 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenefits of Permutation-Equivariance in Auction Mechanisms
Oct 11, 2022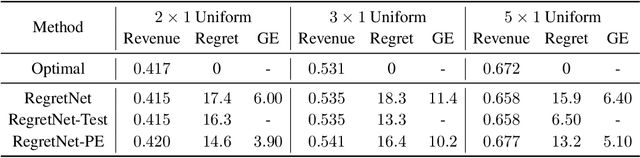
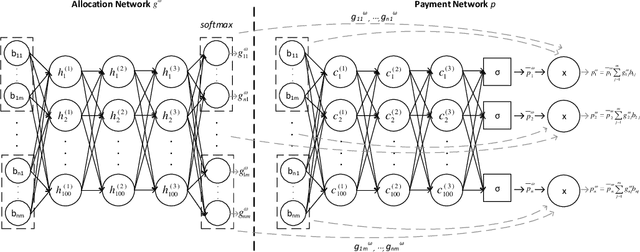
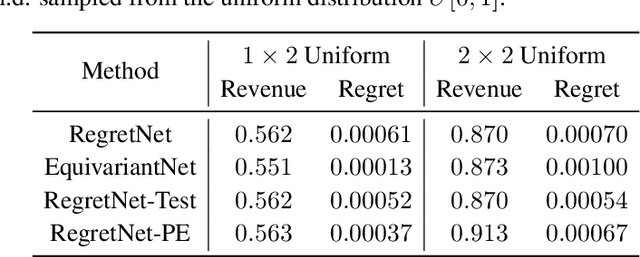
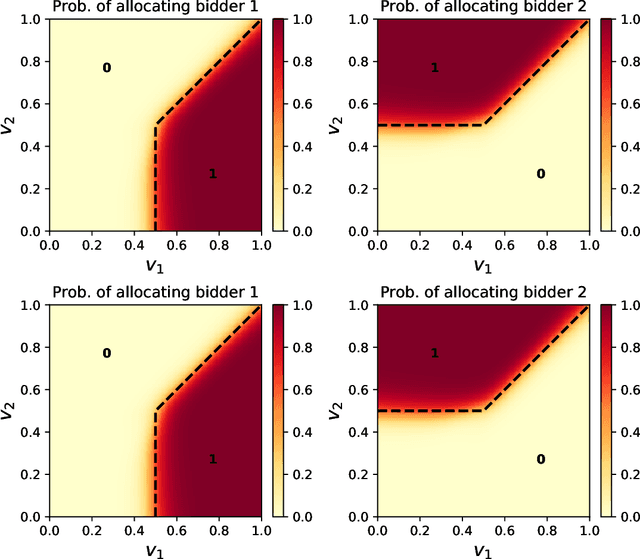
Designing an incentive-compatible auction mechanism that maximizes the auctioneer's revenue while minimizes the bidders' ex-post regret is an important yet intricate problem in economics. Remarkable progress has been achieved through learning the optimal auction mechanism by neural networks. In this paper, we consider the popular additive valuation and symmetric valuation setting; i.e., the valuation for a set of items is defined as the sum of all items' valuations in the set, and the valuation distribution is invariant when the bidders and/or the items are permutated. We prove that permutation-equivariant neural networks have significant advantages: the permutation-equivariance decreases the expected ex-post regret, improves the model generalizability, while maintains the expected revenue invariant. This implies that the permutation-equivariance helps approach the theoretically optimal dominant strategy incentive compatible condition, and reduces the required sample complexity for desired generalization. Extensive experiments fully support our theory. To our best knowledge, this is the first work towards understanding the benefits of permutation-equivariance in auction mechanisms.
