 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCM3D: Object-Centric Monocular 3D Object Detection
Apr 13, 2021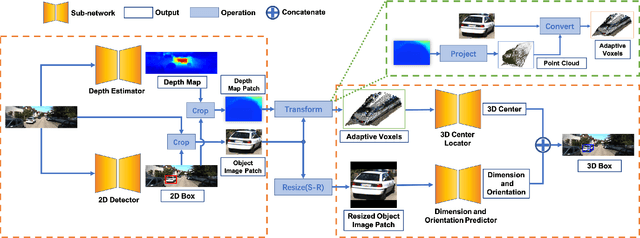
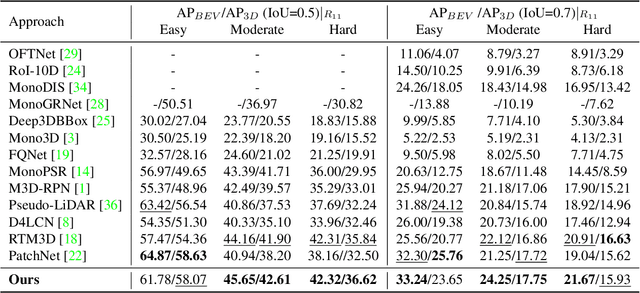
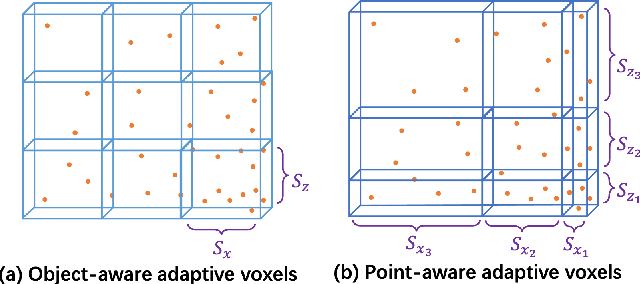

Image-only and pseudo-LiDAR representations are commonly used for monocular 3D object detection. However, methods based on them have shortcomings of either not well capturing the spatial relationships in neighbored image pixels or being hard to handle the noisy nature of the monocular pseudo-LiDAR point cloud. To overcome these issues, in this paper we propose a novel object-centric voxel representation tailored for monocular 3D object detection. Specifically, voxels are built on each object proposal, and their sizes are adaptively determined by the 3D spatial distribution of the points, allowing the noisy point cloud to be organized effectively within a voxel grid. This representation is proved to be able to locate the object in 3D space accurately. Furthermore, prior works would like to estimate the orientation via deep features extracted from an entire image or a noisy point cloud. By contrast, we argue that the local RoI information from the object image patch alone with a proper resizing scheme is a better input as it provides complete semantic clues meanwhile excludes irrelevant interferences. Besides, we decompose the confidence mechanism in monocular 3D object detection by considering the relationship between 3D objects and the associated 2D boxes. Evaluated on KITTI, our method outperforms state-of-the-art methods by a large margin. The code will be made publicly available soon.
SCALoss: Side and Corner Aligned Loss for Bounding Box Regression
Apr 01, 2021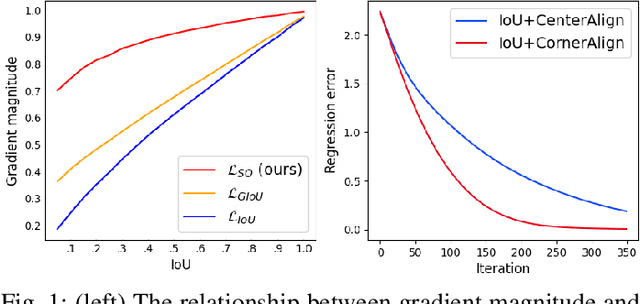
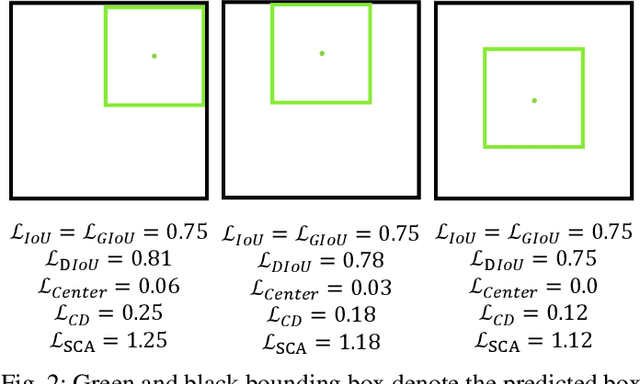
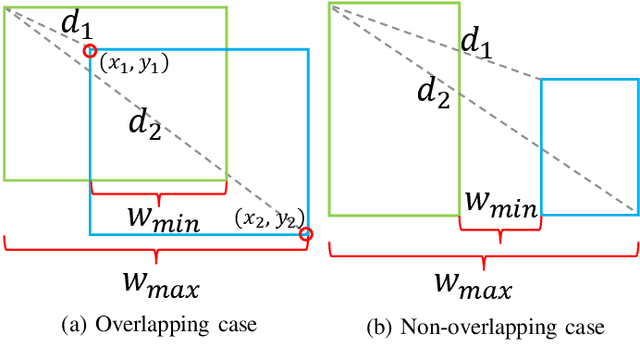
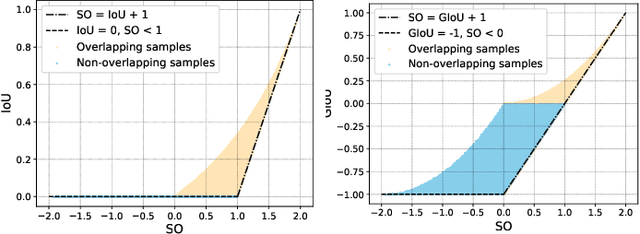
Bounding box regression is an important component in object detection. Recent work has shown the promising performance by optimizing the Intersection over Union (IoU) as loss. However, IoU-based loss has the gradient vanish problem in the case of low overlapping bounding boxes, and the model could easily ignore these simple cases. In this paper, we propose Side Overlap (SO) loss by maximizing the side overlap