 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPQ-HD: Post-Training Compression for Ultra-Low Power Hyperdimensional Computing
May 08, 2025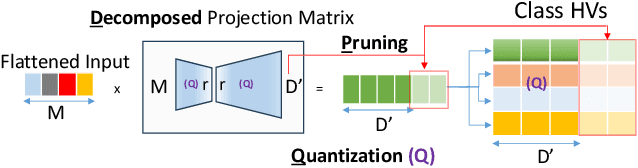

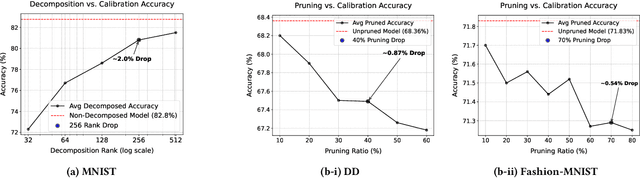
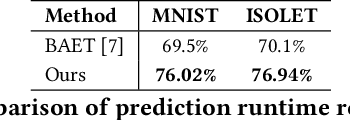
Hyperdimensional Computing (HDC) is emerging as a promising approach for edge AI, offering a balance between accuracy and efficiency. However, current HDC-based applications often rely on high-precision models and/or encoding matrices to achieve competitive performance, which imposes significant computational and memory demands, especially for ultra-low power devices. While recent efforts use techniques like precision reduction and pruning to increase the efficiency, most require retraining to maintain performance, making them expensive and impractical. To address this issue, we propose a novel Post Training Compression algorithm, Decomposition-Pruning-Quantization (DPQ-HD), which aims at compressing the end-to-end HDC system, achieving near floating point performance without the need of retraining. DPQ-HD reduces computational and memory overhead by uniquely combining the above three compression techniques and efficiently adapts to hardware constraints. Additionally, we introduce an energy-efficient inference approach that progressively evaluates similarity scores such as cosine similarity and performs early exit to reduce the computation, accelerating prediction inference while maintaining accuracy. We demonstrate that DPQ-HD achieves up to 20-100x reduction in memory for image and graph classification tasks with only a 1-2% drop in accuracy compared to uncompressed workloads. Lastly, we show that DPQ-HD outperforms the existing post-training compression methods and performs better or at par with retraining-based state-of-the-art techniques, requiring significantly less overall optimization time (up to 100x) and faster inference (up to 56x) on a microcontroller