 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Locally, Explain Globally: Graph-Guided LLM Investigations via Local Reasoning and Belief Propagation
Jan 25, 2026LLM agents excel when environments are mostly static and the needed information fits in a model's context window, but they often fail in open-ended investigations where explanations must be constructed by iteratively mining evidence from massive, heterogeneous operational data. These investigations exhibit hidden dependency structure: entities interact, signals co-vary, and the importance of a fact may only become clear after other evidence is discovered. Because the context window is bounded, agents must summarize intermediate findings before their significance is known, increasing the risk of discarding key evidence. ReAct-style agents are especially brittle in this regime. Their retrieve-summarize-reason loop makes conclusions sensitive to exploration order and introduces run-to-run non-determinism, producing a reliability gap where Pass-at-k may be high but Majority-at-k remains low. Simply sampling more rollouts or generating longer reasoning traces does not reliably stabilize results, since hypotheses cannot be autonomously checked as new evidence arrives and there is no explicit mechanism for belief bookkeeping and revision. In addition, ReAct entangles semantic reasoning with controller duties such as tool orchestration and state tracking, so execution errors and plan drift degrade reasoning while consuming scarce context. We address these issues by formulating investigation as abductive reasoning over a dependency graph and proposing EoG (Explanations over Graphs), a disaggregated framework in which an LLM performs bounded local evidence mining and labeling (cause vs symptom) while a deterministic controller manages traversal, state, and belief propagation to compute a minimal explanatory frontier. On a representative ITBench diagnostics task, EoG improves both accuracy and run-to-run consistency over ReAct baselines, including a 7x average gain in Majority-at-k entity F1.
Are Fairy Tales Fair? Analyzing Gender Bias in Temporal Narrative Event Chains of Children's Fairy Tales
May 26, 2023Social biases and stereotypes are embedded in our culture in part through their presence in our stories, as evidenced by the rich history of humanities and social science literature analyzing such biases in children stories. Because these analyses are often conducted manually and at a small scale, such investigations can benefit from the use of more recent natural language processing methods that examine social bias in models and data corpora. Our work joins this interdisciplinary effort and makes a unique contribution by taking into account the event narrative structures when analyzing the social bias of stories. We propose a computational pipeline that automatically extracts a story's temporal narrative verb-based event chain for each of its characters as well as character attributes such as gender. We also present a verb-based event annotation scheme that can facilitate bias analysis by including categories such as those that align with traditional stereotypes. Through a case study analyzing gender bias in fairy tales, we demonstrate that our framework can reveal bias in not only the unigram verb-based events in which female and male characters participate but also in the temporal narrative order of such event participation.
NECE: Narrative Event Chain Extraction Toolkit
Aug 19, 2022
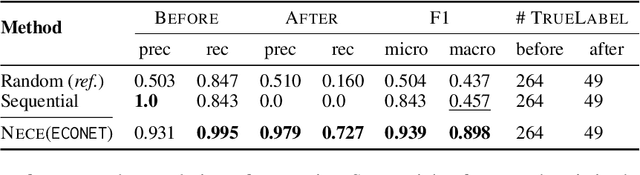
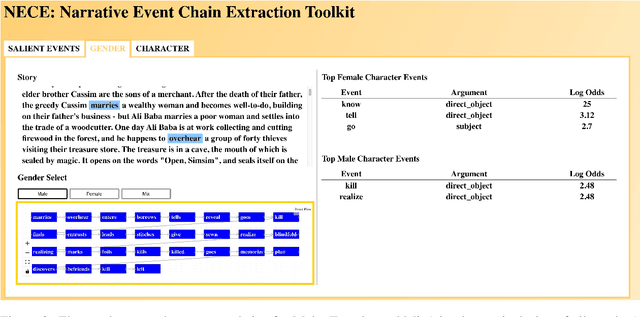
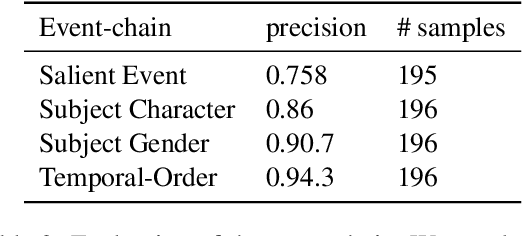
NECE is an event-based text analysis toolkit built for narrative documents. NECE aims to provide users open and easy accesses to an event-based summary and abstraction of long narrative documents through both a graphic interface and a python package, which can be readily used in narrative analysis, understanding, or other advanced purposes. Our work addresses the challenge of long passage events extraction and temporal ordering of key events; at the same time, it offers options to select and view events related to narrative entities, such as main characters and gender groups. We conduct human evaluation to demonstrate the quality of the event chain extraction system and character features mining algorithms. Lastly, we shed light on the toolkit's potential downstream applications by demonstrating its usage in gender bias analysis and Question-Answering tasks.