 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumos: Learning Agents with Unified Data, Modular Design, and Open-Source LLMs
Nov 09, 2023



We introduce Lumos, a novel framework for training language agents that employs a unified data format and a modular architecture based on open-source large language models (LLMs). Lumos consists of three distinct modules: planning, grounding, and execution. The planning module breaks down a task into a series of high-level, tool-agnostic subgoals, which are then made specific by the grounding module through a set of low-level actions. These actions are subsequently executed by the execution module, utilizing a range of off-the-shelf tools and APIs. In order to train these modules effectively, high-quality annotations of subgoals and actions were collected and are made available for fine-tuning open-source LLMs for various tasks such as complex question answering, web tasks, and math problems. Leveraging this unified data and modular design, Lumos not only achieves comparable or superior performance to current, state-of-the-art agents, but also exhibits several key advantages: (1) Lumos surpasses GPT-4/3.5-based agents in complex question answering and web tasks, while equalling the performance of significantly larger LLM agents on math tasks; (2) Lumos outperforms open-source agents created through conventional training methods and those using chain-of-thoughts training; and (3) Lumos is capable of effectively generalizing to unseen interactive tasks, outperforming larger LLM-based agents and even exceeding performance of specialized agents.
Will the Prince Get True Love's Kiss? On the Model Sensitivity to Gender Perturbation over Fairytale Texts
Oct 16, 2023



Recent studies show that traditional fairytales are rife with harmful gender biases. To help mitigate these gender biases in fairytales, this work aims to assess learned biases of language models by evaluating their robustness against gender perturbations. Specifically, we focus on Question Answering (QA) tasks in fairytales. Using counterfactual data augmentation to the FairytaleQA dataset, we evaluate model robustness against swapped gender character information, and then mitigate learned biases by introducing counterfactual gender stereotypes during training time. We additionally introduce a novel approach that utilizes the massive vocabulary of language models to support text genres beyond fairytales. Our experimental results suggest that models are sensitive to gender perturbations, with significant performance drops compared to the original testing set. However, when first fine-tuned on a counterfactual training dataset, models are less sensitive to the later introduced anti-gender stereotyped text.
The Magic of IF: Investigating Causal Reasoning Abilities in Large Language Models of Code
May 30, 2023Causal reasoning, the ability to identify cause-and-effect relationship, is crucial in human thinking. Although large language models (LLMs) succeed in many NLP tasks, it is still challenging for them to conduct complex causal reasoning like abductive reasoning and counterfactual reasoning. Given the fact that programming code may express causal relations more often and explicitly with conditional statements like ``if``, we want to explore whether Code-LLMs acquire better causal reasoning abilities. Our experiments show that compared to text-only LLMs, Code-LLMs with code prompts are significantly better in causal reasoning. We further intervene on the prompts from different aspects, and discover that the programming structure is crucial in code prompt design, while Code-LLMs are robust towards format perturbations.
Dynosaur: A Dynamic Growth Paradigm for Instruction-Tuning Data Curation
May 23, 2023Instruction tuning has emerged to enhance the capabilities of large language models (LLMs) in providing appropriate outputs based on input instructions. However, existing methods for collecting instruction-tuning data suffer from limitations in scalability and affordability. In this paper, we propose Dynosaur, a dynamic growth paradigm for instruction-tuning data curation. Built upon the metadata of existing NLP datasets, we generate multiple task instructions applicable to various NLP datasets and determine the relevant data fields for constructing instruction-tuning data with LLMs. Dynosaur offers several advantages: 1) lower generation costs (less than $12 for generating 800K instruction-tuning data), 2) good quality of instruction-tuning data (better performance than Alpaca and Instruction GPT-4 on Super-NI with comparable data sizes), and 3) the ability to grow dynamically by incorporating new datasets from Huggingface Datasets Platform. We further investigate continual learning as an approach to learning with the ever-growing instruction-tuning dataset. We demonstrate that replay methods not only help mitigate forgetting issues but help generalize to unseen tasks better. As a novel continual learning scenario for instruction tuning, selecting tasks based on instruction representations can be an effective replaying strategy. Code and data are released at \url{https://github.com/WadeYin9712/Dynosaur}.