of two bounding boxes, which puts more penalty for low overlapping bounding box cases. Besides, to speed up the convergence, the Corner Distance (CD) is added into the objective function. Combining the Side Overlap and Corner Distance, we get a new regression objective function, Side and Corner Align Loss (SCALoss). The SCALoss is well-correlated with IoU loss, which also benefits the evaluation metric but produces more penalty for low-overlapping cases. It can serve as a comprehensive similarity measure, leading the better localization performance and faster convergence speed. Experiments on COCO and PASCAL VOC benchmarks show that SCALoss can bring consistent improvement and outperform $\ell_n$ loss and IoU based loss with popular object detectors such as YOLOV3, SSD, Reppoints, Faster-RCNN.
X-view: Non-egocentric Multi-View 3D Object Detector
Mar 24, 2021
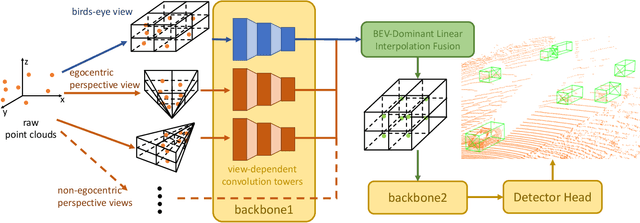

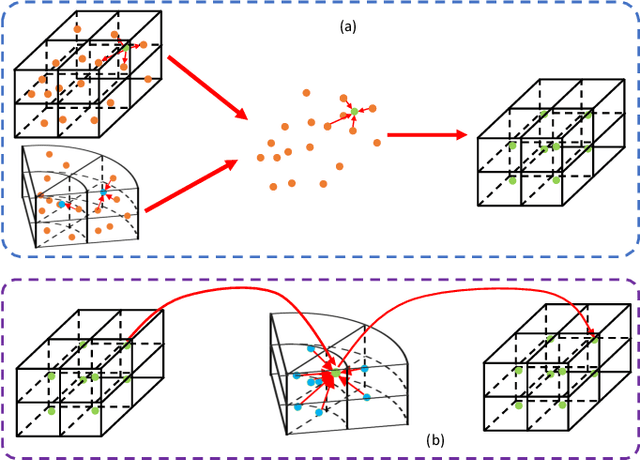
3D object detection algorithms for autonomous driving reason about 3D obstacles either from 3D birds-eye view or perspective view or both. Recent works attempt to improve the detection performance via mining and fusing from multiple egocentric views. Although the egocentric perspective view alleviates some weaknesses of the birds-eye view, the sectored grid partition becomes so coarse in the distance that the targets and surrounding context mix together, which makes the features less discriminative. In this paper, we generalize the research on 3D multi-view learning and propose a novel multi-view-based 3D detection method, named X-view, to overcome the drawbacks of the multi-view methods. Specifically, X-view breaks through the traditional limitation about the perspective view whose original point must be consistent with the 3D Cartesian coordinate. X-view is designed as a general paradigm that can be applied on almost any 3D detectors based on LiDAR with only little increment of running time, no matter it is voxel/grid-based or raw-point-based. We conduct experiments on KITTI and NuScenes datasets to demonstrate the robustness and effectiveness of our proposed X-view. The results show that X-view obtains consistent improvements when combined with four mainstream state-of-the-art 3D methods: SECOND, PointRCNN, Part-A^2, and PV-RCNN.
