 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALMON: Self-Alignment with Principle-Following Reward Models
Oct 09, 2023



Supervised Fine-Tuning (SFT) on response demonstrations combined with Reinforcement Learning from Human Feedback (RLHF) constitutes a powerful paradigm for aligning LLM-based AI agents. However, a significant limitation of such an approach is its dependency on high-quality human annotations, making its application to intricate tasks challenging due to difficulties in obtaining consistent response demonstrations and in-distribution response preferences. This paper presents a novel approach, namely SALMON (Self-ALignMent with principle-fOllowiNg reward models), to align base language models with minimal human supervision, using only a small set of human-defined principles, yet achieving superior performance. Central to our approach is a principle-following reward model. Trained on synthetic preference data, this model can generate reward scores based on arbitrary human-defined principles. By merely adjusting these principles during the RL training phase, we gain full control over the preferences with the reward model, subsequently influencing the behavior of the RL-trained policies, and eliminating the reliance on the collection of online human preferences. Applying our method to the LLaMA-2-70b base language model, we developed an AI assistant named Dromedary-2. With only 6 exemplars for in-context learning and 31 human-defined principles, Dromedary-2 significantly surpasses the performance of several state-of-the-art AI systems, including LLaMA-2-Chat-70b, on various benchmark datasets. We have open-sourced the code and model weights to encourage further research into aligning LLM-based AI agents with enhanced supervision efficiency, improved controllability, and scalable oversight.
Self-Specialization: Uncovering Latent Expertise within Large Language Models
Sep 29, 2023



Recent works have demonstrated the effectiveness of self-alignment in which a large language model is, by itself, aligned to follow general instructions through the automatic generation of instructional data using a handful of human-written seeds. Instead of general alignment, in this work, we focus on self-alignment for expert domain specialization (e.g., biomedicine), discovering it to be very effective for improving zero-shot and few-shot performance in target domains of interest. As a preliminary, we first present the benchmark results of existing aligned models within a specialized domain, which reveals the marginal effect that "generic" instruction-following training has on downstream expert domains' performance. To remedy this, we explore self-specialization that leverages domain-specific unlabelled data and a few labeled seeds for the self-alignment process. When augmented with retrieval to reduce hallucination and enhance concurrency of the alignment, self-specialization offers an effective (and efficient) way of "carving out" an expert model out of a "generalist", pre-trained LLM where different domains of expertise are originally combined in a form of "superposition". Our experimental results on a biomedical domain show that our self-specialized model (30B) outperforms its base model, MPT-30B by a large margin and even surpasses larger popular models based on LLaMA-65B, highlighting its potential and practicality for specialization, especially considering its efficiency in terms of data and parameters.
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
May 04, 2023



Recent AI-assistant agents, such as ChatGPT, predominantly rely on supervised fine-tuning (SFT) with human annotations and reinforcement learning from human feedback (RLHF) to align the output of large language models (LLMs) with human intentions, ensuring they are helpful, ethical, and reliable. However, this dependence can significantly constrain the true potential of AI-assistant agents due to the high cost of obtaining human supervision and the related issues on quality, reliability, diversity, self-consistency, and undesirable biases. To address these challenges, we propose a novel approach called SELF-ALIGN, which combines principle-driven reasoning and the generative power of LLMs for the self-alignment of AI agents with minimal human supervision. Our approach encompasses four stages: first, we use an LLM to generate synthetic prompts, and a topic-guided method to augment the prompt diversity; second, we use a small set of human-written principles for AI models to follow, and guide the LLM through in-context learning from demonstrations (of principles application) to produce helpful, ethical, and reliable responses to user's queries; third, we fine-tune the original LLM with the high-quality self-aligned responses so that the resulting model can generate desirable responses for each query directly without the principle set and the demonstrations anymore; and finally, we offer a refinement step to address the issues of overly-brief or indirect responses. Applying SELF-ALIGN to the LLaMA-65b base language model, we develop an AI assistant named Dromedary. With fewer than 300 lines of human annotations (including < 200 seed prompts, 16 generic principles, and 5 exemplars for in-context learning). Dromedary significantly surpasses the performance of several state-of-the-art AI systems, including Text-Davinci-003 and Alpaca, on benchmark datasets with various settings.
