 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Superordinate Abstraction for Robust Concept Learning
May 28, 2022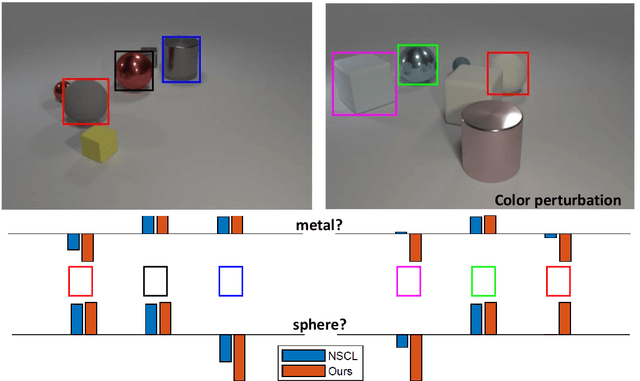

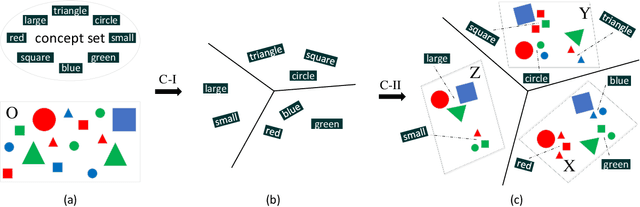
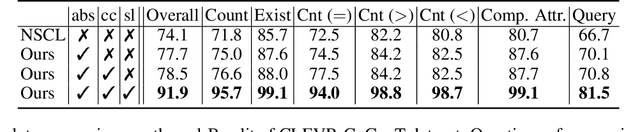
Concept learning constructs visual representations that are connected to linguistic semantics, which is fundamental to vision-language tasks. Although promising progress has been made, existing concept learners are still vulnerable to attribute perturbations and out-of-distribution compositions during inference. We ascribe the bottleneck to a failure of exploring the intrinsic semantic hierarchy of visual concepts, e.g. \{red, blue,...\} $\in$ `color' subspace yet cube $\in$ `shape'. In this paper, we propose a visual superordinate abstraction framework for explicitly modeling semantic-aware visual subspaces (i.e. visual superordinates). With only natural visual question answering data, our model first acquires the semantic hierarchy from a linguistic view, and then explores mutually exclusive visual superordinates under the guidance of linguistic hierarchy. In addition, a quasi-center visual concept clustering and a superordinate shortcut learning schemes are proposed to enhance the discrimination and independence of concepts within each visual superordinate. Experiments demonstrate the superiority of the proposed framework under diverse settings, which increases the overall answering accuracy relatively by 7.5\% on reasoning with perturbations and 15.6\% on compositional generalization tests.
Penalized Proximal Policy Optimization for Safe Reinforcement Learning
May 24, 2022
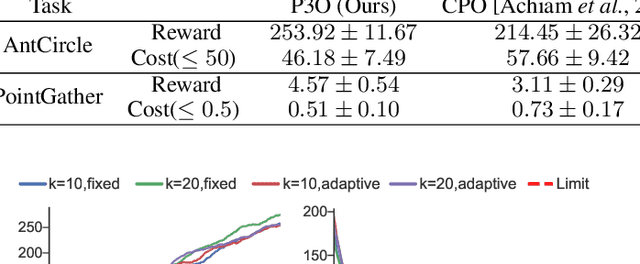
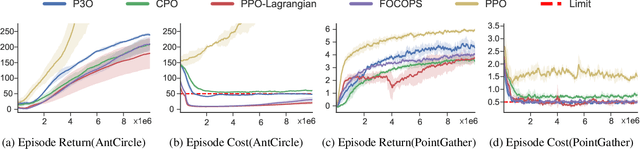
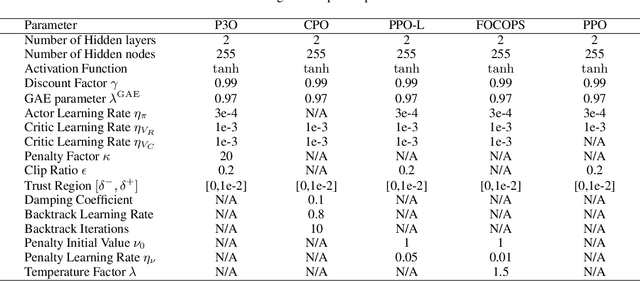
