 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-Efficient Detection Transformers
Mar 21, 2022
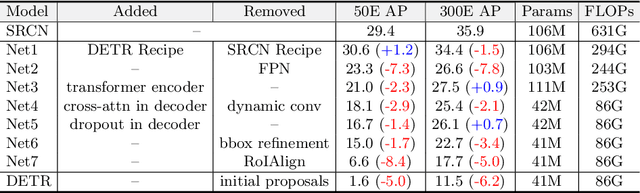
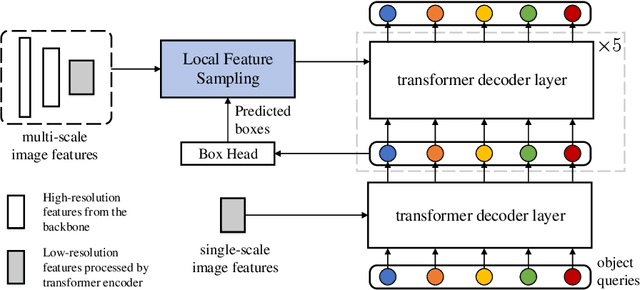
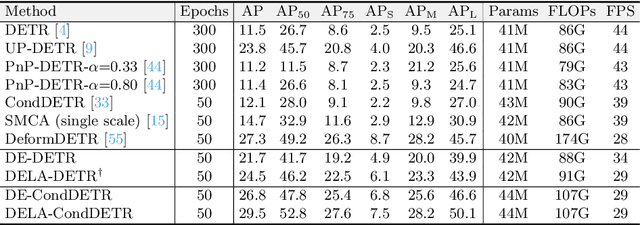
Detection Transformers have achieved competitive performance on the sample-rich COCO dataset. However, we show most of them suffer from significant performance drops on small-size datasets, like Cityscapes. In other words, the detection transformers are generally data-hungry. To tackle this problem, we empirically analyze the factors that affect data efficiency, through a step-by-step transition from a data-efficient RCNN variant to the representative DETR. The empirical results suggest that sparse feature sampling from local image areas holds the key. Based on this observation, we alleviate the data-hungry issue of existing detection transformers by simply alternating how key and value sequences are constructed in the cross-attention layer, with minimum modifications to the original models. Besides, we introduce a simple yet effective label augmentation method to provide richer supervision and improve data efficiency. Experiments show that our method can be readily applied to different detection transformers and improve their performance on both small-size and sample-rich datasets. Code will be made publicly available at \url{https://github.com/encounter1997/DE-DETRs}.
Learning Affordance Grounding from Exocentric Images
Mar 18, 2022
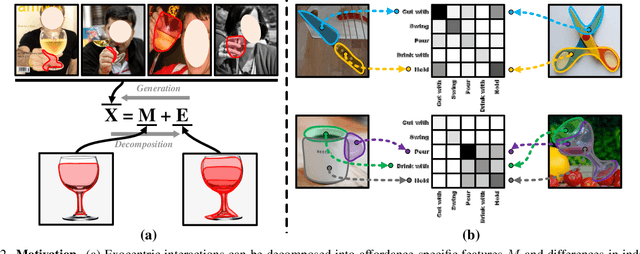
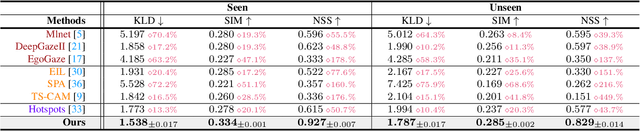
Affordance grounding, a task to ground (i.e., localize) action possibility region in objects, which faces the challenge of establishing an explicit link with object parts due to the diversity of interactive affordance. Human has the ability that transform the various exocentric interactions to invariant egocentric affordance so as to counter the impact of interactive diversity. To empower an agent with such ability, this paper proposes a task of affordance grounding from exocentric view, i.e., given exocentric human-object interaction and egocentric object images, learning the affordance knowledge of the object and transferring it to the egocentric image using only the affordance label as supervision. To this end, we devise a cross-view knowledge transfer framework that extracts affordance-specific features from exocentric interactions and enhances the perception of affordance regions by preserving affordance correlation. Specifically, an Affordance Invariance Mining module is devised to extract specific clues by minimizing the intra-class differences originated from interaction habits in exocentric images. Besides, an Affordance Co-relation Preserving strategy is presented to perceive and localize affordance by aligning the co-relation matrix of predicted results between the two views. Particularly, an affordance grounding dataset named AGD20K is constructed by collecting and labeling over 20K images from 36 affordance categories. Experimental results demonstrate that our method outperforms the representative models in terms of objective metrics and visual quality. Code: github.com/lhc1224/Cross-View-AG.
