 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Fairy Tales Fair? Analyzing Gender Bias in Temporal Narrative Event Chains of Children's Fairy Tales
May 26, 2023Social biases and stereotypes are embedded in our culture in part through their presence in our stories, as evidenced by the rich history of humanities and social science literature analyzing such biases in children stories. Because these analyses are often conducted manually and at a small scale, such investigations can benefit from the use of more recent natural language processing methods that examine social bias in models and data corpora. Our work joins this interdisciplinary effort and makes a unique contribution by taking into account the event narrative structures when analyzing the social bias of stories. We propose a computational pipeline that automatically extracts a story's temporal narrative verb-based event chain for each of its characters as well as character attributes such as gender. We also present a verb-based event annotation scheme that can facilitate bias analysis by including categories such as those that align with traditional stereotypes. Through a case study analyzing gender bias in fairy tales, we demonstrate that our framework can reveal bias in not only the unigram verb-based events in which female and male characters participate but also in the temporal narrative order of such event participation.
Beyond Labels: Empowering Human with Natural Language Explanations through a Novel Active-Learning Architecture
May 22, 2023



Data annotation is a costly task; thus, researchers have proposed low-scenario learning techniques like Active-Learning (AL) to support human annotators; Yet, existing AL works focus only on the label, but overlook the natural language explanation of a data point, despite that real-world humans (e.g., doctors) often need both the labels and the corresponding explanations at the same time. This work proposes a novel AL architecture to support and reduce human annotations of both labels and explanations in low-resource scenarios. Our AL architecture incorporates an explanation-generation model that can explicitly generate natural language explanations for the prediction model and for assisting humans' decision-making in real-world. For our AL framework, we design a data diversity-based AL data selection strategy that leverages the explanation annotations. The automated AL simulation evaluations demonstrate that our data selection strategy consistently outperforms traditional data diversity-based strategy; furthermore, human evaluation demonstrates that humans prefer our generated explanations to the SOTA explanation-generation system.
Are Human Explanations Always Helpful? Towards Objective Evaluation of Human Natural Language Explanations
May 04, 2023



Human-annotated labels and explanations are critical for training explainable NLP models. However, unlike human-annotated labels whose quality is easier to calibrate (e.g., with a majority vote), human-crafted free-form explanations can be quite subjective, as some recent works have discussed. Before blindly using them as ground truth to train ML models, a vital question needs to be asked: How do we evaluate a human-annotated explanation's quality? In this paper, we build on the view that the quality of a human-annotated explanation can be measured based on its helpfulness (or impairment) to the ML models' performance for the desired NLP tasks for which the annotations were collected. In comparison to the commonly used Simulatability score, we define a new metric that can take into consideration the helpfulness of an explanation for model performance at both fine-tuning and inference. With the help of a unified dataset format, we evaluated the proposed metric on five datasets (e.g., e-SNLI) against two model architectures (T5 and BART), and the results show that our proposed metric can objectively evaluate the quality of human-annotated explanations, while Simulatability falls short.
Model Sketching: Centering Concepts in Early-Stage Machine Learning Model Design
Mar 06, 2023



Machine learning practitioners often end up tunneling on low-level technical details like model architectures and performance metrics. Could early model development instead focus on high-level questions of which factors a model ought to pay attention to? Inspired by the practice of sketching in design, which distills ideas to their minimal representation, we introduce model sketching: a technical framework for iteratively and rapidly authoring functional approximations of a machine learning model's decision-making logic. Model sketching refocuses practitioner attention on composing high-level, human-understandable concepts that the model is expected to reason over (e.g., profanity, racism, or sarcasm in a content moderation task) using zero-shot concept instantiation. In an evaluation with 17 ML practitioners, model sketching reframed thinking from implementation to higher-level exploration, prompted iteration on a broader range of model designs, and helped identify gaps in the problem formulation$\unicode{x2014}$all in a fraction of the time ordinarily required to build a model.
