves the test generalization. Performance is still guaranteed, as the ambiguous cases resulting from the mixture of identifiable causal models are unlikely to occur (which we formally prove). Overall, our study finds that amortized causal discovery still needs to obey identifiability theory, but it also differs from classical methods in how the assumptions are formulated, trading more reliance on assumptions on the noise type for fewer hypotheses on the mechanisms.
Evaluating Interventional Reasoning Capabilities of Large Language Models
Apr 08, 2024Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
In-Context Learning Can Re-learn Forbidden Tasks
Feb 08, 2024Despite significant investment into safety training, large language models (LLMs) deployed in the real world still suffer from numerous vulnerabilities. One perspective on LLM safety training is that it algorithmically forbids the model from answering toxic or harmful queries. To assess the effectiveness of safety training, in this work, we study forbidden tasks, i.e., tasks the model is designed to refuse to answer. Specifically, we investigate whether in-context learning (ICL) can be used to re-learn forbidden tasks despite the explicit fine-tuning of the model to refuse them. We first examine a toy example of refusing sentiment classification to demonstrate the problem. Then, we use ICL on a model fine-tuned to refuse to summarise made-up news articles. Finally, we investigate whether ICL can undo safety training, which could represent a major security risk. For the safety task, we look at Vicuna-7B, Starling-7B, and Llama2-7B. We show that the attack works out-of-the-box on Starling-7B and Vicuna-7B but fails on Llama2-7B. Finally, we propose an ICL attack that uses the chat template tokens like a prompt injection attack to achieve a better attack success rate on Vicuna-7B and Starling-7B. Trigger Warning: the appendix contains LLM-generated text with violence, suicide, and misinformation.
Estimating Social Influence from Observational Data
Mar 24, 2022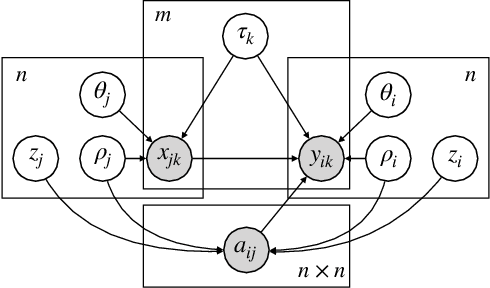
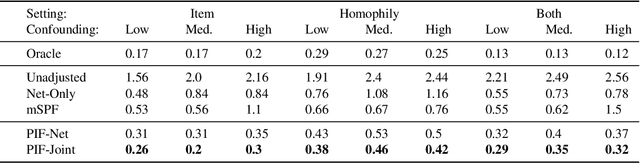
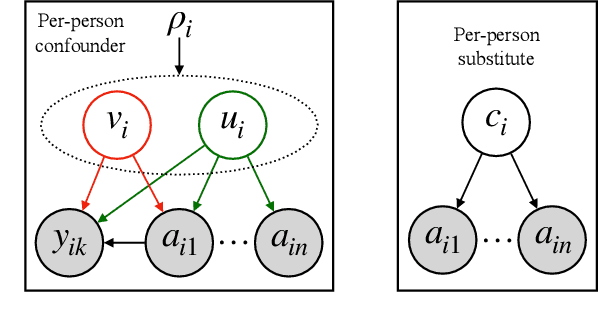
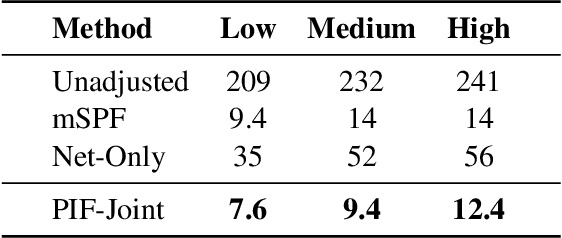
We consider the problem of estimating social influence, the effect that a person's behavior has on the future behavior of their peers. The key challenge is that shared behavior between friends could be equally explained by influence or by two other confounding factors: 1) latent traits that caused people to both become friends and engage in the behavior, and 2) latent preferences for the behavior. This paper addresses the challenges of estimating social influence with three contributions. First, we formalize social influence as a causal effect, one which requires inferences about hypothetical interventions. Second, we develop Poisson Influence Factorization (PIF), a method for estimating social influence from observational data. PIF fits probabilistic factor models to networks and behavior data to infer variables that serve as substitutes for the confounding latent traits. Third, we develop assumptions under which PIF recovers estimates of social influence. We empirically study PIF with semi-synthetic and real data from Last.fm, and conduct a sensitivity analysis. We find that PIF estimates social influence most accurately compared to related methods and remains robust under some violations of its assumptions.
