 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Code Sketches
Jun 18, 2021

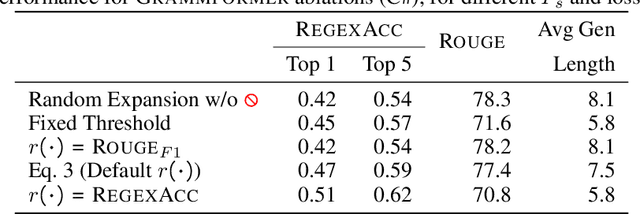
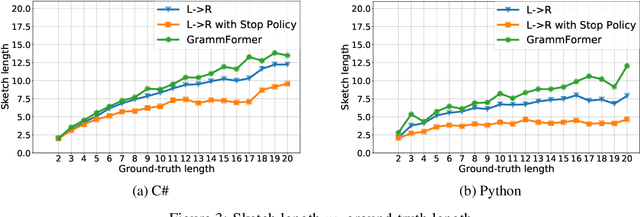
Traditional generative models are limited to predicting sequences of terminal tokens. However, ambiguities in the generation task may lead to incorrect outputs. Towards addressing this, we introduce Grammformers, transformer-based grammar-guided models that learn (without explicit supervision) to generate sketches -- sequences of tokens with holes. Through reinforcement learning, Grammformers learn to introduce holes avoiding the generation of incorrect tokens where there is ambiguity in the target task. We train Grammformers for statement-level source code completion, i.e., the generation of code snippets given an ambiguous user intent, such as a partial code context. We evaluate Grammformers on code completion for C# and Python and show that it generates 10-50% more accurate sketches compared to traditional generative models and 37-50% longer sketches compared to sketch-generating baselines trained with similar techniques.
AR-LSAT: Investigating Analytical Reasoning of Text
Apr 15, 2021



Analytical reasoning is an essential and challenging task that requires a system to analyze a scenario involving a set of particular circumstances and perform reasoning over it to make conclusions. In this paper, we study the challenge of analytical reasoning of text and introduce a new dataset consisting of questions from the Law School Admission Test from 1991 to 2016. We analyze what knowledge understanding and reasoning abilities are required to do well on this task. Furthermore, to address this reasoning challenge, we design two different baselines: (1) a Transformer-based method which leverages the state-of-the-art pre-trained language models and (2) Analytical Reasoning Machine (ARM), a logical-level reasoning framework extracting symbolic knowledge (e.g, participants, facts, logical functions) to deduce legitimate solutions. In our experiments, we find that the Transformer-based models struggle to solve this task as their performance is close to random guess and ARM achieves better performance by leveraging symbolic knowledge and interpretable reasoning steps. Results show that both methods still lag far behind human performance, which leave further space for future research.
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
Feb 09, 2021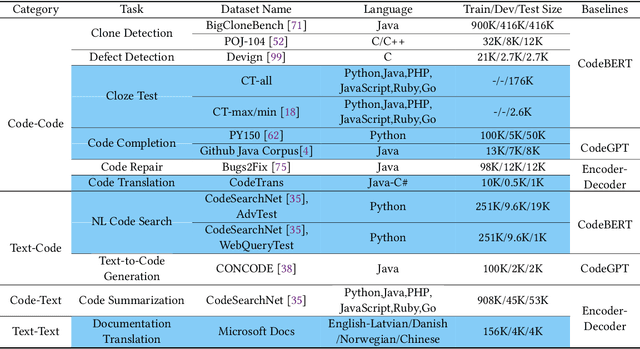

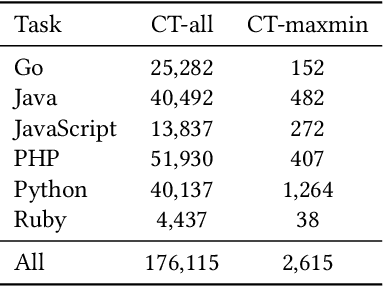

Benchmark datasets have a significant impact on accelerating research in programming language tasks. In this paper, we introduce CodeXGLUE, a benchmark dataset to foster machine learning research for program understanding and generation. CodeXGLUE includes a collection of 10 tasks across 14 datasets and a platform for model evaluation and comparison. CodeXGLUE also features three baseline systems, including the BERT-style, GPT-style, and Encoder-Decoder models, to make it easy for researchers to use the platform. The availability of such data and baselines can help the development and validation of new methods that can be applied to various program understanding and generation problems.