Gaussian initializations help deep variational quantum circuits escape from the barren plateau
Mar 17, 2022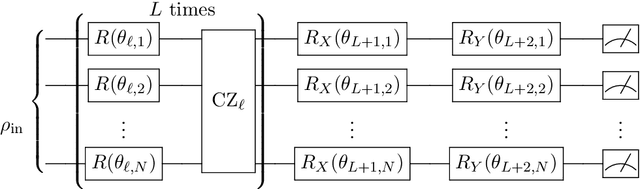
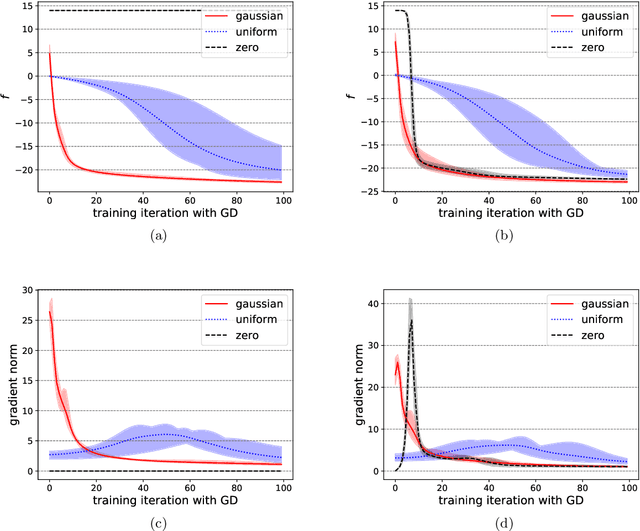
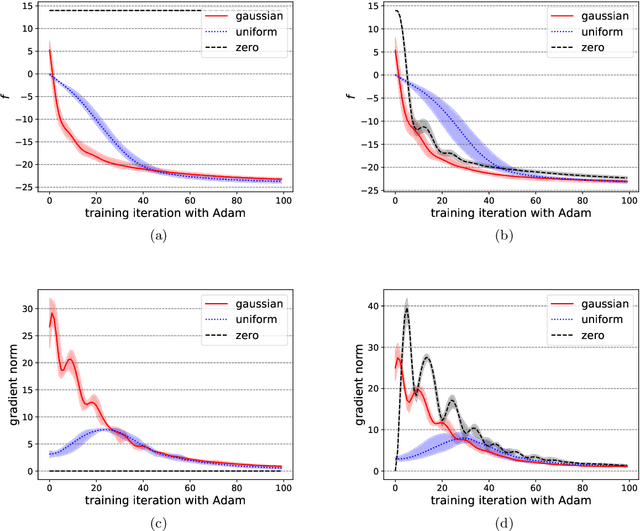
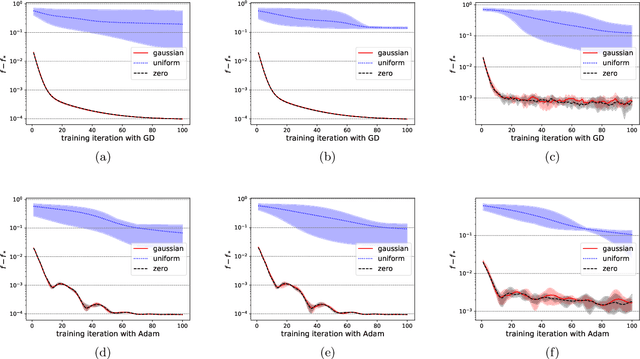
Variational quantum circuits have been widely employed in quantum simulation and quantum machine learning in recent years. However, quantum circuits with random structures have poor trainability due to the exponentially vanishing gradient with respect to the circuit depth and the qubit number. This result leads to a general belief that deep quantum circuits will not be feasible for practical tasks. In this work, we propose an initialization strategy with theoretical guarantees for the vanishing gradient problem in general deep circuits. Specifically, we prove that under proper Gaussian initialized parameters, the norm of the gradient decays at most polynomially when the qubit number and the circuit depth increase. Our theoretical results hold for both the local and the global observable cases, where the latter was believed to have vanishing gradients even for shallow circuits. Experimental results verify our theoretical findings in the quantum simulation and quantum chemistry.
Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning
Mar 17, 2022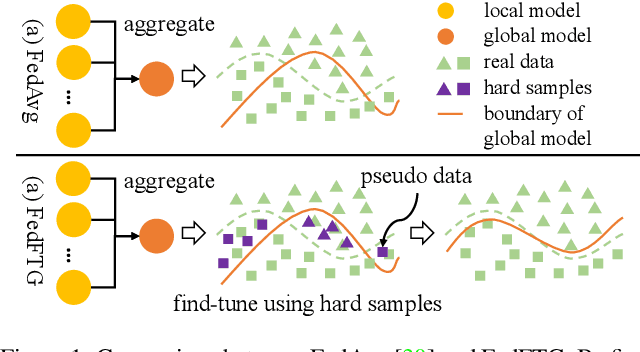
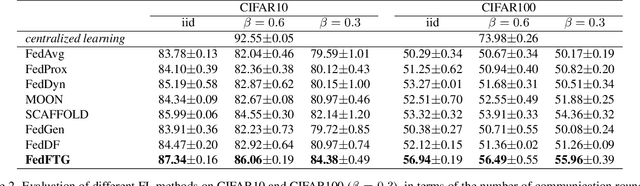
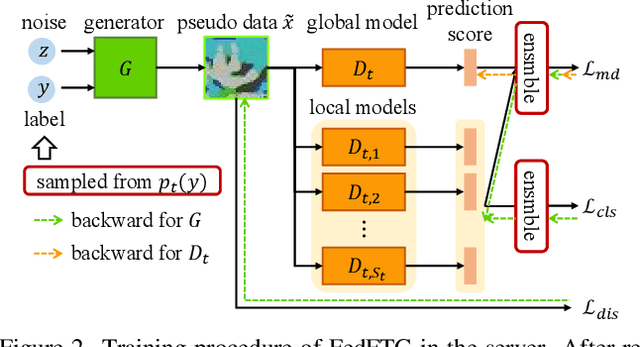
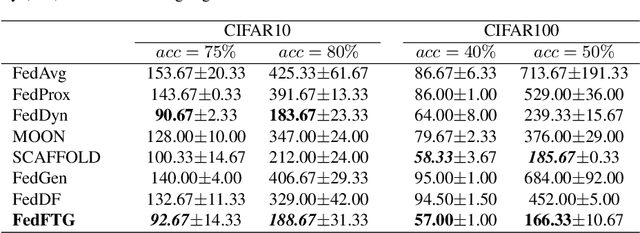
Federated Learning (FL) is an emerging distributed learning paradigm under privacy constraint. Data heterogeneity is one of the main challenges in FL, which results in slow convergence and degraded performance. Most existing approaches only tackle the heterogeneity challenge by restricting the local model update in client, ignoring the performance drop caused by direct global model aggregation. Instead, we propose a data-free knowledge distillation method to fine-tune the global model in the server (FedFTG), which relieves the issue of direct model aggregation. Concretely, FedFTG explores the input space of local models through a generator, and uses it to transfer the knowledge from local models to the global model. Besides, we propose a hard sample mining scheme to achieve effective knowledge distillation throughout the training. In addition, we develop customized label sampling and class-level ensemble to derive maximum utilization of knowledge, which implicitly mitigates the distribution discrepancy across clients. Extensive experiments show that our FedFTG significantly outperforms the state-of-the-art (SOTA) FL algorithms and can serve as a strong plugin for enhancing FedAvg, FedProx, FedDyn, and SCAFFOLD.
Do We Really Need a Learnable Classifier at the End of Deep Neural Network?