SparsePoint: Fully End-to-End Sparse 3D Object Detector
Mar 18, 2021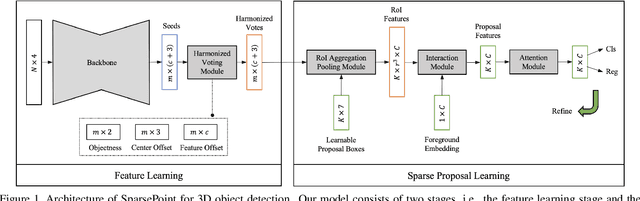
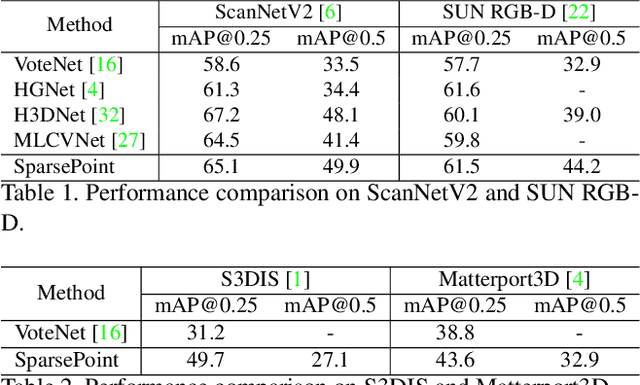
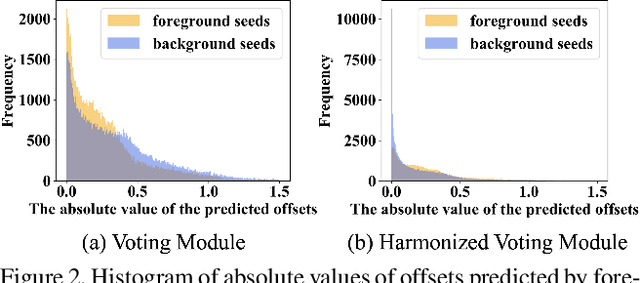
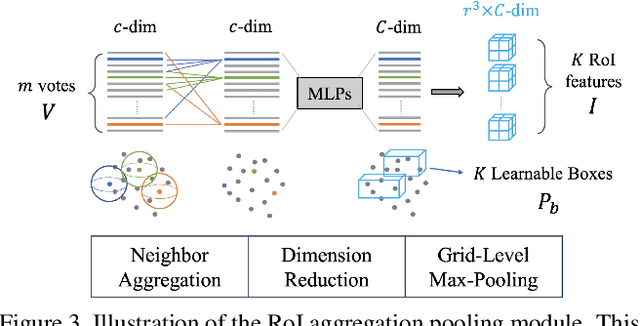
Object detectors based on sparse object proposals have recently been proven to be successful in the 2D domain, which makes it possible to establish a fully end-to-end detector without time-consuming post-processing. This development is also attractive for 3D object detectors. However, considering the remarkably larger search space in the 3D domain, whether it is feasible to adopt the sparse method in the 3D object detection setting is still an open question. In this paper, we propose SparsePoint, the first sparse method for 3D object detection. Our SparsePoint adopts a number of learnable proposals to encode most likely potential positions of 3D objects and a foreground embedding to encode shared semantic features of all objects. Besides, with the attention module to provide object-level interaction for redundant proposal removal and Hungarian algorithm to supply one-one label assignment, our method can produce sparse and accurate predictions. SparsePoint sets a new state-of-the-art on four public datasets, including ScanNetV2, SUN RGB-D, S3DIS, and Matterport3D. Our code will be publicly available soon.
