 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFT-Transformer: Resilient and Reliable Transformer with End-to-End Fault Tolerant Attention
Apr 03, 2025Transformer models leverage self-attention mechanisms to capture complex dependencies, demonstrating exceptional performance in various applications. However, the long-duration high-load computations required for model inference impose stringent reliability demands on the computing platform, as soft errors that occur during execution can significantly degrade model performance. Existing fault tolerance methods protect each operation separately using decoupled kernels, incurring substantial computational and memory overhead. In this paper, we propose a novel error-resilient framework for Transformer models, integrating end-to-end fault tolerant attention (EFTA) to improve inference reliability against soft errors. Our approach enables error detection and correction within a fully fused attention kernel, reducing redundant data access and thereby mitigating memory faults. To further enhance error coverage and reduce overhead, we design a hybrid fault tolerance scheme tailored for the EFTA, introducing for the first time: 1) architecture-aware algorithm-based fault tolerance (ABFT) using tensor checksum, which minimizes inter-thread communication overhead on tensor cores during error detection; 2) selective neuron value restriction, which selectively applies adaptive fault tolerance constraints to neuron values, balancing error coverage and overhead; 3) unified verification, reusing checksums to streamline multiple computation steps into a single verification process. Experimental results show that EFTA achieves up to 7.56x speedup over traditional methods with an average fault tolerance overhead of 13.9%.
Towards Automated Cross-domain Exploratory Data Analysis through Large Language Models
Dec 10, 2024



Exploratory data analysis (EDA), coupled with SQL, is essential for data analysts involved in data exploration and analysis. However, data analysts often encounter two primary challenges: (1) the need to craft SQL queries skillfully, and (2) the requirement to generate suitable visualization types that enhance the interpretation of query results. Due to its significance, substantial research efforts have been made to explore different approaches to address these challenges, including leveraging large language models (LLMs). However, existing methods fail to meet real-world data exploration requirements primarily due to (1) complex database schema; (2) unclear user intent; (3) limited cross-domain generalization capability; and (4) insufficient end-to-end text-to-visualization capability. This paper presents TiInsight, an automated SQL-based cross-domain exploratory data analysis system. First, we propose hierarchical data context (i.e., HDC), which leverages LLMs to summarize the contexts related to the database schema, which is crucial for open-world EDA systems to generalize across data domains. Second, the EDA system is divided into four components (i.e., stages): HDC generation, question clarification and decomposition, text-to-SQL generation (i.e., TiSQL), and data visualization (i.e., TiChart). Finally, we implemented an end-to-end EDA system with a user-friendly GUI interface in the production environment at PingCAP. We have also open-sourced all APIs of TiInsight to facilitate research within the EDA community. Through extensive evaluations by a real-world user study, we demonstrate that TiInsight offers remarkable performance compared to human experts. Specifically, TiSQL achieves an execution accuracy of 86.3% on the Spider dataset using GPT-4. It also demonstrates state-of-the-art performance on the Bird dataset.
Chip-Tuning: Classify Before Language Models Say
Oct 09, 2024



The rapid development in the performance of large language models (LLMs) is accompanied by the escalation of model size, leading to the increasing cost of model training and inference. Previous research has discovered that certain layers in LLMs exhibit redundancy, and removing these layers brings only marginal loss in model performance. In this paper, we adopt the probing technique to explain the layer redundancy in LLMs and demonstrate that language models can be effectively pruned with probing classifiers. We propose chip-tuning, a simple and effective structured pruning framework specialized for classification problems. Chip-tuning attaches tiny probing classifiers named chips to different layers of LLMs, and trains chips with the backbone model frozen. After selecting a chip for classification, all layers subsequent to the attached layer could be removed with marginal performance loss. Experimental results on various LLMs and datasets demonstrate that chip-tuning significantly outperforms previous state-of-the-art baselines in both accuracy and pruning ratio, achieving a pruning ratio of up to 50%. We also find that chip-tuning could be applied on multimodal models, and could be combined with model finetuning, proving its excellent compatibility.
FT K-Means: A High-Performance K-Means on GPU with Fault Tolerance
Aug 02, 2024



K-Means is a widely used algorithm in clustering, however, its efficiency is primarily constrained by the computational cost of distance computing. Existing implementations suffer from suboptimal utilization of computational units and lack resilience against soft errors. To address these challenges, we introduce FT K-Means, a high-performance GPU-accelerated implementation of K-Means with online fault tolerance. We first present a stepwise optimization strategy that achieves competitive performance compared to NVIDIA's cuML library. We further improve FT K-Means with a template-based code generation framework that supports different data types and adapts to different input shapes. A novel warp-level tensor-core error correction scheme is proposed to address the failure of existing fault tolerance methods due to memory asynchronization during copy operations. Our experimental evaluations on NVIDIA T4 GPU and A100 GPU demonstrate that FT K-Means without fault tolerance outperforms cuML's K-Means implementation, showing a performance increase of 10\%-300\% in scenarios involving irregular data shapes. Moreover, the fault tolerance feature of FT K-Means introduces only an overhead of 11\%, maintaining robust performance even with tens of errors injected per second.
GSDeformer: Direct Cage-based Deformation for 3D Gaussian Splatting
May 24, 2024