Mar 17, 2022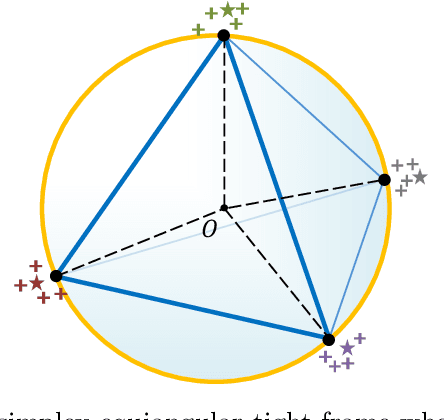

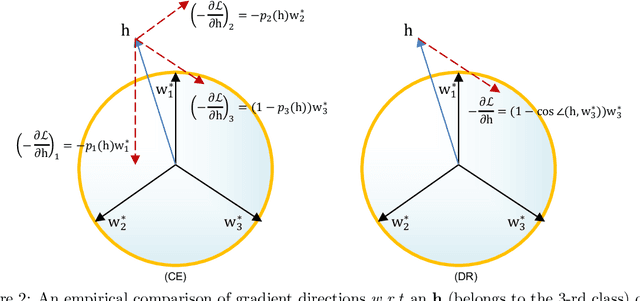
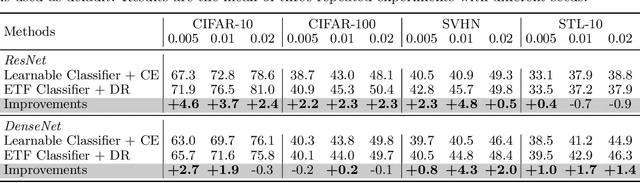
Modern deep neural networks for classification usually jointly learn a backbone for representation and a linear classifier to output the logit of each class. A recent study has shown a phenomenon called neural collapse that the within-class means of features and the classifier vectors converge to the vertices of a simplex equiangular tight frame (ETF) at the terminal phase of training on a balanced dataset. Since the ETF geometric structure maximally separates the pair-wise angles of all classes in the classifier, it is natural to raise the question, why do we spend an effort to learn a classifier when we know its optimal geometric structure? In this paper, we study the potential of learning a neural network for classification with the classifier randomly initialized as an ETF and fixed during training. Our analytical work based on the layer-peeled model indicates that the feature learning with a fixed ETF classifier naturally leads to the neural collapse state even when the dataset is imbalanced among classes. We further show that in this case the cross entropy (CE) loss is not necessary and can be replaced by a simple squared loss that shares the same global optimality but enjoys a more accurate gradient and better convergence property. Our experimental results show that our method is able to achieve similar performances on image classification for balanced datasets, and bring significant improvements in the long-tailed and fine-grained classification tasks.
Contrastive Boundary Learning for Point Cloud Segmentation
Mar 11, 2022
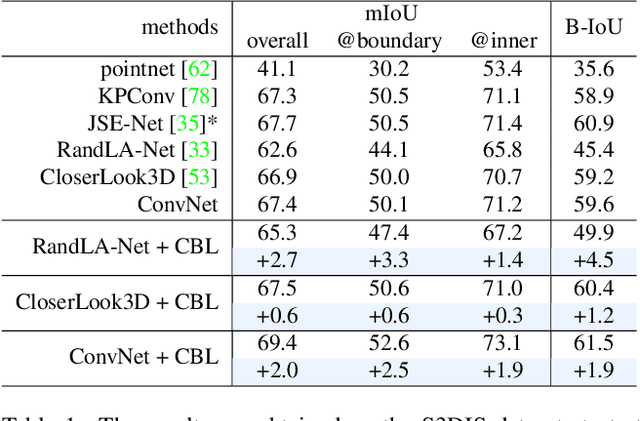

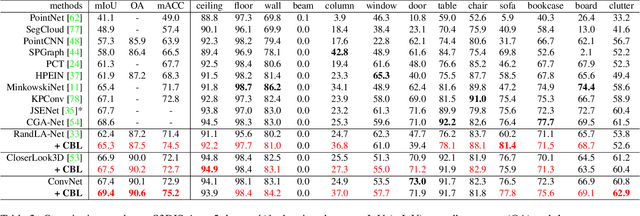
Point cloud segmentation is fundamental in understanding 3D environments. However, current 3D point cloud segmentation methods usually perform poorly on scene boundaries, which degenerates the overall segmentation performance. In this paper, we focus on the segmentation of scene boundaries. Accordingly, we first explore metrics to evaluate the segmentation performance on scene boundaries. To address the unsatisfactory performance on boundaries, we then propose a novel contrastive boundary learning (CBL) framework for point cloud segmentation. Specifically, the proposed CBL enhances feature discrimination between points across boundaries by contrasting their representations with the assistance of scene contexts at multiple scales. By applying CBL on three different baseline methods, we experimentally show that CBL consistently improves different baselines and assists them to achieve compelling performance on boundaries, as well as the overall performance, eg in mIoU. The experimental results demonstrate the effectiveness of our method and the importance of boundaries for 3D point cloud segmentation. Code and model will be made publicly available at https://github.com/LiyaoTang/contrastBoundary.