Improving Sharpness-Aware Minimization with Fisher Mask for Better Generalization on Language Models
Oct 11, 2022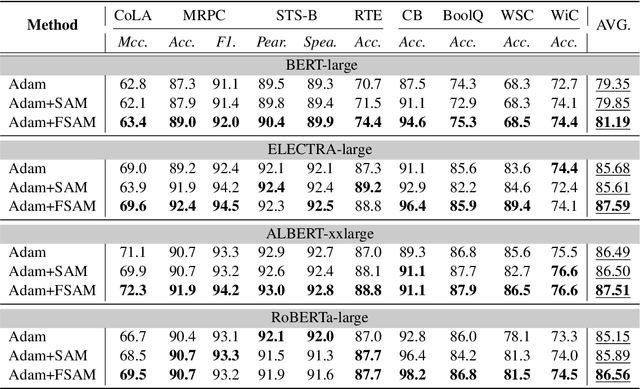
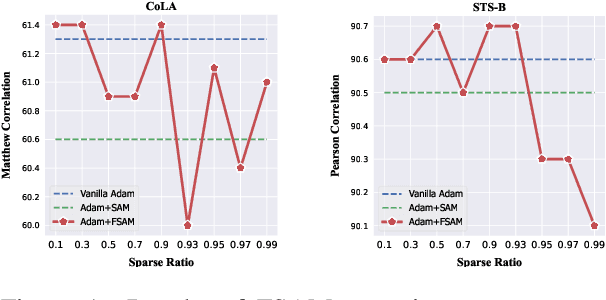
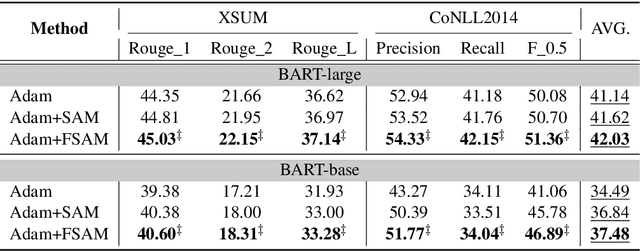
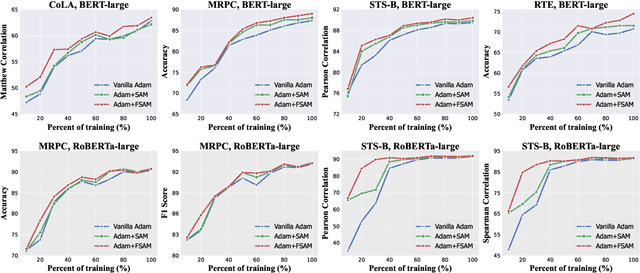
Fine-tuning large pretrained language models on a limited training corpus usually suffers from poor generalization. Prior works show that the recently-proposed sharpness-aware minimization (SAM) optimization method can improve the model generalization. However, SAM adds a perturbation to each model parameter equally (but not all parameters contribute equally to the optimization of training), which we argue is sub-optimal and will lead to excessive computation. In this paper, we propose a novel optimization procedure, namely FSAM, which introduces a Fisher mask to improve the efficiency and performance of SAM. In short, instead of adding perturbation to all parameters, FSAM uses the Fisher information to identity the important parameters and formulates a Fisher mask to obtain the sparse perturbation, i.e., making the optimizer focus on these important parameters. Experiments on various tasks in GLUE and SuperGLUE benchmarks show that FSAM consistently outperforms the vanilla SAM by 0.67~1.98 average score among four different pretrained models. We also empirically show that FSAM works well in other complex scenarios, e.g., fine-tuning on generation tasks or limited training data. Encouragingly, when training data is limited, FSAM improves the SAM by a large margin, i.e., up to 15.1.