Safe reinforcement learning aims to learn the optimal policy while satisfying safety constraints, which is essential in real-world applications. However, current algorithms still struggle for efficient policy updates with hard constraint satisfaction. In this paper, we propose Penalized Proximal Policy Optimization (P3O), which solves the cumbersome constrained policy iteration via a single minimization of an equivalent unconstrained problem. Specifically, P3O utilizes a simple-yet-effective penalty function to eliminate cost constraints and removes the trust-region constraint by the clipped surrogate objective. We theoretically prove the exactness of the proposed method with a finite penalty factor and provide a worst-case analysis for approximate error when evaluated on sample trajectories. Moreover, we extend P3O to more challenging multi-constraint and multi-agent scenarios which are less studied in previous work. Extensive experiments show that P3O outperforms state-of-the-art algorithms with respect to both reward improvement and constraint satisfaction on a set of constrained locomotive tasks.
Mapping Emulation for Knowledge Distillation
May 21, 2022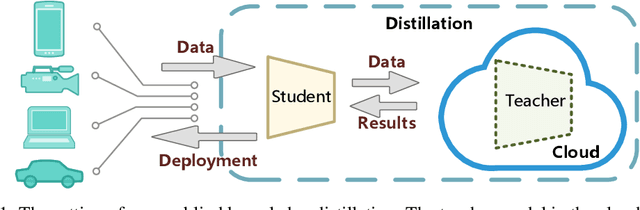
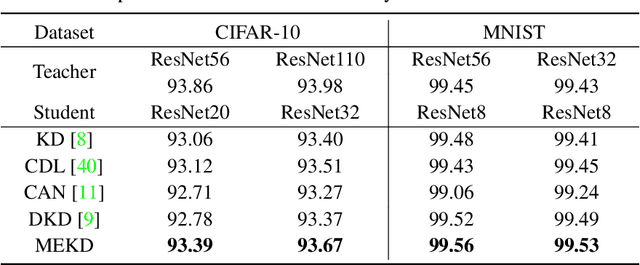
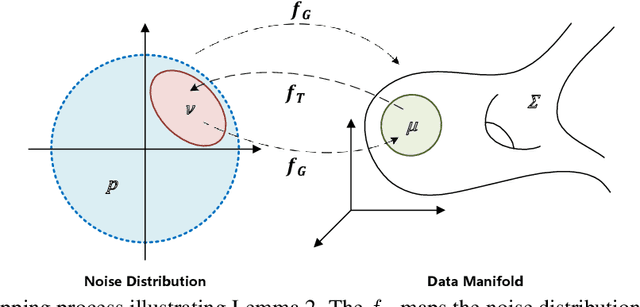
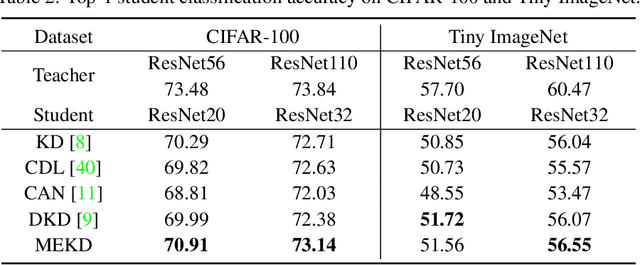
This paper formalizes the source-blind knowledge distillation problem that is essential to federated learning. A new geometric perspective is presented to view such a problem as aligning generated distributions between the teacher and student. With its guidance, a new architecture MEKD is proposed to emulate the inverse mapping through generative adversarial training. Unlike mimicking logits and aligning logit distributions, reconstructing the mapping from classifier-logits has a geometric intuition of decreasing empirical distances, and theoretical guarantees using the universal function approximation and optimal mass transportation theories. A new algorithm is also proposed to train the student model that reaches the teacher's performance source-blindly. On various benchmarks, MEKD outperforms existing source-blind KD methods, explainable with ablation studies and visualized results.
