 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInadequately Pre-trained Models are Better Feature Extractors
Mar 09, 2022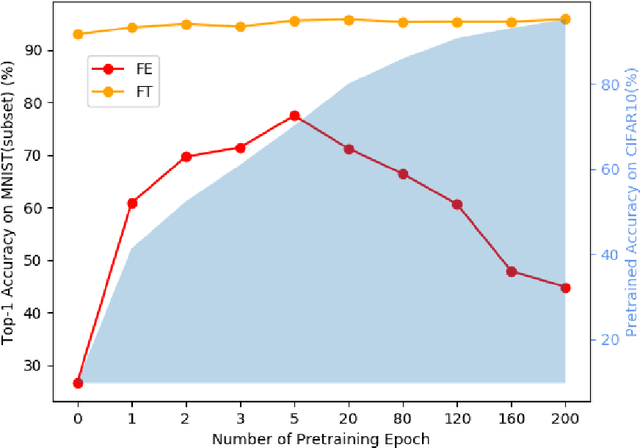
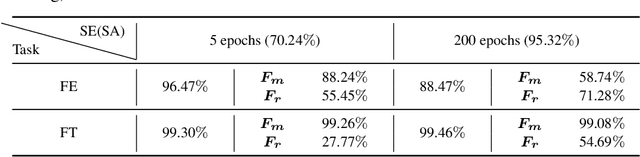
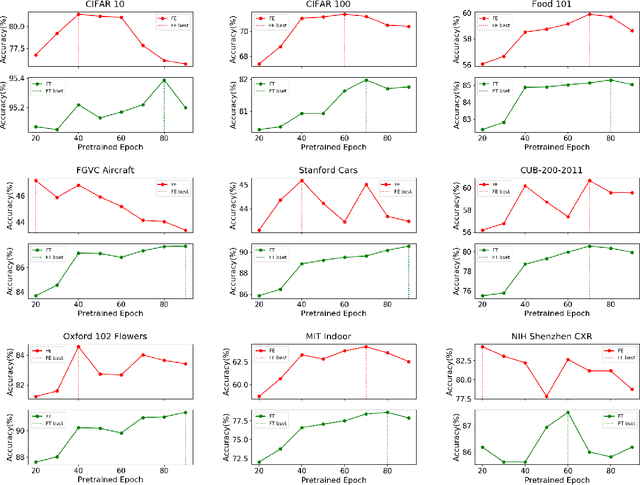
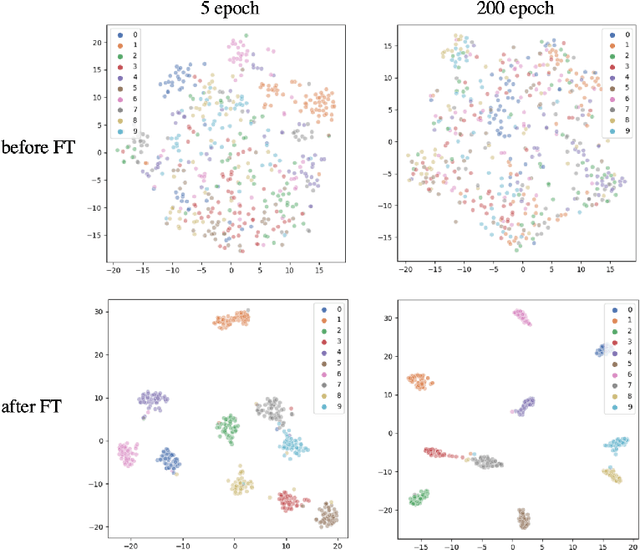
Pre-training has been a popular learning paradigm in deep learning era, especially in annotation-insufficient scenario. Better ImageNet pre-trained models have been demonstrated, from the perspective of architecture, by previous research to have better transferability to downstream tasks. However, in this paper, we found that during the same pre-training process, models at middle epochs, which is inadequately pre-trained, can outperform fully trained models when used as feature extractors (FE), while the fine-tuning (FT) performance still grows with the source performance. This reveals that there is not a solid positive correlation between top-1 accuracy on ImageNet and the transferring result on target data. Based on the contradictory phenomenon between FE and FT that better feature extractor fails to be fine-tuned better accordingly, we conduct comprehensive analyses on features before softmax layer to provide insightful explanations. Our discoveries suggest that, during pre-training, models tend to first learn spectral components corresponding to large singular values and the residual components contribute more when fine-tuning.