DMN4: Few-shot Learning via Discriminative Mutual Nearest Neighbor Neural Network
Mar 15, 2021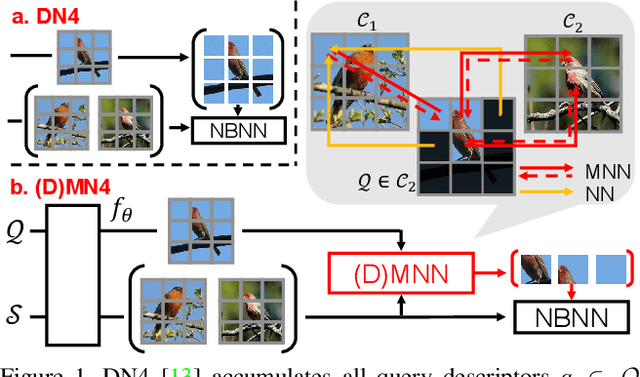
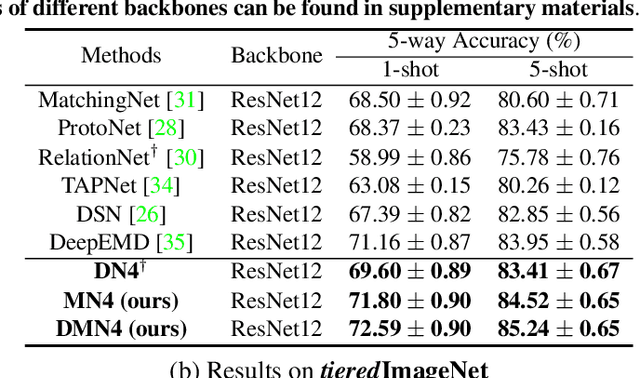
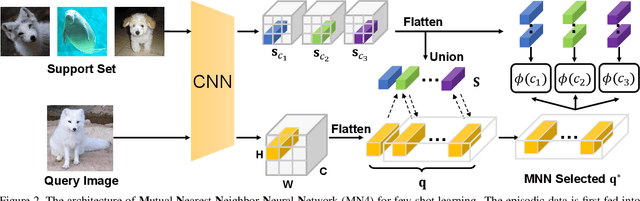
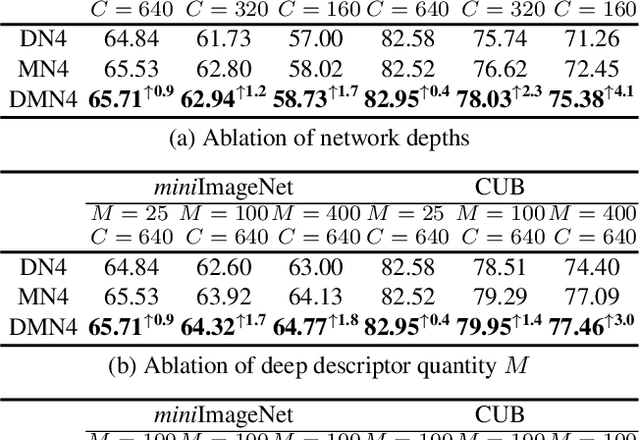
Few-shot learning (FSL) aims to classify images under low-data regimes, where the conventional pooled global representation is likely to lose useful local characteristics. Recent work has achieved promising performances by using deep descriptors. They generally take all deep descriptors from neural networks into consideration while ignoring that some of them are useless in classification due to their limited receptive field, e.g., task-irrelevant descriptors could be misleading and multiple aggregative descriptors from background clutter could even overwhelm the object's presence. In this paper, we argue that a Mutual Nearest Neighbor (MNN) relation should be established to explicitly select the query descriptors that are most relevant to each task and discard less relevant ones from aggregative clutters in FSL. Specifically, we propose Discriminative Mutual Nearest Neighbor Neural Network (DMN4) for FSL. Extensive experiments demonstrate that our method not only qualitatively selects task-relevant descriptors but also quantitatively outperforms the existing state-of-the-arts by a large margin of 1.8~4.9% on fine-grained CUB, a considerable margin of 1.4~2.2% on both supervised and semi-supervised miniImagenet, and ~1.4% on challenging tieredimagenet.
