 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021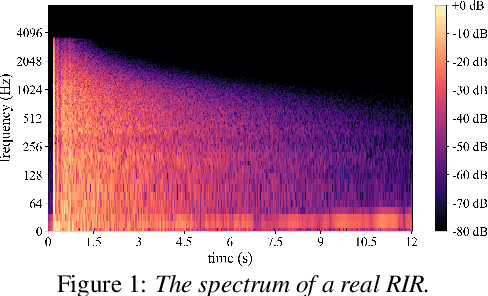
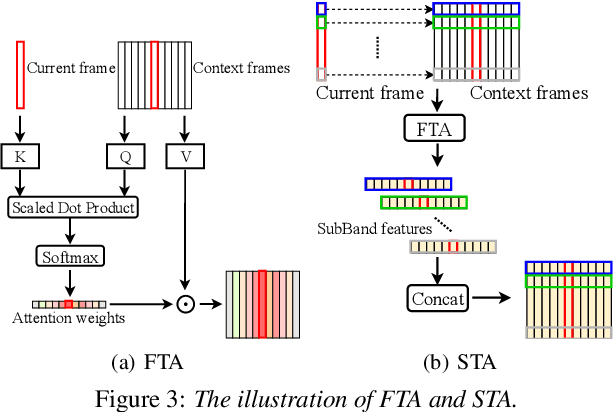
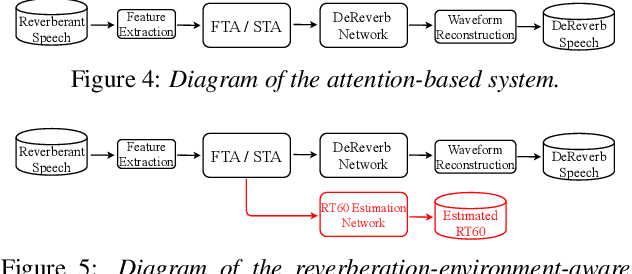
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
Sandglasset: A Light Multi-Granularity Self-attentive Network For Time-Domain Speech Separation
Mar 08, 2021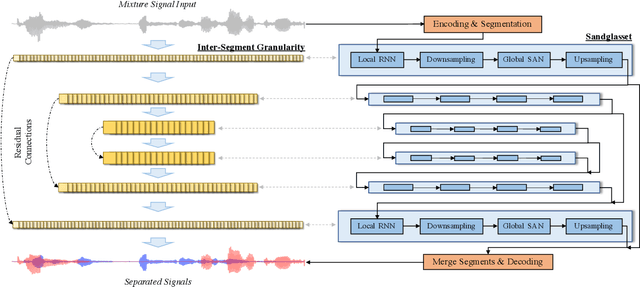
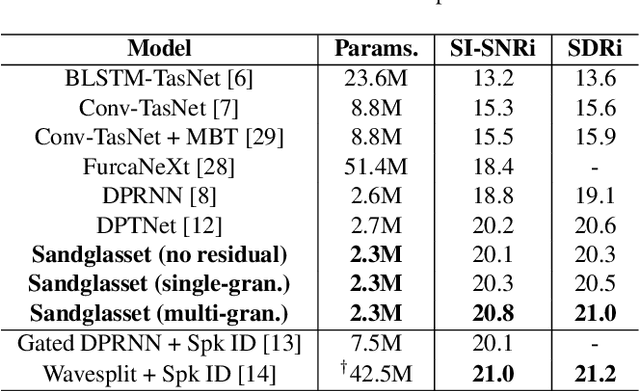
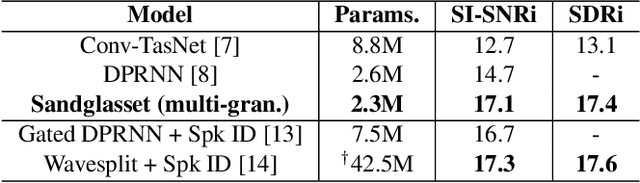
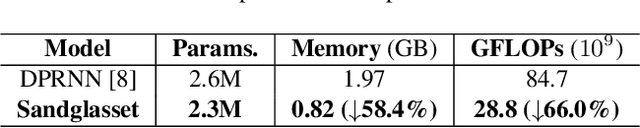
One of the leading single-channel speech separation (SS) models is based on a TasNet with a dual-path segmentation technique, where the size of each segment remains unchanged throughout all layers. In contrast, our key finding is that multi-granularity features are essential for enhancing contextual modeling and computational efficiency. We introduce a self-attentive network with a novel sandglass-shape, namely Sandglasset, which advances the state-of-the-art (SOTA) SS performance at significantly smaller model size and computational cost. Forward along each block inside Sandglasset, the temporal granularity of the features gradually becomes coarser until reaching half of the network blocks, and then successively turns finer towards the raw signal level. We also unfold that residual connections between features with the same granularity are critical for preserving information after passing through the bottleneck layer. Experiments show our Sandglasset with only 2.3M parameters has achieved the best results on two benchmark SS datasets -- WSJ0-2mix and WSJ0-3mix, where the SI-SNRi scores have been improved by absolute 0.8 dB and 2.4 dB, respectively, comparing to the prior SOTA results.
