 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations that Enable Generalization in Assistive Tasks
Dec 05, 2022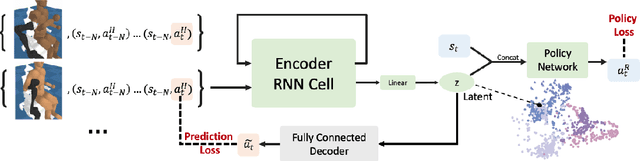



Recent work in sim2real has successfully enabled robots to act in physical environments by training in simulation with a diverse ''population'' of environments (i.e. domain randomization). In this work, we focus on enabling generalization in assistive tasks: tasks in which the robot is acting to assist a user (e.g. helping someone with motor impairments with bathing or with scratching an itch). Such tasks are particularly interesting relative to prior sim2real successes because the environment now contains a human who is also acting. This complicates the problem because the diversity of human users (instead of merely physical environment parameters) is more difficult to capture in a population, thus increasing the likelihood of encountering out-of-distribution (OOD) human policies at test time. We advocate that generalization to such OOD policies benefits from (1) learning a good latent representation for human policies that test-time humans can accurately be mapped to, and (2) making that representation adaptable with test-time interaction data, instead of relying on it to perfectly capture the space of human policies based on the simulated population only. We study how to best learn such a representation by evaluating on purposefully constructed OOD test policies. We find that sim2real methods that encode environment (or population) parameters and work well in tasks that robots do in isolation, do not work well in assistance. In assistance, it seems crucial to train the representation based on the history of interaction directly, because that is what the robot will have access to at test time. Further, training these representations to then predict human actions not only gives them better structure, but also enables them to be fine-tuned at test-time, when the robot observes the partner act. https://adaptive-caregiver.github.io.
Autonomous Assessment of Demonstration Sufficiency via Bayesian Inverse Reinforcement Learning
Nov 29, 2022In this paper we examine the problem of determining demonstration sufficiency for AI agents that learn from demonstrations: how can an AI agent self-assess whether it has received enough demonstrations from an expert to ensure a desired level of performance? To address this problem we propose a novel self-assessment approach based on Bayesian inverse reinforcement learning and value-at-risk to enable agents that learn from demonstrations to compute high-confidence bounds on their performance and use these bounds to determine when they have a sufficient number of demonstrations. We propose and evaluate two definitions of sufficiency: (1) normalized expected value difference, which measures regret with respect to the expert's unobserved reward function, and (2) improvement over a baseline policy. We demonstrate how to formulate high-confidence bounds on both of these metrics. We evaluate our approach in simulation and demonstrate the feasibility of developing an AI system that can accurately evaluate whether it has received sufficient training data to guarantee, with high confidence, that it can match an expert's performance or surpass the performance of a baseline policy within some desired safety threshold.
The Effect of Modeling Human Rationality Level on Learning Rewards from Multiple Feedback Types
Aug 23, 2022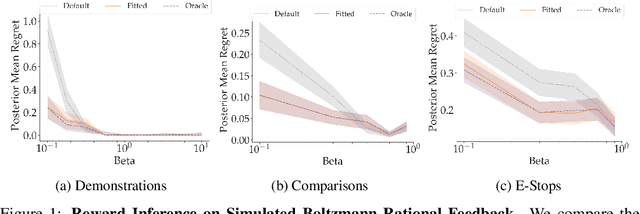

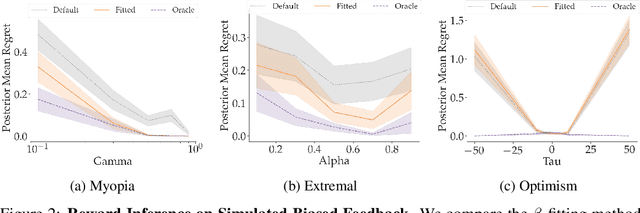
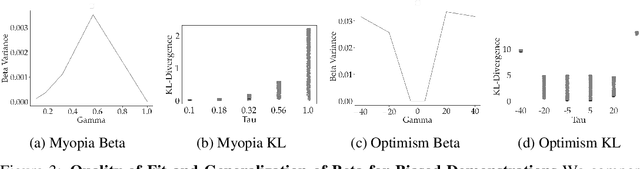
When inferring reward functions from human behavior (be it demonstrations, comparisons, physical corrections, or e-stops), it has proven useful to model the human as making noisy-rational choices, with a "rationality coefficient" capturing how much noise or entropy we expect to see in the human behavior. Many existing works have opted to fix this coefficient regardless of the type, or quality, of human feedback. However, in some settings, giving a demonstration may be much more difficult than answering a comparison query. In this case, we should expect to see more noise or suboptimality in demonstrations than in comparisons, and should interpret the feedback accordingly. In this work, we advocate that grounding the rationality coefficient in real data for each feedback type, rather than assuming a default value, has a significant positive effect on reward learning. We test this in experiments with both simulated feedback, as well a user study. We find that when learning from a single feedback type, overestimating human rationality can have dire effects on reward accuracy and regret. Further, we find that the rationality level affects the informativeness of each feedback type: surprisingly, demonstrations are not always the most informative -- when the human acts very suboptimally, comparisons actually become more informative, even when the rationality level is the same for both. Moreover, when the robot gets to decide which feedback type to ask for, it gets a large advantage from accurately modeling the rationality level of each type. Ultimately, our results emphasize the importance of paying attention to the assumed rationality level, not only when learning from a single feedback type, but especially when agents actively learn from multiple feedback types.
