 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Collaborative Learning for Co-Salient Object Detection
Mar 15, 2021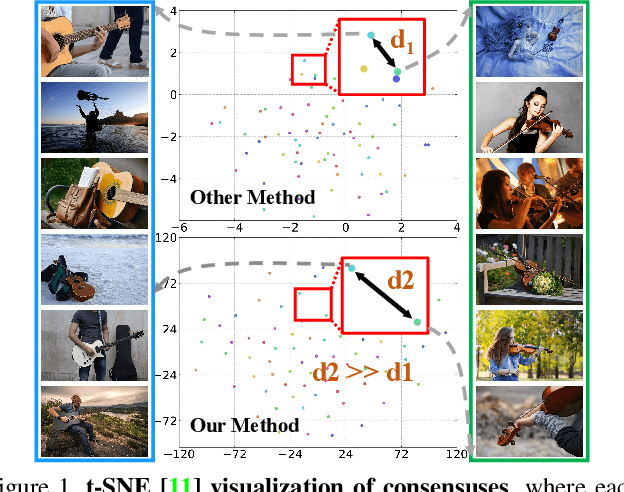

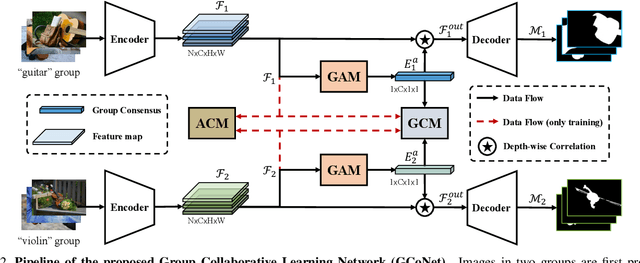
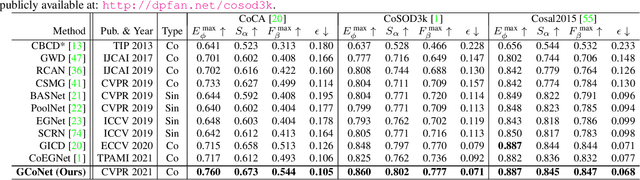
We present a novel group collaborative learning framework (GCoNet) capable of detecting co-salient objects in real time (16ms), by simultaneously mining consensus representations at group level based on the two necessary criteria: 1) intra-group compactness to better formulate the consistency among co-salient objects by capturing their inherent shared attributes using our novel group affinity module; 2) inter-group separability to effectively suppress the influence of noisy objects on the output by introducing our new group collaborating module conditioning the inconsistent consensus. To learn a better embedding space without extra computational overhead, we explicitly employ auxiliary classification supervision. Extensive experiments on three challenging benchmarks, i.e., CoCA, CoSOD3k, and Cosal2015, demonstrate that our simple GCoNet outperforms 10 cutting-edge models and achieves the new state-of-the-art. We demonstrate this paper's new technical contributions on a number of important downstream computer vision applications including content aware co-segmentation, co-localization based automatic thumbnails, etc.
Simultaneously Localize, Segment and Rank the Camouflaged Objects
Mar 06, 2021
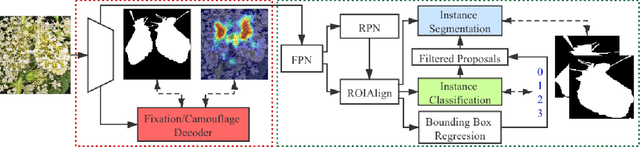
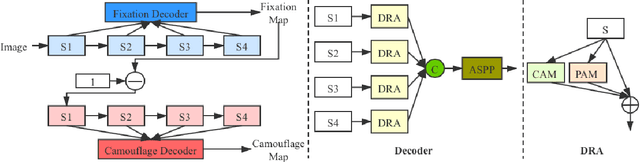
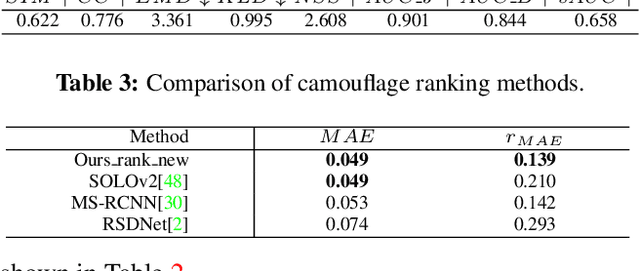
Camouflage is a key defence mechanism across species that is critical to survival. Common strategies for camouflage include background matching, imitating the color and pattern of the environment, and disruptive coloration, disguising body outlines [35]. Camouflaged object detection (COD) aims to segment camouflaged objects hiding in their surroundings. Existing COD models are built upon binary ground truth to segment the camouflaged objects without illustrating the level of camouflage. In this paper, we revisit this task and argue that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage and evolution of animals, but also provide guidance to design more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of the camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first ranking based COD network (Rank-Net) to simultaneously localize, segment and rank camouflaged objects. The localization model is proposed to find the discriminative regions that make the camouflaged object obvious. The segmentation model segments the full scope of the camouflaged objects. And, the ranking model infers the detectability of different camouflaged objects. Moreover, we contribute a large COD testing set to evaluate the generalization ability of COD models. Experimental results show that our model achieves new state-of-the-art, leading to a more interpretable COD network.
