 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Accelerate Vision-Language-Action Models through Adaptive Visual Token Caching
Jan 31, 2026Vision-Language-Action (VLA) models have demonstrated remarkable generalization capabilities in robotic manipulation tasks, yet their substantial computational overhead remains a critical obstacle to real-world deployment. Improving inference efficiency is therefore essential for practical robotic applications. Existing acceleration methods often rely on heuristic or static strategies--such as rule-based token caching or pruning--that are decoupled from task objectives and fail to adapt to dynamic scene changes. In this work, we reformulate inference acceleration as a learnable policy optimization problem and propose a novel framework that integrates a dynamic, task-aware decision-making process directly into the VLA model. At its core are two lightweight, cooperative modules: a Cached Token Selector, which determines which tokens should be reused, and a Cache Ratio Predictor, which controls how many tokens to reuse. Training these modules is non-trivial due to their discrete decisions. We address this by adopting a differentiable relaxation that allows gradient-based end-to-end optimization. Extensive experiments on the LIBERO and SIMPLER benchmarks, as well as real-robot evaluations, show that our method achieves a 1.76x wall-clock inference speedup while simultaneously improving the average success rate by 1.9 percentage points (from 75.0% to 76.9%) on LIBERO and by 5.0 percentage points on real-world tasks, significantly outperforming existing baselines. This work highlights the potential of learning task-aware computational allocation policies, paving the way for VLA models that are both powerful and efficient.
Exploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities
May 28, 2025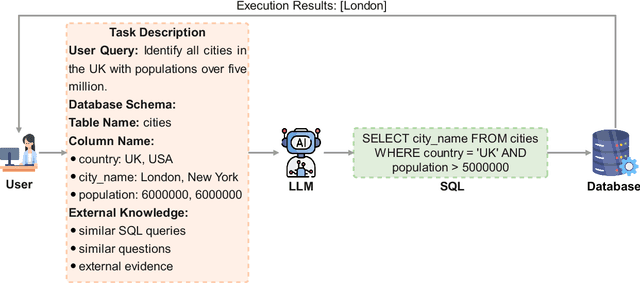
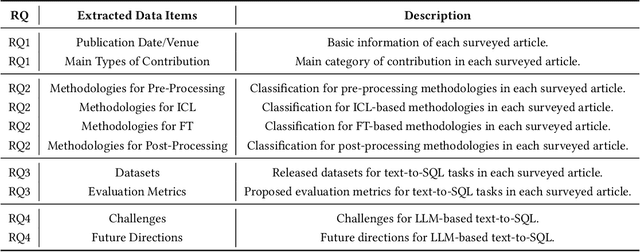
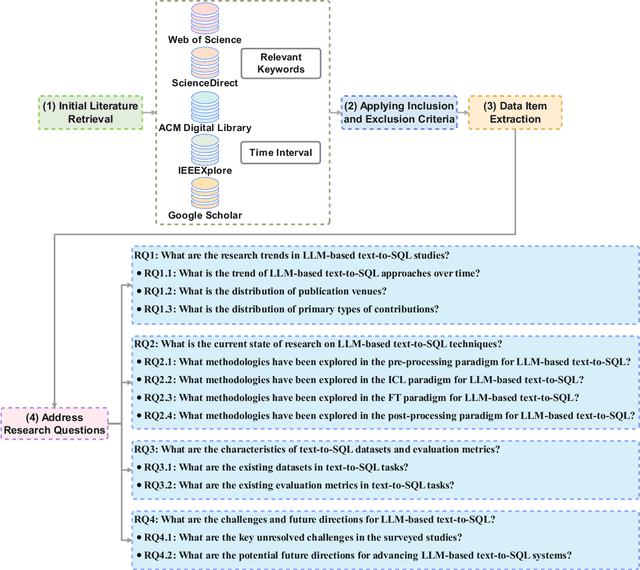
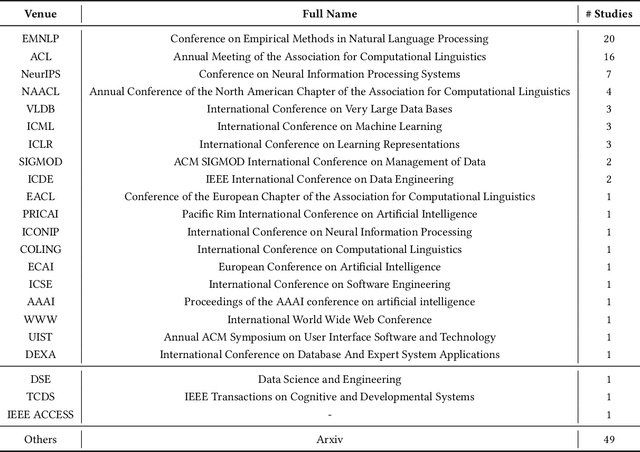
Converting natural language (NL) questions into SQL queries, referred to as Text-to-SQL, has emerged as a pivotal technology for facilitating access to relational databases, especially for users without SQL knowledge. Recent progress in large language models (LLMs) has markedly propelled the field of natural language processing (NLP), opening new avenues to improve text-to-SQL systems. This study presents a systematic review of LLM-based text-to-SQL, focusing on four key aspects: (1) an analysis of the research trends in LLM-based text-to-SQL; (2) an in-depth analysis of existing LLM-based text-to-SQL techniques from diverse perspectives; (3) summarization of existing text-to-SQL datasets and evaluation metrics; and (4) discussion on potential obstacles and avenues for future exploration in this domain. This survey seeks to furnish researchers with an in-depth understanding of LLM-based text-to-SQL, sparking new innovations and advancements in this field.
Can LLMs Replace Human Evaluators? An Empirical Study of LLM-as-a-Judge in Software Engineering
Feb 10, 2025Recently, large language models (LLMs) have been deployed to tackle various software engineering (SE) tasks like code generation, significantly advancing the automation of SE tasks. However, assessing the quality of these LLM-generated code and text remains challenging. The commonly used Pass@k metric necessitates extensive unit tests and configured environments, demands a high labor cost, and is not suitable for evaluating LLM-generated text. Conventional metrics like BLEU, which measure only lexical rather than semantic similarity, have also come under scrutiny. In response, a new trend has emerged to employ LLMs for automated evaluation, known as LLM-as-a-judge. These LLM-as-a-judge methods are claimed to better mimic human assessment than conventional metrics without relying on high-quality reference answers. Nevertheless, their exact human alignment in SE tasks remains unexplored. In this paper, we empirically explore LLM-as-a-judge methods for evaluating SE tasks, focusing on their alignment with human judgments. We select seven LLM-as-a-judge methods that utilize general-purpose LLMs, alongside two LLMs specifically fine-tuned for evaluation. After generating and manually scoring LLM responses on three recent SE datasets of code translation, code generation, and code summarization, we then prompt these methods to evaluate each response. Finally, we compare the scores generated by these methods with human evaluation. The results indicate that output-based methods reach the highest Pearson correlation of 81.32 and 68.51 with human scores in code translation and generation, achieving near-human evaluation, noticeably outperforming ChrF++, one of the best conventional metrics, at 34.23 and 64.92. Such output-based methods prompt LLMs to output judgments directly, and exhibit more balanced score distributions that resemble human score patterns. Finally, we provide...