Learning Switching Criteria for Sim2Real Transfer of Robotic Fabric Manipulation Policies
Jul 02, 2022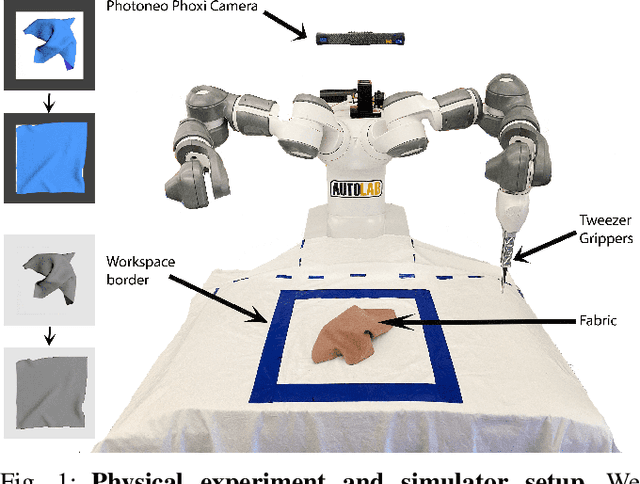

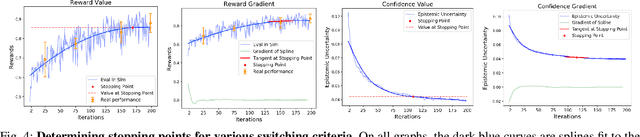
Simulation-to-reality transfer has emerged as a popular and highly successful method to train robotic control policies for a wide variety of tasks. However, it is often challenging to determine when policies trained in simulation are ready to be transferred to the physical world. Deploying policies that have been trained with very little simulation data can result in unreliable and dangerous behaviors on physical hardware. On the other hand, excessive training in simulation can cause policies to overfit to the visual appearance and dynamics of the simulator. In this work, we study strategies to automatically determine when policies trained in simulation can be reliably transferred to a physical robot. We specifically study these ideas in the context of robotic fabric manipulation, in which successful sim2real transfer is especially challenging due to the difficulties of precisely modeling the dynamics and visual appearance of fabric. Results in a fabric smoothing task suggest that our switching criteria correlate well with performance in real. In particular, our confidence-based switching criteria achieve average final fabric coverage of 87.2-93.7% within 55-60% of the total training budget. See https://tinyurl.com/lsc-case for code and supplemental materials.
