 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Policy Projector: Grounding LLM Policy Design in Iterative Mapmaking
Sep 26, 2024Whether a large language model policy is an explicit constitution or an implicit reward model, it is challenging to assess coverage over the unbounded set of real-world situations that a policy must contend with. We introduce an AI policy design process inspired by mapmaking, which has developed tactics for visualizing and iterating on maps even when full coverage is not possible. With Policy Projector, policy designers can survey the landscape of model input-output pairs, define custom regions (e.g., "violence"), and navigate these regions with rules that can be applied to LLM outputs (e.g., if output contains "violence" and "graphic details," then rewrite without "graphic details"). Policy Projector supports interactive policy authoring using LLM classification and steering and a map visualization reflecting the policy designer's work. In an evaluation with 12 AI safety experts, our system helps policy designers to address problematic model behaviors extending beyond an existing, comprehensive harm taxonomy.
Concept Induction: Analyzing Unstructured Text with High-Level Concepts Using LLooM
Apr 18, 2024



Data analysts have long sought to turn unstructured text data into meaningful concepts. Though common, topic modeling and clustering focus on lower-level keywords and require significant interpretative work. We introduce concept induction, a computational process that instead produces high-level concepts, defined by explicit inclusion criteria, from unstructured text. For a dataset of toxic online comments, where a state-of-the-art BERTopic model outputs "women, power, female," concept induction produces high-level concepts such as "Criticism of traditional gender roles" and "Dismissal of women's concerns." We present LLooM, a concept induction algorithm that leverages large language models to iteratively synthesize sampled text and propose human-interpretable concepts of increasing generality. We then instantiate LLooM in a mixed-initiative text analysis tool, enabling analysts to shift their attention from interpreting topics to engaging in theory-driven analysis. Through technical evaluations and four analysis scenarios ranging from literature review to content moderation, we find that LLooM's concepts improve upon the prior art of topic models in terms of quality and data coverage. In expert case studies, LLooM helped researchers to uncover new insights even from familiar datasets, for example by suggesting a previously unnoticed concept of attacks on out-party stances in a political social media dataset.
Clarify: Improving Model Robustness With Natural Language Corrections
Feb 06, 2024



In supervised learning, models are trained to extract correlations from a static dataset. This often leads to models that rely on high-level misconceptions. To prevent such misconceptions, we must necessarily provide additional information beyond the training data. Existing methods incorporate forms of additional instance-level supervision, such as labels for spurious features or additional labeled data from a balanced distribution. Such strategies can become prohibitively costly for large-scale datasets since they require additional annotation at a scale close to the original training data. We hypothesize that targeted natural language feedback about a model's misconceptions is a more efficient form of additional supervision. We introduce Clarify, a novel interface and method for interactively correcting model misconceptions. Through Clarify, users need only provide a short text description to describe a model's consistent failure patterns. Then, in an entirely automated way, we use such descriptions to improve the training process by reweighting the training data or gathering additional targeted data. Our user studies show that non-expert users can successfully describe model misconceptions via Clarify, improving worst-group accuracy by an average of 17.1% in two datasets. Additionally, we use Clarify to find and rectify 31 novel hard subpopulations in the ImageNet dataset, improving minority-split accuracy from 21.1% to 28.7%.
Designing LLM Chains by Adapting Techniques from Crowdsourcing Workflows
Dec 20, 2023



LLM chains enable complex tasks by decomposing work into a sequence of sub-tasks. Crowdsourcing workflows similarly decompose complex tasks into smaller tasks for human crowdworkers. Chains address LLM errors analogously to the way crowdsourcing workflows address human error. To characterize opportunities for LLM chaining, we survey 107 papers across the crowdsourcing and chaining literature to construct a design space for chain development. The design space connects an LLM designer's objectives to strategies they can use to achieve those objectives, and tactics to implement each strategy. To explore how techniques from crowdsourcing may apply to chaining, we adapt crowdsourcing workflows to implement LLM chains across three case studies: creating a taxonomy, shortening text, and writing a short story. From the design space and our case studies, we identify which techniques transfer from crowdsourcing to LLM chaining and raise implications for future research and development.
Embedding Democratic Values into Social Media AIs via Societal Objective Functions
Jul 26, 2023