ES-Net: Erasing Salient Parts to Learn More in Re-Identification
Mar 10, 2021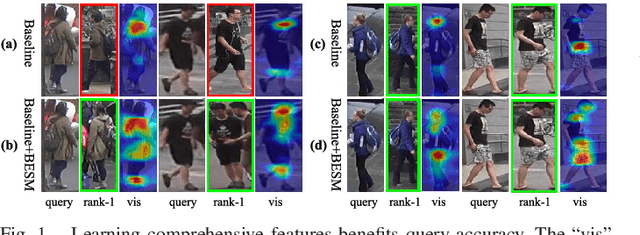
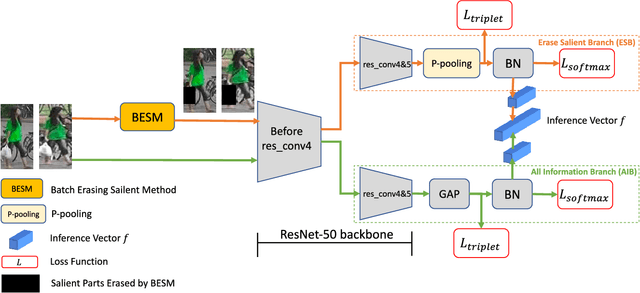
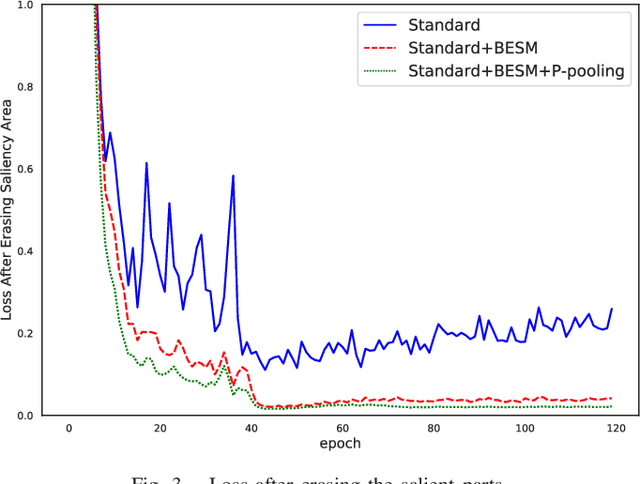

As an instance-level recognition problem, re-identification (re-ID) requires models to capture diverse features. However, with continuous training, re-ID models pay more and more attention to the salient areas. As a result, the model may only focus on few small regions with salient representations and ignore other important information. This phenomenon leads to inferior performance, especially when models are evaluated on small inter-identity variation data. In this paper, we propose a novel network, Erasing-Salient Net (ES-Net), to learn comprehensive features by erasing the salient areas in an image. ES-Net proposes a novel method to locate the salient areas by the confidence of objects and erases them efficiently in a training batch. Meanwhile, to mitigate the over-erasing problem, this paper uses a trainable pooling layer P-pooling that generalizes global max and global average pooling. Experiments are conducted on two specific re-identification tasks (i.e., Person re-ID, Vehicle re-ID). Our ES-Net outperforms state-of-the-art methods on three Person re-ID benchmarks and two Vehicle re-ID benchmarks. Specifically, mAP / Rank-1 rate: 88.6% / 95.7% on Market1501, 78.8% / 89.2% on DuckMTMC-reID, 57.3% / 80.9% on MSMT17, 81.9% / 97.0% on Veri-776, respectively. Rank-1 / Rank-5 rate: 83.6% / 96.9% on VehicleID (Small), 79.9% / 93.5% on VehicleID (Medium), 76.9% / 90.7% on VehicleID (Large), respectively. Moreover, the visualized salient areas show human-interpretable visual explanations for the ranking results.
