 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Jun 11, 2024Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
CRiskEval: A Chinese Multi-Level Risk Evaluation Benchmark Dataset for Large Language Models
Jun 07, 2024Large language models (LLMs) are possessed of numerous beneficial capabilities, yet their potential inclination harbors unpredictable risks that may materialize in the future. We hence propose CRiskEval, a Chinese dataset meticulously designed for gauging the risk proclivities inherent in LLMs such as resource acquisition and malicious coordination, as part of efforts for proactive preparedness. To curate CRiskEval, we define a new risk taxonomy with 7 types of frontier risks and 4 safety levels, including extremely hazardous,moderately hazardous, neutral and safe. We follow the philosophy of tendency evaluation to empirically measure the stated desire of LLMs via fine-grained multiple-choice question answering. The dataset consists of 14,888 questions that simulate scenarios related to predefined 7 types of frontier risks. Each question is accompanied with 4 answer choices that state opinions or behavioral tendencies corresponding to the question. All answer choices are manually annotated with one of the defined risk levels so that we can easily build a fine-grained frontier risk profile for each assessed LLM. Extensive evaluation with CRiskEval on a spectrum of prevalent Chinese LLMs has unveiled a striking revelation: most models exhibit risk tendencies of more than 40% (weighted tendency to the four risk levels). Furthermore, a subtle increase in the model's inclination toward urgent self-sustainability, power seeking and other dangerous goals becomes evident as the size of models increase. To promote further research on the frontier risk evaluation of LLMs, we publicly release our dataset at https://github.com/lingshi6565/Risk_eval.
Benchmark Underestimates the Readiness of Multi-lingual Dialogue Agents
May 28, 2024



Creating multilingual task-oriented dialogue (TOD) agents is challenging due to the high cost of training data acquisition. Following the research trend of improving training data efficiency, we show for the first time, that in-context learning is sufficient to tackle multilingual TOD. To handle the challenging dialogue state tracking (DST) subtask, we break it down to simpler steps that are more compatible with in-context learning where only a handful of few-shot examples are used. We test our approach on the multilingual TOD dataset X-RiSAWOZ, which has 12 domains in Chinese, English, French, Korean, Hindi, and code-mixed Hindi-English. Our turn-by-turn DST accuracy on the 6 languages range from 55.6% to 80.3%, seemingly worse than the SOTA results from fine-tuned models that achieve from 60.7% to 82.8%; our BLEU scores in the response generation (RG) subtask are also significantly lower than SOTA. However, after manual evaluation of the validation set, we find that by correcting gold label errors and improving dataset annotation schema, GPT-4 with our prompts can achieve (1) 89.6%-96.8% accuracy in DST, and (2) more than 99% correct response generation across different languages. This leads us to conclude that current automatic metrics heavily underestimate the effectiveness of in-context learning.
Decoding at the Speed of Thought: Harnessing Parallel Decoding of Lexical Units for LLMs
May 24, 2024



Large language models have demonstrated exceptional capability in natural language understanding and generation. However, their generation speed is limited by the inherently sequential nature of their decoding process, posing challenges for real-time applications. This paper introduces Lexical Unit Decoding (LUD), a novel decoding methodology implemented in a data-driven manner, accelerating the decoding process without sacrificing output quality. The core of our approach is the observation that a pre-trained language model can confidently predict multiple contiguous tokens, forming the basis for a \textit{lexical unit}, in which these contiguous tokens could be decoded in parallel. Extensive experiments validate that our method substantially reduces decoding time while maintaining generation quality, i.e., 33\% speed up on natural language generation with no quality loss, and 30\% speed up on code generation with a negligible quality loss of 3\%. Distinctively, LUD requires no auxiliary models and does not require changes to existing architectures. It can also be integrated with other decoding acceleration methods, thus achieving an even more pronounced inference efficiency boost. We posit that the foundational principles of LUD could define a new decoding paradigm for future language models, enhancing their applicability for a broader spectrum of applications. All codes are be publicly available at https://github.com/tjunlp-lab/Lexical-Unit-Decoding-LUD-. Keywords: Parallel Decoding, Lexical Unit Decoding, Large Language Model
ConTrans: Weak-to-Strong Alignment Engineering via Concept Transplantation
May 22, 2024Ensuring large language models (LLM) behave consistently with human goals, values, and intentions is crucial for their safety but yet computationally expensive. To reduce the computational cost of alignment training of LLMs, especially for those with a huge number of parameters, and to reutilize learned value alignment, we propose ConTrans, a novel framework that enables weak-to-strong alignment transfer via concept transplantation. From the perspective of representation engineering, ConTrans refines concept vectors in value alignment from a source LLM (usually a weak yet aligned LLM). The refined concept vectors are then reformulated to adapt to the target LLM (usually a strong yet unaligned base LLM) via affine transformation. In the third step, ConTrans transplants the reformulated concept vectors into the residual stream of the target LLM. Experiments demonstrate the successful transplantation of a wide range of aligned concepts from 7B models to 13B and 70B models across multiple LLMs and LLM families. Remarkably, ConTrans even surpasses instruction-tuned models in terms of truthfulness. Experiment results validate the effectiveness of both inter-LLM-family and intra-LLM-family concept transplantation. Our work successfully demonstrates an alternative way to achieve weak-to-strong alignment generalization and control.
LFED: A Literary Fiction Evaluation Dataset for Large Language Models
May 16, 2024