Learning Moving-Object Tracking with FMCW LiDAR
Mar 02, 2022

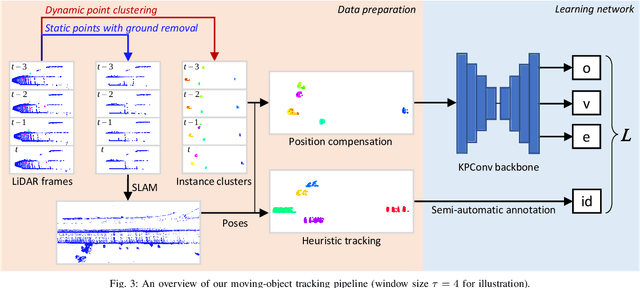
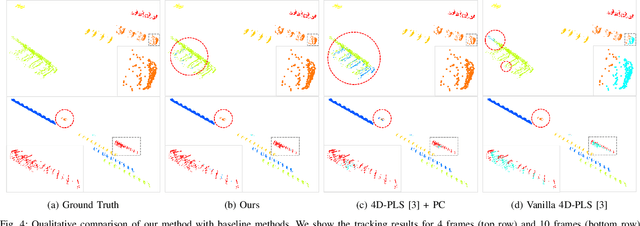
In this paper, we propose a learning-based moving-object tracking method utilizing our newly developed LiDAR sensor, Frequency Modulated Continuous Wave (FMCW) LiDAR. Compared with most existing commercial LiDAR sensors, our FMCW LiDAR can provide additional Doppler velocity information to each 3D point of the point clouds. Benefiting from this, we can generate instance labels as ground truth in a semi-automatic manner. Given the labels, we propose a contrastive learning framework, which pulls together the features from the same instance in embedding space and pushes apart the features from different instances, to improve the tracking quality. Extensive experiments are conducted on our recorded driving data, and the results show that our method outperforms the baseline methods by a large margin.
Predicting Patient Readmission Risk from Medical Text via Knowledge Graph Enhanced Multiview Graph Convolution
Dec 19, 2021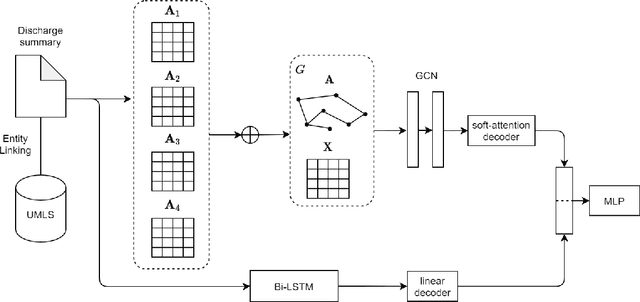
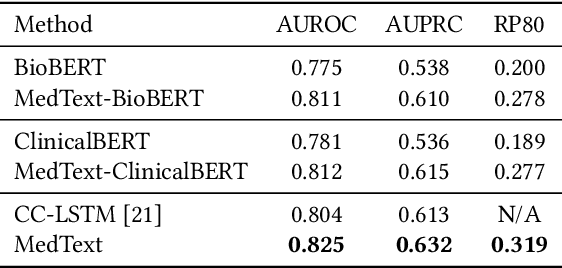
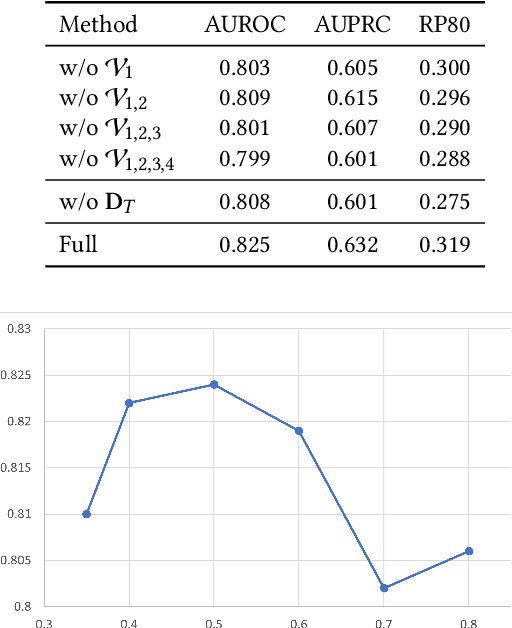
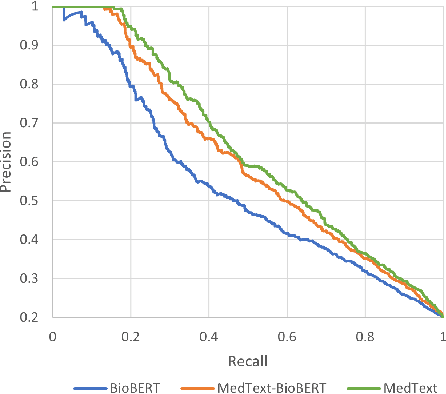
Unplanned intensive care unit (ICU) readmission rate is an important metric for evaluating the quality of hospital care. Efficient and accurate prediction of ICU readmission risk can not only help prevent patients from inappropriate discharge and potential dangers, but also reduce associated costs of healthcare. In this paper, we propose a new method that uses medical text of Electronic Health Records (EHRs) for prediction, which provides an alternative perspective to previous studies that heavily depend on numerical and time-series features of patients. More specifically, we extract discharge summaries of patients