 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA KL Lens on Quantization: Fast, Forward-Only Sensitivity for Mixed-Precision SSM-Transformer Models
Apr 15, 2026Deploying Large Language Models (LLMs) on edge devices faces severe computational and memory constraints, limiting real-time processing and on-device intelligence. Hybrid architectures combining Structured State Space Models (SSMs) with transformer-based LLMs offer a balance of efficiency and performance. Aggressive quantization can drastically cut model size and speed up inference, but its uneven effects on different components require careful management. In this work, we propose a lightweight, backpropagation-free, surrogate-based sensitivity analysis framework to identify hybrid SSM-Transformer components most susceptible to quantization-induced degradation. Relying solely on forward-pass metrics, our method avoids expensive gradient computations and retraining, making it suitable for situations where access to in-domain data is limited due to proprietary restrictions or privacy constraints. We also provide a formal analysis showing that the Kullback-Leibler (KL) divergence metric better captures quantization sensitivity for Language modeling tasks than widely adopted alternatives such as mean squared error (MSE) and signal-to-quantization-noise ratio (SQNR). Through extensive experiments on SSM and hybrid architectures, our ablation studies confirm that KL-based rankings align with observed performance drops and outperform alternative metrics. This framework enables the practical deployment of advanced hybrid models on resource-constrained edge devices with minimal accuracy loss. We further validate our approach with real-world on-device profiling on Intel Lunar Lake hardware, demonstrating that KL-guided mixed-precision achieves near-FP16 perplexity with model sizes and throughput competitive with Uniform INT4 on both CPU and GPU execution modes. Code is available at https://github.com/jasonkongie/kl-ssm-quant.
QMC: Efficient SLM Edge Inference via Outlier-Aware Quantization and Emergent Memories Co-Design
Jan 21, 2026Deploying Small Language Models (SLMs) on edge platforms is critical for real-time, privacy-sensitive generative AI, yet constrained by memory, latency, and energy budgets. Quantization reduces model size and cost but suffers from device noise in emerging non-volatile memories, while conventional memory hierarchies further limit efficiency. SRAM provides fast access but has low density, DRAM must simultaneously accommodate static weights and dynamic KV caches, which creates bandwidth contention, and Flash, although dense, is primarily used for initialization and remains inactive during inference. These limitations highlight the need for hybrid memory organizations tailored to LLM inference. We propose Outlier-aware Quantization with Memory Co-design (QMC), a retraining-free quantization with a novel heterogeneous memory architecture. QMC identifies inlier and outlier weights in SLMs, storing inlier weights in compact multi-level Resistive-RAM (ReRAM) while preserving critical outliers in high-precision on-chip Magnetoresistive-RAM (MRAM), mitigating noise-induced degradation. On language modeling and reasoning benchmarks, QMC outperforms and matches state-of-the-art quantization methods using advanced algorithms and hybrid data formats, while achieving greater compression under both algorithm-only evaluation and realistic deployment settings. Specifically, compared against SoTA quantization methods on the latest edge AI platform, QMC reduces memory usage by 6.3x-7.3x, external data transfers by 7.6x, energy by 11.7x, and latency by 12.5x when compared to FP16, establishing QMC as a scalable, deployment-ready co-design for efficient on-device inference.
DPQ-HD: Post-Training Compression for Ultra-Low Power Hyperdimensional Computing
May 08, 2025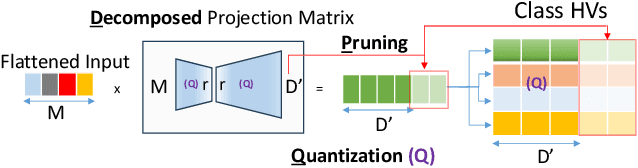

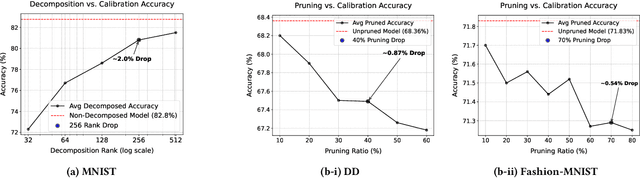
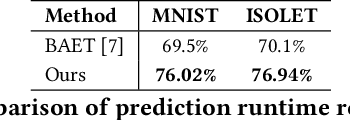
Hyperdimensional Computing (HDC) is emerging as a promising approach for edge AI, offering a balance between accuracy and efficiency. However, current HDC-based applications often rely on high-precision models and/or encoding matrices to achieve competitive performance, which imposes significant computational and memory demands, especially for ultra-low power devices. While recent efforts use techniques like precision reduction and pruning to increase the efficiency, most require retraining to maintain performance, making them expensive and impractical. To address this issue, we propose a novel Post Training Compression algorithm, Decomposition-Pruning-Quantization (DPQ-HD), which aims at compressing the end-to-end HDC system, achieving near floating point performance without the need of retraining. DPQ-HD reduces computational and memory overhead by uniquely combining the above three compression techniques and efficiently adapts to hardware constraints. Additionally, we introduce an energy-efficient inference approach that progressively evaluates similarity scores such as cosine similarity and performs early exit to reduce the computation, accelerating prediction inference while maintaining accuracy. We demonstrate that DPQ-HD achieves up to 20-100x reduction in memory for image and graph classification tasks with only a 1-2% drop in accuracy compared to uncompressed workloads. Lastly, we show that DPQ-HD outperforms the existing post-training compression methods and performs better or at par with retraining-based state-of-the-art techniques, requiring significantly less overall optimization time (up to 100x) and faster inference (up to 56x) on a microcontroller
Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024