KPEval: Towards Fine-grained Semantic-based Evaluation of Keyphrase Extraction and Generation Systems
Mar 27, 2023Despite the significant advancements in keyphrase extraction and keyphrase generation methods, the predominant approach for evaluation only relies on exact matching with human references and disregards reference-free attributes. This scheme fails to recognize systems that generate keyphrases that are semantically equivalent to the references or keyphrases that have practical utility. To better understand the strengths and weaknesses of different keyphrase systems, we propose a comprehensive evaluation framework consisting of six critical dimensions: naturalness, faithfulness, saliency, coverage, diversity, and utility. For each dimension, we discuss the desiderata and design semantic-based metrics that align with the evaluation objectives. Rigorous meta-evaluation studies demonstrate that our evaluation strategy correlates better with human preferences compared to a range of previously used metrics. Using this framework, we re-evaluate 18 keyphrase systems and further discover that (1) the best model differs in different dimensions, with pre-trained language models achieving the best in most dimensions; (2) the utility in downstream tasks does not always correlate well with reference-based metrics; and (3) large language models exhibit a strong performance in reference-free evaluation.
GIVL: Improving Geographical Inclusivity of Vision-Language Models with Pre-Training Methods
Jan 05, 2023



A key goal for the advancement of AI is to develop technologies that serve the needs not just of one group but of all communities regardless of their geographical region. In fact, a significant proportion of knowledge is locally shared by people from certain regions but may not apply equally in other regions because of cultural differences. If a model is unaware of regional characteristics, it may lead to performance disparity across regions and result in bias against underrepresented groups. We propose GIVL, a Geographically Inclusive Vision-and-Language Pre-trained model. There are two attributes of geo-diverse visual concepts which can help to learn geo-diverse knowledge: 1) concepts under similar categories have unique knowledge and visual characteristics, 2) concepts with similar visual features may fall in completely different categories. Motivated by the attributes, we design new pre-training objectives Image Knowledge Matching (IKM) and Image Edit Checking (IEC) to pre-train GIVL. Compared with similar-size models pre-trained with similar scale of data, GIVL achieves state-of-the-art (SOTA) and more balanced performance on geo-diverse V&L tasks.
How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?
Oct 27, 2022Text-to-image generative models have achieved unprecedented success in generating high-quality images based on natural language descriptions. However, it is shown that these models tend to favor specific social groups when prompted with neutral text descriptions (e.g., 'a photo of a lawyer'). Following Zhao et al. (2021), we study the effect on the diversity of the generated images when adding ethical intervention that supports equitable judgment (e.g., 'if all individuals can be a lawyer irrespective of their gender') in the input prompts. To this end, we introduce an Ethical NaTural Language Interventions in Text-to-Image GENeration (ENTIGEN) benchmark dataset to evaluate the change in image generations conditional on ethical interventions across three social axes -- gender, skin color, and culture. Through ENTIGEN framework, we find that the generations from minDALL.E, DALL.E-mini and Stable Diffusion cover diverse social groups while preserving the image quality. Preliminary studies indicate that a large change in the model predictions is triggered by certain phrases such as 'irrespective of gender' in the context of gender bias in the ethical interventions. We release code and annotated data at https://github.com/Hritikbansal/entigen_emnlp.