Teaching Robots to Span the Space of Functional Expressive Motion
Mar 04, 2022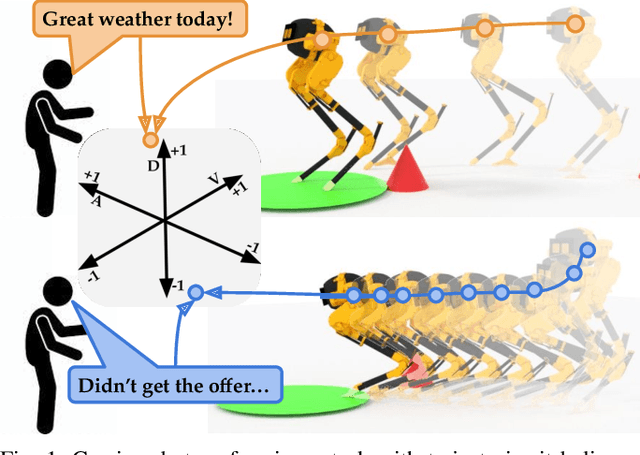
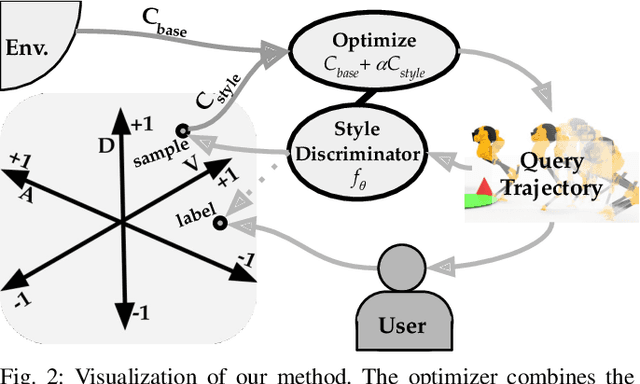
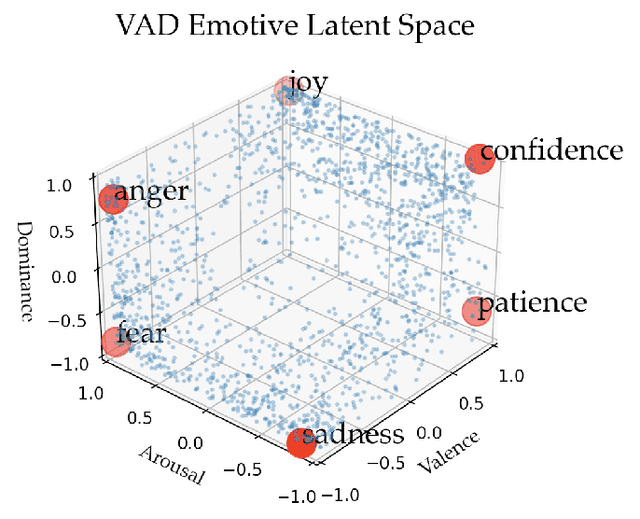

Our goal is to enable robots to perform functional tasks in emotive ways, be it in response to their users' emotional states, or expressive of their confidence levels. Prior work has proposed learning independent cost functions from user feedback for each target emotion, so that the robot may optimize it alongside task and environment specific objectives for any situation it encounters. However, this approach is inefficient when modeling multiple emotions and unable to generalize to new ones. In this work, we leverage the fact that emotions are not independent of each other: they are related through a latent space of Valence-Arousal-Dominance (VAD). Our key idea is to learn a model for how trajectories map onto VAD with user labels. Considering the distance between a trajectory's mapping and a target VAD allows this single model to represent cost functions for all emotions. As a result 1) all user feedback can contribute to learning about every emotion; 2) the robot can generate trajectories for any emotion in the space instead of only a few predefined ones; and 3) the robot can respond emotively to user-generated natural language by mapping it to a target VAD. We introduce a method that interactively learns to map trajectories to this latent space and test it in simulation and in a user study. In experiments, we use a simple vacuum robot as well as the Cassie biped.