Syntax-Enhanced Pre-trained Model
Dec 28, 2020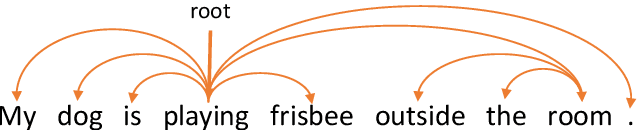
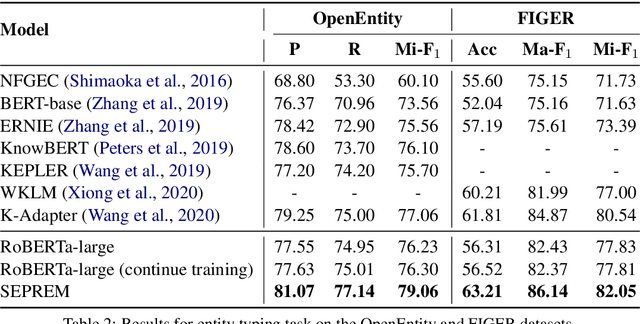
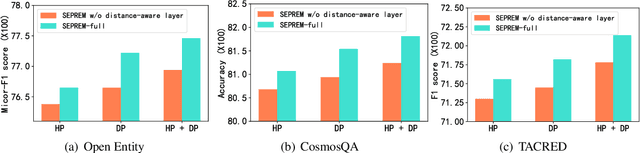
We study the problem of leveraging the syntactic structure of text to enhance pre-trained models such as BERT and RoBERTa. Existing methods utilize syntax of text either in the pre-training stage or in the fine-tuning stage, so that they suffer from discrepancy between the two stages. Such a problem would lead to the necessity of having human-annotated syntactic information, which limits the application of existing methods to broader scenarios. To address this, we present a model that utilizes the syntax of text in both pre-training and fine-tuning stages. Our model is based on Transformer with a syntax-aware attention layer that considers the dependency tree of the text. We further introduce a new pre-training task of predicting the syntactic distance among tokens in the dependency tree. We evaluate the model on three downstream tasks, including relation classification, entity typing, and question answering. Results show that our model achieves state-of-the-art performance on six public benchmark datasets. We have two major findings. First, we demonstrate that infusing automatically produced syntax of text improves pre-trained models. Second, global syntactic distances among tokens bring larger performance gains compared to local head relations between contiguous tokens.
GraphCodeBERT: Pre-training Code Representations with Data Flow
Sep 29, 2020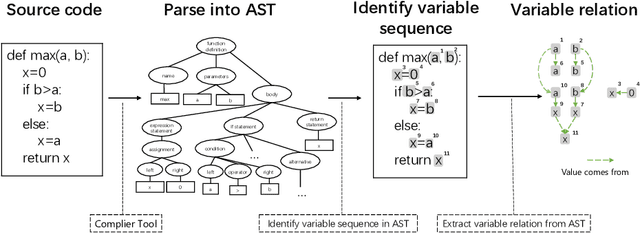
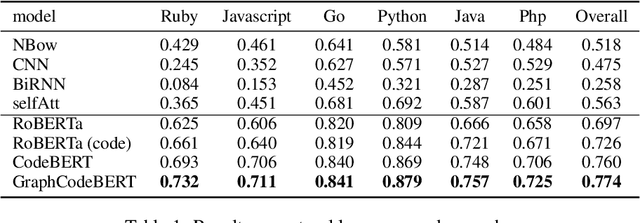
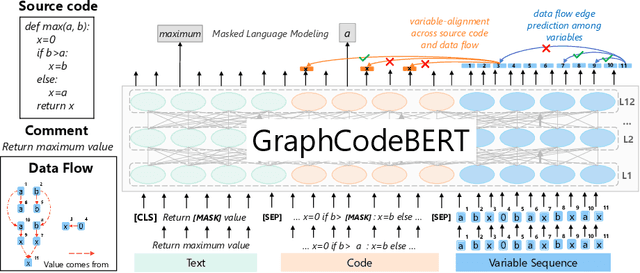
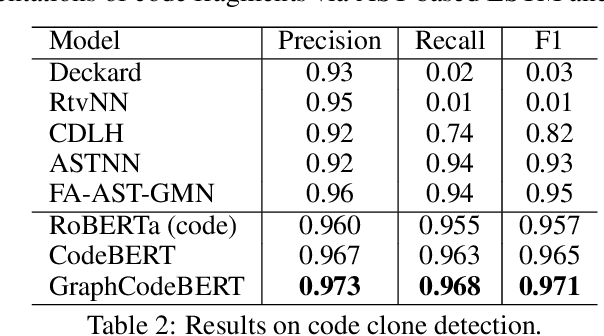
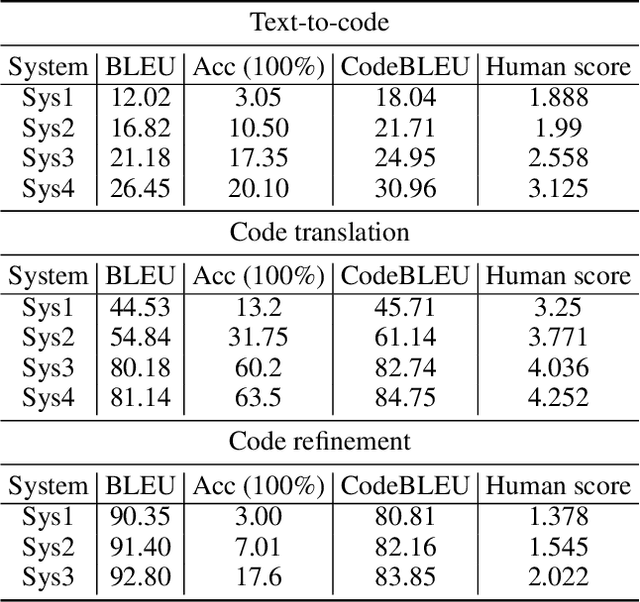
Pre-trained models for programming language have achieved dramatic empirical improvements on a variety of code-related tasks such as code search, code completion, code summarization, etc. However, existing pre-trained models regard a code snippet as a sequence of tokens, while ignoring the inherent structure of code, which provides crucial code semantics and would enhance the code understanding process. We present GraphCodeBERT, a pre-trained model for programming language that considers the inherent structure of code. Instead of taking syntactic-level structure of code like abstract syntax tree (AST), we use data flow in the pre-training stage, which is a semantic-level structure of code that encodes the relation of "where-the-value-comes-from" between variables. Such a semantic-level structure is neat and does not bring an unnecessarily deep hierarchy of AST, the property of which makes the model more efficient. We develop GraphCodeBERT based on Transformer. In addition to using the task of masked language modeling, we introduce two structure-aware pre-training tasks. One is to predict code structure edges, and the other is to align representations between source code and code structure. We implement the model in an efficient way with a graph-guided masked attention function to incorporate the code structure. We evaluate our model on four tasks, including code search, clone detection, code translation, and code refinement. Results show that code structure and newly introduced pre-training tasks can improve GraphCodeBERT and achieves state-of-the-art performance on the four downstream tasks. We further show that the model prefers structure-level attentions over token-level attentions in the task of code search.