Can we design artificial intelligence (AI) systems that rank our social media feeds to consider democratic values such as mitigating partisan animosity as part of their objective functions? We introduce a method for translating established, vetted social scientific constructs into AI objective functions, which we term societal objective functions, and demonstrate the method with application to the political science construct of anti-democratic attitudes. Traditionally, we have lacked observable outcomes to use to train such models, however, the social sciences have developed survey instruments and qualitative codebooks for these constructs, and their precision facilitates translation into detailed prompts for large language models. We apply this method to create a democratic attitude model that estimates the extent to which a social media post promotes anti-democratic attitudes, and test this democratic attitude model across three studies. In Study 1, we first test the attitudinal and behavioral effectiveness of the intervention among US partisans (N=1,380) by manually annotating (alpha=.895) social media posts with anti-democratic attitude scores and testing several feed ranking conditions based on these scores. Removal (d=.20) and downranking feeds (d=.25) reduced participants' partisan animosity without compromising their experience and engagement. In Study 2, we scale up the manual labels by creating the democratic attitude model, finding strong agreement with manual labels (rho=.75). Finally, in Study 3, we replicate Study 1 using the democratic attitude model instead of manual labels to test its attitudinal and behavioral impact (N=558), and again find that the feed downranking using the societal objective function reduced partisan animosity (d=.25). This method presents a novel strategy to draw on social science theory and methods to mitigate societal harms in social media AIs.
Model Sketching: Centering Concepts in Early-Stage Machine Learning Model Design
Mar 06, 2023



Machine learning practitioners often end up tunneling on low-level technical details like model architectures and performance metrics. Could early model development instead focus on high-level questions of which factors a model ought to pay attention to? Inspired by the practice of sketching in design, which distills ideas to their minimal representation, we introduce model sketching: a technical framework for iteratively and rapidly authoring functional approximations of a machine learning model's decision-making logic. Model sketching refocuses practitioner attention on composing high-level, human-understandable concepts that the model is expected to reason over (e.g., profanity, racism, or sarcasm in a content moderation task) using zero-shot concept instantiation. In an evaluation with 17 ML practitioners, model sketching reframed thinking from implementation to higher-level exploration, prompted iteration on a broader range of model designs, and helped identify gaps in the problem formulation$\unicode{x2014}$all in a fraction of the time ordinarily required to build a model.
Jury Learning: Integrating Dissenting Voices into Machine Learning Models
Feb 07, 2022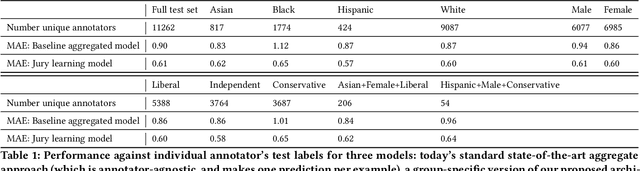

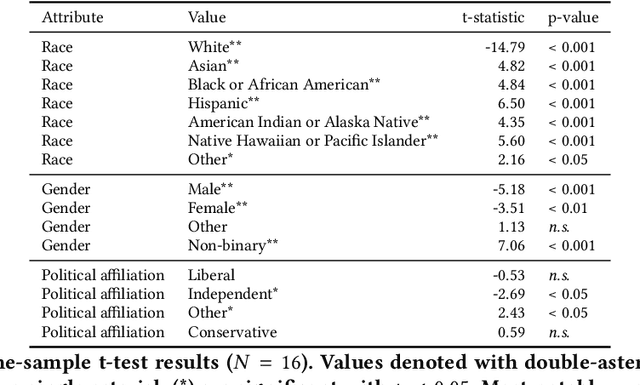

Whose labels should a machine learning (ML) algorithm learn to emulate? For ML tasks ranging from online comment toxicity to misinformation detection to medical diagnosis, different groups in society may have irreconcilable disagreements about ground truth labels. Supervised ML today resolves these label disagreements implicitly using majority vote, which overrides minority groups' labels. We introduce jury learning, a supervised ML approach that resolves these disagreements explicitly through the metaphor of a jury: defining which people or groups, in what proportion, determine the classifier's prediction. For example, a jury learning model for online toxicity might centrally feature women and Black jurors, who are commonly targets of online harassment. To enable jury learning, we contribute a deep learning architecture that models every annotator in a dataset, samples from annotators' models to populate the jury, then runs inference to classify. Our architecture enables juries that dynamically adapt their composition, explore counterfactuals, and visualize dissent.