SparseAdapter: An Easy Approach for Improving the Parameter-Efficiency of Adapters
Oct 11, 2022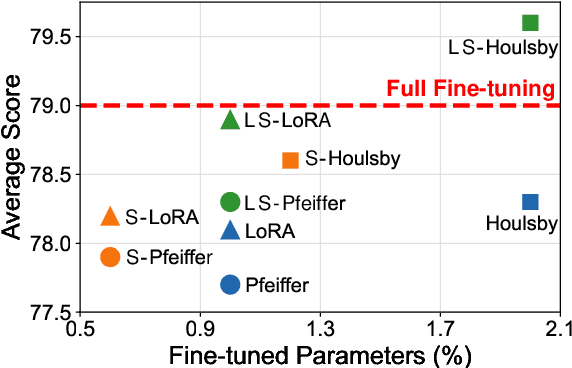
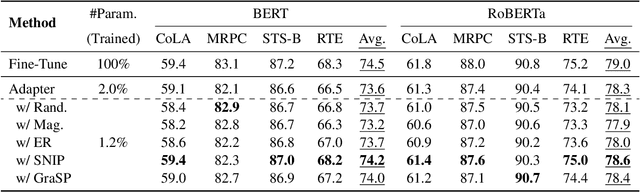
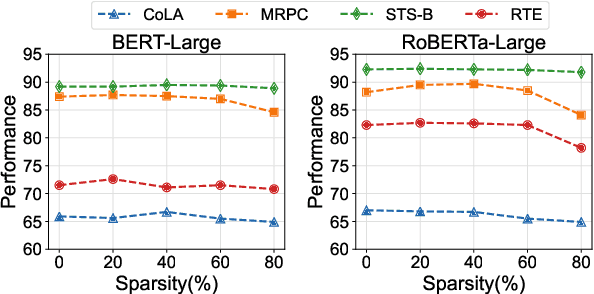
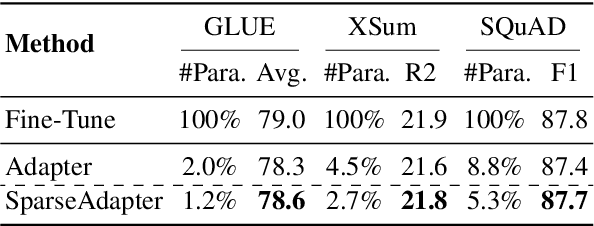
Adapter Tuning, which freezes the pretrained language models (PLMs) and only fine-tunes a few extra modules, becomes an appealing efficient alternative to the full model fine-tuning. Although computationally efficient, the recent Adapters often increase parameters (e.g. bottleneck dimension) for matching the performance of full model fine-tuning, which we argue goes against their original intention. In this work, we re-examine the parameter-efficiency of Adapters through the lens of network pruning (we name such plug-in concept as \texttt{SparseAdapter}) and find that SparseAdapter can achieve comparable or better performance than standard Adapters when the sparse ratio reaches up to 80\%. Based on our findings, we introduce an easy but effective setting ``\textit{Large-Sparse}'' to improve the model capacity of Adapters under the same parameter budget. Experiments on five competitive Adapters upon three advanced PLMs show that with proper sparse method (e.g. SNIP) and ratio (e.g. 40\%) SparseAdapter can consistently outperform their corresponding counterpart. Encouragingly, with the \textit{Large-Sparse} setting, we can obtain further appealing gains, even outperforming the full fine-tuning by a large margin. Our code will be released at: \url{https://github.com/Shwai-He/SparseAdapter}.