Beyond Greedy Search: Tracking by Multi-Agent Reinforcement Learning-based Beam Search
May 19, 2022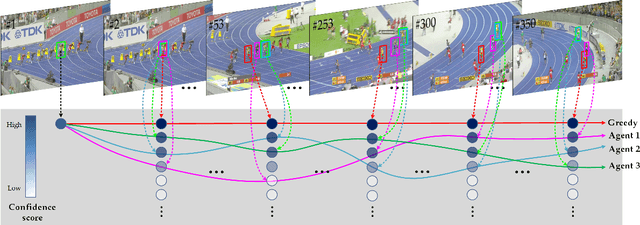
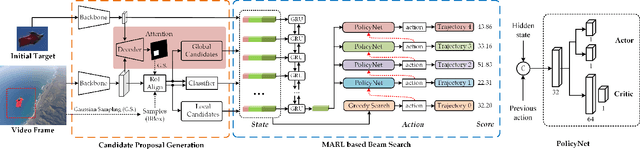
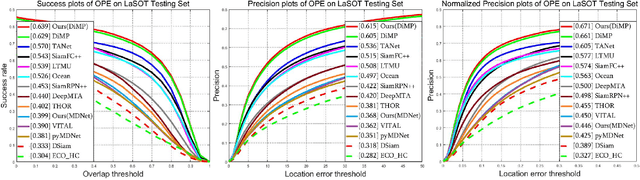
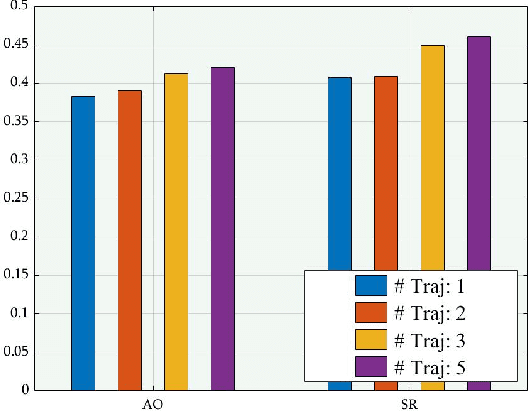
Existing trackers usually select a location or proposal with the maximum score as tracking result for each frame. However, such greedy search scheme maybe not the optimal choice, especially when encountering challenging tracking scenarios like heavy occlusions and fast motion. Since the accumulated errors would make response scores not reliable anymore. In this paper, we propose a novel multi-agent reinforcement learning based beam search strategy (termed BeamTracking) to address this issue. Specifically, we formulate the tracking as a sample selection problem fulfilled by multiple parallel decision-making processes, each of which aims at picking out one sample as their tracking result in each frame. We take the target feature, proposal feature, and its response score as state, and also consider actions predicted by nearby agent, to train multi-agents to select their actions. When all the frames are processed, we select the trajectory with the maximum accumulated score as the tracking result. Extensive experiments on seven popular tracking benchmark datasets validated the effectiveness of the proposed algorithm.