* 11 pages, 6 figures. Accepted for publication in IEEE Transactions on Image Processing 2021
Non-Autoregressive Text Generation with Pre-trained Language Models
Feb 16, 2021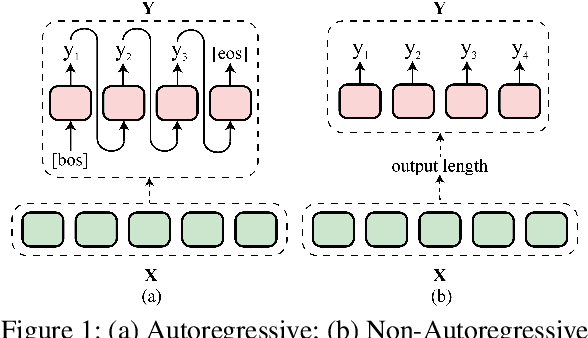
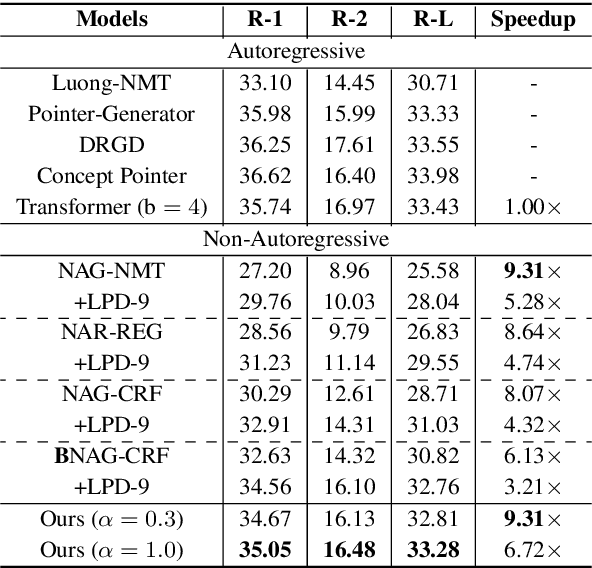
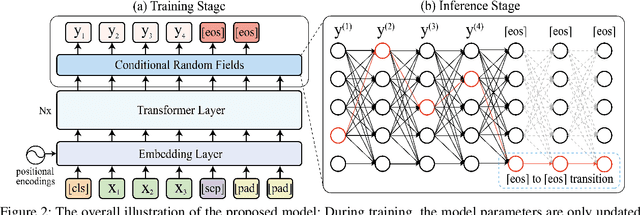
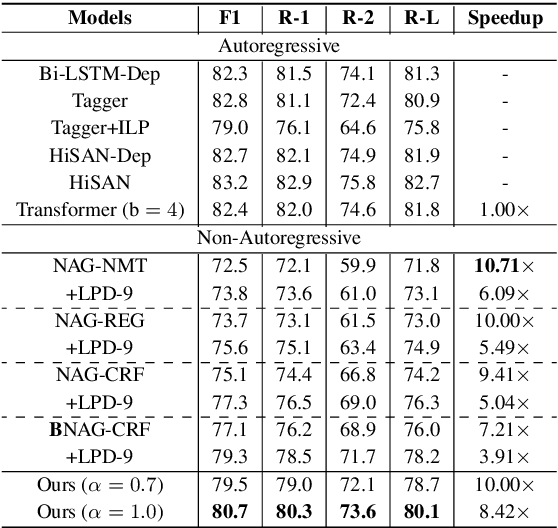
Non-autoregressive generation (NAG) has recently attracted great attention due to its fast inference speed. However, the generation quality of existing NAG models still lags behind their autoregressive counterparts. In this work, we show that BERT can be employed as the backbone of a NAG model to greatly improve performance. Additionally, we devise mechanisms to alleviate the two common problems of vanilla NAG models: the inflexibility of prefixed output length and the conditional independence of individual token predictions. Lastly, to further increase the speed advantage of the proposed model, we propose a new decoding strategy, ratio-first, for applications where the output lengths can be approximately estimated beforehand. For a comprehensive evaluation, we test the proposed model on three text generation tasks, including text summarization, sentence compression and machine translation. Experimental results show that our model significantly outperforms existing non-autoregressive baselines and achieves competitive performance with many strong autoregressive models. In addition, we also conduct extensive analysis experiments to reveal the effect of each proposed component.