A Comprehensive Survey of Data Augmentation in Visual Reinforcement Learning
Oct 10, 2022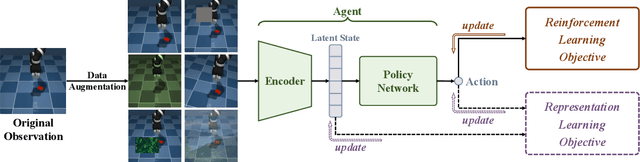
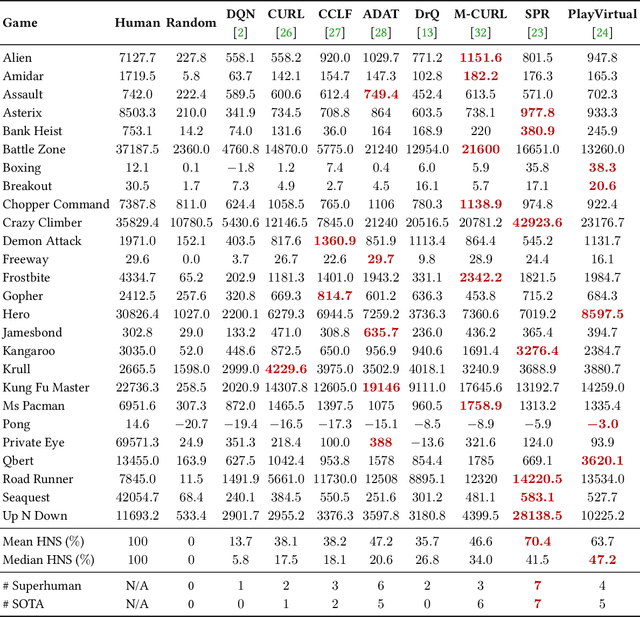
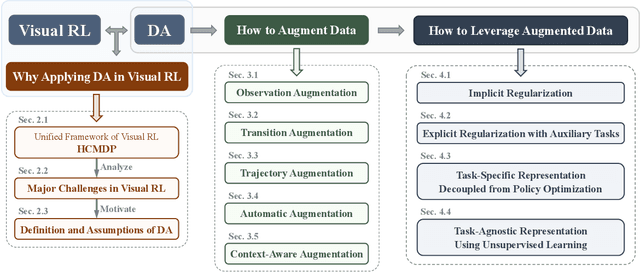
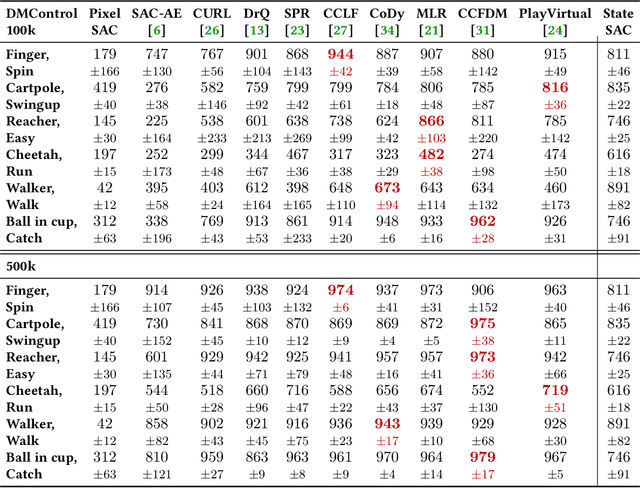
Visual reinforcement learning (RL), which makes decisions directly from high-dimensional visual inputs, has demonstrated significant potential in various domains. However, deploying visual RL techniques in the real world remains challenging due to their low sample efficiency and large generalization gaps. To tackle these obstacles, data augmentation (DA) has become a widely used technique in visual RL for acquiring sample-efficient and generalizable policies by diversifying the training data. This survey aims to provide a timely and essential review of DA techniques in visual RL in recognition of the thriving development in this field. In particular, we propose a unified framework for analyzing visual RL and understanding the role of DA in it. We then present a principled taxonomy of the existing augmentation techniques used in visual RL and conduct an in-depth discussion on how to better leverage augmented data in different scenarios. Moreover, we report a systematic empirical evaluation of DA-based techniques in visual RL and conclude by highlighting the directions for future research. As the first comprehensive survey of DA in visual RL, this work is expected to offer valuable guidance to this emerging field.