from their EHRs, and represent them with multiview graphs enhanced by an external knowledge graph. Graph convolutional networks are then used for representation learning. Experimental results prove the effectiveness of our method, yielding state-of-the-art performance for this task.
Efficient Device Scheduling with Multi-Job Federated Learning
Dec 15, 2021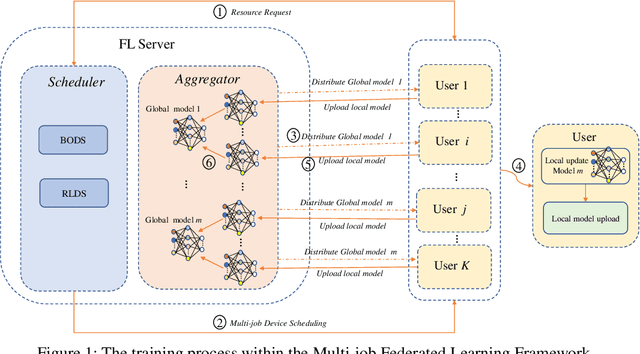
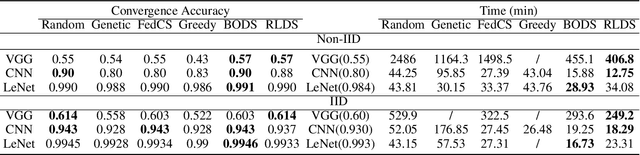
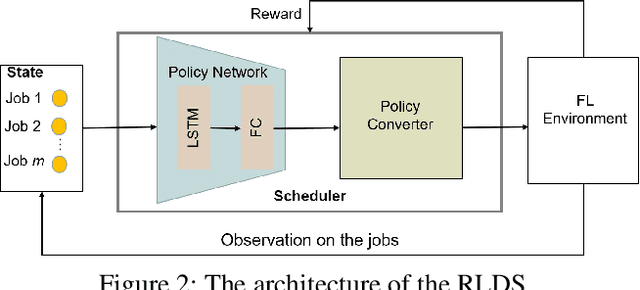
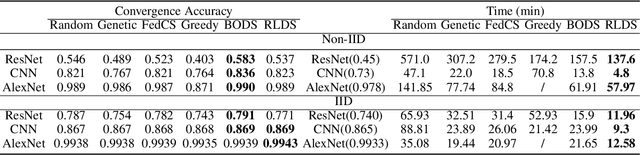
Recent years have witnessed a large amount of decentralized data in multiple (edge) devices of end-users, while the aggregation of the decentralized data remains difficult for machine learning jobs due to laws or regulations. Federated Learning (FL) emerges as an effective approach to handling decentralized data without sharing the sensitive raw data, while collaboratively training global machine learning models. The servers in FL need to select (and schedule) devices during the training process. However, the scheduling of devices for multiple jobs with FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework to enable the parallel training process of multiple jobs. The framework consists of a system model and two scheduling methods. In the system model, we propose a parallel training process of multiple jobs, and construct a cost model based on the training time and the data fairness of various devices during the training process of diverse jobs. We propose a reinforcement learning-based method and a Bayesian optimization-based method to schedule devices for multiple jobs while minimizing the cost. We conduct extensive experimentation with multiple jobs and datasets. The experimental results show that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 8.67 times faster) and accuracy (up to 44.6% higher).