Identifiable Variational Autoencoders via Sparse Decoding
Oct 20, 2021
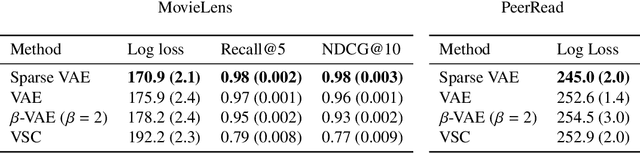
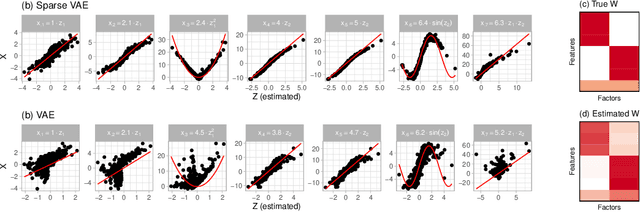
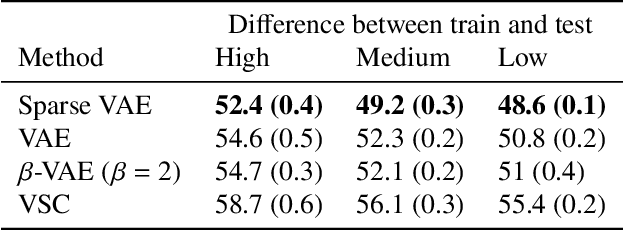
We develop the Sparse VAE, a deep generative model for unsupervised representation learning on high-dimensional data. Given a dataset of observations, the Sparse VAE learns a set of latent factors that captures its distribution. The model is sparse in the sense that each feature of the dataset (i.e., each dimension) depends on a small subset of the latent factors. As examples, in ratings data each movie is only described by a few genres; in text data each word is only applicable to a few topics; in genomics, each gene is active in only a few biological processes. We first show that the Sparse VAE is identifiable: given data drawn from the model, there exists a uniquely optimal set of factors. (In contrast, most VAE-based models are not identifiable.) The key assumption behind Sparse-VAE identifiability is the existence of "anchor features", where for each factor there exists a feature that depends only on that factor. Importantly, the anchor features do not need to be known in advance. We then show how to fit the Sparse VAE with variational EM. Finally, we empirically study the Sparse VAE with both simulated and real data. We find that it recovers meaningful latent factors and has smaller heldout reconstruction error than related methods.
Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021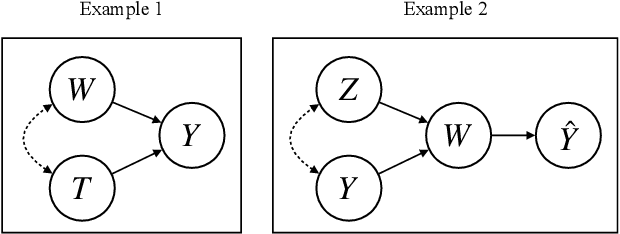
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
Causal Effects of Linguistic Properties
Oct 24, 2020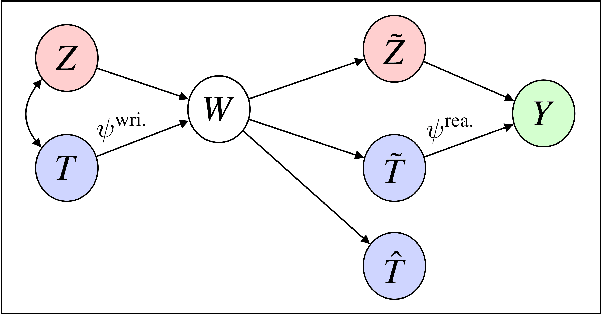
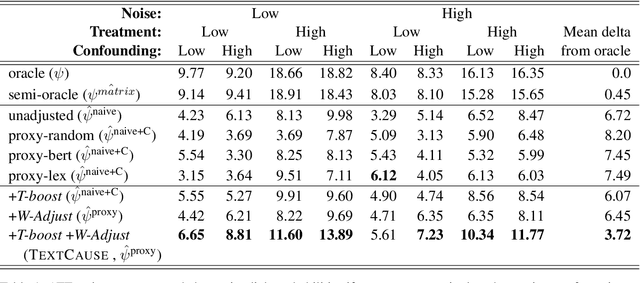
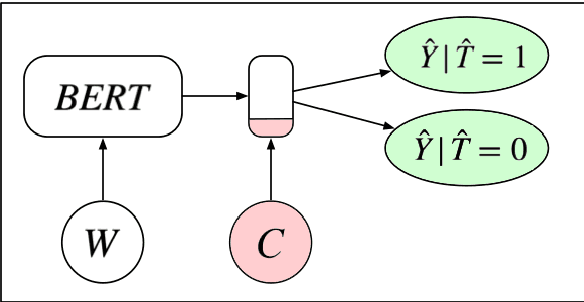

We consider the problem of estimating the causal effects of linguistic properties on downstream outcomes. For example, does writing a complaint politely lead to a faster response time? How much will a positive product review increase sales? This paper focuses on two challenges related to the problem. First, we formalize the causal quantity of interest as the effect of a writer's intent, and establish the assumptions necessary to identify this from observational data. Second, in practice we only have access to noisy proxies for these linguistic properties---e.g., predictions from classifiers and lexicons. We propose an estimator for this setting and prove that its bias is bounded when we perform an adjustment for the text. The method leverages (1) a pre-trained language model (BERT) to adjust for the text, and (2) distant supervision to improve the quality of noisy proxies. We show that our algorithm produces better causal estimates than related methods on two datasets: predicting the effect of music review sentiment on sales, and complaint politeness on response time.