KnowledgeShovel: An AI-in-the-Loop Document Annotation System for Scientific Knowledge Base Construction
Oct 06, 2022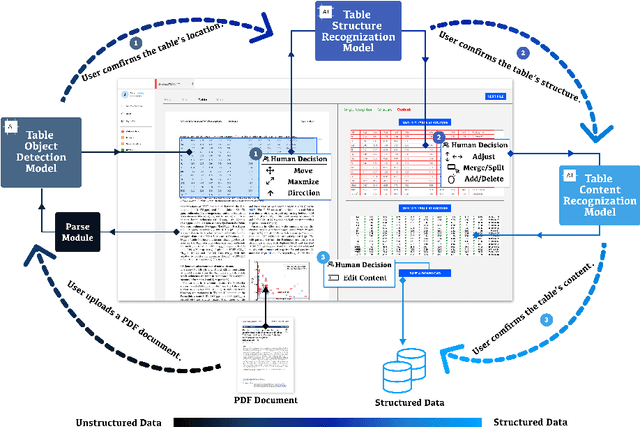
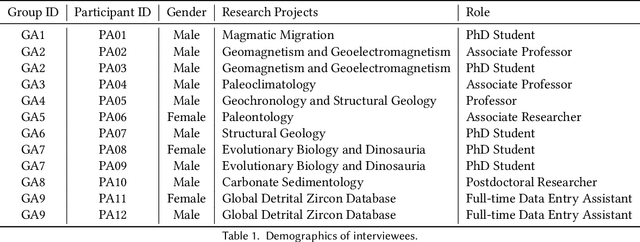
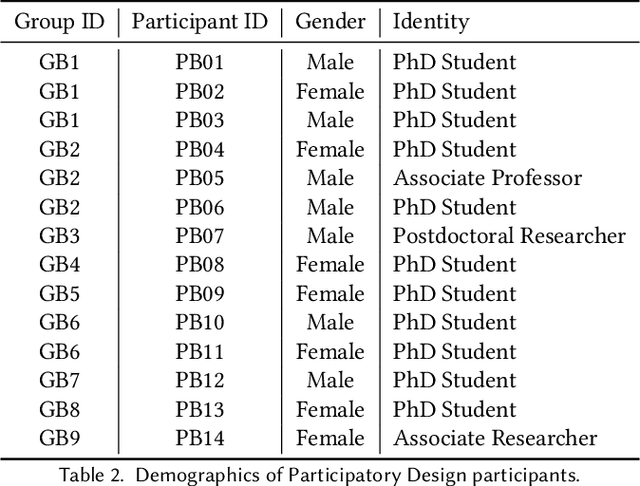
Constructing a comprehensive, accurate, and useful scientific knowledge base is crucial for human researchers synthesizing scientific knowledge and for enabling Al-driven scientific discovery. However, the current process is difficult, error-prone, and laborious due to (1) the enormous amount of scientific literature available; (2) the highly-specialized scientific domains; (3) the diverse modalities of information (text, figure, table); and, (4) the silos of scientific knowledge in different publications with inconsistent formats and structures. Informed by a formative study and iterated with participatory design workshops, we designed and developed KnowledgeShovel, an Al-in-the-Loop document annotation system for researchers to construct scientific knowledge bases. The design of KnowledgeShovel introduces a multi-step multi-modal human-AI collaboration pipeline that aligns with users' existing workflows to improve data accuracy while reducing the human burden. A follow-up user evaluation with 7 geoscience researchers shows that KnowledgeShovel can enable efficient construction of scientific knowledge bases with satisfactory accuracy.