Information-Theoretic Odometry Learning
Mar 11, 2022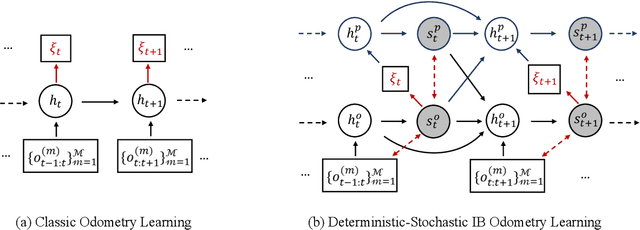
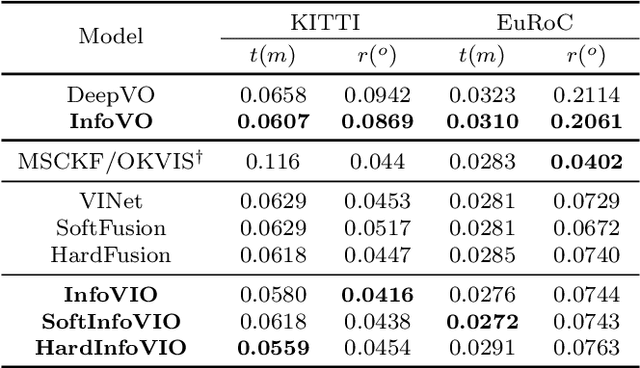
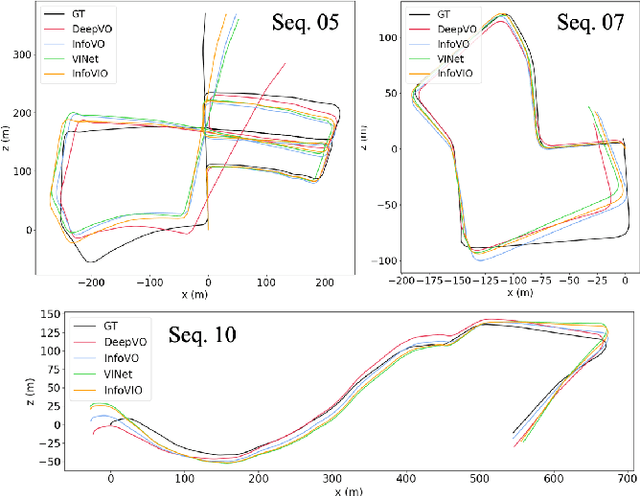
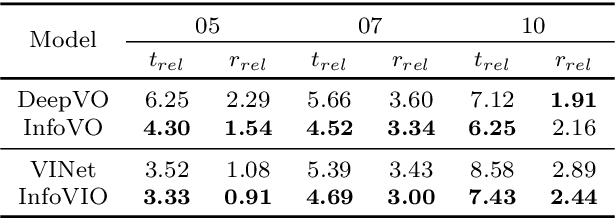
In this paper, we propose a unified information theoretic framework for learning-motivated methods aimed at odometry estimation, a crucial component of many robotics and vision tasks such as navigation and virtual reality where relative camera poses are required in real time. We formulate this problem as optimizing a variational information bottleneck objective function, which eliminates pose-irrelevant information from the latent representation. The proposed framework provides an elegant tool for performance evaluation and understanding in information-theoretic language. Specifically, we bound the generalization errors of the deep information bottleneck framework and the predictability of the latent representation. These provide not only a performance guarantee but also practical guidance for model design, sample collection, and sensor selection. Furthermore, the stochastic latent representation provides a natural uncertainty measure without the needs for extra structures or computations. Experiments on two well-known odometry datasets demonstrate the effectiveness of our method.