Rapid Development of Compositional AI
Feb 12, 2023



Compositional AI systems, which combine multiple artificial intelligence components together with other application components to solve a larger problem, have no known pattern of development and are often approached in a bespoke and ad hoc style. This makes development slower and harder to reuse for future applications. To support the full rapid development cycle of compositional AI applications, we have developed a novel framework called (Bee)* (written as a regular expression and pronounced as "beestar"). We illustrate how (Bee)* supports building integrated, scalable, and interactive compositional AI applications with a simplified developer experience.
* Accepted to ICSE 2023, NIER track
ConStruct-VL: Data-Free Continual Structured VL Concepts Learning
Nov 17, 2022



Recently, large-scale pre-trained Vision-and-Language (VL) foundation models have demonstrated remarkable capabilities in many zero-shot downstream tasks, achieving competitive results for recognizing objects defined by as little as short text prompts. However, it has also been shown that VL models are still brittle in Structured VL Concept (SVLC) reasoning, such as the ability to recognize object attributes, states, and inter-object relations. This leads to reasoning mistakes, which need to be corrected as they occur by teaching VL models the missing SVLC skills; often this must be done using private data where the issue was found, which naturally leads to a data-free continual (no task-id) VL learning setting. In this work, we introduce the first Continual Data-Free Structured VL Concepts Learning (ConStruct-VL) benchmark and show it is challenging for many existing data-free CL strategies. We, therefore, propose a data-free method comprised of a new approach of Adversarial Pseudo-Replay (APR) which generates adversarial reminders of past tasks from past task models. To use this method efficiently, we also propose a continual parameter-efficient Layered-LoRA (LaLo) neural architecture allowing no-memory-cost access to all past models at train time. We show this approach outperforms all data-free methods by as much as ~7% while even matching some levels of experience-replay (prohibitive for applications where data-privacy must be preserved).
VALHALLA: Visual Hallucination for Machine Translation
May 31, 2022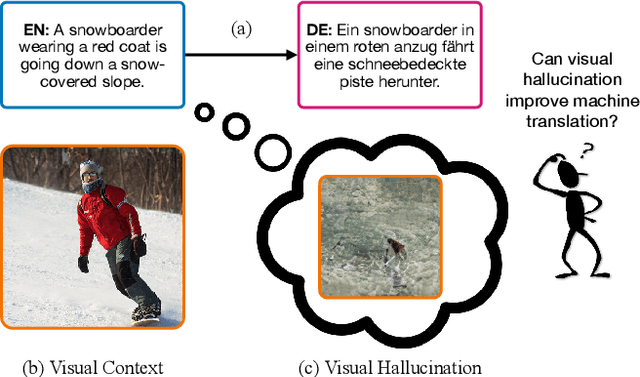
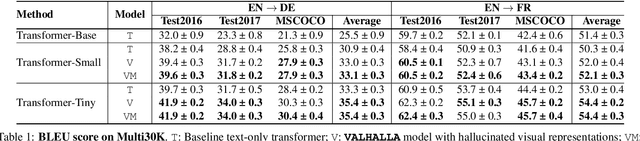
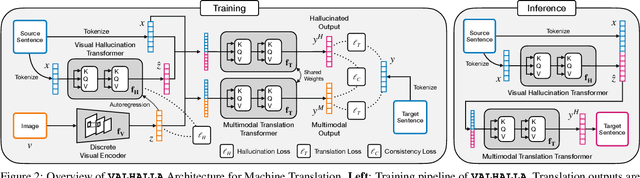
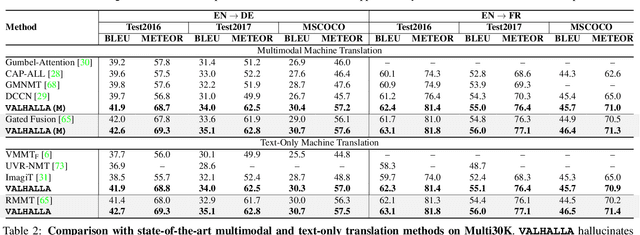
Designing better machine translation systems by considering auxiliary inputs such as images has attracted much attention in recent years. While existing methods show promising performance over the conventional text-only translation systems, they typically require paired text and image as input during inference, which limits their applicability to real-world scenarios. In this paper, we introduce a visual hallucination framework, called VALHALLA, which requires only source sentences at inference time and instead uses hallucinated visual representations for multimodal machine translation. In particular, given a source sentence an autoregressive hallucination transformer is used to predict a discrete visual representation from the input text, and the combined text and hallucinated representations are utilized to obtain the target translation. We train the hallucination transformer jointly with the translation transformer using standard backpropagation with cross-entropy losses while being guided by an additional loss that encourages consistency between predictions using either ground-truth or hallucinated visual representations. Extensive experiments on three standard translation datasets with a diverse set of language pairs demonstrate the effectiveness of our approach over both text-only baselines and state-of-the-art methods. Project page: http://www.svcl.ucsd.edu/projects/valhalla.