Towards a Unified Multi-Dimensional Evaluator for Text Generation
Oct 13, 2022
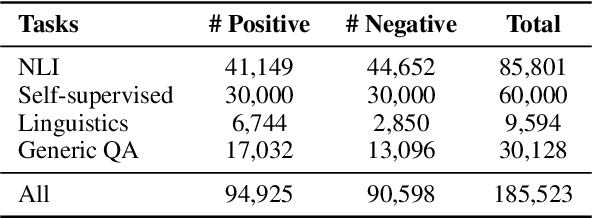
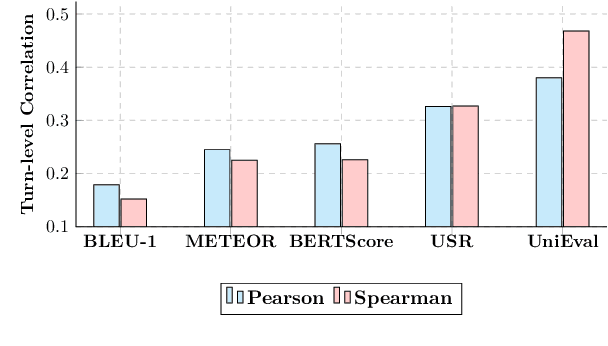
Multi-dimensional evaluation is the dominant paradigm for human evaluation in Natural Language Generation (NLG), i.e., evaluating the generated text from multiple explainable dimensions, such as coherence and fluency. However, automatic evaluation in NLG is still dominated by similarity-based metrics, and we lack a reliable framework for a more comprehensive evaluation of advanced models. In this paper, we propose a unified multi-dimensional evaluator UniEval for NLG. We re-frame NLG evaluation as a Boolean Question Answering (QA) task, and by guiding the model with different questions, we can use one evaluator to evaluate from multiple dimensions. Furthermore, thanks to the unified Boolean QA format, we are able to introduce an intermediate learning phase that enables UniEval to incorporate external knowledge from multiple related tasks and gain further improvement. Experiments on three typical NLG tasks show that UniEval correlates substantially better with human judgments than existing metrics. Specifically, compared to the top-performing unified evaluators, UniEval achieves a 23% higher correlation on text summarization, and over 43% on dialogue response generation. Also, UniEval demonstrates a strong zero-shot learning ability for unseen evaluation dimensions and tasks. Source code, data and all pre-trained evaluators are available on our GitHub repository (https://github.com/maszhongming/UniEval).
GeoMLAMA: Geo-Diverse Commonsense Probing on Multilingual Pre-Trained Language Models
May 24, 2022
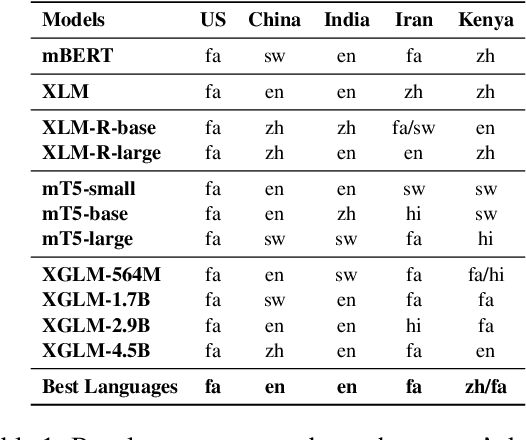
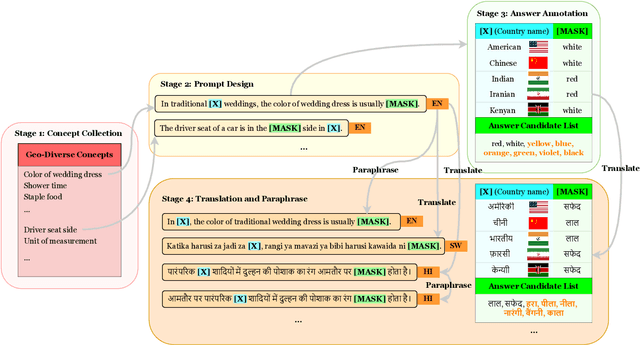
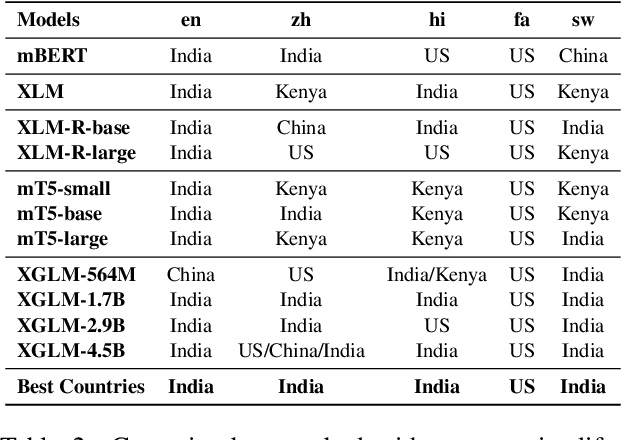
Recent work has shown that Pre-trained Language Models (PLMs) have the ability to store the relational knowledge from pre-training data in their model parameters. However, it is not clear up to what extent do PLMs store geo-diverse commonsense knowledge, the knowledge associated with a culture and only shared locally. For instance, the color of bridal dress is white in American weddings whereas it is red in Chinese weddings. Here, we wish to probe if PLMs can predict red and white as the color of the bridal dress