Revisiting PINNs: Generative Adversarial Physics-informed Neural Networks and Point-weighting Method
May 18, 2022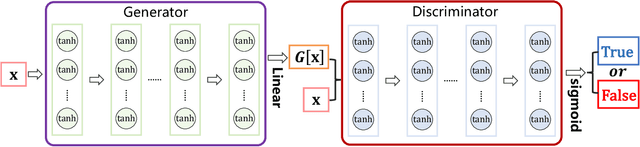
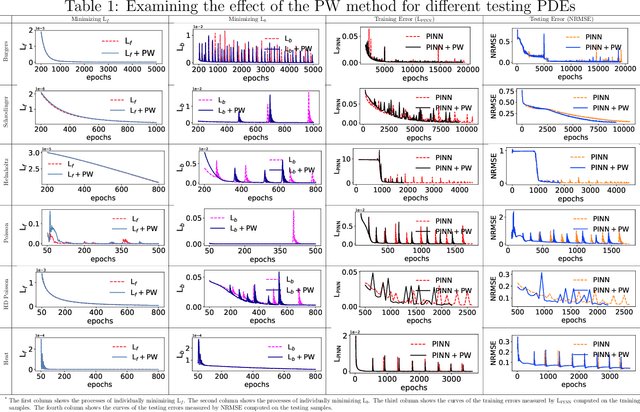

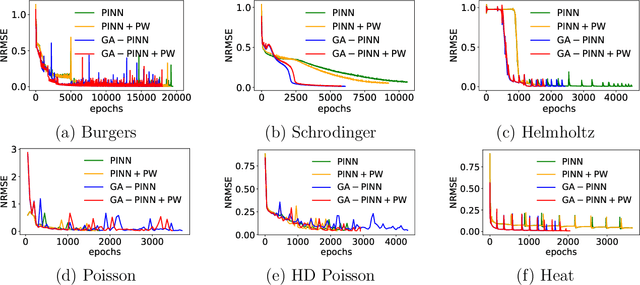
Physics-informed neural networks (PINNs) provide a deep learning framework for numerically solving partial differential equations (PDEs), and have been widely used in a variety of PDE problems. However, there still remain some challenges in the application of PINNs: 1) the mechanism of PINNs is unsuitable (at least cannot be directly applied) to exploiting a small size of (usually very few) extra informative samples to refine the networks; and 2) the efficiency of training PINNs often becomes low for some complicated PDEs. In this paper, we propose the generative adversarial physics-informed neural network (GA-PINN), which integrates the generative adversarial (GA) mechanism with the structure of PINNs, to improve the performance of PINNs by exploiting only a small size of exact solutions to the PDEs. Inspired from the weighting strategy of the Adaboost method, we then introduce a point-weighting (PW) method to improve the training efficiency of PINNs, where the weight of each sample point is adaptively updated at each training iteration. The numerical experiments show that GA-PINNs outperform PINNs in many well-known PDEs and the PW method also improves the efficiency of training PINNs and GA-PINNs.
Theory of Quantum Generative Learning Models with Maximum Mean Discrepancy
May 10, 2022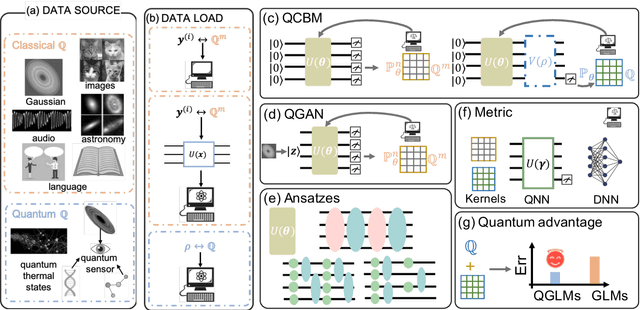
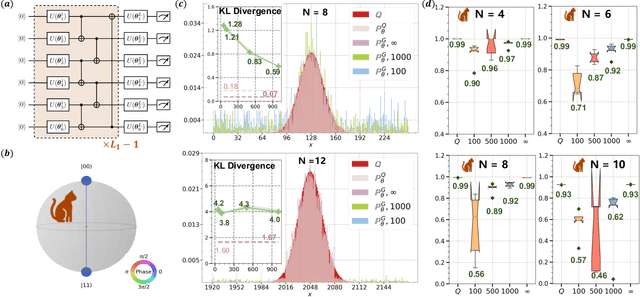
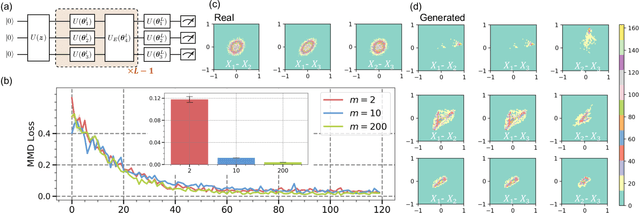
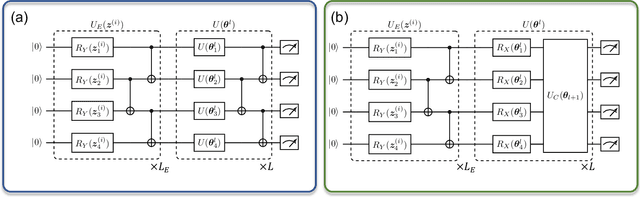