In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024



Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
FouRA: Fourier Low Rank Adaptation
Jun 13, 2024



While Low-Rank Adaptation (LoRA) has proven beneficial for efficiently fine-tuning large models, LoRA fine-tuned text-to-image diffusion models lack diversity in the generated images, as the model tends to copy data from the observed training samples. This effect becomes more pronounced at higher values of adapter strength and for adapters with higher ranks which are fine-tuned on smaller datasets. To address these challenges, we present FouRA, a novel low-rank method that learns projections in the Fourier domain along with learning a flexible input-dependent adapter rank selection strategy. Through extensive experiments and analysis, we show that FouRA successfully solves the problems related to data copying and distribution collapse while significantly improving the generated image quality. We demonstrate that FouRA enhances the generalization of fine-tuned models thanks to its adaptive rank selection. We further show that the learned projections in the frequency domain are decorrelated and prove effective when merging multiple adapters. While FouRA is motivated for vision tasks, we also demonstrate its merits for language tasks on the GLUE benchmark.
Oh! We Freeze: Improving Quantized Knowledge Distillation via Signal Propagation Analysis for Large Language Models
Mar 28, 2024Large generative models such as large language models (LLMs) and diffusion models have revolutionized the fields of NLP and computer vision respectively. However, their slow inference, high computation and memory requirement makes it challenging to deploy them on edge devices. In this study, we propose a light-weight quantization aware fine tuning technique using knowledge distillation (KD-QAT) to improve the performance of 4-bit weight quantized LLMs using commonly available datasets to realize a popular language use case, on device chat applications. To improve this paradigm of finetuning, as main contributions, we provide insights into stability of KD-QAT by empirically studying the gradient propagation during training to better understand the vulnerabilities of KD-QAT based approaches to low-bit quantization errors. Based on our insights, we propose ov-freeze, a simple technique to stabilize the KD-QAT process. Finally, we experiment with the popular 7B LLaMAv2-Chat model at 4-bit quantization level and demonstrate that ov-freeze results in near floating point precision performance, i.e., less than 0.7% loss of accuracy on Commonsense Reasoning benchmarks.
Softmax Bias Correction for Quantized Generative Models
Sep 04, 2023Post-training quantization (PTQ) is the go-to compression technique for large generative models, such as stable diffusion or large language models. PTQ methods commonly keep the softmax activation in higher precision as it has been shown to be very sensitive to quantization noise. However, this can lead to a significant runtime and power overhead during inference on resource-constraint edge devices. In this work, we investigate the source of the softmax sensitivity to quantization and show that the quantization operation leads to a large bias in the softmax output, causing accuracy degradation. To overcome this issue, we propose an offline bias correction technique that improves the quantizability of softmax without additional compute during deployment, as it can be readily absorbed into the quantization parameters. We demonstrate the effectiveness of our method on stable diffusion v1.5 and 125M-size OPT language model, achieving significant accuracy improvement for 8-bit quantized softmax.
A Practical Mixed Precision Algorithm for Post-Training Quantization
Feb 10, 2023



Neural network quantization is frequently used to optimize model size, latency and power consumption for on-device deployment of neural networks. In many cases, a target bit-width is set for an entire network, meaning every layer get quantized to the same number of bits. However, for many networks some layers are significantly more robust to quantization noise than others, leaving an important axis of improvement unused. As many hardware solutions provide multiple different bit-width settings, mixed-precision quantization has emerged as a promising solution to find a better performance-efficiency trade-off than homogeneous quantization. However, most existing mixed precision algorithms are rather difficult to use for practitioners as they require access to the training data, have many hyper-parameters to tune or even depend on end-to-end retraining of the entire model. In this work, we present a simple post-training mixed precision algorithm that only requires a small unlabeled calibration dataset to automatically select suitable bit-widths for each layer for desirable on-device performance. Our algorithm requires no hyper-parameter tuning, is robust to data variation and takes into account practical hardware deployment constraints making it a great candidate for practical use. We experimentally validate our proposed method on several computer vision tasks, natural language processing tasks and many different networks, and show that we can find mixed precision networks that provide a better trade-off between accuracy and efficiency than their homogeneous bit-width equivalents.