Tune-In: Training Under Negative Environments with Interference for Attention Networks Simulating Cocktail Party Effect
Mar 02, 2021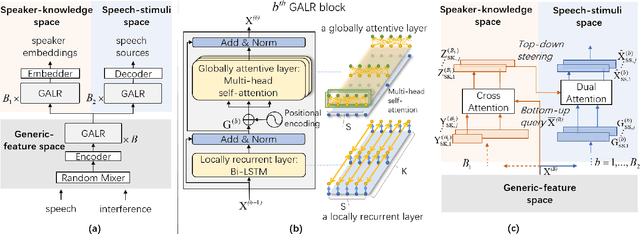
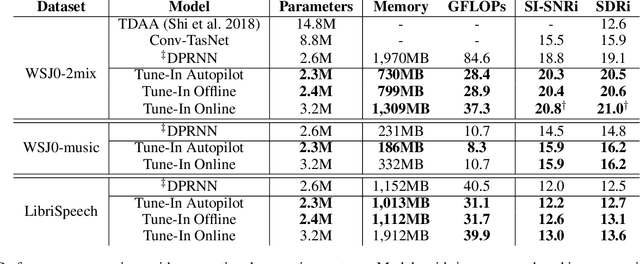
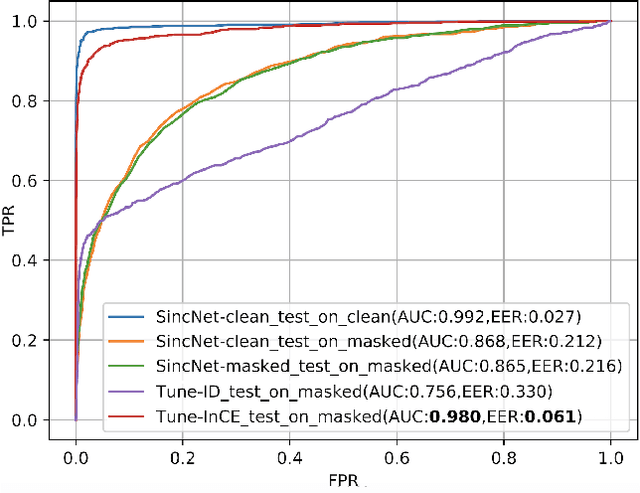
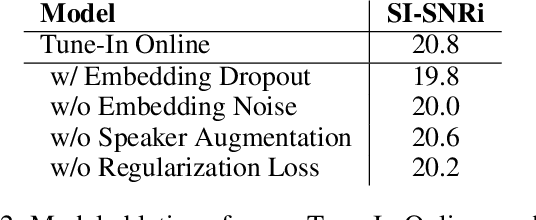
We study the cocktail party problem and propose a novel attention network called Tune-In, abbreviated for training under negative environments with interference. It firstly learns two separate spaces of speaker-knowledge and speech-stimuli based on a shared feature space, where a new block structure is designed as the building block for all spaces, and then cooperatively solves different tasks. Between the two spaces, information is cast towards each other via a novel cross- and dual-attention mechanism, mimicking the bottom-up and top-down processes of a human's cocktail party effect. It turns out that substantially discriminative and generalizable speaker representations can be learnt in severely interfered conditions via our self-supervised training. The experimental results verify this seeming paradox. The learnt speaker embedding has superior discriminative power than a standard speaker verification method; meanwhile, Tune-In achieves remarkably better speech separation performances in terms of SI-SNRi and SDRi consistently in all test modes, and especially at lower memory and computational consumption, than state-of-the-art benchmark systems.