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
Feb 24, 2021
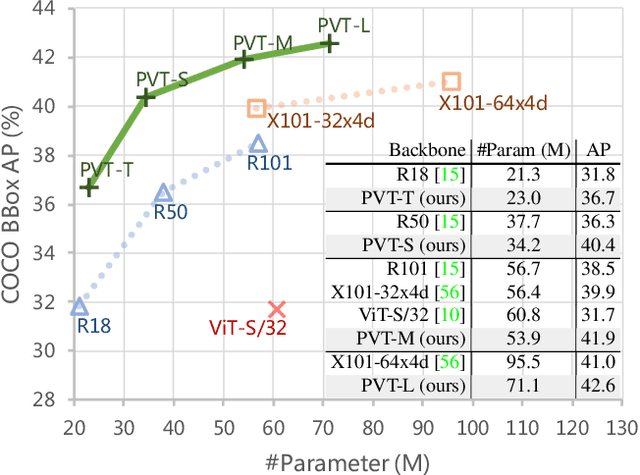
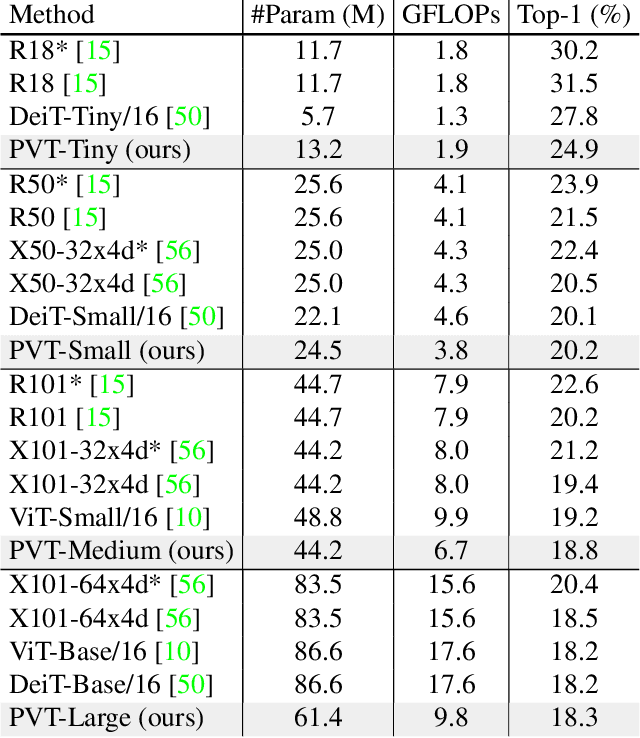
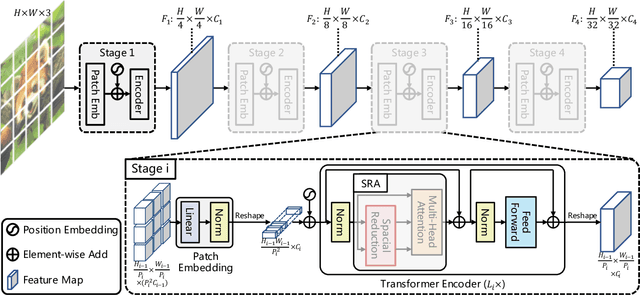
Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several merits compared to prior arts. (1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense predictions but also using a progressive shrinking pyramid to reduce computations of large feature maps. (2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones. (3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g., object detection, semantic, and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches. Code is available at https://github.com/whai362/PVT.