The intrinsic probabilistic nature of quantum mechanics invokes endeavors of designing quantum generative learning models (QGLMs) with computational advantages over classical ones. To date, two prototypical QGLMs are quantum circuit Born machines (QCBMs) and quantum generative adversarial networks (QGANs), which approximate the target distribution in explicit and implicit ways, respectively. Despite the empirical achievements, the fundamental theory of these models remains largely obscure. To narrow this knowledge gap, here we explore the learnability of QCBMs and QGANs from the perspective of generalization when their loss is specified to be the maximum mean discrepancy. Particularly, we first analyze the generalization ability of QCBMs and identify their superiorities when the quantum devices can directly access the target distribution and the quantum kernels are employed. Next, we prove how the generalization error bound of QGANs depends on the employed Ansatz, the number of qudits, and input states. This bound can be further employed to seek potential quantum advantages in Hamiltonian learning tasks. Numerical results of QGLMs in approximating quantum states, Gaussian distribution, and ground states of parameterized Hamiltonians accord with the theoretical analysis. Our work opens the avenue for quantitatively understanding the power of quantum generative learning models.
HL-Net: Heterophily Learning Network for Scene Graph Generation
May 04, 2022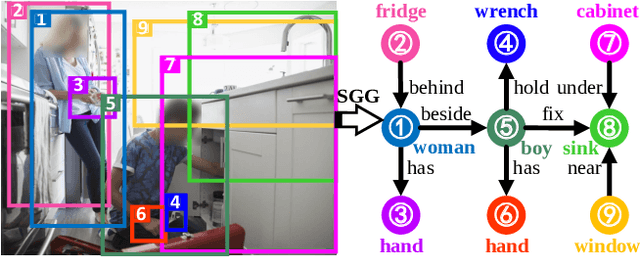
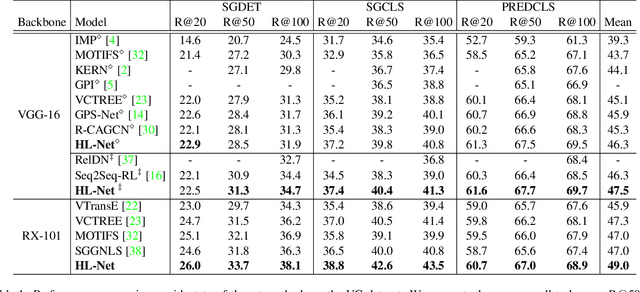
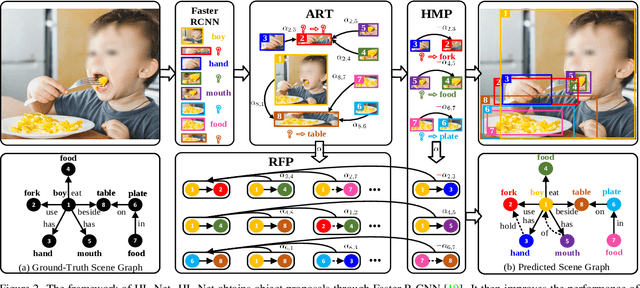
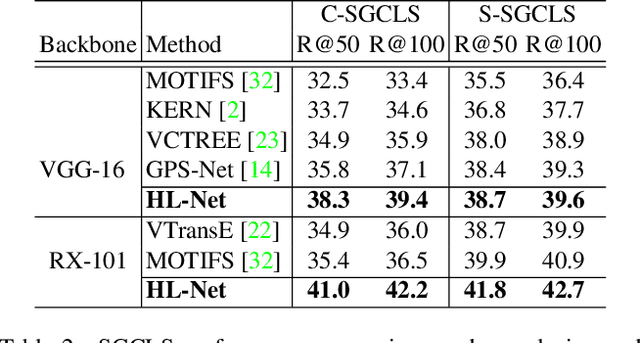
Scene graph generation (SGG) aims to detect objects and predict their pairwise relationships within an image. Current SGG methods typically utilize graph neural networks (GNNs) to acquire context information between objects/relationships. Despite their effectiveness, however, current SGG methods