HeterPS: Distributed Deep Learning With Reinforcement Learning Based Scheduling in Heterogeneous Environments
Nov 20, 2021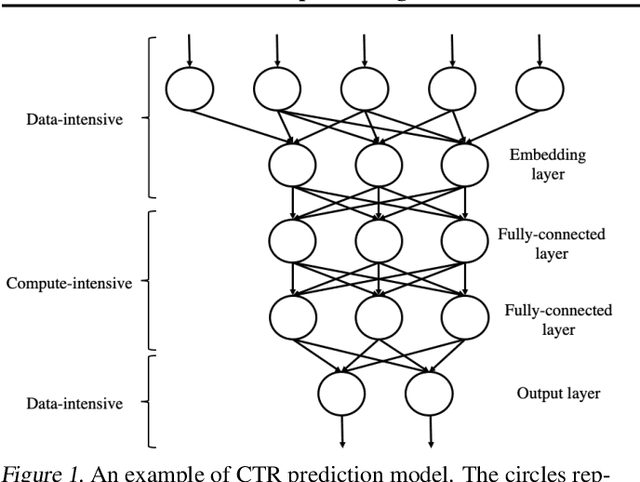

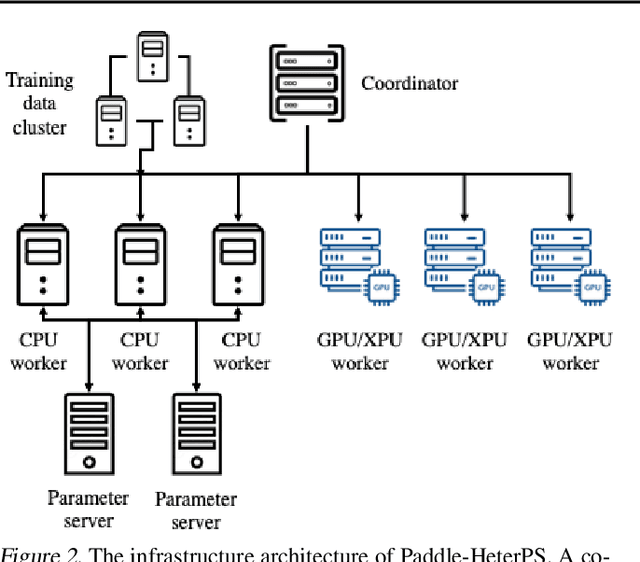
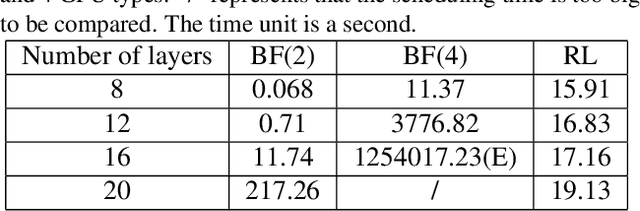
Deep neural networks (DNNs) exploit many layers and a large number of parameters to achieve excellent performance. The training process of DNN models generally handles large-scale input data with many sparse features, which incurs high Input/Output (IO) cost, while some layers are compute-intensive. The training process generally exploits distributed computing resources to reduce training time. In addition, heterogeneous computing resources, e.g., CPUs, GPUs of multiple types, are available for the distributed training process. Thus, the scheduling of multiple layers to diverse computing resources is critical for the training process. To efficiently train a DNN model using the heterogeneous computing resources, we propose a distributed framework, i.e., Paddle-Heterogeneous Parameter Server (Paddle-HeterPS), composed of a distributed architecture and a Reinforcement Learning (RL)-based scheduling method. The advantages of Paddle-HeterPS are three-fold compared with existing frameworks. First, Paddle-HeterPS enables efficient training process of diverse workloads with heterogeneous computing resources. Second, Paddle-HeterPS exploits an RL-based method to efficiently schedule the workload of each layer to appropriate computing resources to minimize the cost while satisfying throughput constraints. Third, Paddle-HeterPS manages data storage and data communication among distributed computing resources. We carry out extensive experiments to show that Paddle-HeterPS significantly outperforms state-of-the-art approaches in terms of throughput (14.5 times higher) and monetary cost (312.3% smaller). The codes of the framework are publicly available at: https://github.com/PaddlePaddle/Paddle.