Salient Object Detection via Integrity Learning
Feb 21, 2021
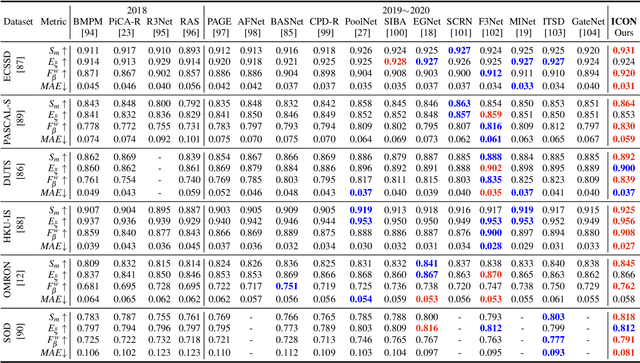
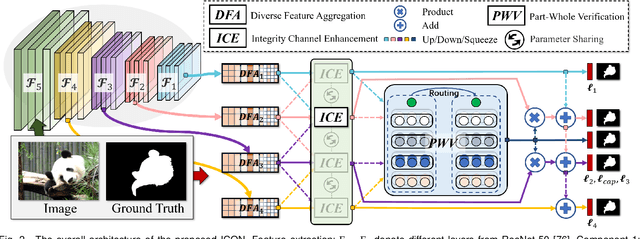
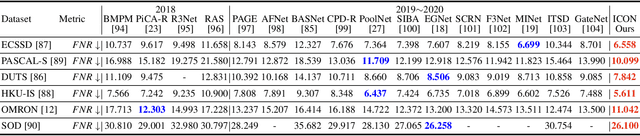
Albeit current salient object detection (SOD) works have achieved fantastic progress, they are cast into the shade when it comes to the integrity of the predicted salient regions. We define the concept of integrity at both the micro and macro level. Specifically, at the micro level, the model should highlight all parts that belong to a certain salient object, while at the macro level, the model needs to discover all salient objects from the given image scene. To facilitate integrity learning for salient object detection, we design a novel Integrity Cognition Network (ICON), which explores three important components to learn strong integrity features. 1) Unlike the existing models that focus more on feature discriminability, we introduce a diverse feature aggregation (DFA) component to aggregate features with various receptive fields (i.e.,, kernel shape and context) and increase the feature diversity. Such diversity is the foundation for mining the integral salient objects. 2) Based on the DFA features, we introduce the integrity channel enhancement (ICE) component with the goal of enhancing feature channels that highlight the integral salient objects at the macro level, while suppressing the other distracting ones. 3) After extracting the enhanced features, the part-whole verification (PWV) method is employed to determine whether the part and whole object features have strong agreement. Such part-whole agreements can further improve the micro-level integrity for each salient object. To demonstrate the effectiveness of ICON, comprehensive experiments are conducted on seven challenging benchmarks, where promising results are achieved.
Concealed Object Detection
Feb 20, 2021

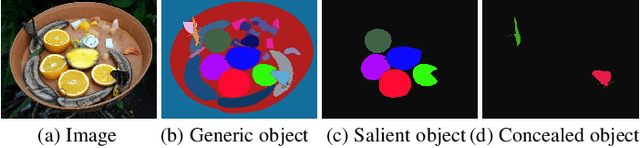

We present the first systematic study on concealed object detection (COD), which aims to identify objects that are "perfectly" embedded in their background. The high intrinsic similarities between the concealed objects and their background make COD far more challenging than traditional object detection/segmentation. To better understand this task, we collect a large-scale dataset, called COD10K, which consists of 10,000 images covering concealed objects in diverse real-world scenarios from 78 object categories. Further, we provide rich annotations including object categories, object boundaries, challenging attributes, object-level labels, and instance-level annotations. Our COD10K is the largest COD dataset to date, with the richest annotations, which enables comprehensive concealed object understanding and can even be used to help progress several other vision tasks, such as detection, segmentation, classification, etc. Motivated by how animals hunt in the wild, we also design a simple but strong baseline for COD, termed the Search Identification Network (SINet). Without any bells and whistles, SINet outperforms 12 cutting-edge baselines on all datasets tested, making them robust, general architectures that could serve as catalysts for future research in COD. Finally, we provide some interesting findings and highlight several potential applications and future directions. To spark research in this new field, our code, dataset, and online demo are available on our project page: http://mmcheng.net/cod.