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
Sep 27, 2020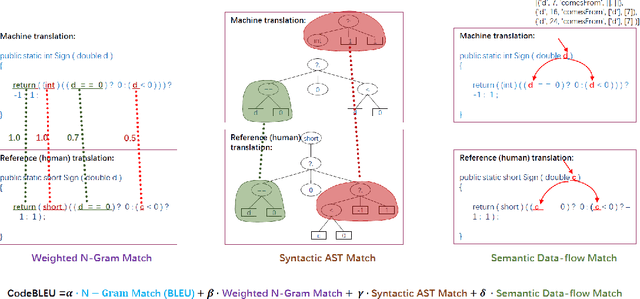


Evaluation metrics play a vital role in the growth of an area as it defines the standard of distinguishing between good and bad models. In the area of code synthesis, the commonly used evaluation metric is BLEU or perfect accuracy, but they are not suitable enough to evaluate codes, because BLEU is originally designed to evaluate the natural language, neglecting important syntactic and semantic features of codes, and perfect accuracy is too strict thus it underestimates different outputs with the same semantic logic. To remedy this, we introduce a new automatic evaluation metric, dubbed CodeBLEU. It absorbs the strength of BLEU in the n-gram match and further injects code syntax via abstract syntax trees (AST) and code semantics via data-flow. We conduct experiments by evaluating the correlation coefficient between CodeBLEU and quality scores assigned by the programmers on three code synthesis tasks, i.e., text-to-code, code translation, and code refinement. Experimental results show that our proposed CodeBLEU can achieve a better correlation with programmer assigned scores compared with BLEU and accuracy.
Evidence-Aware Inferential Text Generation with Vector Quantised Variational AutoEncoder
Jun 15, 2020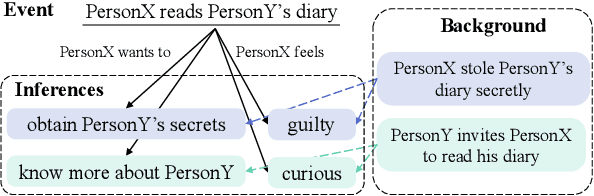
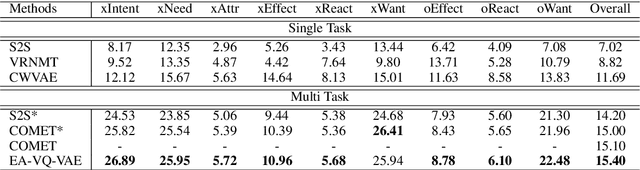
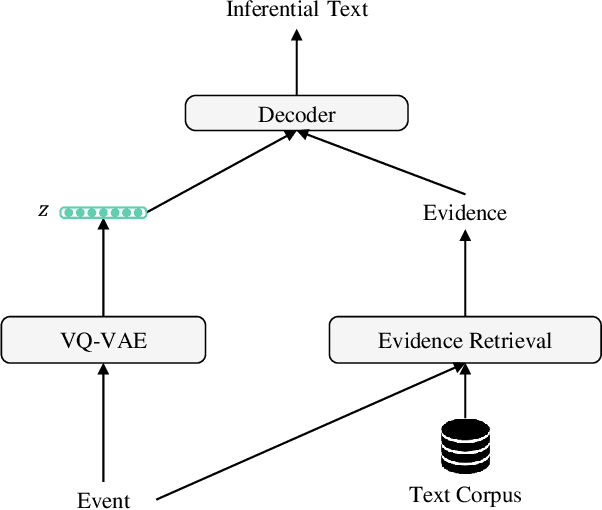
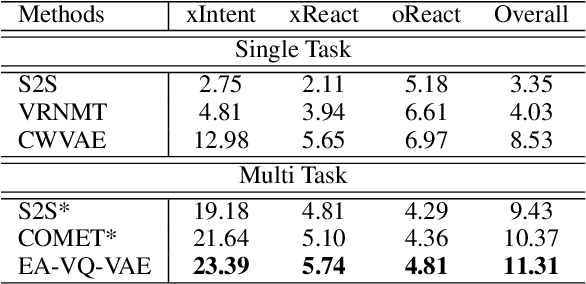
Generating inferential texts about an event in different perspectives requires reasoning over different contexts that the event occurs. Existing works usually ignore the context that is not explicitly provided, resulting in a context-independent semantic representation that struggles to support the generation. To address this, we propose an approach that automatically finds evidence for an event from a large text corpus, and leverages the evidence to guide the generation of inferential texts. Our approach works in an encoder-decoder manner and is equipped with a Vector Quantised-Variational Autoencoder, where the encoder outputs representations from a distribution over discrete variables. Such discrete representations enable automatically selecting relevant evidence, which not only facilitates evidence-aware generation, but also provides a natural way to uncover rationales behind the generation. Our approach provides state-of-the-art performance on both Event2Mind and ATOMIC datasets. More importantly, we find that with discrete representations, our model selectively uses evidence to generate different inferential texts.