Complementary Pseudo Labels For Unsupervised Domain Adaptation On Person Re-identification
Feb 07, 2021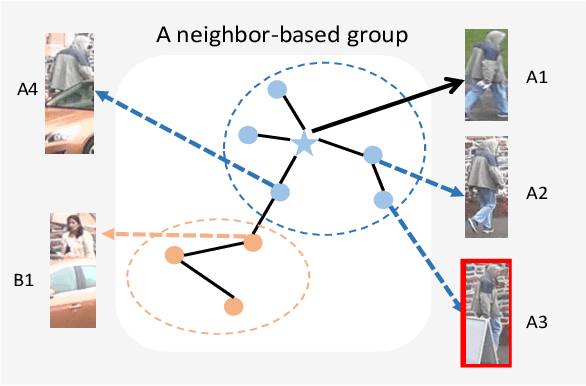
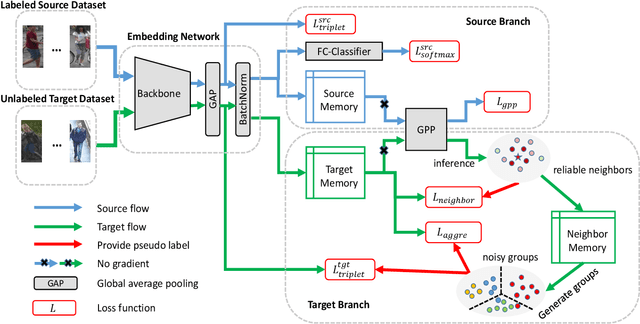
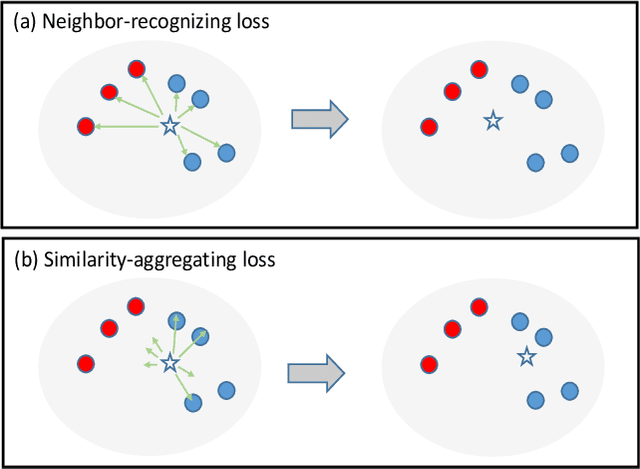
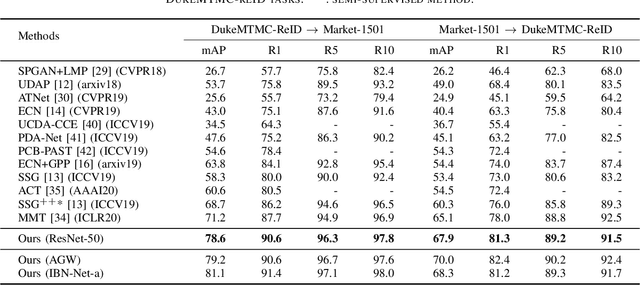
In recent years, supervised person re-identification (re-ID) models have received increasing studies. However, these models trained on the source domain always suffer dramatic performance drop when tested on an unseen domain. Existing methods are primary to use pseudo labels to alleviate this problem. One of the most successful approaches predicts neighbors of each unlabeled image and then uses them to train the model. Although the predicted neighbors are credible, they always miss some hard positive samples, which may hinder the model from discovering important discriminative information of the unlabeled domain. In this paper, to complement these low recall neighbor pseudo labels, we propose a joint learning framework to learn better feature embeddings via high precision neighbor pseudo labels and high recall group pseudo labels. The group pseudo labels are generated by transitively merging neighbors of different samples into a group to achieve higher recall. However, the merging operation may cause subgroups in the group due to imperfect neighbor predictions. To utilize these group pseudo labels properly, we propose using a similarity-aggregating loss to mitigate the influence of these subgroups by pulling the input sample towards the most similar embeddings. Extensive experiments on three large-scale datasets demonstrate that our method can achieve state-of-the-art performance under the unsupervised domain adaptation re-ID setting.