Boundary-Aware Segmentation Network for Mobile and Web Applications
Jan 12, 2021
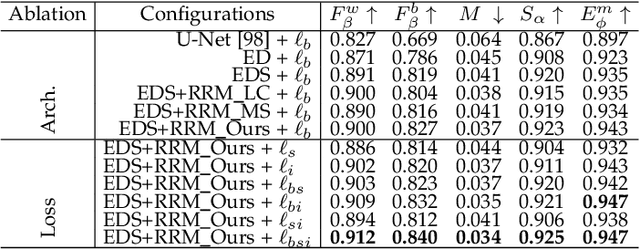
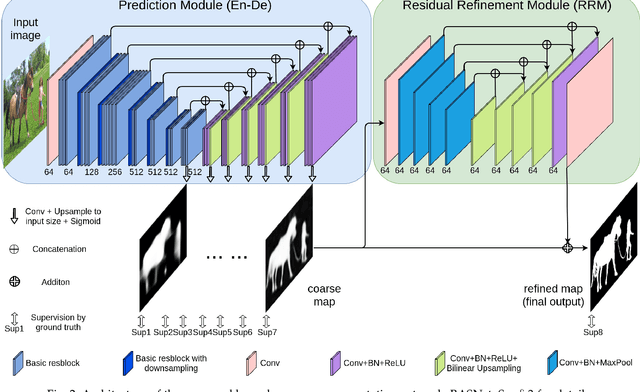
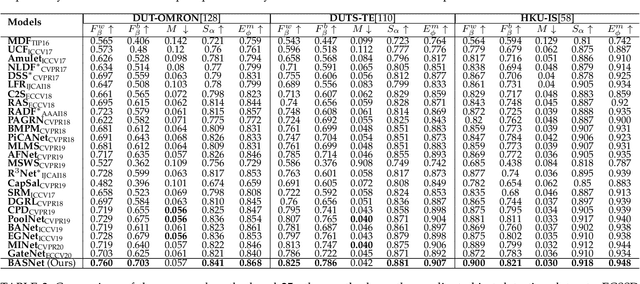
Although deep models have greatly improved the accuracy and robustness of image segmentation, obtaining segmentation results with highly accurate boundaries and fine structures is still a challenging problem. In this paper, we propose a simple yet powerful Boundary-Aware Segmentation Network (BASNet), which comprises a predict-refine architecture and a hybrid loss, for highly accurate image segmentation. The predict-refine architecture consists of a densely supervised encoder-decoder network and a residual refinement module, which are respectively used to predict and refine a segmentation probability map. The hybrid loss is a combination of the binary cross entropy, structural similarity and intersection-over-union losses, which guide the network to learn three-level (ie, pixel-, patch- and map- level) hierarchy representations. We evaluate our BASNet on two reverse tasks including salient object segmentation, camouflaged object segmentation, showing that it achieves very competitive performance with sharp segmentation boundaries. Importantly, BASNet runs at over 70 fps on a single GPU which benefits many potential real applications. Based on BASNet, we further developed two (close to) commercial applications: AR COPY & PASTE, in which BASNet is integrated with augmented reality for "COPYING" and "PASTING" real-world objects, and OBJECT CUT, which is a web-based tool for automatic object background removal. Both applications have already drawn huge amount of attention and have important real-world impacts. The code and two applications will be publicly available at: https://github.com/NathanUA/BASNet.