only assume scene graph homophily while ignoring heterophily. Accordingly, in this paper, we propose a novel Heterophily Learning Network (HL-Net) to comprehensively explore the homophily and heterophily between objects/relationships in scene graphs. More specifically, HL-Net comprises the following 1) an adaptive reweighting transformer module, which adaptively integrates the information from different layers to exploit both the heterophily and homophily in objects; 2) a relationship feature propagation module that efficiently explores the connections between relationships by considering heterophily in order to refine the relationship representation; 3) a heterophily-aware message-passing scheme to further distinguish the heterophily and homophily between objects/relationships, thereby facilitating improved message passing in graphs. We conducted extensive experiments on two public datasets: Visual Genome (VG) and Open Images (OI). The experimental results demonstrate the superiority of our proposed HL-Net over existing state-of-the-art approaches. In more detail, HL-Net outperforms the second-best competitors by 2.1$\%$ on the VG dataset for scene graph classification and 1.2$\%$ on the IO dataset for the final score. Code is available at https://github.com/siml3/HL-Net.
RU-Net: Regularized Unrolling Network for Scene Graph Generation
May 03, 2022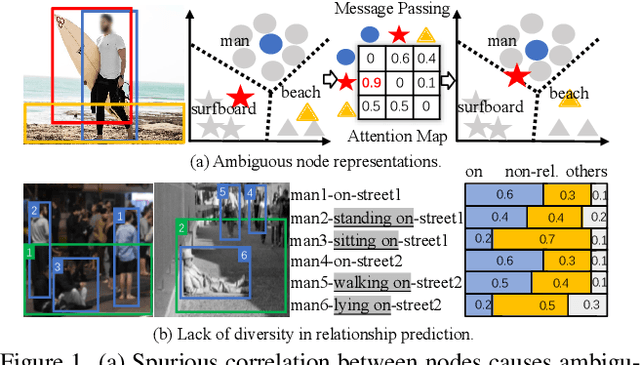
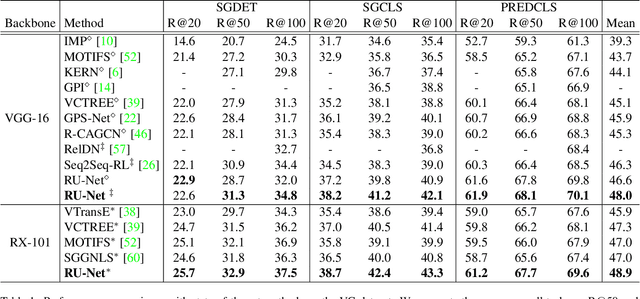
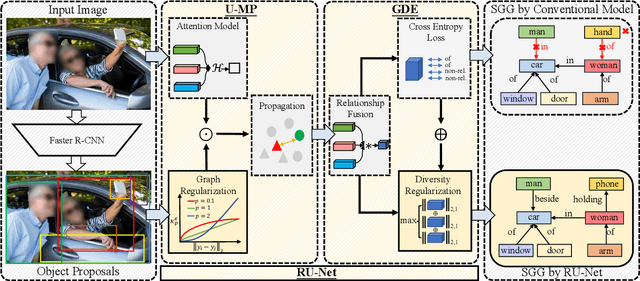
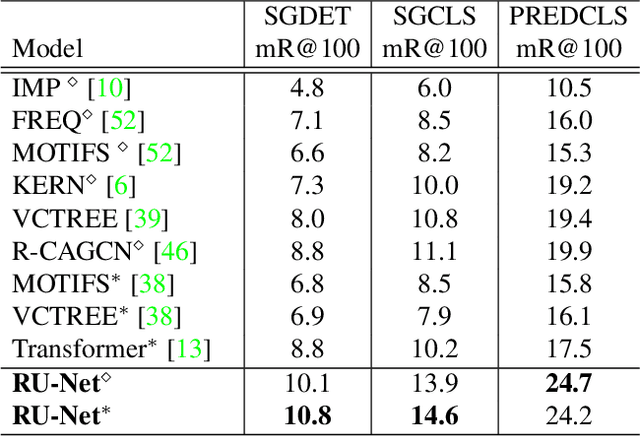
Scene graph generation (SGG) aims to detect objects and predict the relationships between each pair of objects. Existing SGG methods usually suffer from several issues, including 1) ambiguous object representations, as graph neural network-based message passing (GMP) modules are