Dialogue Response Selection with Hierarchical Curriculum Learning
Dec 29, 2020
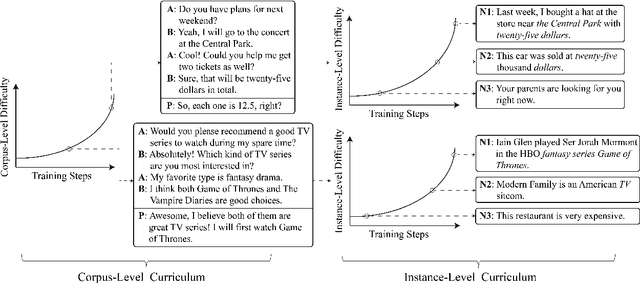
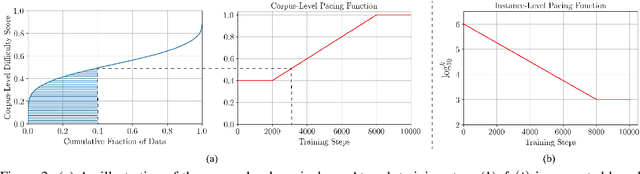
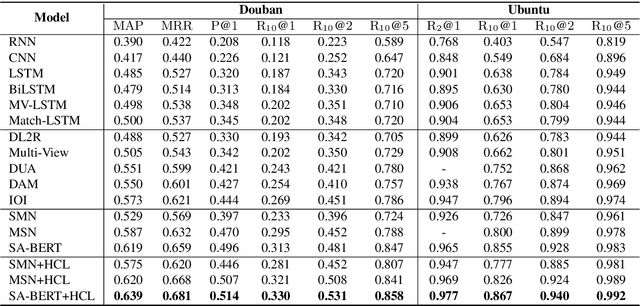
We study the learning of a matching model for dialogue response selection. Motivated by the recent finding that random negatives are often too trivial to train a reliable model, we propose a hierarchical curriculum learning (HCL) framework that consists of two complementary curricula: (1) corpus-level curriculum (CC); and (2) instance-level curriculum (IC). In CC, the model gradually increases its ability in finding the matching clues between the dialogue context and response. On the other hand, IC progressively strengthens the model's ability in identifying the mismatched information between the dialogue context and response. Empirical studies on two benchmark datasets with three state-of-the-art matching models demonstrate that the proposed HCL significantly improves the model performance across various evaluation metrics.
SplitNet: Divide and Co-training
Dec 29, 2020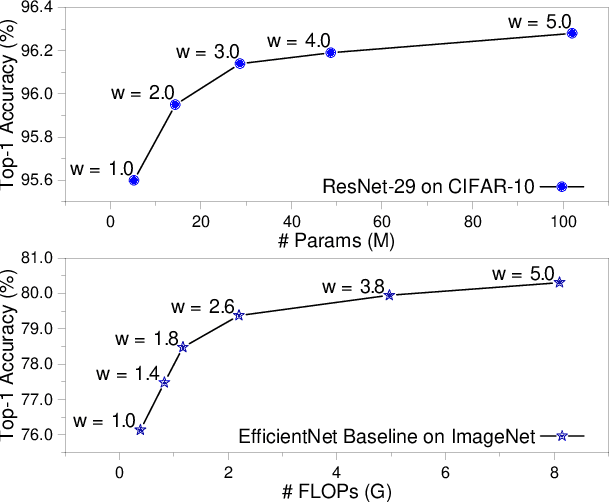

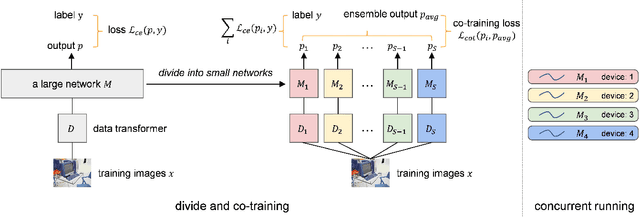
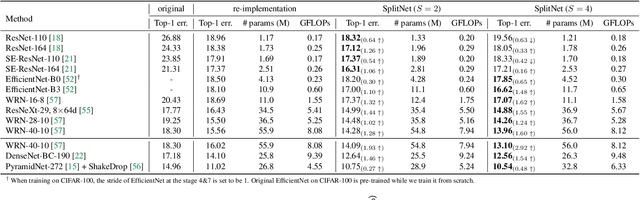
The width of a neural network matters since increasing the width will necessarily increase the model capacity. However, the performance of a network does not improve linearly with the width and soon gets saturated. To tackle this problem, we propose to increase the number of networks rather than purely scaling up the width. To prove it, one large network is divided into several small ones, and each of these small networks has a fraction of the original one's parameters. We then train these small networks together and make them see various views of the same data to learn different and complementary knowledge. During this co-training process, networks can also learn from each other. As a result, small networks can achieve better ensemble performance than the large one with few or no extra parameters or FLOPs. \emph{This reveals that the number of networks is a new dimension of effective model scaling, besides depth/width/resolution}. Small networks can also achieve faster inference speed than the large one by concurrent running on different devices. We validate the idea -- increasing the number of networks is a new dimension of effective model scaling -- with different network architectures on common benchmarks through extensive experiments. The code is available at \url{https://github.com/mzhaoshuai/SplitNet-Divide-and-Co-training}.