Light Field Salient Object Detection: A Review and Benchmark
Oct 18, 2020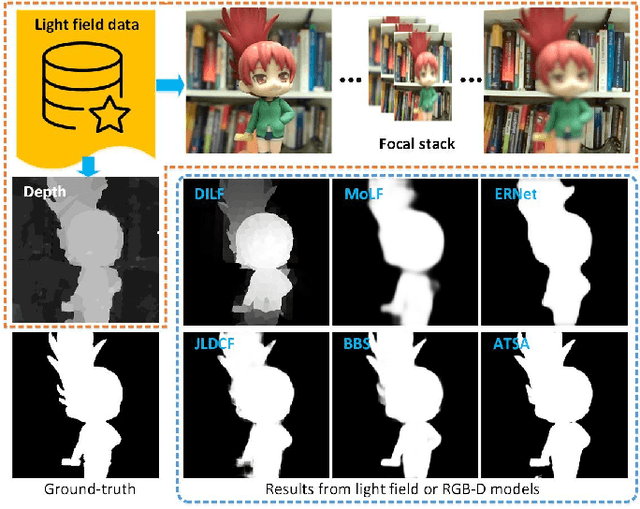

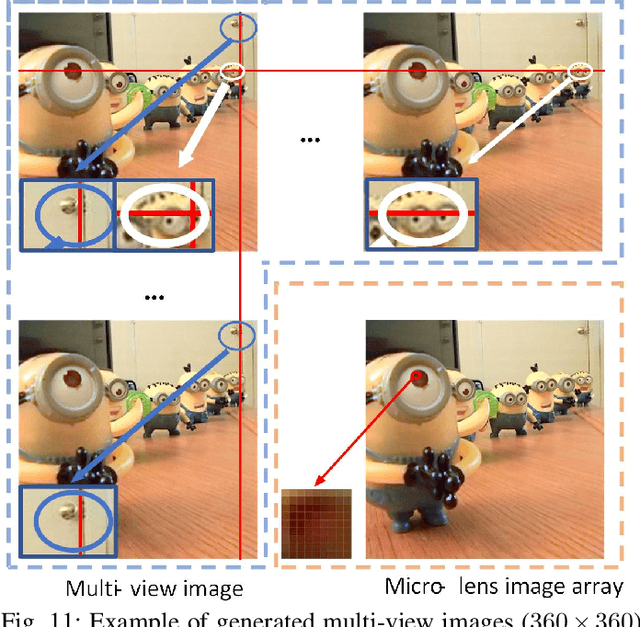
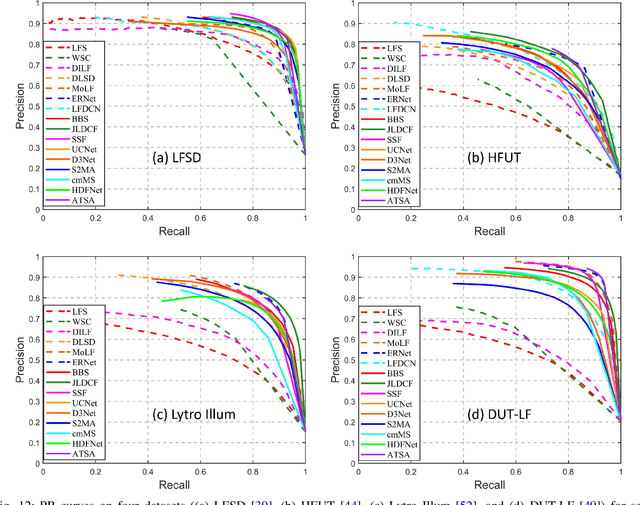
Salient object detection (SOD) is a long-standing research topic in computer vision and has drawn an increasing amount of research interest in the past decade. This paper provides the first comprehensive review and benchmark for SOD on light field, which has long been lacking in the saliency community. Firstly, we introduce preliminary knowledge on lights, including theory and data forms, and then review existing studies on light field SOD, covering ten traditional models, seven deep learning-based models, one comparative study, and one brief review. Existing datasets for light field SOD are also summarized with detailed information and statistical analyses. Secondly, we benchmark seven representative light field SOD models together with several cutting-edge RGB-D SOD models on four widely used light field datasets, from which insightful discussions and analyses, including a comparison between light field SOD and RGB-D SOD models, are achieved. Besides, due to the inconsistency of datasets in their current forms, we further generate complete data and supplement focal stacks, depth maps and multi-view images for the inconsistent datasets, making them consistent and unified. Our supplemental data makes a universal benchmark possible. Lastly, because light field SOD is quite a special problem attributed to its diverse data representations and high dependency on acquisition hardware, making it differ greatly from other saliency detection tasks, we provide nine hints into the challenges and future directions, and outline several open issues. We hope our review and benchmarking could serve as a catalyst to advance research in this field. All the materials including collected models, datasets, benchmarking results, and supplemented light field datasets will be publicly available on our project site https://github.com/kerenfu/LFSOD-Survey.