Bridged Transformer for Vision and Point Cloud 3D Object Detection
Oct 04, 2022

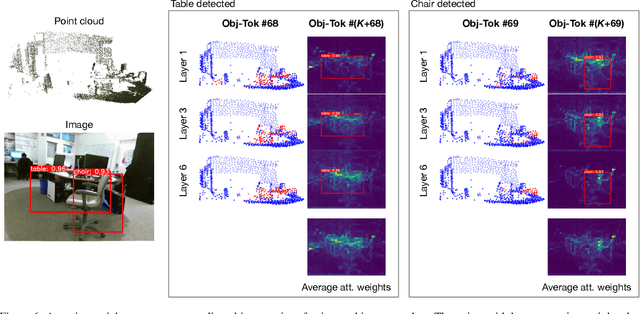
3D object detection is a crucial research topic in computer vision, which usually uses 3D point clouds as input in conventional setups. Recently, there is a trend of leveraging multiple sources of input data, such as complementing the 3D point cloud with 2D images that often have richer color and fewer noises. However, due to the heterogeneous geometrics of the 2D and 3D representations, it prevents us from applying off-the-shelf neural networks to achieve multimodal fusion. To that end, we propose Bridged Transformer (BrT), an end-to-end architecture for 3D object detection. BrT is simple and effective, which learns to identify 3D and 2D object bounding boxes from both points and image patches. A key element of BrT lies in the utilization of object queries for bridging 3D and 2D spaces, which unifies different sources of data representations in Transformer. We adopt a form of feature aggregation realized by point-to-patch projections which further strengthen the correlations between images and points. Moreover, BrT works seamlessly for fusing the point cloud with multi-view images. We experimentally show that BrT surpasses state-of-the-art methods on SUN RGB-D and ScanNetV2 datasets.
Alternating Differentiation for Optimization Layers
Oct 03, 2022
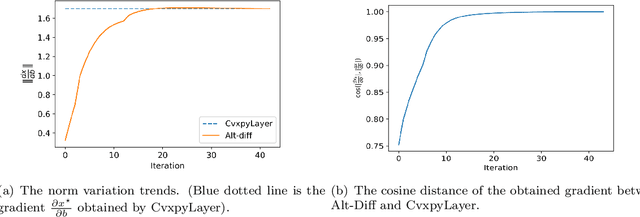
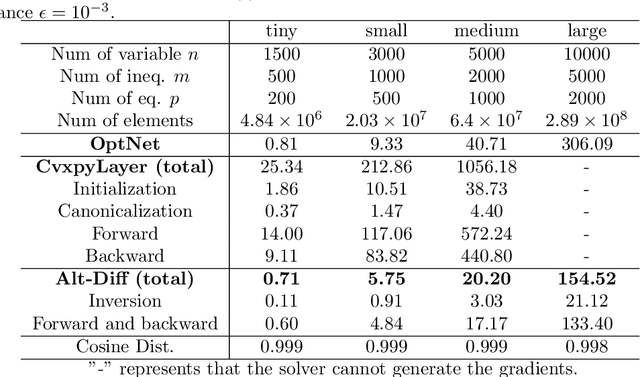
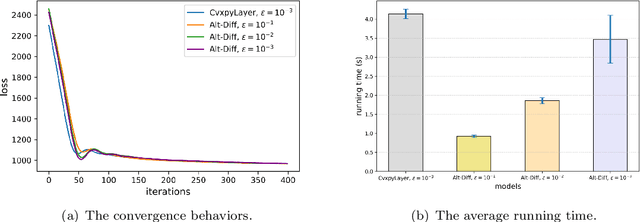
The idea of embedding optimization problems into deep neural networks as optimization layers to encode constraints and inductive priors has taken hold in recent years. Most existing methods focus on implicitly differentiating Karush-Kuhn-Tucker (KKT) conditions in a way that requires expensive computations on the Jacobian matrix, which can be slow and memory-intensive. In this paper, we developed a new framework, named Alternating Differentiation (Alt-Diff), that differentiates optimization problems (here, specifically in the form of convex optimization problems with polyhedral constraints) in a fast and recursive way. Alt-Diff decouples the differentiation procedure into a primal update and a dual update in an alternating way. Accordingly, Alt-Diff substantially decreases the dimensions of the Jacobian matrix and thus significantly increases the computational speed of implicit differentiation. Further, we present the computational complexity of the forward and backward pass of Alt-Diff and show that Alt-Diff enjoys quadratic computational complexity in the backward pass. Another notable difference between Alt-Diff and state-of-the-arts is that Alt-Diff can be truncated for the optimization layer. We theoretically show that: 1) Alt-Diff can converge to consistent gradients obtained by differentiating KKT conditions; 2) the error between the gradient obtained by the truncated Alt-Diff and by differentiating KKT conditions is upper bounded by the same order of variables' truncation error. Therefore, Alt-Diff can be truncated to further increases computational speed without sacrificing much accuracy. A series of comprehensive experiments demonstrate that Alt-Diff yields results comparable to the state-of-the-arts in far less time.