LEGS: Learning Efficient Grasp Sets for Exploratory Grasping
Nov 29, 2021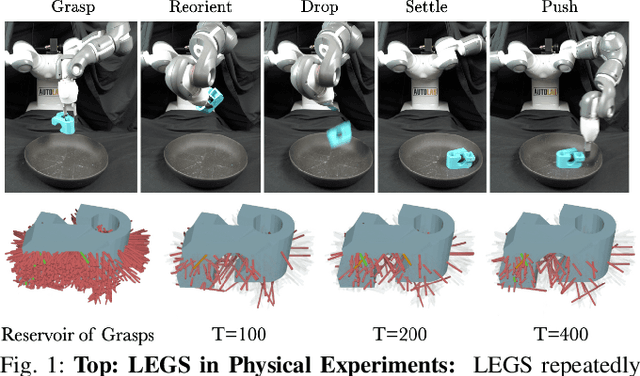
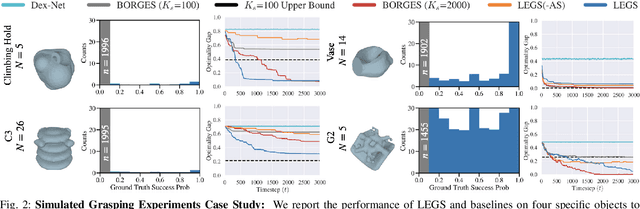
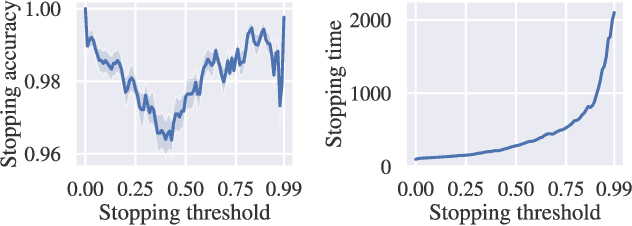
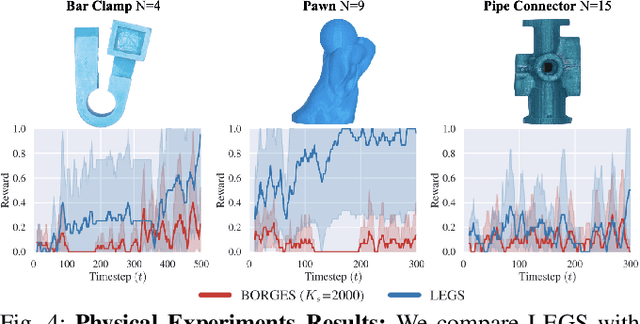
Previous work defined Exploratory Grasping, where a robot iteratively grasps and drops an unknown complex polyhedral object to discover a set of robust grasps for each recognizably distinct stable pose of the object. Recent work used a multi-armed bandit model with a small set of candidate grasps per pose; however, for objects with few successful grasps, this set may not include the most robust grasp. We present Learned Efficient Grasp Sets (LEGS), an algorithm that can efficiently explore thousands of possible grasps by constructing small active sets of promising grasps and uses learned confidence bounds to determine when, with high confidence, it can stop exploring the object. Experiments suggest that LEGS can identify a high-quality grasp more efficiently than prior algorithms which do not learn active sets. In simulation experiments, we measure the optimality gap between the success probability of the best grasp identified by LEGS and baselines and that of the true most robust grasp. After 3000 steps of exploration, LEGS outperforms baseline algorithms on 10 of the 14 Dex-Net Adversarial objects and 25 of the 39 EGAD! objects. We then develop a self-supervised grasping system, where the robot explores grasps with minimal human intervention. Physical experiments across 3 objects suggest that LEGS converges to high-performing grasps significantly faster than baselines. See \url{https://sites.google.com/view/legs-exp-grasping} for supplemental material and videos.
ThriftyDAgger: Budget-Aware Novelty and Risk Gating for Interactive Imitation Learning
Sep 17, 2021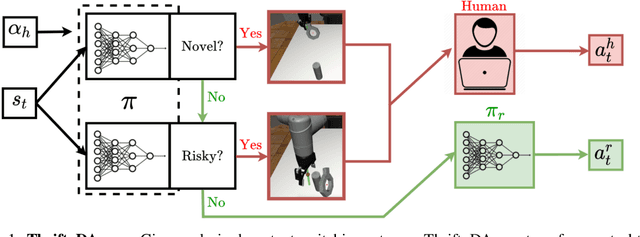
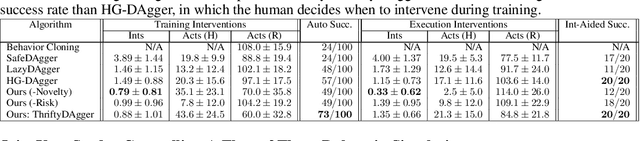
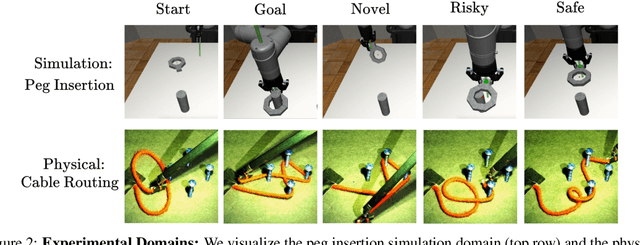

Effective robot learning often requires online human feedback and interventions that can cost significant human time, giving rise to the central challenge in interactive imitation learning: is it possible to control the timing and length of interventions to both facilitate learning and limit burden on the human supervisor? This paper presents ThriftyDAgger, an algorithm for actively querying a human supervisor given a desired budget of human interventions. ThriftyDAgger uses a learned switching policy to solicit interventions only at states that are sufficiently (1) novel, where the robot policy has no reference behavior to imitate, or (2) risky, where the robot has low confidence in task completion. To detect the latter, we introduce a novel metric for estimating risk under the current robot policy. Experiments in simulation and on a physical cable routing experiment suggest that ThriftyDAgger's intervention criteria balances task performance and supervisor burden more effectively than prior algorithms. ThriftyDAgger can also be applied at execution time, where it achieves a 100% success rate on both the simulation and physical tasks. A user study (N=10) in which users control a three-robot fleet while also performing a concentration task suggests that ThriftyDAgger increases human and robot performance by 58% and 80% respectively compared to the next best algorithm while reducing supervisor burden.