Uncertainty Inspired RGB-D Saliency Detection
Sep 07, 2020
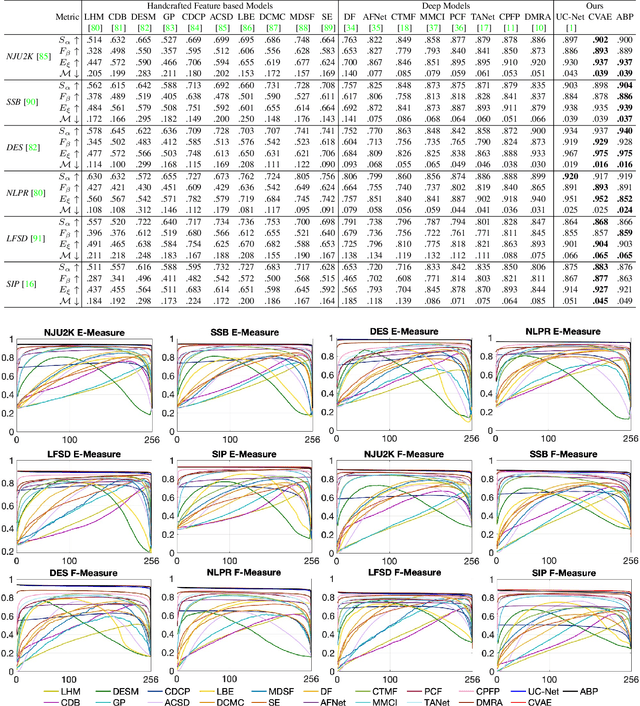
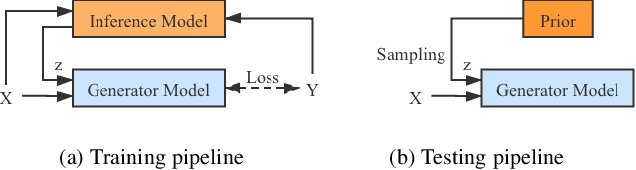

We propose the first stochastic framework to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection models treat this task as a point estimation problem by predicting a single saliency map following a deterministic learning pipeline. We argue that, however, the deterministic solution is relatively ill-posed. Inspired by the saliency data labeling process, we propose a generative architecture to achieve probabilistic RGB-D saliency detection which utilizes a latent variable to model the labeling variations. Our framework includes two main models: 1) a generator model, which maps the input image and latent variable to stochastic saliency prediction, and 2) an inference model, which gradually updates the latent variable by sampling it from the true or approximate posterior distribution. The generator model is an encoder-decoder saliency network. To infer the latent variable, we introduce two different solutions: i) a Conditional Variational Auto-encoder with an extra encoder to approximate the posterior distribution of the latent variable; and ii) an Alternating Back-Propagation technique, which directly samples the latent variable from the true posterior distribution. Qualitative and quantitative results on six challenging RGB-D benchmark datasets show our approach's superior performance in learning the distribution of saliency maps. The source code is publicly available via our project page: https://github.com/JingZhang617/UCNet.