Improving Self-Supervised Speech Representations by Disentangling Speakers
Apr 20, 2022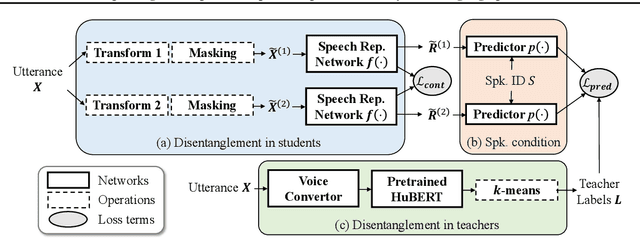

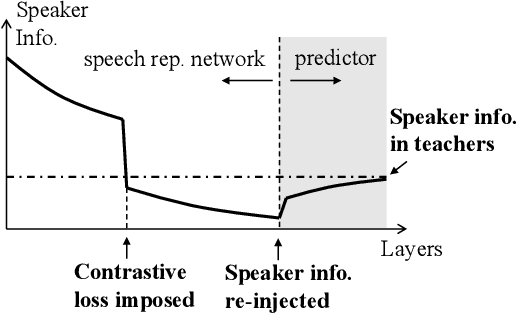
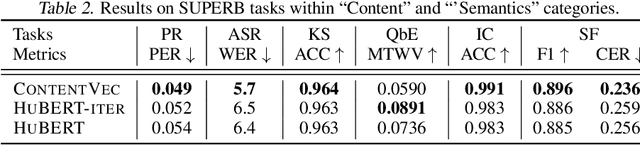
Self-supervised learning in speech involves training a speech representation network on a large-scale unannotated speech corpus, and then applying the learned representations to downstream tasks. Since the majority of the downstream tasks of SSL learning in speech largely focus on the content information in speech, the most desirable speech representations should be able to disentangle unwanted variations, such as speaker variations, from the content. However, disentangling speakers is very challenging, because removing the speaker information could easily result in a loss of content as well, and the damage of the latter usually far outweighs the benefit of the former. In this paper, we propose a new SSL method that can achieve speaker disentanglement without severe loss of content. Our approach is adapted from the HuBERT framework, and incorporates disentangling mechanisms to regularize both the teacher labels and the learned representations. We evaluate the benefit of speaker disentanglement on a set of content-related downstream tasks, and observe a consistent and notable performance advantage of our speaker-disentangled representations.