Inferential Text Generation with Multiple Knowledge Sources and Meta-Learning
Apr 15, 2020
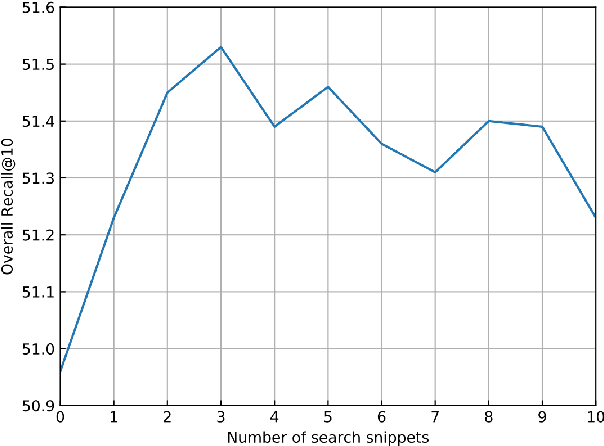
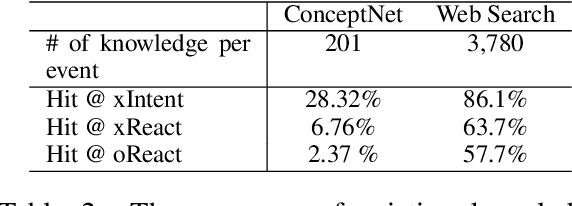
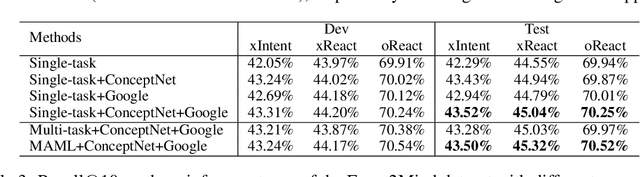
We study the problem of generating inferential texts of events for a variety of commonsense like \textit{if-else} relations. Existing approaches typically use limited evidence from training examples and learn for each relation individually. In this work, we use multiple knowledge sources as fuels for the model. Existing commonsense knowledge bases like ConceptNet are dominated by taxonomic knowledge (e.g., \textit{isA} and \textit{relatedTo} relations), having a limited number of inferential knowledge. We use not only structured commonsense knowledge bases, but also natural language snippets from search-engine results. These sources are incorporated into a generative base model via key-value memory network. In addition, we introduce a meta-learning based multi-task learning algorithm. For each targeted commonsense relation, we regard the learning of examples from other relations as the meta-training process, and the evaluation on examples from the targeted relation as the meta-test process. We conduct experiments on Event2Mind and ATOMIC datasets. Results show that both the integration of multiple knowledge sources and the use of the meta-learning algorithm improve the performance.