Siamese Network for RGB-D Salient Object Detection and Beyond
Aug 26, 2020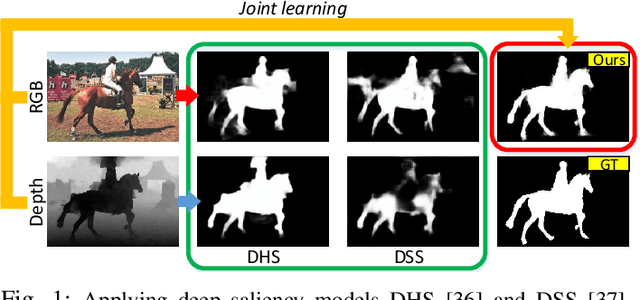

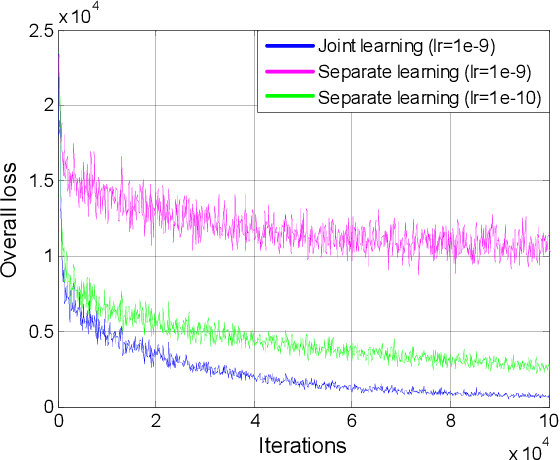

Existing RGB-D salient object detection (SOD) models usually treat RGB and depth as independent information and design separate networks for feature extraction from each. Such schemes can easily be constrained by a limited amount of training data or over-reliance on an elaborately designed training process. Inspired by the observation that RGB and depth modalities actually present certain commonality in distinguishing salient objects, a novel joint learning and densely cooperative fusion (JL-DCF) architecture is designed to learn from both RGB and depth inputs through a shared network backbone, known as the Siamese architecture. In this paper, we propose two effective components: joint learning (JL), and densely cooperative fusion (DCF). The JL module provides robust saliency feature learning by exploiting cross-modal commonality via a Siamese network, while the DCF module is introduced for complementary feature discovery. Comprehensive experiments using five popular metrics show that the designed framework yields a robust RGB-D saliency detector with good generalization. As a result, JL-DCF significantly advances the state-of-the-art models by an average of ~2.0% (F-measure) across seven challenging datasets. In addition, we show that JL-DCF is readily applicable to other related multi-modal detection tasks, including RGB-T (thermal infrared) SOD and video SOD (VSOD), achieving comparable or even better performance against state-of-the-art methods. This further confirms that the proposed framework could offer a potential solution for various applications and provide more insight into the cross-modal complementarity task. The code will be available at https://github.com/kerenfu/JLDCF/
RGB-D Salient Object Detection: A Survey
Aug 01, 2020
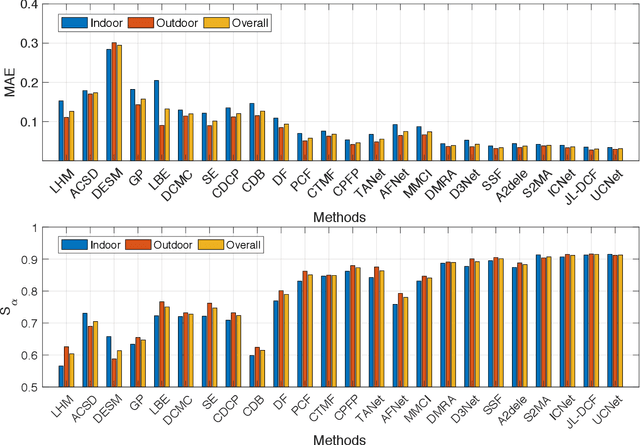


Salient object detection (SOD), which simulates the human visual perception system to locate the most attractive object(s) in a scene, has been widely applied to various computer vision tasks. Now, with the advent of depth sensors, depth maps with affluent spatial information that can be beneficial in boosting the performance of SOD, can easily be captured. Although various RGB-D based SOD models with promising performance have been proposed over the past several years, an in-depth understanding of these models and challenges in this topic remains lacking. In this paper, we provide a comprehensive survey of RGB-D based SOD models from various perspectives, and review related benchmark datasets in detail. Further, considering that the light field can also provide depth maps, we review SOD models and popular benchmark datasets from this domain as well. Moreover, to investigate the SOD ability of existing models, we carry out a comprehensive evaluation, as well as attribute-based evaluation of several representative RGB-D based SOD models. Finally, we discuss several challenges and open directions of RGB-D based SOD for future research. All collected models, benchmark datasets, source code links, datasets constructed for attribute-based evaluation, and codes for evaluation will be made publicly available at https://github.com/taozh2017/RGBDSODsurvey