typically sensitive to spurious inter-node correlations, and 2) low diversity in relationship predictions due to severe class imbalance and a large number of missing annotations. To address both problems, in this paper, we propose a regularized unrolling network (RU-Net). We first study the relation between GMP and graph Laplacian denoising (GLD) from the perspective of the unrolling technique, determining that GMP can be formulated as a solver for GLD. Based on this observation, we propose an unrolled message passing module and introduce an $\ell_p$-based graph regularization to suppress spurious connections between nodes. Second, we propose a group diversity enhancement module that promotes the prediction diversity of relationships via rank maximization. Systematic experiments demonstrate that RU-Net is effective under a variety of settings and metrics. Furthermore, RU-Net achieves new state-of-the-arts on three popular databases: VG, VRD, and OI. Code is available at https://github.com/siml3/RU-Net.
DearKD: Data-Efficient Early Knowledge Distillation for Vision Transformers
Apr 28, 2022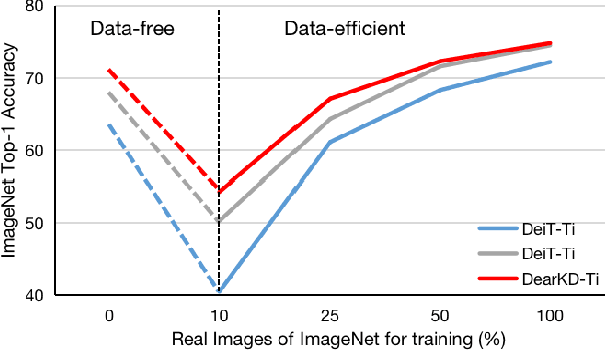
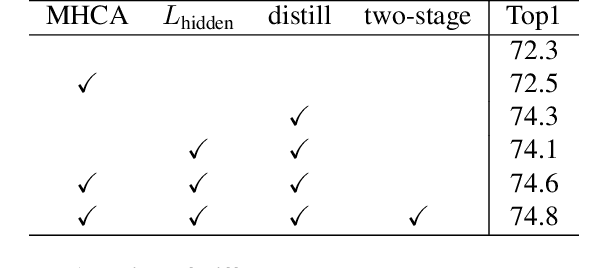
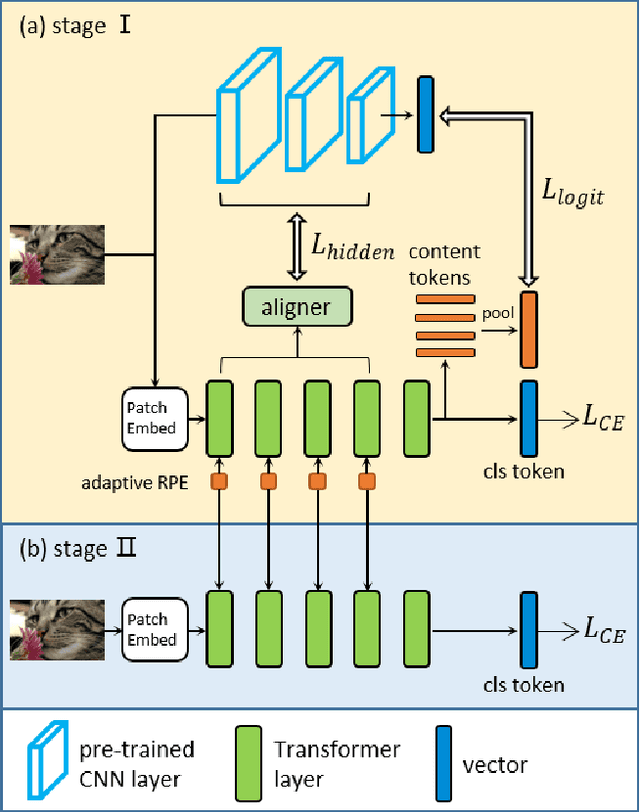
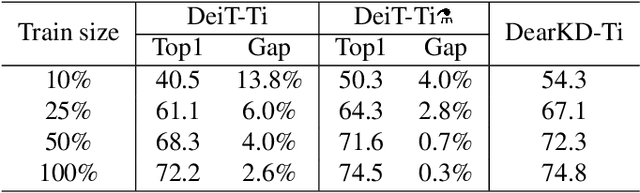
Transformers are successfully applied to computer vision due to their powerful modeling capacity with self-attention. However, the excellent performance of transformers heavily depends on enormous training images. Thus, a data-efficient transformer solution is urgently needed. In this work, we propose an early knowledge distillation framework, which is termed as DearKD, to improve the data efficiency required by transformers. Our DearKD is a two-stage framework that first distills the inductive biases from the early intermediate layers of a CNN and