We present GSDeformer, a method that achieves free-form deformation on 3D Gaussian Splatting(3DGS) without requiring any architectural changes. Our method extends cage-based deformation, a traditional mesh deformation method, to 3DGS. This is done by converting 3DGS into a novel proxy point cloud representation, where its deformation can be used to infer the transformations to apply on the 3D gaussians making up 3DGS. We also propose an automatic cage construction algorithm for 3DGS to minimize manual work. Our method does not modify the underlying architecture of 3DGS. Therefore, any existing trained vanilla 3DGS can be easily edited by our method. We compare the deformation capability of our method against other existing methods, demonstrating the ease of use and comparable quality of our method, despite being more direct and thus easier to integrate with other concurrent developments on 3DGS.
Point'n Move: Interactive Scene Object Manipulation on Gaussian Splatting Radiance Fields
Nov 28, 2023



We propose Point'n Move, a method that achieves interactive scene object manipulation with exposed region inpainting. Interactivity here further comes from intuitive object selection and real-time editing. To achieve this, we adopt Gaussian Splatting Radiance Field as the scene representation and fully leverage its explicit nature and speed advantage. Its explicit representation formulation allows us to devise a 2D prompt points to 3D mask dual-stage self-prompting segmentation algorithm, perform mask refinement and merging, minimize change as well as provide good initialization for scene inpainting and perform editing in real-time without per-editing training, all leads to superior quality and performance. We test our method by performing editing on both forward-facing and 360 scenes. We also compare our method against existing scene object removal methods, showing superior quality despite being more capable and having a speed advantage.
Two-in-one Knowledge Distillation for Efficient Facial Forgery Detection
Feb 21, 2023



Facial forgery detection is a crucial but extremely challenging topic, with the fast development of forgery techniques making the synthetic artefact highly indistinguishable. Prior works show that by mining both spatial and frequency information the forgery detection performance of deep learning models can be vastly improved. However, leveraging multiple types of information usually requires more than one branch in the neural network, which makes the model heavy and cumbersome. Knowledge distillation, as an important technique for efficient modelling, could be a possible remedy. We find that existing knowledge distillation methods have difficulties distilling a dual-branch model into a single-branch model. More specifically, knowledge distillation on both the spatial and frequency branches has degraded performance than distillation only on the spatial branch. To handle such problem, we propose a novel two-in-one knowledge distillation framework which can smoothly merge the information from a large dual-branch network into a small single-branch network, with the help of different dedicated feature projectors and the gradient homogenization technique. Experimental analysis on two datasets, FaceForensics++ and Celeb-DF, shows that our proposed framework achieves superior performance for facial forgery detection with much fewer parameters.
Anti-Compression Contrastive Facial Forgery Detection
Feb 13, 2023



