 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Generative Approach for Emotion Detection and Reasoning
Aug 09, 2024Large language models (LLMs) have demonstrated impressive performance in mathematical and commonsense reasoning tasks using chain-of-thought (CoT) prompting techniques. But can they perform emotional reasoning by concatenating `Let's think step-by-step' to the input prompt? In this paper we investigate this question along with introducing a novel approach to zero-shot emotion detection and emotional reasoning using LLMs. Existing state of the art zero-shot approaches rely on textual entailment models to choose the most appropriate emotion label for an input text. We argue that this strongly restricts the model to a fixed set of labels which may not be suitable or sufficient for many applications where emotion analysis is required. Instead, we propose framing the problem of emotion analysis as a generative question-answering (QA) task. Our approach uses a two step methodology of generating relevant context or background knowledge to answer the emotion detection question step-by-step. Our paper is the first work on using a generative approach to jointly address the tasks of emotion detection and emotional reasoning for texts. We evaluate our approach on two popular emotion detection datasets and also release the fine-grained emotion labels and explanations for further training and fine-tuning of emotional reasoning systems.
Figuratively Speaking: Authorship Attribution via Multi-Task Figurative Language Modeling
Jun 12, 2024The identification of Figurative Language (FL) features in text is crucial for various Natural Language Processing (NLP) tasks, where understanding of the author's intended meaning and its nuances is key for successful communication. At the same time, the use of a specific blend of various FL forms most accurately reflects a writer's style, rather than the use of any single construct, such as just metaphors or irony. Thus, we postulate that FL features could play an important role in Authorship Attribution (AA) tasks. We believe that our is the first computational study of AA based on FL use. Accordingly, we propose a Multi-task Figurative Language Model (MFLM) that learns to detect multiple FL features in text at once. We demonstrate, through detailed evaluation across multiple test sets, that the our model tends to perform equally or outperform specialized binary models in FL detection. Subsequently, we evaluate the predictive capability of joint FL features towards the AA task on three datasets, observing improved AA performance through the integration of MFLM embeddings.
Uncovering Agendas: A Novel French & English Dataset for Agenda Detection on Social Media
May 01, 2024The behavior and decision making of groups or communities can be dramatically influenced by individuals pushing particular agendas, e.g., to promote or disparage a person or an activity, to call for action, etc.. In the examination of online influence campaigns, particularly those related to important political and social events, scholars often concentrate on identifying the sources responsible for setting and controlling the agenda (e.g., public media). In this article we present a methodology for detecting specific instances of agenda control through social media where annotated data is limited or non-existent. By using a modest corpus of Twitter messages centered on the 2022 French Presidential Elections, we carry out a comprehensive evaluation of various approaches and techniques that can be applied to this problem. Our findings demonstrate that by treating the task as a textual entailment problem, it is possible to overcome the requirement for a large annotated training dataset.
Social Convos: Capturing Agendas and Emotions on Social Media
Feb 23, 2024Social media platforms are popular tools for disseminating targeted information during major public events like elections or pandemics. Systematic analysis of the message traffic can provide valuable insights into prevailing opinions and social dynamics among different segments of the population. We are specifically interested in influence spread, and in particular whether more deliberate influence operations can be detected. However, filtering out the essential messages with telltale influence indicators from the extensive and often chaotic social media traffic is a major challenge. In this paper we present a novel approach to extract influence indicators from messages circulating among groups of users discussing particular topics. We build upon the concept of a convo to identify influential authors who are actively promoting some particular agenda around that topic within the group. We focus on two influence indicators: the (control of) agenda and the use of emotional language.
Bergeron: Combating Adversarial Attacks through a Conscience-Based Alignment Framework
Nov 16, 2023



Modern Large language models (LLMs) can still generate responses that may not be aligned with human expectations or values. While many weight-based alignment methods have been proposed, many of them still leave models vulnerable to attacks when used on their own. To help mitigate this issue, we introduce Bergeron, a framework designed to improve the robustness of LLMs against adversarial attacks. Bergeron employs a two-tiered architecture. Here, a secondary LLM serves as a simulated conscience that safeguards a primary LLM. We do this by monitoring for and correcting potentially harmful text within both the prompt inputs and the generated outputs of the primary LLM. Empirical evaluation shows that Bergeron can improve the alignment and robustness of several popular LLMs without costly fine-tuning. It aids both open-source and black-box LLMs by complementing and reinforcing their existing alignment training.