then gives the transformer full play by training without distillation. Further, our DearKD can be readily applied to the extreme data-free case where no real images are available. In this case, we propose a boundary-preserving intra-divergence loss based on DeepInversion to further close the performance gap against the full-data counterpart. Extensive experiments on ImageNet, partial ImageNet, data-free setting and other downstream tasks prove the superiority of DearKD over its baselines and state-of-the-art methods.
ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
Apr 26, 2022


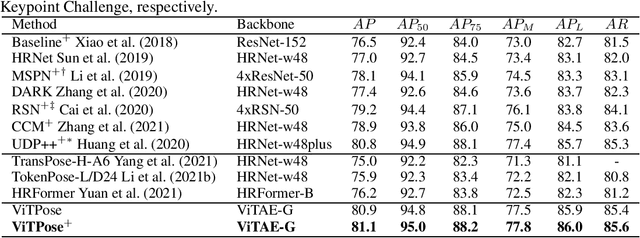
Recently, customized vision transformers have been adapted for human pose estimation and have achieved superior performance with elaborate structures. However, it is still unclear whether plain vision transformers can facilitate pose estimation. In this paper, we take the first step toward answering the question by employing a plain and non-hierarchical vision transformer together with simple deconvolution decoders termed ViTPose for human pose estimation. We demonstrate that a plain vision transformer with MAE pretraining can obtain superior performance after finetuning on human pose estimation datasets. ViTPose has good scalability with respect to model size and flexibility regarding input resolution and token number. Moreover, it can be easily pretrained using the unlabeled pose data without the need for large-scale upstream ImageNet data. Our biggest ViTPose model based on the ViTAE-G backbone with 1 billion parameters obtains the best 80.9 mAP on the MS COCO test-dev set, while the ensemble models further set a new state-of-the-art for human pose estimation, i.e., 81.1 mAP. The source code and models will be released at https://github.com/ViTAE-Transformer/ViTPose.