Contrastive Separative Coding for Self-supervised Representation Learning
Mar 01, 2021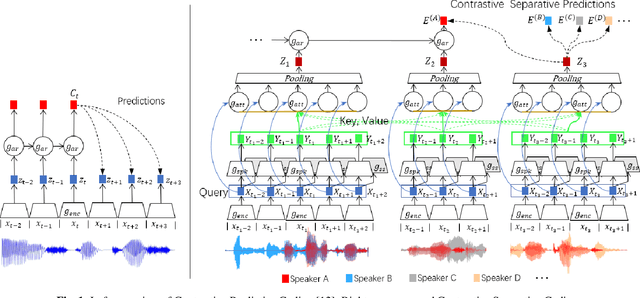
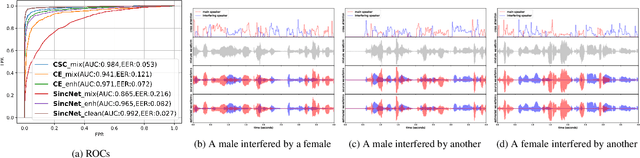
To extract robust deep representations from long sequential modeling of speech data, we propose a self-supervised learning approach, namely Contrastive Separative Coding (CSC). Our key finding is to learn such representations by separating the target signal from contrastive interfering signals. First, a multi-task separative encoder is built to extract shared separable and discriminative embedding; secondly, we propose a powerful cross-attention mechanism performed over speaker representations across various interfering conditions, allowing the model to focus on and globally aggregate the most critical information to answer the "query" (current bottom-up embedding) while paying less attention to interfering, noisy, or irrelevant parts; lastly, we form a new probabilistic contrastive loss which estimates and maximizes the mutual information between the representations and the global speaker vector. While most prior unsupervised methods have focused on predicting the future, neighboring, or missing samples, we take a different perspective of predicting the interfered samples. Moreover, our contrastive separative loss is free from negative sampling. The experiment demonstrates that our approach can learn useful representations achieving a strong speaker verification performance in adverse conditions.
VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
Feb 12, 2021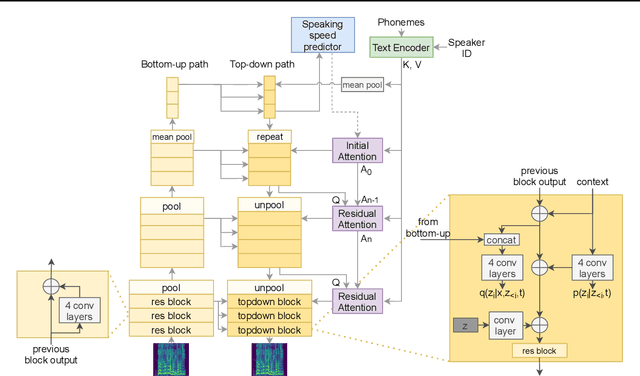
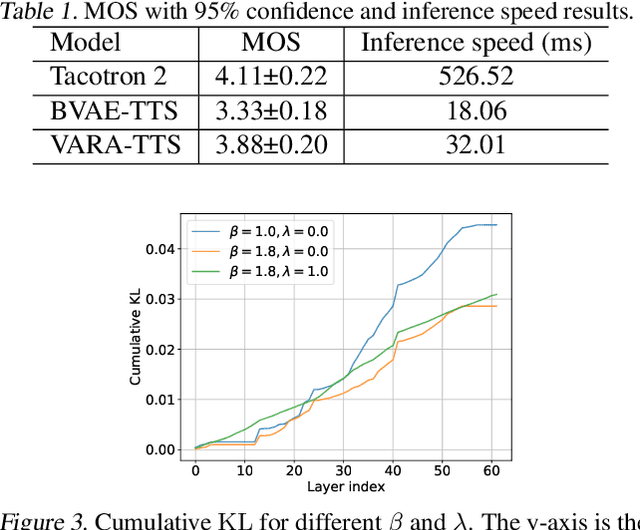

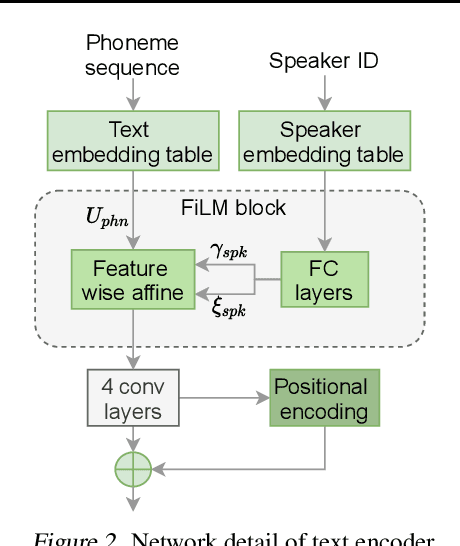
This paper proposes VARA-TTS, a non-autoregressive (non-AR) text-to-speech (TTS) model using a very deep Variational Autoencoder (VDVAE) with Residual Attention mechanism, which refines the textual-to-acoustic alignment layer-wisely. Hierarchical latent variables with different temporal resolutions from the VDVAE are used as queries for residual attention module. By leveraging the coarse global alignment from previous attention layer as an extra input, the following attention layer can produce a refined version of alignment. This amortizes the burden of learning the textual-to-acoustic alignment among multiple attention layers and outperforms the use of only a single attention layer in robustness. An utterance-level speaking speed factor is computed by a jointly-trained speaking speed predictor, which takes the mean-pooled latent variables of the coarsest layer as input, to determine number of acoustic frames at inference. Experimental results show that VARA-TTS achieves slightly inferior speech quality to an AR counterpart Tacotron 2 but an order-of-magnitude speed-up at inference; and outperforms an analogous non-AR model, BVAE-TTS, in terms of speech quality.
Effective Low-Cost Time-Domain Audio Separation Using Globally Attentive Locally Recurrent Networks
Jan 13, 2021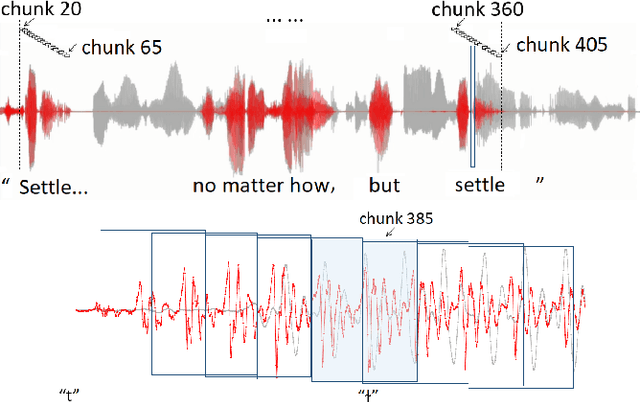

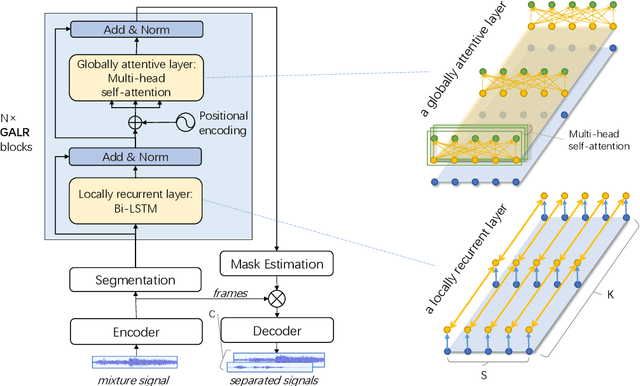

Recent research on the time-domain audio separation networks (TasNets) has brought great success to speech separation. Nevertheless, conventional TasNets struggle to satisfy the memory and latency constraints in industrial applications. In this regard, we design a low-cost high-performance architecture, namely, globally attentive locally recurrent (GALR) network. Alike the dual-path RNN (DPRNN), we first split a feature sequence into 2D segments and then process the sequence along both the intra- and inter-segment dimensions. Our main innovation lies in that, on top of features recurrently processed along the inter-segment dimensions, GALR applies a self-attention mechanism to the sequence