Hierarchical Heterogeneous Graph Representation Learning for Short Text Classification
Oct 30, 2021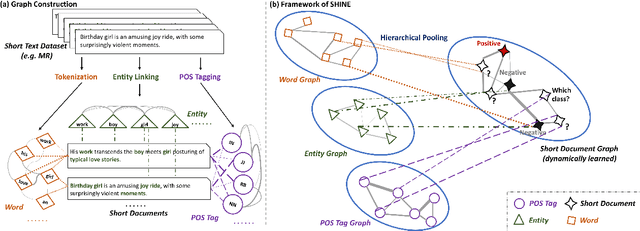
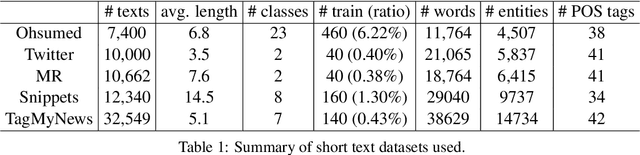
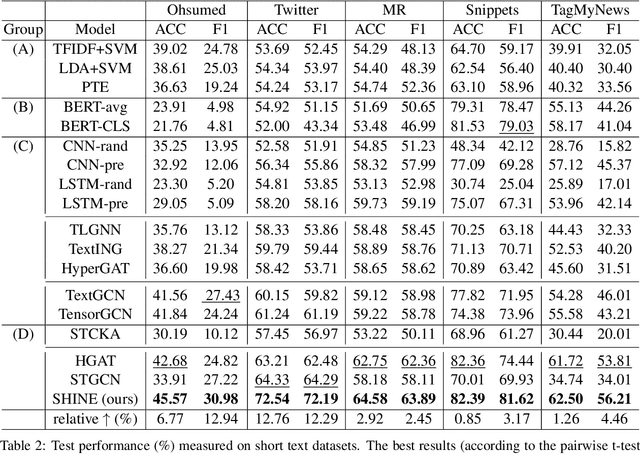
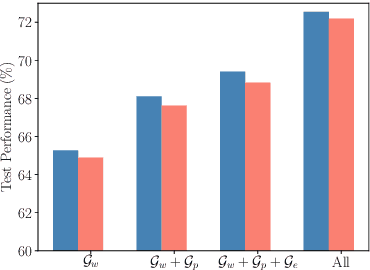
Short text classification is a fundamental task in natural language processing. It is hard due to the lack of context information and labeled data in practice. In this paper, we propose a new method called SHINE, which is based on graph neural network (GNN), for short text classification. First, we model the short text dataset as a hierarchical heterogeneous graph consisting of word-level component graphs which introduce more semantic and syntactic information. Then, we dynamically learn a short document graph that facilitates effective label propagation among similar short texts. Thus, compared with existing GNN-based methods, SHINE can better exploit interactions between nodes of the same types and capture similarities between short texts. Extensive experiments on various benchmark short text datasets show that SHINE consistently outperforms state-of-the-art methods, especially with fewer labels.