The rapid evolution of large language models (LLMs) has ushered in the need for comprehensive assessments of their performance across various dimensions. In this paper, we propose LFED, a Literary Fiction Evaluation Dataset, which aims to evaluate the capability of LLMs on the long fiction comprehension and reasoning. We collect 95 literary fictions that are either originally written in Chinese or translated into Chinese, covering a wide range of topics across several centuries. We define a question taxonomy with 8 question categories to guide the creation of 1,304 questions. Additionally, we conduct an in-depth analysis to ascertain how specific attributes of literary fictions (e.g., novel types, character numbers, the year of publication) impact LLM performance in evaluations. Through a series of experiments with various state-of-the-art LLMs, we demonstrate that these models face considerable challenges in effectively addressing questions related to literary fictions, with ChatGPT reaching only 57.08% under the zero-shot setting. The dataset will be publicly available at https://github.com/tjunlp-lab/LFED.git
LHMKE: A Large-scale Holistic Multi-subject Knowledge Evaluation Benchmark for Chinese Large Language Models
Mar 19, 2024



Chinese Large Language Models (LLMs) have recently demonstrated impressive capabilities across various NLP benchmarks and real-world applications. However, the existing benchmarks for comprehensively evaluating these LLMs are still insufficient, particularly in terms of measuring knowledge that LLMs capture. Current datasets collect questions from Chinese examinations across different subjects and educational levels to address this issue. Yet, these benchmarks primarily focus on objective questions such as multiple-choice questions, leading to a lack of diversity in question types. To tackle this problem, we propose LHMKE, a Large-scale, Holistic, and Multi-subject Knowledge Evaluation benchmark in this paper. LHMKE is designed to provide a comprehensive evaluation of the knowledge acquisition capabilities of Chinese LLMs. It encompasses 10,465 questions across 75 tasks covering 30 subjects, ranging from primary school to professional certification exams. Notably, LHMKE includes both objective and subjective questions, offering a more holistic evaluation of the knowledge level of LLMs. We have assessed 11 Chinese LLMs under the zero-shot setting, which aligns with real examinations, and compared their performance across different subjects. We also conduct an in-depth analysis to check whether GPT-4 can automatically score subjective predictions. Our findings suggest that LHMKE is a challenging and advanced testbed for Chinese LLMs.
OpenEval: Benchmarking Chinese LLMs across Capability, Alignment and Safety
Mar 18, 2024