along the inter-segment dimension, which aggregates context-aware information and also enables parallelization. Our experiments suggest that GALR is a notably more effective network than the prior work. On one hand, with only 1.5M parameters, it has achieved comparable separation performance at a much lower cost with 36.1% less runtime memory and 49.4% fewer computational operations, relative to the DPRNN. On the other hand, in a comparable model size with DPRNN, GALR has consistently outperformed DPRNN in three datasets, in particular, with a substantial margin of 2.4dB absolute improvement of SI-SNRi in the benchmark WSJ0-2mix task.
Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
Dec 03, 2020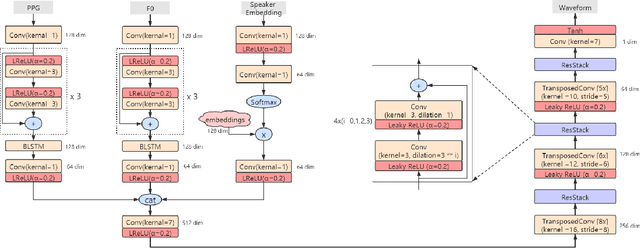

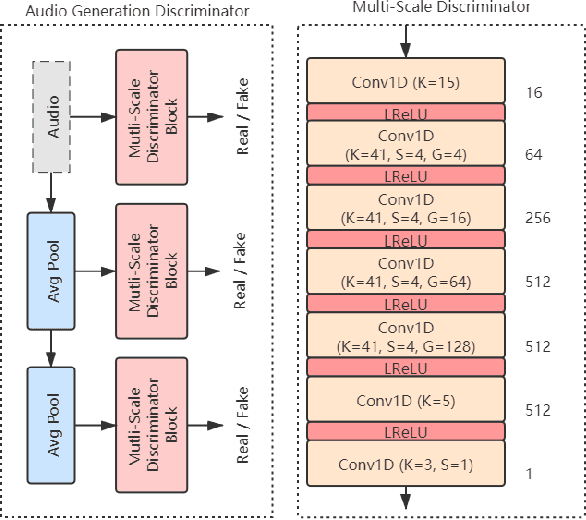

This paper describes an end-to-end adversarial singing voice conversion (EA-SVC) approach. It can directly generate arbitrary singing waveform by given phonetic posteriorgram (PPG) representing content, F0 representing pitch, and speaker embedding representing timbre, respectively. Proposed system is composed of three modules: generator $G$, the audio generation discriminator $D_{A}$, and the feature disentanglement discriminator $D_F$. The generator $G$ encodes the features in parallel and inversely transforms them into the target waveform. In order to make timbre conversion more stable and controllable, speaker embedding is further decomposed to the weighted sum of a group of trainable vectors representing different timbre clusters. Further, to realize more robust and accurate singing conversion, disentanglement discriminator $D_F$ is proposed to remove pitch and timbre related information that remains in the encoded PPG. Finally, a two-stage training is conducted to keep a stable and effective adversarial training process. Subjective evaluation results demonstrate the effectiveness of our proposed methods. Proposed system outperforms conventional cascade approach and the WaveNet based end-to-end approach in terms of both singing quality and singer similarity. Further objective analysis reveals that the model trained with the proposed two-stage training strategy can produce a smoother and sharper formant which leads to higher audio quality.