Generalized Data Weighting via Class-level Gradient Manipulation
Oct 29, 2021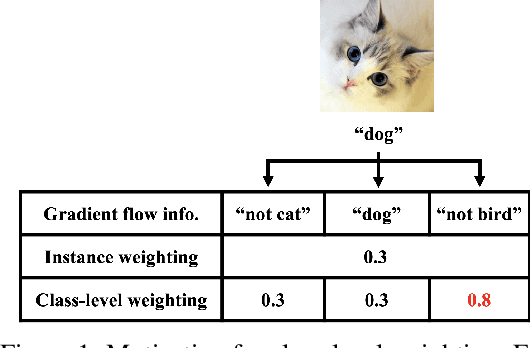


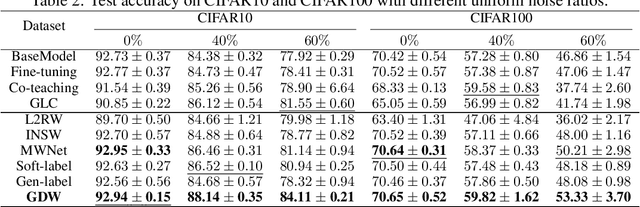
Label noise and class imbalance are two major issues coexisting in real-world datasets. To alleviate the two issues, state-of-the-art methods reweight each instance by leveraging a small amount of clean and unbiased data. Yet, these methods overlook class-level information within each instance, which can be further utilized to improve performance. To this end, in this paper, we propose Generalized Data Weighting (GDW) to simultaneously mitigate label noise and class imbalance by manipulating gradients at the class level. To be specific, GDW unrolls the loss gradient to class-level gradients by the chain rule and reweights the flow of each gradient separately. In this way, GDW achieves remarkable performance improvement on both issues. Aside from the performance gain, GDW efficiently obtains class-level weights without introducing any extra computational cost compared with instance weighting methods. Specifically, GDW performs a gradient descent step on class-level weights, which only relies on intermediate gradients. Extensive experiments in various settings verify the effectiveness of GDW. For example, GDW outperforms state-of-the-art methods by $2.56\%$ under the $60\%$ uniform noise setting in CIFAR10. Our code is available at https://github.com/GGchen1997/GDW-NIPS2021.
SenseMag: Enabling Low-Cost Traffic Monitoring using Non-invasive Magnetic Sensing
Oct 24, 2021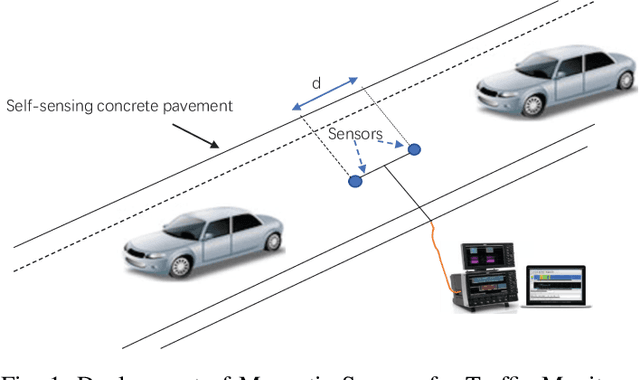

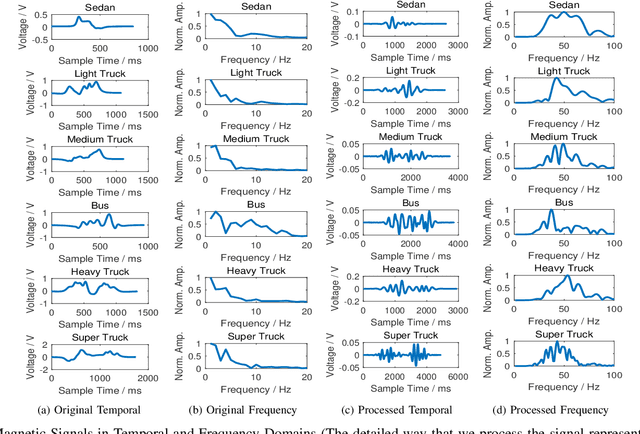
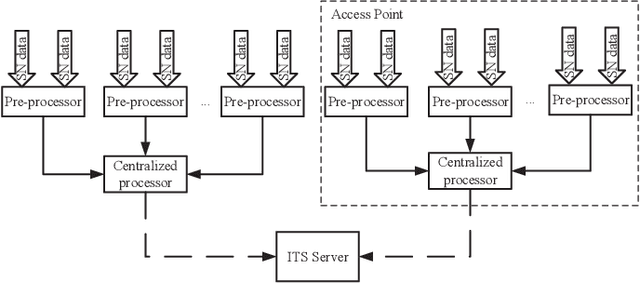
The operation and management of intelligent transportation systems (ITS), such as traffic monitoring, relies on real-time data aggregation of vehicular traffic information, including vehicular types (e.g., cars, trucks, and buses), in the critical roads and highways. While traditional approaches based on vehicular-embedded GPS sensors or camera networks would either invade drivers' privacy or require high deployment cost, this paper introduces a low-cost method, namely SenseMag, to recognize the vehicular type using a pair of non-invasive magnetic sensors deployed on the straight road section. SenseMag filters out noises and segments received magnetic signals by the exact time points that the vehicle arrives or departs from every sensor node. Further, SenseMag adopts a hierarchical recognition model to first estimate the speed/velocity, then identify the length of vehicle using the predicted speed, sampling cycles, and the distance between the sensor nodes. With the vehicle length identified and the temporal/spectral features extracted from the magnetic signals, SenseMag classify the types of vehicles accordingly. Some semi-automated learning techniques have been adopted for the design of filters, features, and the choice of hyper-parameters. Extensive experiment based on real-word field deployment (on the highways in Shenzhen, China) shows that SenseMag significantly outperforms the existing methods in both classification accuracy and the granularity of vehicle types (i.e., 7 types by SenseMag versus 4 types by the existing work in comparisons). To be specific, our field experiment results validate that SenseMag is with at least $90\%$ vehicle type classification accuracy and less than 5\% vehicle length classification error.