Towards a Progression-Aware Autonomous Dialogue Agent
May 10, 2022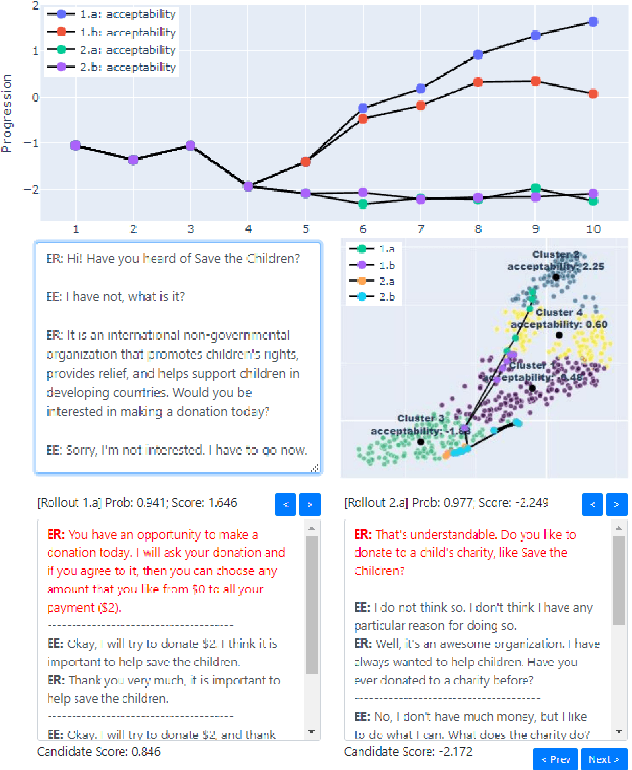

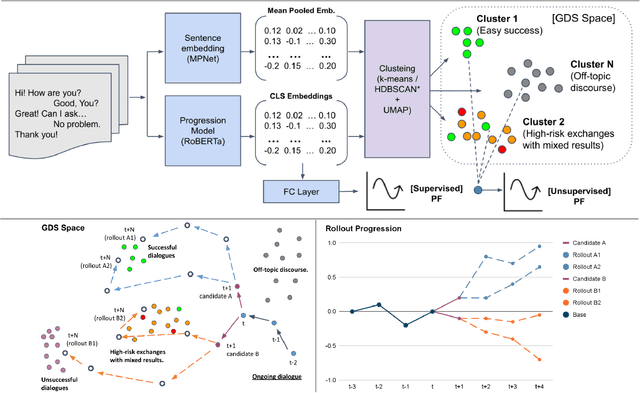
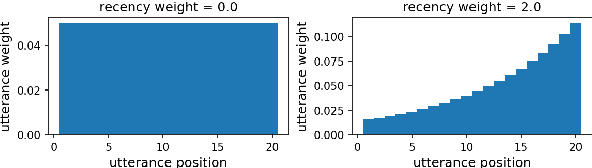
Recent advances in large-scale language modeling and generation have enabled the creation of dialogue agents that exhibit human-like responses in a wide range of conversational scenarios spanning a diverse set of tasks, from general chit-chat to focused goal-oriented discourse. While these agents excel at generating high-quality responses that are relevant to prior context, they suffer from a lack of awareness of the overall direction in which the conversation is headed, and the likelihood of task success inherent therein. Thus, we propose a framework in which dialogue agents can evaluate the progression of a conversation toward or away from desired outcomes, and use this signal to inform planning for subsequent responses. Our framework is composed of three key elements: (1) the notion of a "global" dialogue state (GDS) space, (2) a task-specific progression function (PF) computed in terms of a conversation's trajectory through this space, and (3) a planning mechanism based on dialogue rollouts by which an agent may use progression signals to select its next response.