Exploring the Relationship between Architecture and Adversarially Robust Generalization
Sep 28, 2022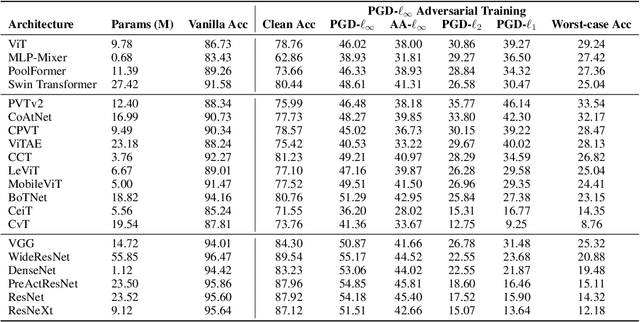
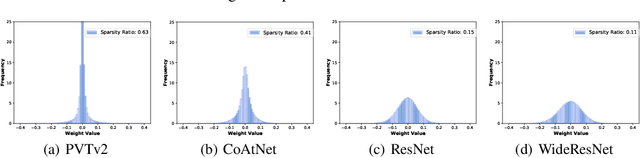
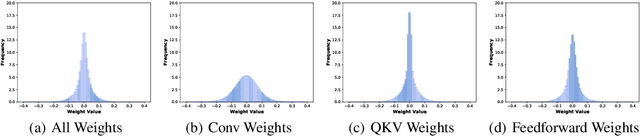
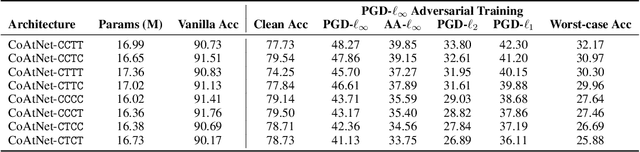
Adversarial training has been demonstrated to be one of the most effective remedies for defending adversarial examples, yet it often suffers from the huge robustness generalization gap on unseen testing adversaries, deemed as the \emph{adversarially robust generalization problem}. Despite the preliminary understandings devoted on adversarially robust generalization, little is known from the architectural perspective. Thus, this paper tries to bridge the gap by systematically examining the most representative architectures (e.g., Vision Transformers and CNNs). In particular, we first comprehensively evaluated \emph{20} adversarially trained architectures on ImageNette and CIFAR-10 datasets towards several adversaries (multiple $\ell_p$-norm adversarial attacks), and found that Vision Transformers (e.g., PVT, CoAtNet) often yield better adversarially robust generalization. To further understand what architectural ingredients favor adversarially robust generalization, we delve into several key building blocks and revealed the fact via the lens of Rademacher complexity that the higher weight sparsity contributes significantly towards the better adversarially robust generalization of Vision Transformers, which can be often achieved by attention layers. Our extensive studies discovered the close relationship between architectural design and adversarially robust generalization, and instantiated several important insights. We hope our findings could help to better understand the mechanism towards designing robust deep learning architectures.