AgFlow: Fast Model Selection of Penalized PCA via Implicit Regularization Effects of Gradient Flow
Oct 07, 2021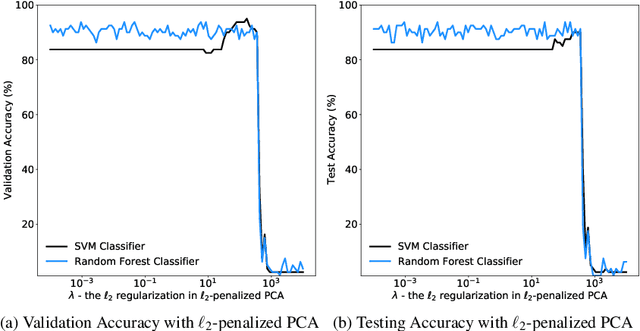
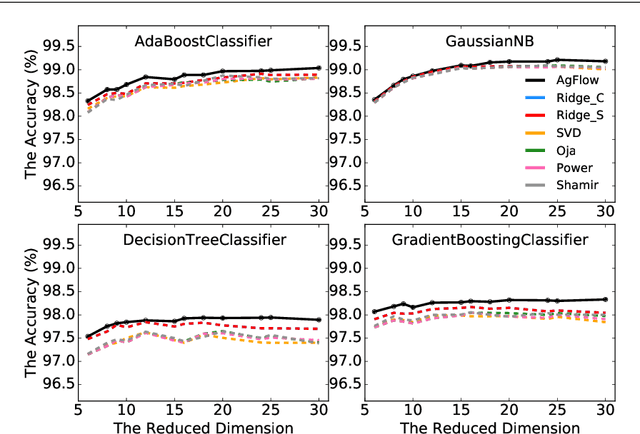
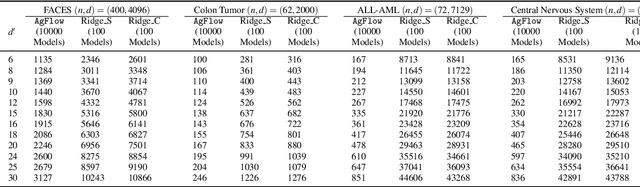
Principal component analysis (PCA) has been widely used as an effective technique for feature extraction and dimension reduction. In the High Dimension Low Sample Size (HDLSS) setting, one may prefer modified principal components, with penalized loadings, and automated penalty selection by implementing model selection among these different models with varying penalties. The earlier work [1, 2] has proposed penalized PCA, indicating the feasibility of model selection in $L_2$- penalized PCA through the solution path of Ridge regression, however, it is extremely time-consuming because of the intensive calculation of matrix inverse. In this paper, we propose a fast model selection method for penalized PCA, named Approximated Gradient Flow (AgFlow), which lowers the computation complexity through incorporating the implicit regularization effect introduced by (stochastic) gradient flow [3, 4] and obtains the complete solution path of $L_2$-penalized PCA under varying $L_2$-regularization. We perform extensive experiments on real-world datasets. AgFlow outperforms existing methods (Oja [5], Power [6], and Shamir [7] and the vanilla Ridge estimators) in terms of computation costs.