Learning to Plan and Realize Separately for Open-Ended Dialogue Systems
Oct 04, 2020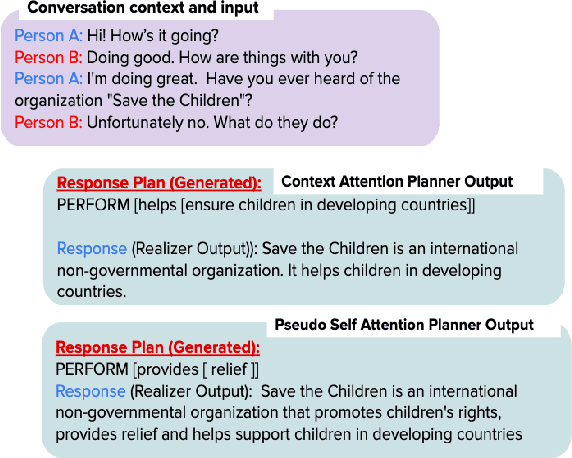

Achieving true human-like ability to conduct a conversation remains an elusive goal for open-ended dialogue systems. We posit this is because extant approaches towards natural language generation (NLG) are typically construed as end-to-end architectures that do not adequately model human generation processes. To investigate, we decouple generation into two separate phases: planning and realization. In the planning phase, we train two planners to generate plans for response utterances. The realization phase uses response plans to produce an appropriate response. Through rigorous evaluations, both automated and human, we demonstrate that decoupling the process into planning and realization performs better than an end-to-end approach.
The Panacea Threat Intelligence and Active Defense Platform
Apr 20, 2020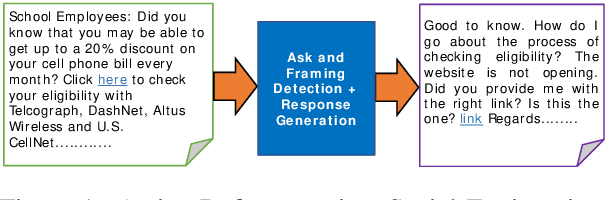
We describe Panacea, a system that supports natural language processing (NLP) components for active defenses against social engineering attacks. We deploy a pipeline of human language technology, including Ask and Framing Detection, Named Entity Recognition, Dialogue Engineering, and Stylometry. Panacea processes modern message formats through a plug-in architecture to accommodate innovative approaches for message analysis, knowledge representation and dialogue generation. The novelty of the Panacea system is that uses NLP for cyber defense and engages the attacker using bots to elicit evidence to attribute to the attacker and to waste the attacker's time and resources.
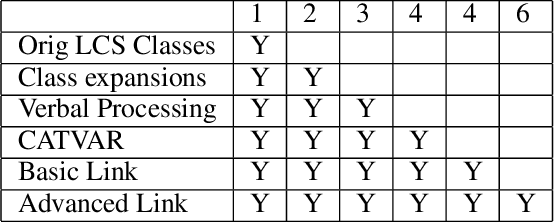
Adaptation of a Lexical Organization for Social Engineering Detection and Response Generation
Apr 20, 2020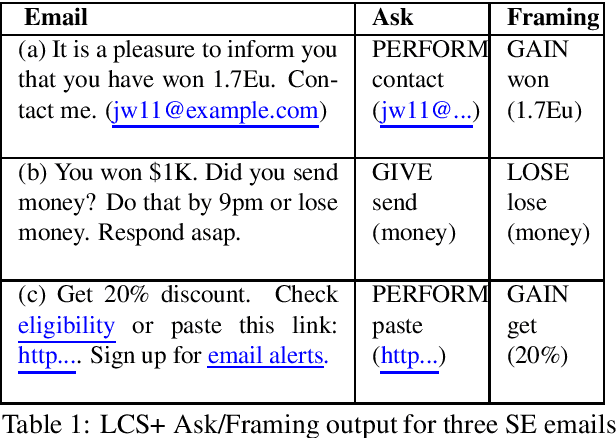

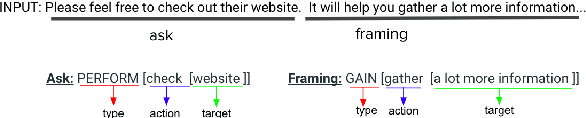
We present a paradigm for extensible lexicon development based on Lexical Conceptual Structure to support social engineering detection and response generation. We leverage the central notions of ask (elicitation of behaviors such as providing access to money) and framing (risk/reward implied by the ask). We demonstrate improvements in ask/framing detection through refinements to our lexical organization and show that response generation qualitatively improves as ask/framing detection performance improves. The paradigm presents a systematic and efficient approach to resource adaptation for improved task-specific performance.