Non-Autoregressive Transformer ASR with CTC-Enhanced Decoder Input
Oct 28, 2020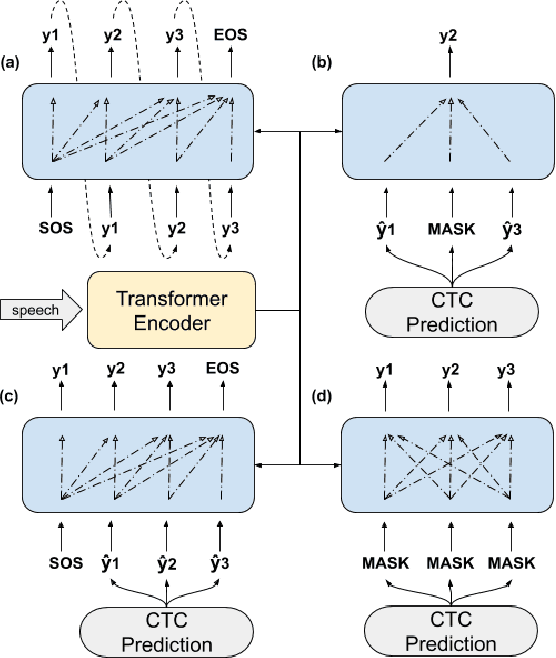
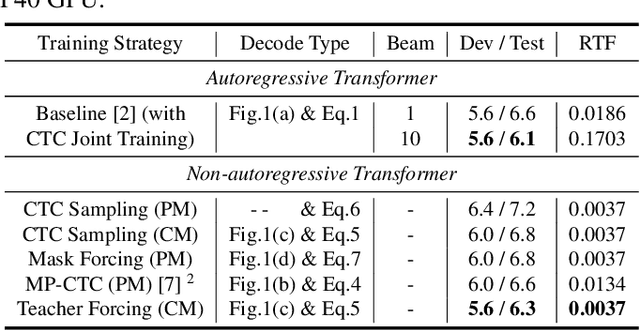
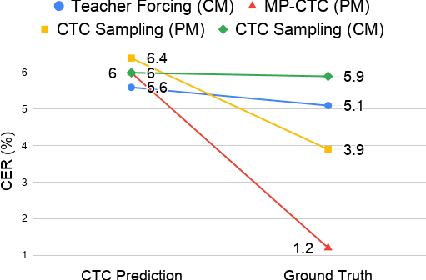

Non-autoregressive (NAR) transformer models have achieved significantly inference speedup but at the cost of inferior accuracy compared to autoregressive (AR) models in automatic speech recognition (ASR). Most of the NAR transformers take a fixed-length sequence filled with MASK tokens or a redundant sequence copied from encoder states as decoder input, they cannot provide efficient target-side information thus leading to accuracy degradation. To address this problem, we propose a CTC-enhanced NAR transformer, which generates target sequence by refining predictions of the CTC module. Experimental results show that our method outperforms all previous NAR counterparts and achieves 50x faster decoding speed than a strong AR baseline with only 0.0 ~ 0.3 absolute CER degradation on Aishell-1 and Aishell-2 datasets.