Offline Preference-Based Apprenticeship Learning
Jul 22, 2021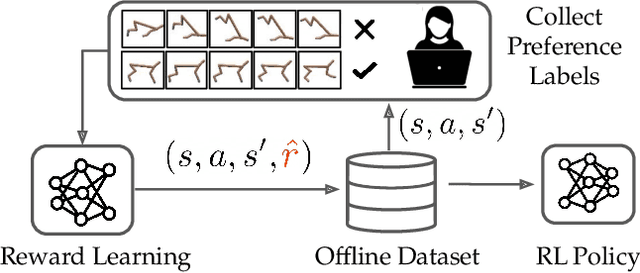
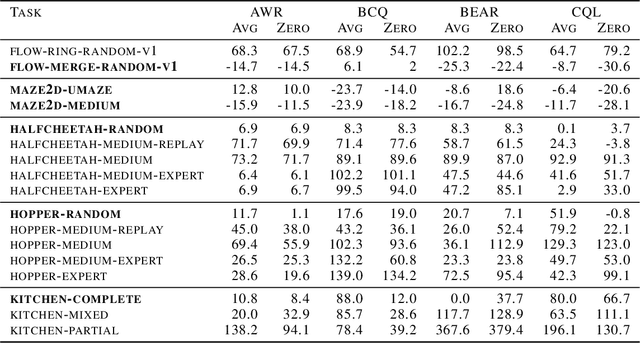
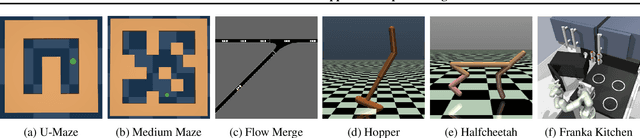
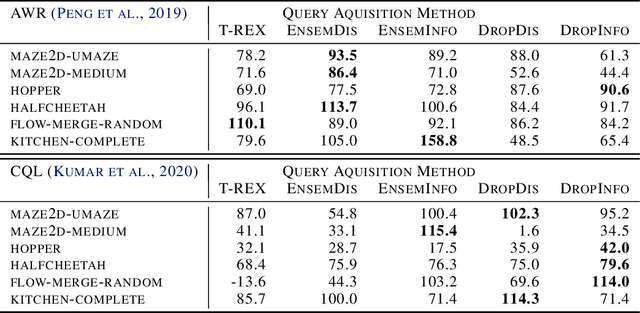
We study how an offline dataset of prior (possibly random) experience can be used to address two challenges that autonomous systems face when they endeavor to learn from, adapt to, and collaborate with humans : (1) identifying the human's intent and (2) safely optimizing the autonomous system's behavior to achieve this inferred intent. First, we use the offline dataset to efficiently infer the human's reward function via pool-based active preference learning. Second, given this learned reward function, we perform offline reinforcement learning to optimize a policy based on the inferred human intent. Crucially, our proposed approach does not require actual physical rollouts or an accurate simulator for either the reward learning or policy optimization steps, enabling both safe and efficient apprenticeship learning. We identify and evaluate our approach on a subset of existing offline RL benchmarks that are well suited for offline reward learning and also evaluate extensions of these benchmarks which allow more open-ended behaviors. Our experiments show that offline preference-based reward learning followed by offline reinforcement learning enables efficient and high-performing policies, while only requiring small numbers of preference queries. Videos available at https://sites.google.com/view/offline-prefs.