Towards Scale Consistent Monocular Visual Odometry by Learning from the Virtual World
Mar 11, 2022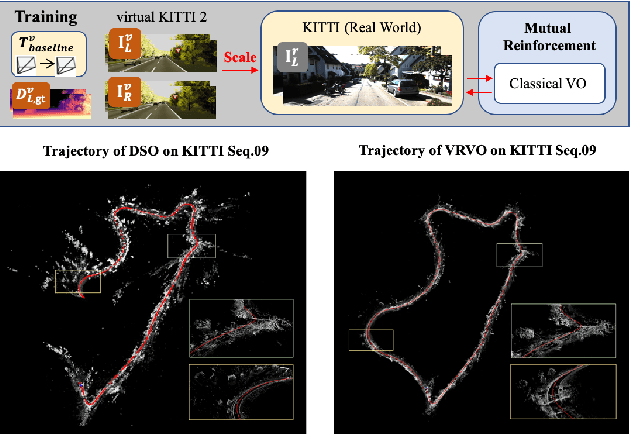
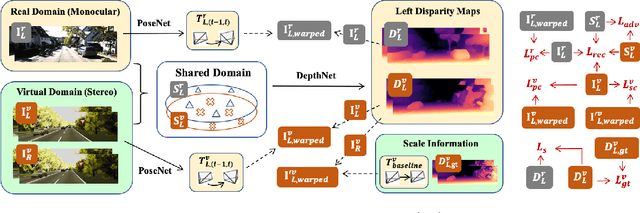
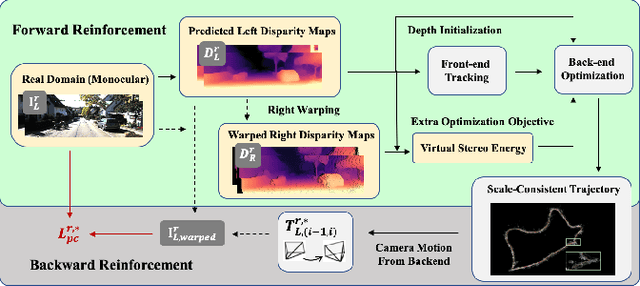
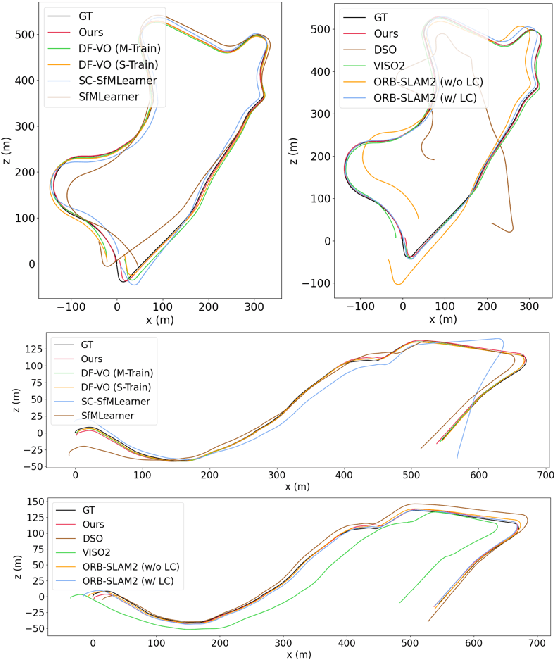
Monocular visual odometry (VO) has attracted extensive research attention by providing real-time vehicle motion from cost-effective camera images. However, state-of-the-art optimization-based monocular VO methods suffer from the scale inconsistency problem for long-term predictions. Deep learning has recently been introduced to address this issue by leveraging stereo sequences or ground-truth motions in the training dataset. However, it comes at an additional cost for data collection, and such training data may not be available in all datasets. In this work, we propose VRVO, a novel framework for retrieving the absolute scale from virtual data that can be easily obtained from modern simulation environments, whereas in the real domain no stereo or ground-truth data are required in either the training or inference phases. Specifically, we first train a scale-aware disparity network using both monocular real images and stereo virtual data. The virtual-to-real domain gap is bridged by using an adversarial training strategy to map images from both domains into a shared feature space. The resulting scale-consistent disparities are then integrated with a direct VO system by constructing a virtual stereo objective that ensures the scale consistency over long trajectories. Additionally, to address the suboptimality issue caused by the separate optimization backend and the learning process, we further propose a mutual reinforcement pipeline that allows bidirectional information flow between learning and optimization, which boosts the robustness and accuracy of each other. We demonstrate the effectiveness of our framework on the KITTI and vKITTI2 datasets.
ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
Mar 08, 2022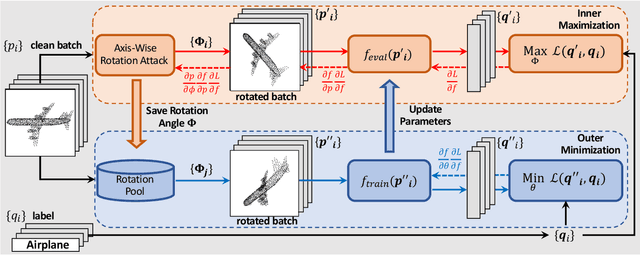
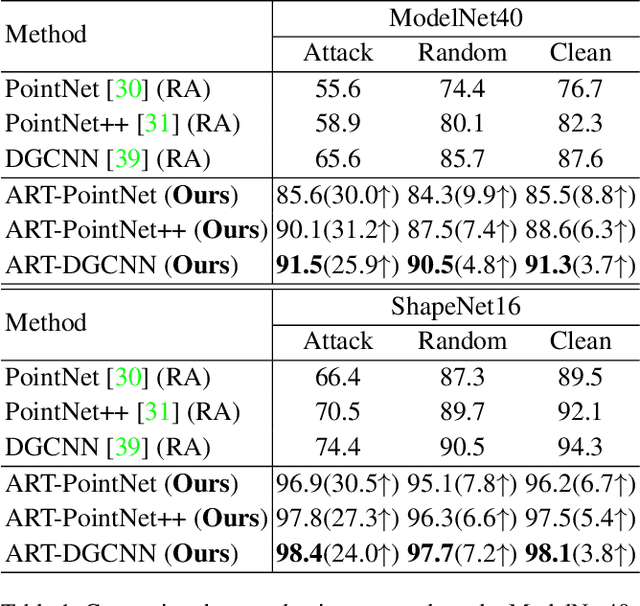
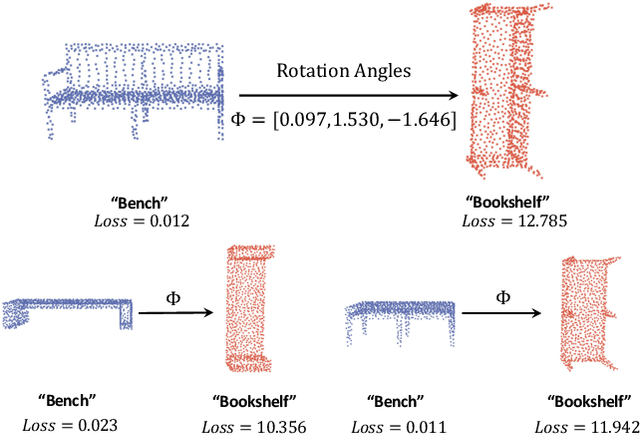
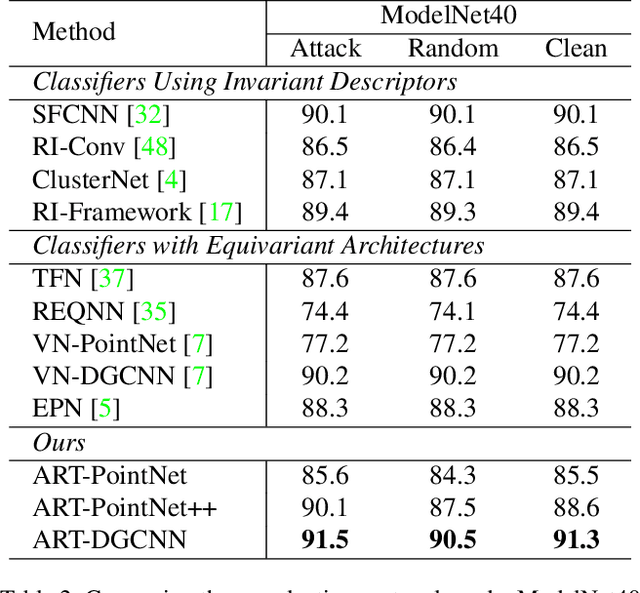
Point cloud classifiers with rotation robustness have been widely discussed in the 3D deep learning community. Most proposed methods either use rotation invariant descriptors as inputs or try to design rotation equivariant networks. However, robust models generated by these methods have limited performance under clean aligned datasets due to modifications on the original classifiers or input space. In this study, for the first time, we show that the rotation robustness of point cloud classifiers can also be acquired via adversarial training with better performance on both rotated and clean datasets. Specifically, our proposed framework named ART-Point regards the rotation of the point cloud as an attack and improves rotation robustness by training the classifier on inputs with Adversarial RoTations. We contribute an axis-wise rotation attack that uses back-propagated gradients of the pre-trained model to effectively find the adversarial rotations. To avoid model over-fitting on adversarial inputs, we construct rotation pools that leverage the transferability of adversarial rotations among samples to increase the diversity of training data. Moreover, we propose a fast one-step optimization to efficiently reach the final robust model. Experiments show that our proposed rotation attack achieves a high success rate and ART-Point can be used on most existing classifiers to improve the rotation robustness while showing better performance on clean datasets than state-of-the-art methods.