NECE: Narrative Event Chain Extraction Toolkit
Aug 19, 2022
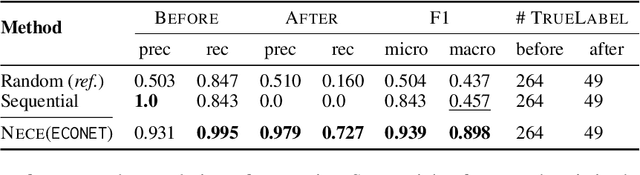
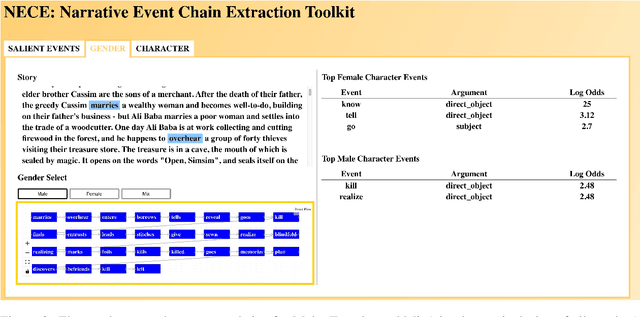
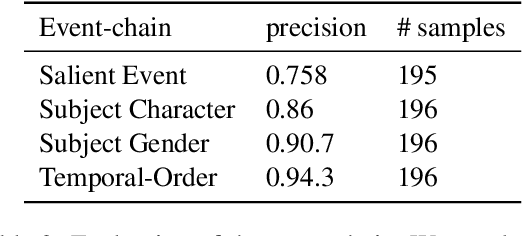
NECE is an event-based text analysis toolkit built for narrative documents. NECE aims to provide users open and easy accesses to an event-based summary and abstraction of long narrative documents through both a graphic interface and a python package, which can be readily used in narrative analysis, understanding, or other advanced purposes. Our work addresses the challenge of long passage events extraction and temporal ordering of key events; at the same time, it offers options to select and view events related to narrative entities, such as main characters and gender groups. We conduct human evaluation to demonstrate the quality of the event chain extraction system and character features mining algorithms. Lastly, we shed light on the toolkit's potential downstream applications by demonstrating its usage in gender bias analysis and Question-Answering tasks.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022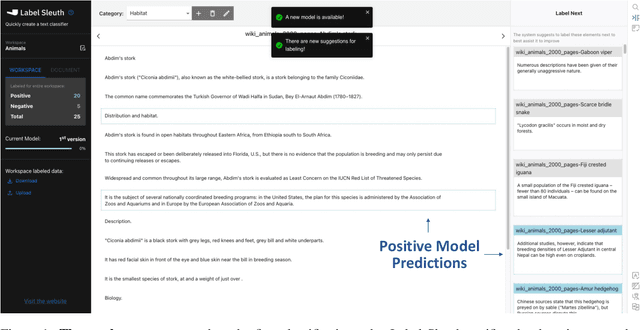

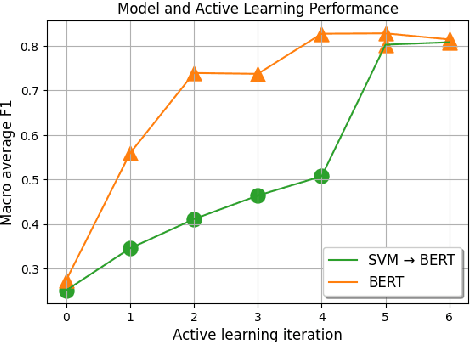

Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022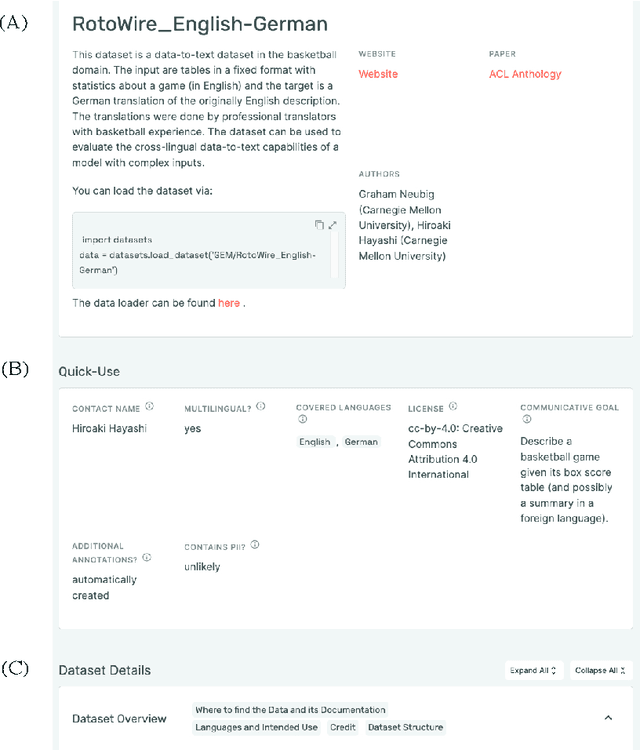

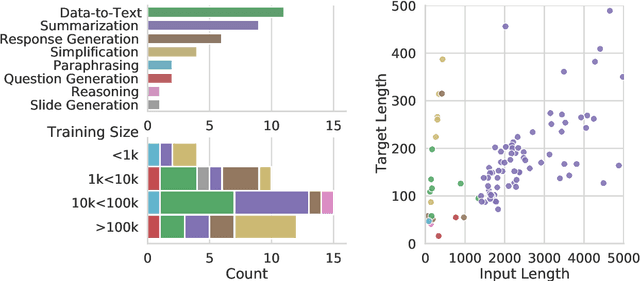

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
A Word is Worth A Thousand Dollars: Adversarial Attack on Tweets Fools Stock Prediction
May 11, 2022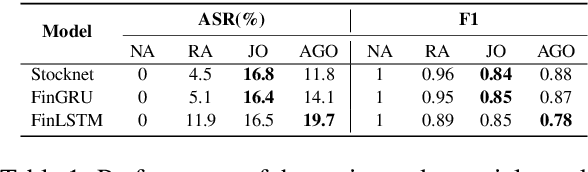
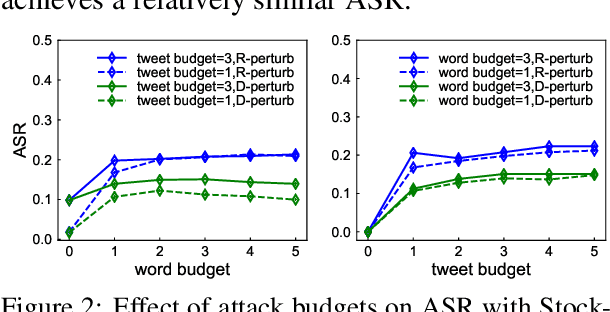
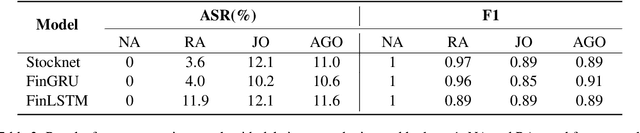
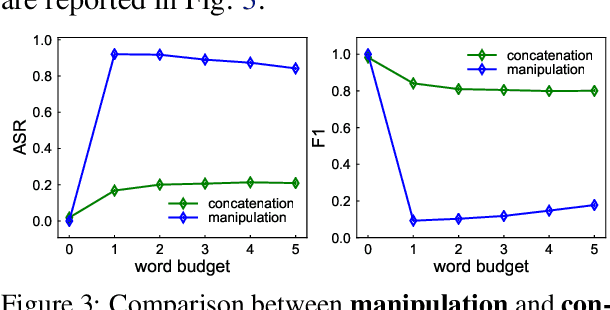
More and more investors and machine learning models rely on social media (e.g., Twitter and Reddit) to gather real-time information and sentiment to predict stock price movements. Although text-based models are known to be vulnerable to adversarial attacks, whether stock prediction models have similar vulnerability is underexplored. In this paper, we experiment with a variety of adversarial attack configurations to fool three stock prediction victim models. We address the task of adversarial generation by solving combinatorial optimization problems with semantics and budget constraints. Our results show that the proposed attack method can achieve consistent success rates and cause significant monetary loss in trading simulation by simply concatenating a perturbed but semantically similar tweet.