Drawing Robust Scratch Tickets: Subnetworks with Inborn Robustness Are Found within Randomly Initialized Networks
Nov 06, 2021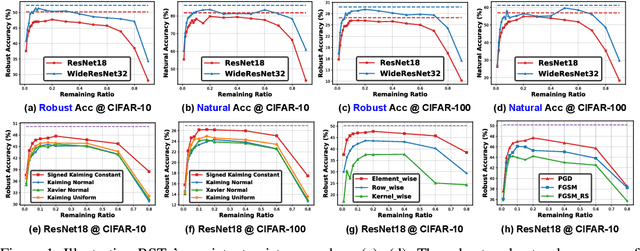
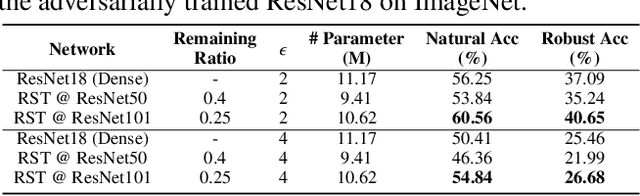
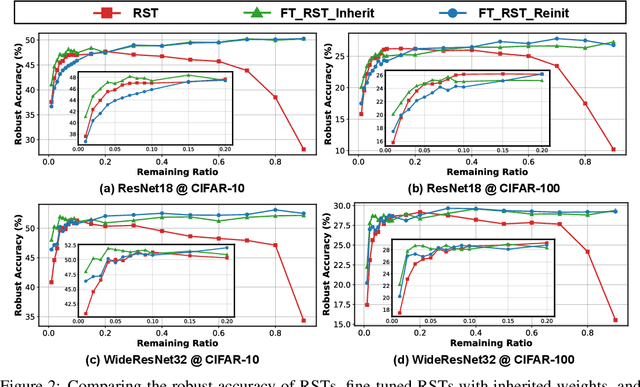
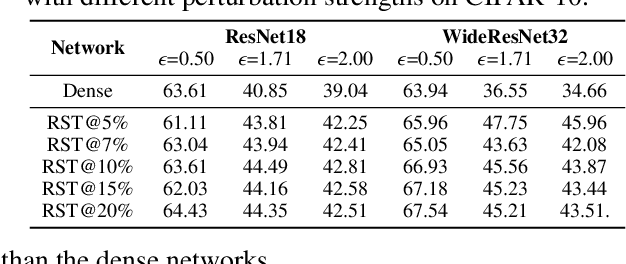
Deep Neural Networks (DNNs) are known to be vulnerable to adversarial attacks, i.e., an imperceptible perturbation to the input can mislead DNNs trained on clean images into making erroneous predictions. To tackle this, adversarial training is currently the most effective defense method, by augmenting the training set with adversarial samples generated on the fly. Interestingly, we discover for the first time that there exist subnetworks with inborn robustness, matching or surpassing the robust accuracy of the adversarially trained networks with comparable model sizes, within randomly initialized networks without any model training, indicating that adversarial training on model weights is not indispensable towards adversarial robustness. We name such subnetworks Robust Scratch Tickets (RSTs), which are also by nature efficient. Distinct from the popular lottery ticket hypothesis, neither the original dense networks nor the identified RSTs need to be trained. To validate and understand this fascinating finding, we further conduct extensive experiments to study the existence and properties of RSTs under different models, datasets, sparsity patterns, and attacks, drawing insights regarding the relationship between DNNs' robustness and their initialization/overparameterization. Furthermore, we identify the poor adversarial transferability between RSTs of different sparsity ratios drawn from the same randomly initialized dense network, and propose a Random RST Switch (R2S) technique, which randomly switches between different RSTs, as a novel defense method built on top of RSTs. We believe our findings about RSTs have opened up a new perspective to study model robustness and extend the lottery ticket hypothesis.