Shuffle-QUDIO: accelerate distributed VQE with trainability enhancement and measurement reduction
Sep 26, 2022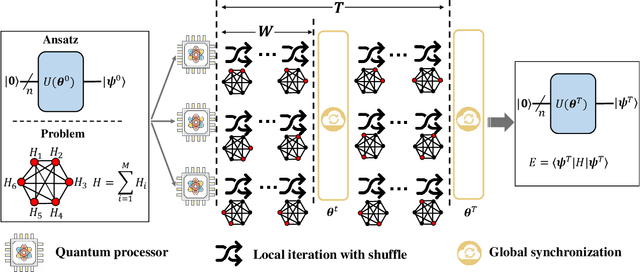

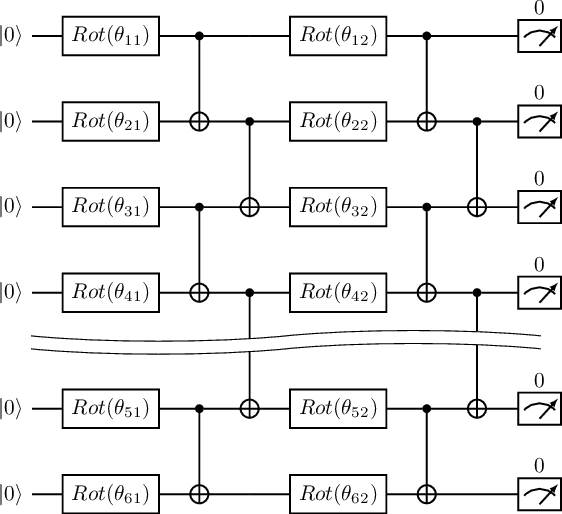
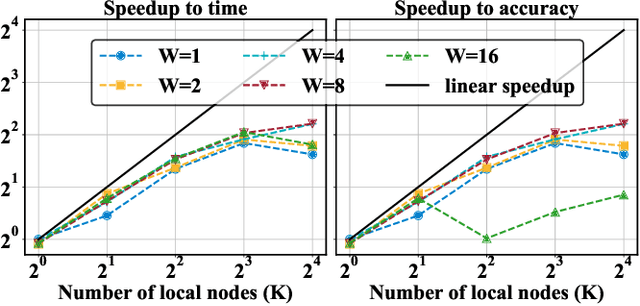
The variational quantum eigensolver (VQE) is a leading strategy that exploits noisy intermediate-scale quantum (NISQ) machines to tackle chemical problems outperforming classical approaches. To gain such computational advantages on large-scale problems, a feasible solution is the QUantum DIstributed Optimization (QUDIO) scheme, which partitions the original problem into $K$ subproblems and allocates them to $K$ quantum machines followed by the parallel optimization. Despite the provable acceleration ratio, the efficiency of QUDIO may heavily degrade by the synchronization operation. To conquer this issue, here we propose Shuffle-QUDIO to involve shuffle operations into local Hamiltonians during the quantum distributed optimization. Compared with QUDIO, Shuffle-QUDIO significantly reduces the communication frequency among quantum processors and simultaneously achieves better trainability. Particularly, we prove that Shuffle-QUDIO enables a faster convergence rate over QUDIO. Extensive numerical experiments are conducted to verify that Shuffle-QUDIO allows both a wall-clock time speedup and low approximation error in the tasks of estimating the ground state energy of molecule. We empirically demonstrate that our proposal can be seamlessly integrated with other acceleration techniques, such as operator grouping, to further improve the efficacy of VQE.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022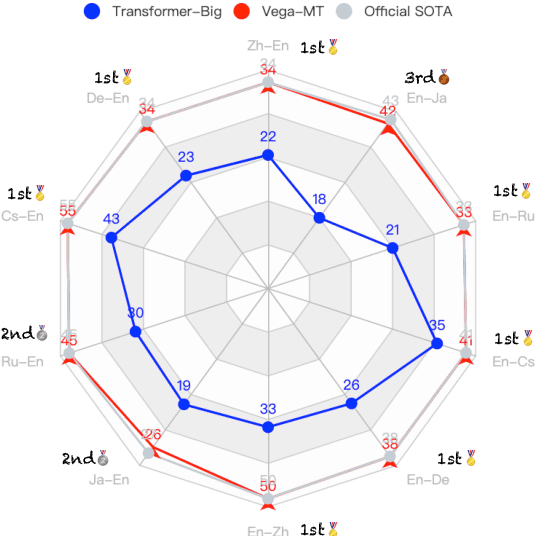
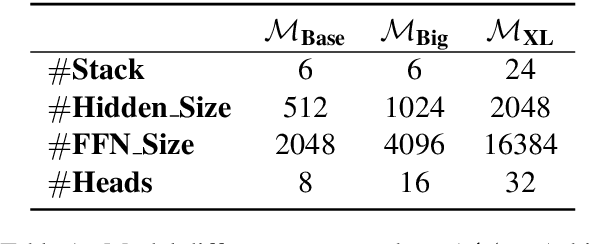
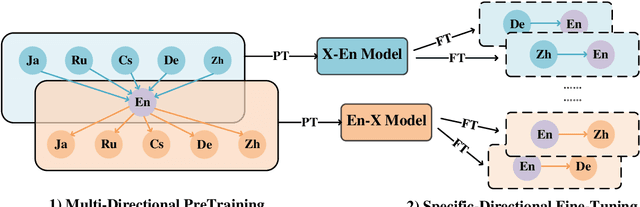

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.