when queried for American and Chinese weddings, respectively. To this end, we introduce a framework for geo-diverse commonsense probing on multilingual PLMs (mPLMs) and introduce a corresponding benchmark Geo-diverse Commonsense Multilingual Language Model Analysis (GeoMLAMA) dataset. GeoMLAMA contains 3125 prompts in English, Chinese, Hindi, Persian, and Swahili, with a wide coverage of concepts shared by people from American, Chinese, Indian, Iranian and Kenyan cultures. We benchmark 11 standard mPLMs which include variants of mBERT, XLM, mT5, and XGLM on GeoMLAMA. Interestingly, we find that 1) larger mPLM variants do not necessarily store geo-diverse concepts better than its smaller variant; 2) mPLMs are not intrinsically biased towards knowledge from the Western countries (the United States); 3) the native language of a country may not be the best language to probe its knowledge and 4) a language may better probe knowledge about a non-native country than its native country.
Things not Written in Text: Exploring Spatial Commonsense from Visual Signals
Mar 15, 2022
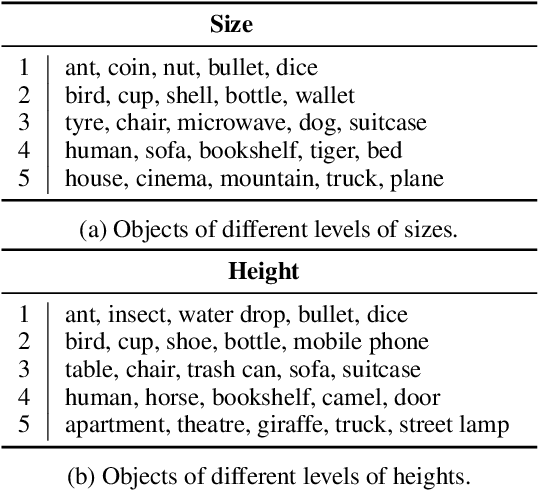
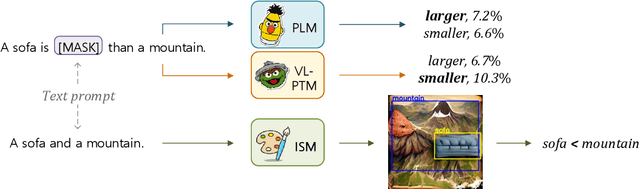

Spatial commonsense, the knowledge about spatial position and relationship between objects (like the relative size of a lion and a girl, and the position of a boy relative to a bicycle when cycling), is an important part of commonsense knowledge. Although pretrained language models (PLMs) succeed in many NLP tasks, they are shown to be ineffective in spatial commonsense reasoning. Starting from the observation that images are more likely to exhibit spatial commonsense than texts, we explore whether models with visual signals learn more spatial commonsense than text-based PLMs. We propose a spatial commonsense benchmark that focuses on the relative scales of objects, and the positional relationship between people and objects under different actions. We probe PLMs and models with visual signals, including vision-language pretrained models and image synthesis models, on this benchmark, and find that image synthesis models are more capable of learning accurate and consistent spatial knowledge than other models. The spatial knowledge from image synthesis models also helps in natural language understanding tasks that require spatial commonsense.