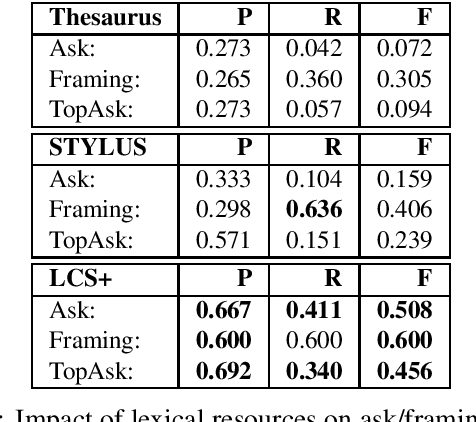
Detecting Asks in SE attacks: Impact of Linguistic and Structural Knowledge
Feb 25, 2020
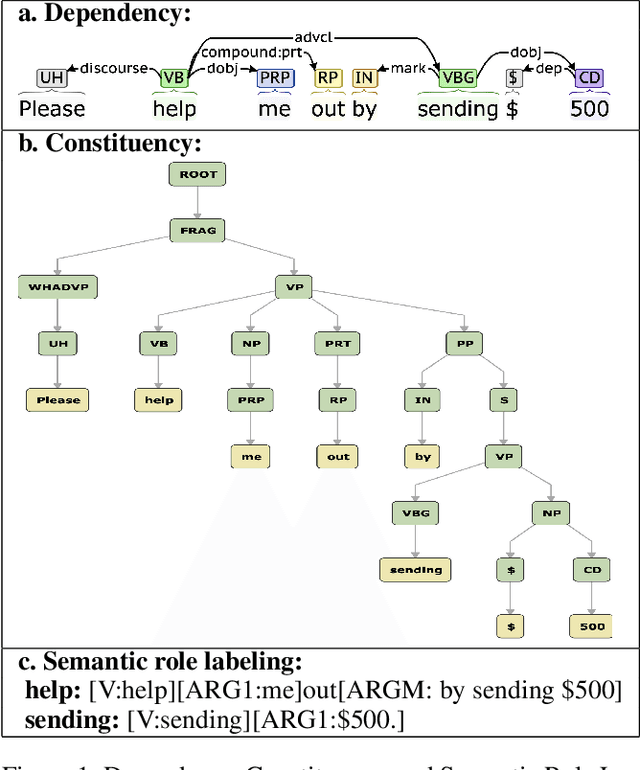
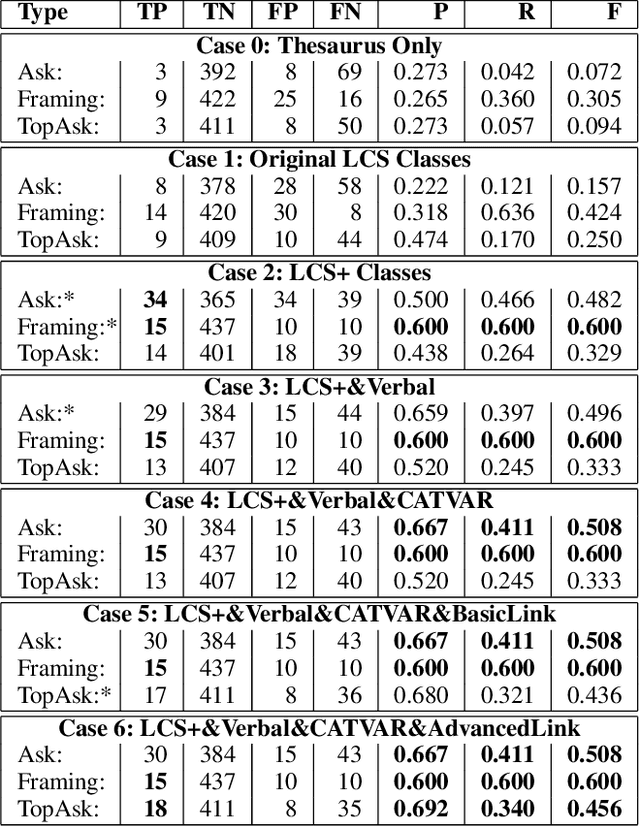
Social engineers attempt to manipulate users into undertaking actions such as downloading malware by clicking links or providing access to money or sensitive information. Natural language processing, computational sociolinguistics, and media-specific structural clues provide a means for detecting both the ask (e.g., buy gift card) and the risk/reward implied by the ask, which we call framing (e.g., lose your job, get a raise). We apply linguistic resources such as Lexical Conceptual Structure to tackle ask detection and also leverage structural clues such as links and their proximity to identified asks to improve confidence in our results. Our experiments indicate that the performance of ask detection, framing detection, and identification of the top ask is improved by linguistically motivated classes coupled with structural clues such as links. Our approach is implemented in a system that informs users about social engineering risk situations.