Pre-training Text Representations as Meta Learning
Apr 12, 2020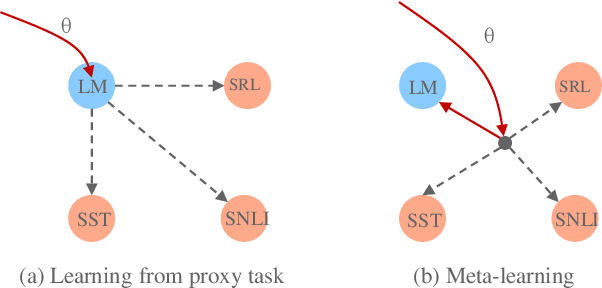
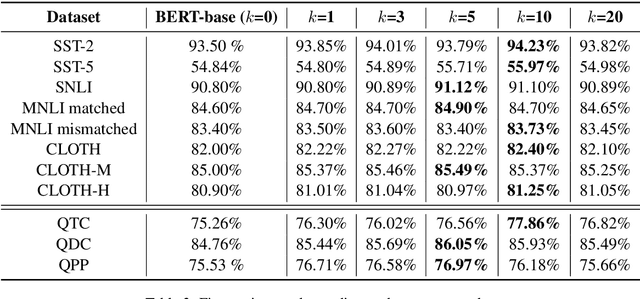
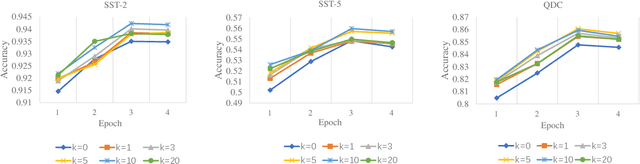
Pre-training text representations has recently been shown to significantly improve the state-of-the-art in many natural language processing tasks. The central goal of pre-training is to learn text representations that are useful for subsequent tasks. However, existing approaches are optimized by minimizing a proxy objective, such as the negative log likelihood of language modeling. In this work, we introduce a learning algorithm which directly optimizes model's ability to learn text representations for effective learning of downstream tasks. We show that there is an intrinsic connection between multi-task pre-training and model-agnostic meta-learning with a sequence of meta-train steps. The standard multi-task learning objective adopted in BERT is a special case of our learning algorithm where the depth of meta-train is zero. We study the problem in two settings: unsupervised pre-training and supervised pre-training with different pre-training objects to verify the generality of our approach.Experimental results show that our algorithm brings improvements and learns better initializations for a variety of downstream tasks.
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Feb 19, 2020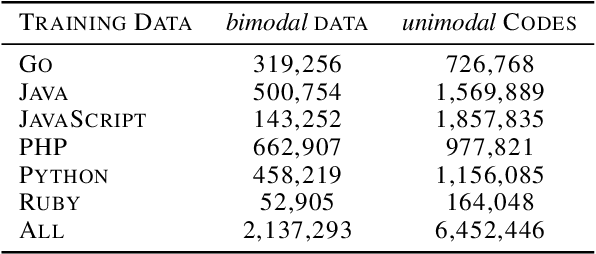

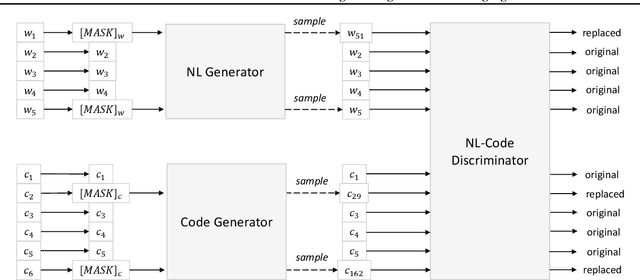
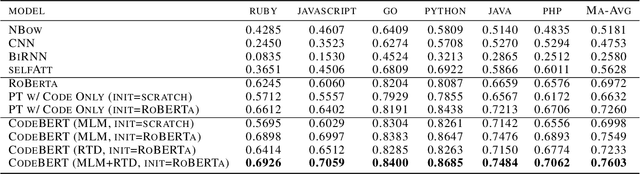
We present CodeBERT, a bimodal pre-trained model for programming language (PL) and nat-ural language (NL). CodeBERT learns general-purpose representations that support downstream NL-PL applications such as natural language codesearch, code documentation generation, etc. We develop CodeBERT with Transformer-based neural architecture, and train it with a hybrid objective function that incorporates the pre-training task of replaced token detection, which is to detect plausible alternatives sampled from generators. This enables us to utilize both bimodal data of NL-PL pairs and unimodal data, where the former provides input tokens for model training while the latter helps to learn better generators. We evaluate CodeBERT on two NL-PL applications by fine-tuning model parameters. Results show that CodeBERT achieves state-of-the-art performance on both natural language code search and code documentation generation tasks. Furthermore, to investigate what type of knowledge is learned in CodeBERT, we construct a dataset for NL-PL probing, and evaluate in a zero-shot setting where parameters of pre-trained models are fixed. Results show that CodeBERT performs better than previous pre-trained models on NL-PL probing.