Valid Causal Inference with (Some) Invalid Instruments
Jun 19, 2020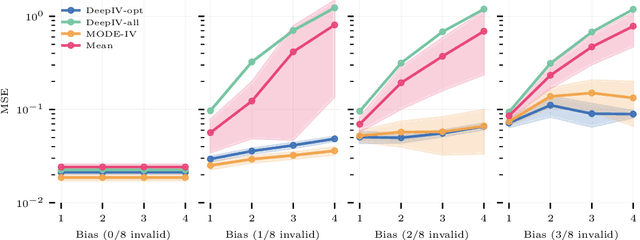
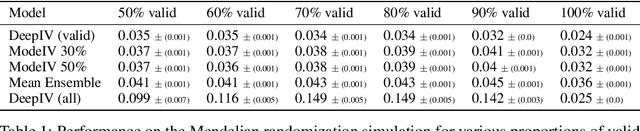
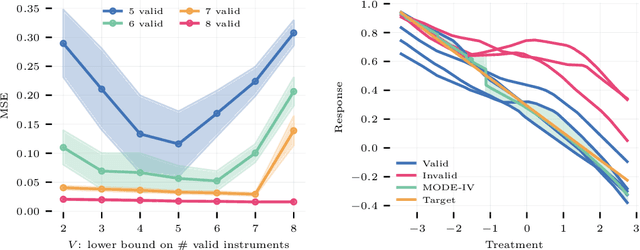
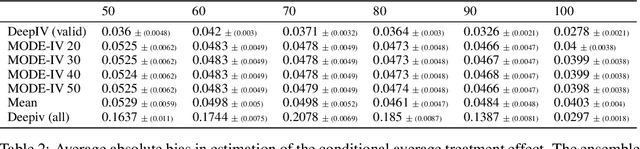
Instrumental variable methods provide a powerful approach to estimating causal effects in the presence of unobserved confounding. But a key challenge when applying them is the reliance on untestable "exclusion" assumptions that rule out any relationship between the instrument variable and the response that is not mediated by the treatment. In this paper, we show how to perform consistent IV estimation despite violations of the exclusion assumption. In particular, we show that when one has multiple candidate instruments, only a majority of these candidates---or, more generally, the modal candidate-response relationship---needs to be valid to estimate the causal effect. Our approach uses an estimate of the modal prediction from an ensemble of instrumental variable estimators. The technique is simple to apply and is "black-box" in the sense that it may be used with any instrumental variable estimator as long as the treatment effect is identified for each valid instrument independently. As such, it is compatible with recent machine-learning based estimators that allow for the estimation of conditional average treatment effects (CATE) on complex, high dimensional data. Experimentally, we achieve accurate estimates of conditional average treatment effects using an ensemble of deep network-based estimators, including on a challenging simulated Mendelian Randomization problem.
Estimating Causal Effects of Tone in Online Debates
Jun 12, 2019


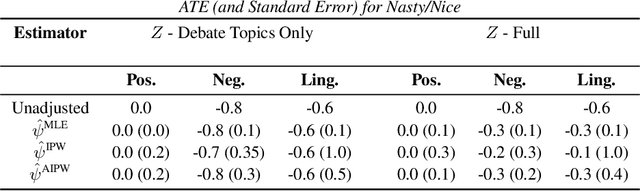
Statistical methods applied to social media posts shed light on the dynamics of online dialogue. For example, users' wording choices predict their persuasiveness and users adopt the language patterns of other dialogue participants. In this paper, we estimate the causal effect of reply tones in debates on linguistic and sentiment changes in subsequent responses. The challenge for this estimation is that a reply's tone and subsequent responses are confounded by the users' ideologies on the debate topic and their emotions. To overcome this challenge, we learn representations of ideology using generative models of text. We study debates from 4Forums and compare annotated tones of replying such as emotional versus factual, or reasonable versus attacking. We show that our latent confounder representation reduces bias in ATE estimation. Our results suggest that factual and asserting tones affect dialogue and provide a methodology for estimating causal effects from text.