Where Does the Performance Improvement Come From? - A Reproducibility Concern about Image-Text Retrieval
Mar 08, 2022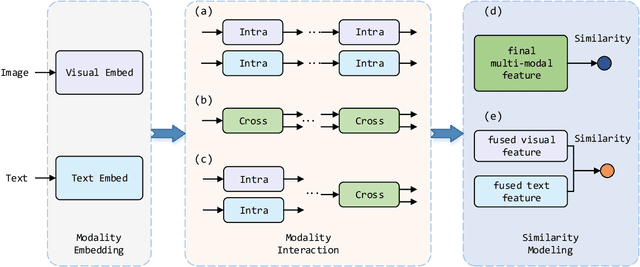
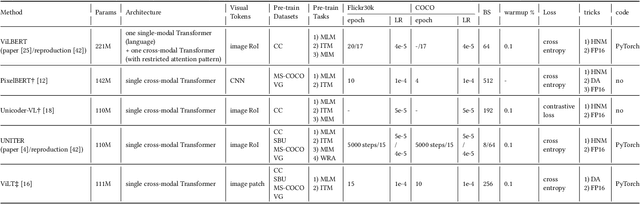
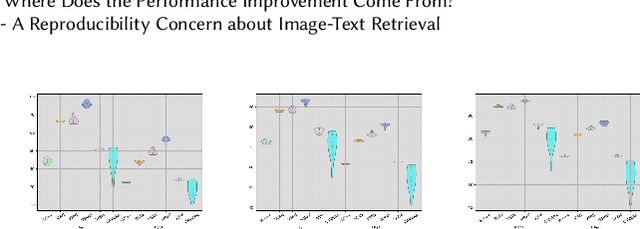
This paper seeks to provide the information retrieval community with some reflections on the current improvements of retrieval learning through the analysis of the reproducibility aspects of image-text retrieval models. For the latter part of the past decade, image-text retrieval has gradually become a major research direction in the field of information retrieval because of the growth of multi-modal data. Many researchers use benchmark datasets like MS-COCO and Flickr30k to train and assess the performance of image-text retrieval algorithms. Research in the past has mostly focused on performance, with several state-of-the-art methods being proposed in various ways. According to their claims, these approaches achieve better modal interactions and thus better multimodal representations with greater precision. In contrast to those previous works, we focus on the repeatability of the approaches and the overall examination of the elements that lead to improved performance by pretrained and nonpretrained models in retrieving images and text. To be more specific, we first examine the related reproducibility concerns and why the focus is on image-text retrieval tasks, and then we systematically summarize the current paradigm of image-text retrieval models and the stated contributions of those approaches. Second, we analyze various aspects of the reproduction of pretrained and nonpretrained retrieval models. Based on this, we conducted ablation experiments and obtained some influencing factors that affect retrieval recall more than the improvement claimed in the original paper. Finally, we also present some reflections and issues that should be considered by the retrieval community in the future. Our code is freely available at https://github.com/WangFei-2019/Image-text-Retrieval.