Forgery facial images and videos have increased the concern of digital security. It leads to the significant development of detecting forgery data recently. However, the data, especially the videos published on the Internet, are usually compressed with lossy compression algorithms such as H.264. The compressed data could significantly degrade the performance of recent detection algorithms. The existing anti-compression algorithms focus on enhancing the performance in detecting heavily compressed data but less consider the compression adaption to the data from various compression levels. We believe creating a forgery detection model that can handle the data compressed with unknown levels is important. To enhance the performance for such models, we consider the weak compressed and strong compressed data as two views of the original data and they should have similar representation and relationships with other samples. We propose a novel anti-compression forgery detection framework by maintaining closer relations within data under different compression levels. Specifically, the algorithm measures the pair-wise similarity within data as the relations, and forcing the relations of weak and strong compressed data close to each other, thus improving the discriminate power for detecting strong compressed data. To achieve a better strong compressed data relation guided by the less compressed one, we apply video level contrastive learning for weak compressed data, which forces the model to produce similar representations within the same video and far from the negative samples. The experiment results show that the proposed algorithm could boost performance for strong compressed data while improving the accuracy rate when detecting the clean data.
DeepFake MNIST+: A DeepFake Facial Animation Dataset
Aug 18, 2021
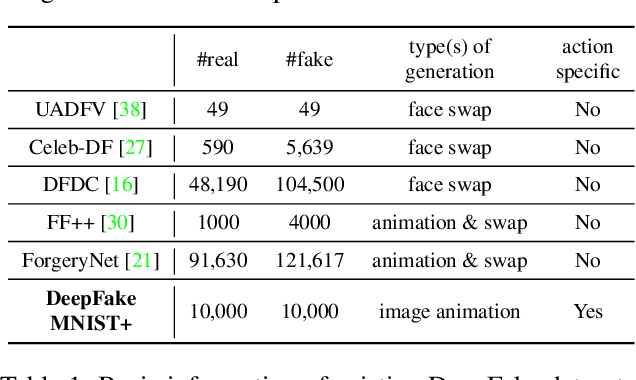
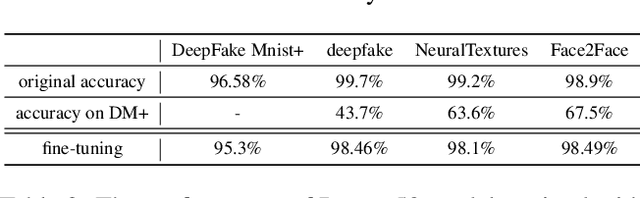
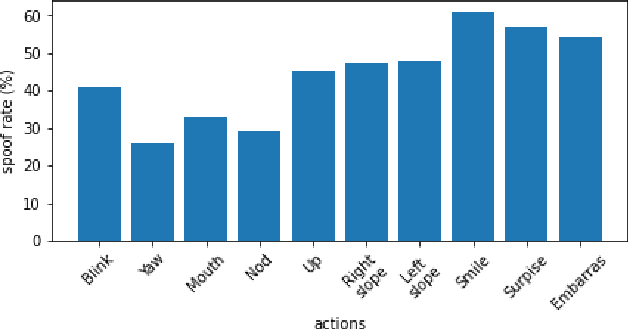
The DeepFakes, which are the facial manipulation techniques, is the emerging threat to digital society. Various DeepFake detection methods and datasets are proposed for detecting such data, especially for face-swapping. However, recent researches less consider facial animation, which is also important in the DeepFake attack side. It tries to animate a face image with actions provided by a driving video, which also leads to a concern about the security of recent payment systems that reply on liveness detection to authenticate real users via recognising a sequence of user facial actions. However, our experiments show that the existed datasets are not sufficient to develop reliable detection methods. While the current liveness detector cannot defend such videos as the attack. As a response, we propose a new human face animation dataset, called DeepFake MNIST+, generated by a SOTA image animation generator. It includes 10,000 facial animation videos in ten different actions, which can spoof the recent liveness detectors. A baseline detection method and a comprehensive analysis of the method is also included in this paper. In addition, we analyze the proposed dataset's properties and reveal the difficulty and importance of detecting animation datasets under different types of motion and compression quality.
On Positive-Unlabeled Classification in GAN
Feb 04, 2020

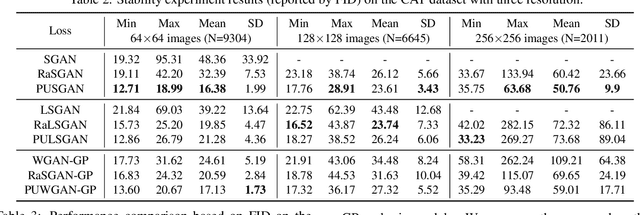
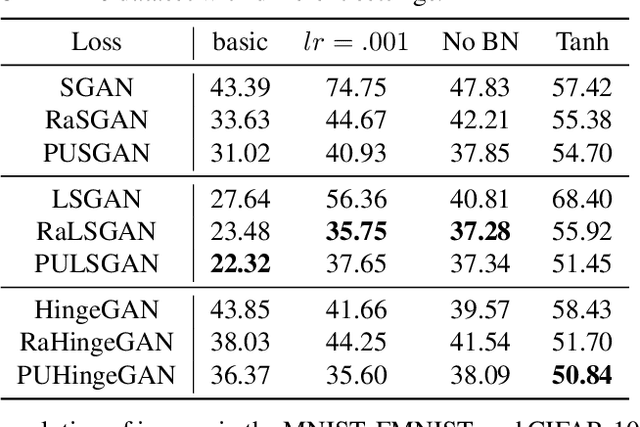
This paper defines a positive and unlabeled classification problem for standard GANs, which then leads to a novel technique to stabilize the training of the discriminator in GANs. Traditionally, real data are taken as positive while generated data are negative. This positive-negative classification criterion was kept fixed all through the learning process of the discriminator without considering the gradually improved quality of generated data, even if they could be more realistic than real data at times. In contrast, it is more reasonable to treat the generated data as unlabeled, which could be positive or negative according to their quality. The discriminator is thus a classifier for this positive and unlabeled classification problem, and we derive a new Positive-Unlabeled GAN (PUGAN). We theoretically discuss the global optimality the proposed model will achieve and the equivalent optimization goal. Empirically, we find that PUGAN can achieve comparable or even better performance than those sophisticated discriminator stabilization methods.