The rapid development of Chinese large language models (LLMs) poses big challenges for efficient LLM evaluation. While current initiatives have introduced new benchmarks or evaluation platforms for assessing Chinese LLMs, many of these focus primarily on capabilities, usually overlooking potential alignment and safety issues. To address this gap, we introduce OpenEval, an evaluation testbed that benchmarks Chinese LLMs across capability, alignment and safety. For capability assessment, we include 12 benchmark datasets to evaluate Chinese LLMs from 4 sub-dimensions: NLP tasks, disciplinary knowledge, commonsense reasoning and mathematical reasoning. For alignment assessment, OpenEval contains 7 datasets that examines the bias, offensiveness and illegalness in the outputs yielded by Chinese LLMs. To evaluate safety, especially anticipated risks (e.g., power-seeking, self-awareness) of advanced LLMs, we include 6 datasets. In addition to these benchmarks, we have implemented a phased public evaluation and benchmark update strategy to ensure that OpenEval is in line with the development of Chinese LLMs or even able to provide cutting-edge benchmark datasets to guide the development of Chinese LLMs. In our first public evaluation, we have tested a range of Chinese LLMs, spanning from 7B to 72B parameters, including both open-source and proprietary models. Evaluation results indicate that while Chinese LLMs have shown impressive performance in certain tasks, more attention should be directed towards broader aspects such as commonsense reasoning, alignment, and safety.
FineMath: A Fine-Grained Mathematical Evaluation Benchmark for Chinese Large Language Models
Mar 12, 2024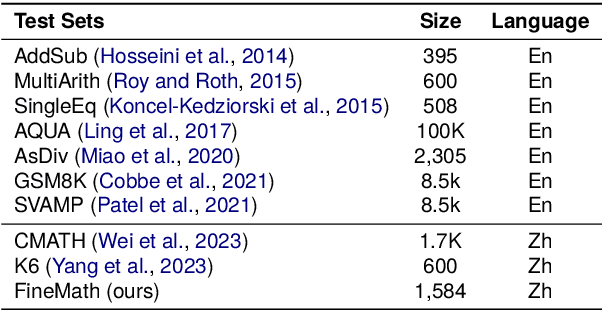
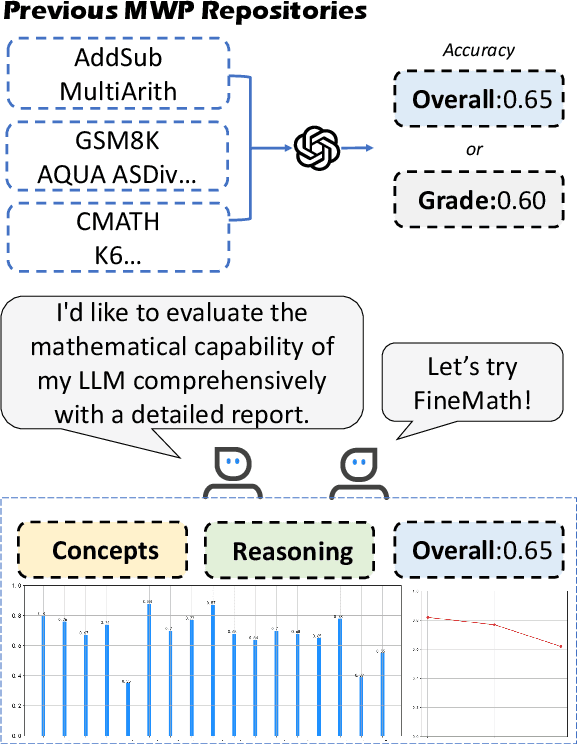
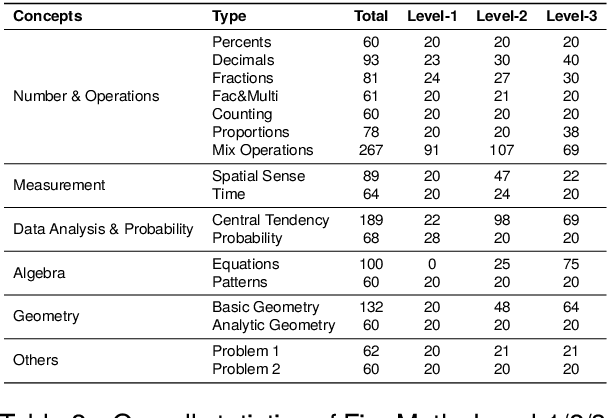
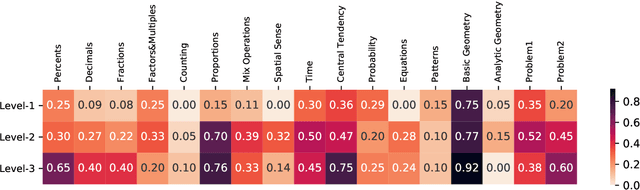
To thoroughly assess the mathematical reasoning abilities of Large Language Models (LLMs), we need to carefully curate evaluation datasets covering diverse mathematical concepts and mathematical problems at different difficulty levels. In pursuit of this objective, we propose FineMath in this paper, a fine-grained mathematical evaluation benchmark dataset for assessing Chinese LLMs. FineMath is created to cover the major key mathematical concepts taught in elementary school math, which are further divided into 17 categories of math word problems, enabling in-depth analysis of mathematical reasoning abilities of LLMs. All the 17 categories of math word problems are manually annotated with their difficulty levels according to the number of reasoning steps required to solve these problems. We conduct extensive experiments on a wide range of LLMs on FineMath and find that there is still considerable room for improvements in terms of mathematical reasoning capability of Chinese LLMs. We also carry out an in-depth analysis on the evaluation process and methods that have been overlooked previously. These two factors significantly influence the model results and our understanding of their mathematical reasoning capabilities. The dataset will be publicly available soon.
Exploring Multilingual Human Value Concepts in Large Language Models: Is Value Alignment Consistent, Transferable and Controllable across Languages?
Feb 28, 2024Prior research in representation engineering has revealed that LLMs encode concepts within their representation spaces, predominantly centered around English. In this study, we extend this philosophy to a multilingual scenario, delving into multilingual human value concepts in LLMs. Through our comprehensive exploration covering 7 types of human values, 16 languages and 3 LLM series with distinct multilinguality, we empirically substantiate the existence of multilingual human values in LLMs. Further cross-lingual analysis on these concepts discloses 3 traits arising from language resource disparities: cross-lingual inconsistency, distorted linguistic relationships, and unidirectional cross-lingual transfer between high- and low-resource languages, all in terms of human value concepts. Additionally, we validate the feasibility of cross-lingual control over value alignment capabilities of LLMs, leveraging the dominant language as a source language. Drawing from our findings on multilingual value alignment, we prudently provide suggestions on the composition of multilingual data for LLMs pre-training: including a limited number of dominant languages for cross-lingual alignment transfer while avoiding their excessive prevalence, and keeping a balanced distribution of non-dominant languages. We aspire that our findings would contribute to enhancing the safety and utility of multilingual AI.