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
Oct 04, 2021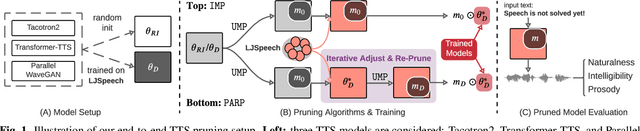
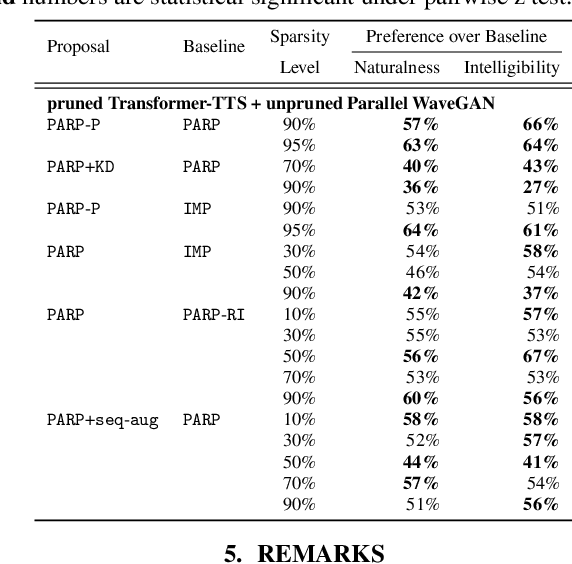
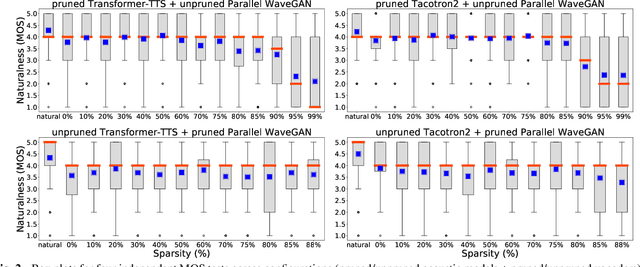
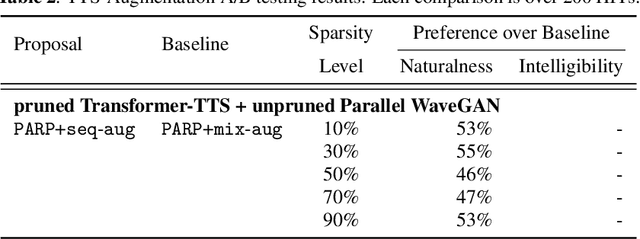
Are end-to-end text-to-speech (TTS) models over-parametrized? To what extent can these models be pruned, and what happens to their synthesis capabilities? This work serves as a starting point to explore pruning both spectrogram prediction networks and vocoders. We thoroughly investigate the tradeoffs between sparstiy and its subsequent effects on synthetic speech. Additionally, we explored several aspects of TTS pruning: amount of finetuning data versus sparsity, TTS-Augmentation to utilize unspoken text, and combining knowledge distillation and pruning. Our findings suggest that not only are end-to-end TTS models highly prunable, but also, perhaps surprisingly, pruned TTS models can produce synthetic speech with equal or higher naturalness and intelligibility, with similar prosody. All of our experiments are conducted on publicly available models, and findings in this work are backed by large-scale subjective tests and objective measures. Code and 200 pruned models are made available to facilitate future research on efficiency in TTS.
Global Rhythm Style Transfer Without Text Transcriptions
Jun 16, 2021
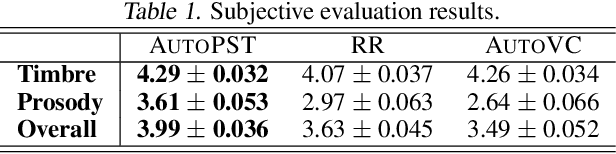
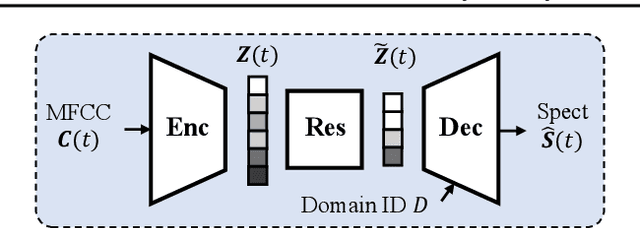

Prosody plays an important role in characterizing the style of a speaker or an emotion, but most non-parallel voice or emotion style transfer algorithms do not convert any prosody information. Two major components of prosody are pitch and rhythm. Disentangling the prosody information, particularly the rhythm component, from the speech is challenging because it involves breaking the synchrony between the input speech and the disentangled speech representation. As a result, most existing prosody style transfer algorithms would need to rely on some form of text transcriptions to identify the content information, which confines their application to high-resource languages only. Recently, SpeechSplit has made sizeable progress towards unsupervised prosody style transfer, but it is unable to extract high-level global prosody style in an unsupervised manner. In this paper, we propose AutoPST, which can disentangle global prosody style from speech without relying on any text transcriptions. AutoPST is an Autoencoder-based Prosody Style Transfer framework with a thorough rhythm removal module guided by the self-expressive representation learning. Experiments on different style transfer tasks show that AutoPST can effectively convert prosody that correctly reflects the styles of the target domains.