Kit-Net: Self-Supervised Learning to Kit Novel 3D Objects into Novel 3D Cavities
Jul 13, 2021



In industrial part kitting, 3D objects are inserted into cavities for transportation or subsequent assembly. Kitting is a critical step as it can decrease downstream processing and handling times and enable lower storage and shipping costs. We present Kit-Net, a framework for kitting previously unseen 3D objects into cavities given depth images of both the target cavity and an object held by a gripper in an unknown initial orientation. Kit-Net uses self-supervised deep learning and data augmentation to train a convolutional neural network (CNN) to robustly estimate 3D rotations between objects and matching concave or convex cavities using a large training dataset of simulated depth images pairs. Kit-Net then uses the trained CNN to implement a controller to orient and position novel objects for insertion into novel prismatic and conformal 3D cavities. Experiments in simulation suggest that Kit-Net can orient objects to have a 98.9% average intersection volume between the object mesh and that of the target cavity. Physical experiments with industrial objects succeed in 18% of trials using a baseline method and in 63% of trials with Kit-Net. Video, code, and data are available at https://github.com/BerkeleyAutomation/Kit-Net.
Policy Gradient Bayesian Robust Optimization for Imitation Learning
Jun 21, 2021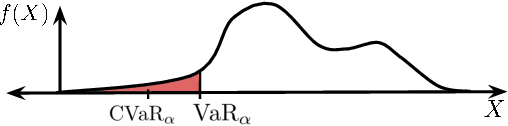
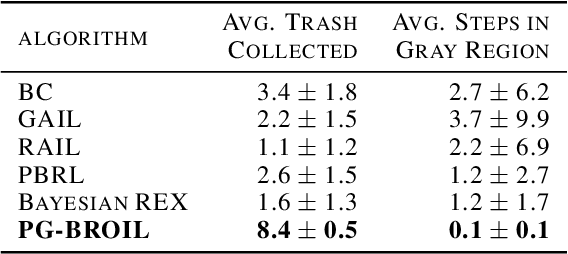
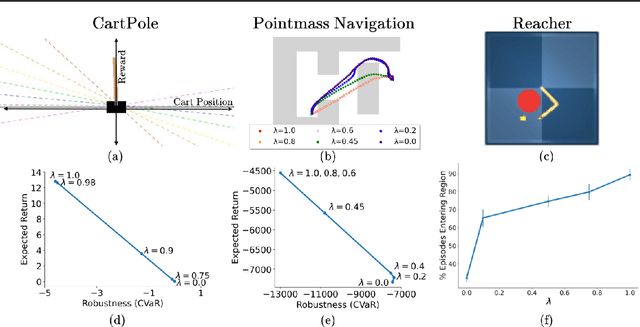
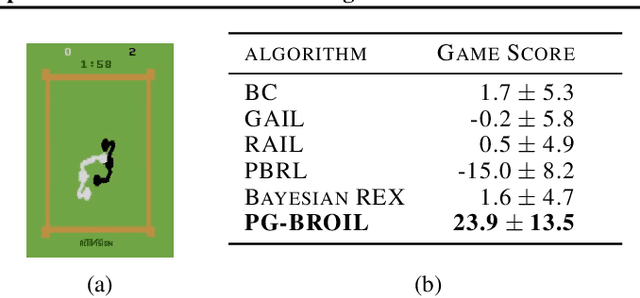
The difficulty in specifying rewards for many real-world problems has led to an increased focus on learning rewards from human feedback, such as demonstrations. However, there are often many different reward functions that explain the human feedback, leaving agents with uncertainty over what the true reward function is. While most policy optimization approaches handle this uncertainty by optimizing for expected performance, many applications demand risk-averse behavior. We derive a novel policy gradient-style robust optimization approach, PG-BROIL, that optimizes a soft-robust objective that balances expected performance and risk. To the best of our knowledge, PG-BROIL is the first policy optimization algorithm robust to a distribution of reward hypotheses which can scale to continuous MDPs. Results suggest that PG-BROIL can produce a family of behaviors ranging from risk-neutral to risk-averse and outperforms state-of-the-art imitation learning algorithms when learning from ambiguous demonstrations by hedging against uncertainty, rather than seeking to uniquely identify the demonstrator's reward function.