Towards a Progression-Aware Autonomous Dialogue Agent
May 10, 2022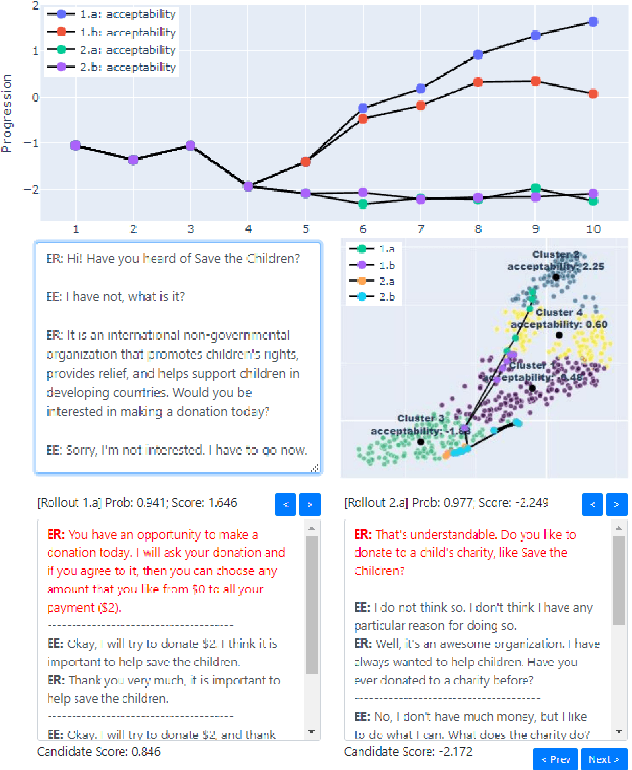

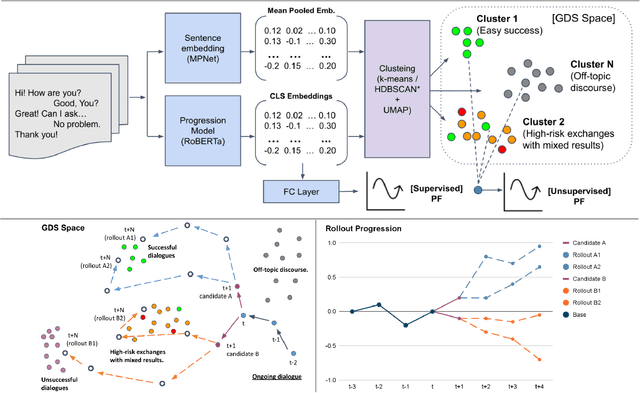
Recent advances in large-scale language modeling and generation have enabled the creation of dialogue agents that exhibit human-like responses in a wide range of conversational scenarios spanning a diverse set of tasks, from general chit-chat to focused goal-oriented discourse. While these agents excel at generating high-quality responses that are relevant to prior context, they suffer from a lack of awareness of the overall direction in which the conversation is headed, and the likelihood of task success inherent therein. Thus, we propose a framework in which dialogue agents can evaluate the progression of a conversation toward or away from desired outcomes, and use this signal to inform planning for subsequent responses. Our framework is composed of three key elements: (1) the notion of a "global" dialogue state (GDS) space, (2) a task-specific progression function (PF) computed in terms of a conversation's trajectory through this space, and (3) a planning mechanism based on dialogue rollouts by which an agent may use progression signals to select its next response.