Exploring the Common Principal Subspace of Deep Features in Neural Networks
Oct 06, 2021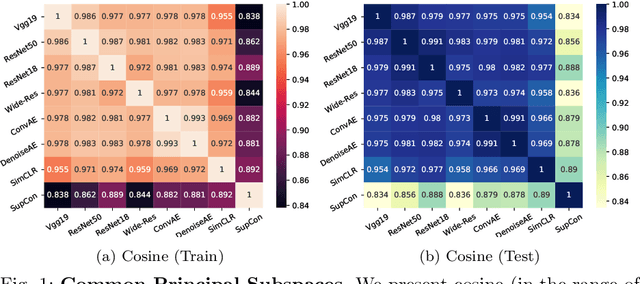

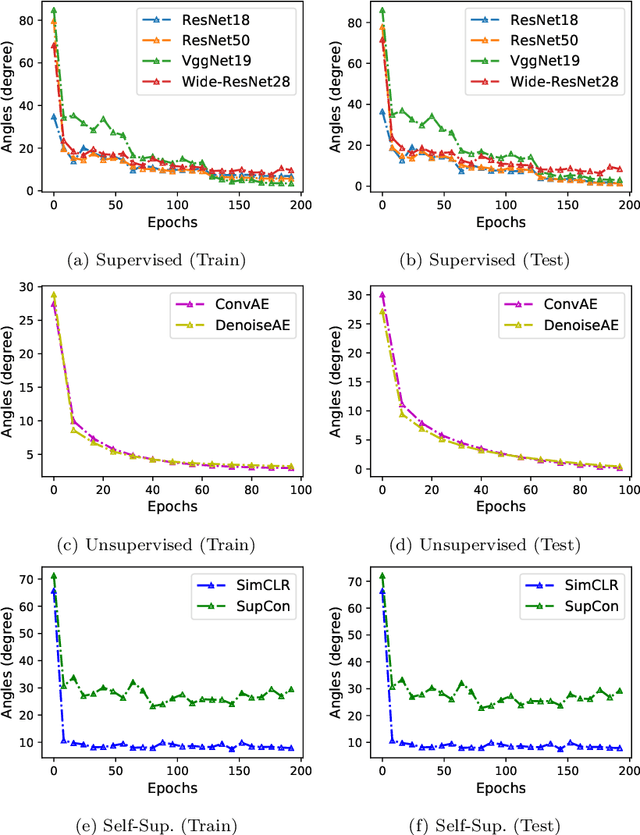
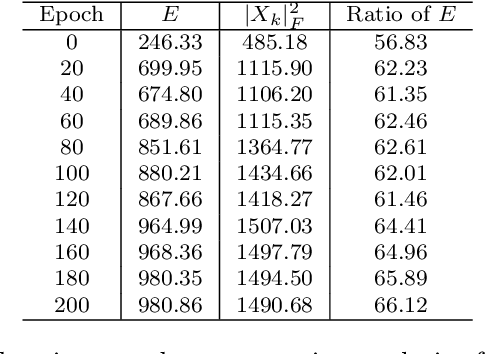
We find that different Deep Neural Networks (DNNs) trained with the same dataset share a common principal subspace in latent spaces, no matter in which architectures (e.g., Convolutional Neural Networks (CNNs), Multi-Layer Preceptors (MLPs) and Autoencoders (AEs)) the DNNs were built or even whether labels have been used in training (e.g., supervised, unsupervised, and self-supervised learning). Specifically, we design a new metric $\mathcal{P}$-vector to represent the principal subspace of deep features learned in a DNN, and propose to measure angles between the principal subspaces using $\mathcal{P}$-vectors. Small angles (with cosine close to $1.0$) have been found in the comparisons between any two DNNs trained with different algorithms/architectures. Furthermore, during the training procedure from random scratch, the angle decrease from a larger one ($70^\circ-80^\circ$ usually) to the small one, which coincides the progress of feature space learning from scratch to convergence. Then, we carry out case studies to measure the angle between the $\mathcal{P}$-vector and the principal subspace of training dataset, and connect such angle with generalization performance. Extensive experiments with practically-used Multi-Layer Perceptron (MLPs), AEs and CNNs for classification, image reconstruction, and self-supervised learning tasks on MNIST, CIFAR-10 and CIFAR-100 datasets have been done to support our claims with solid evidences. Interpretability of Deep Learning, Feature Learning, and Subspaces of Deep Features