Replay and Synthetic Speech Detection with Res2net Architecture
Oct 28, 2020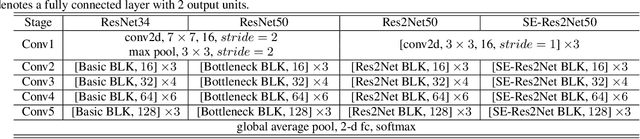
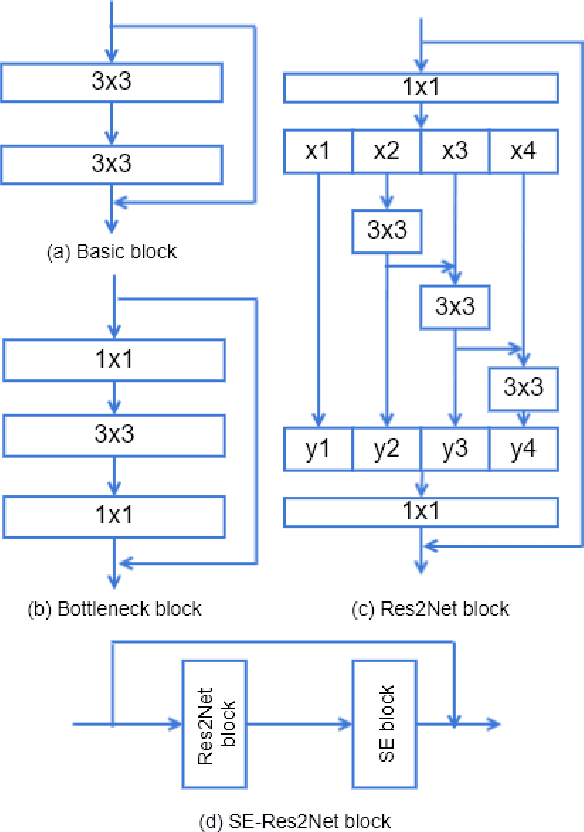
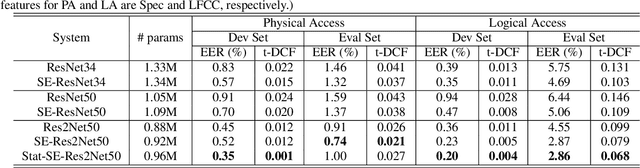
Existing approaches for replay and synthetic speech detection still lack generalizability to unseen spoofing attacks. This work proposes to leverage a novel model structure, so-called Res2Net, to improve the anti-spoofing countermeasure's generalizability. Res2Net mainly modifies the ResNet block to enable multiple feature scales. Specifically, it splits the feature maps within one block into multiple channel groups and designs a residual-like connection across different channel groups. Such connection increases the possible receptive fields, resulting in multiple feature scales. This multiple scaling mechanism significantly improves the countermeasure's generalizability to unseen spoofing attacks. It also decreases the model size compared to ResNet-based models. Experimental results show that the Res2Net model consistently outperforms ResNet34 and ResNet50 by a large margin in both physical access (PA) and logical access (LA) of the ASVspoof 2019 corpus. Moreover, integration with the squeeze-and-excitation (SE) block can further enhance performance. For feature engineering, we investigate the generalizability of Res2Net combined with different acoustic features, and observe that the constant-Q transform (CQT) achieves the most promising performance in both PA and LA scenarios. Our best single system outperforms other state-of-the-art single systems in both PA and LA of the ASVspoof 2019 corpus.
Dimsum @LaySumm 20: BART-based Approach for Scientific Document Summarization
Oct 19, 2020
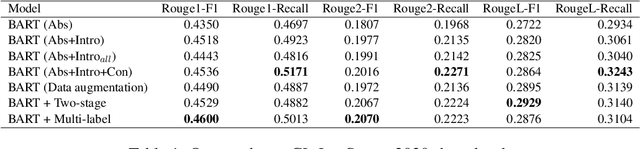
Lay summarization aims to generate lay summaries of scientific papers automatically. It is an essential task that can increase the relevance of science for all of society. In this paper, we build a lay summary generation system based on the BART model. We leverage sentence labels as extra supervision signals to improve the performance of lay summarization. In the CL-LaySumm 2020 shared task, our model achieves 46.00\% Rouge1-F1 score.