Towards Robust Referring Image Segmentation
Sep 20, 2022
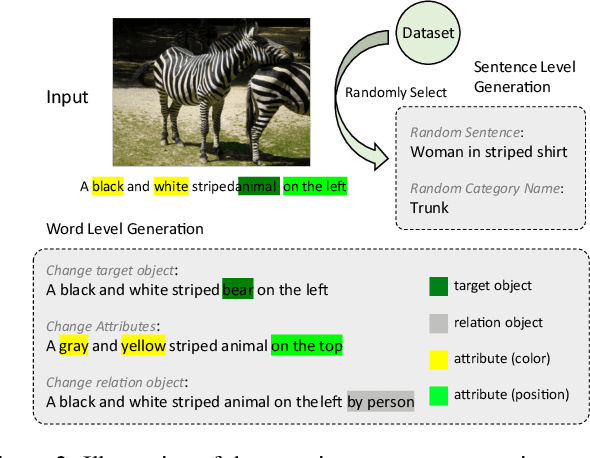
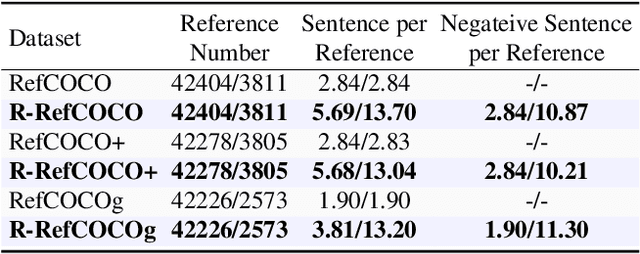
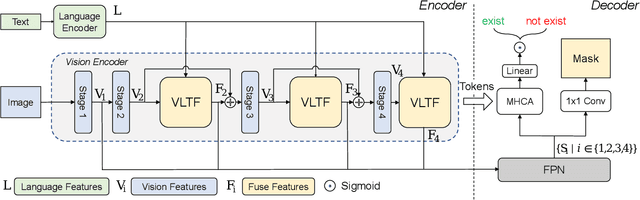
Referring Image Segmentation (RIS) aims to connect image and language via outputting the corresponding object masks given a text description, which is a fundamental vision-language task. Despite lots of works that have achieved considerable progress for RIS, in this work, we explore an essential question, "what if the description is wrong or misleading of the text description?". We term such a sentence as a negative sentence. However, we find that existing works cannot handle such settings. To this end, we propose a novel formulation of RIS, named Robust Referring Image Segmentation (R-RIS). It considers the negative sentence inputs besides the regularly given text inputs. We present three different datasets via augmenting the input negative sentences and a new metric to unify both input types. Furthermore, we design a new transformer-based model named RefSegformer, where we introduce a token-based vision and language fusion module. Such module can be easily extended to our R-RIS setting by adding extra blank tokens. Our proposed RefSegformer achieves the new state-of-the-art results on three regular RIS datasets and three R-RIS datasets, which serves as a new solid baseline for further research. The project page is at \url{https://lxtgh.github.io/project/robust_ref_seg/}.