 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Electronic Design Automation: A Handoff Perspective
Jun 18, 2026Electronic design automation (EDA) is inherently multi-stage and handoff-heavy. Design artifacts, flow scripts, and engineering decisions cross tool, session, and organizational boundaries before final implementation, signoff, or release. Each transfer carries explicit and implicit requirements that may not be fully captured by stage-local checks. LLM-based agents now invoke EDA tools directly, embed retrieved knowledge in executable scripts, and hand off state across sessions and stages. Once their outputs condition downstream engineering decisions, the transferred object must satisfy a handoff contract and meet the assumptions of its next consumer. This survey introduces handoff validity as its organizing principle. A handoff is valid when the transferred object satisfies the consumer's acceptance conditions and carries sufficient context, evidence, and provenance for downstream use. We review 82 systems and classify them into three boundary classes. Stage-Bound systems establish validity within a single EDA stage or bounded verification task. Flow-Bound systems preserve coherent workflow state across tools, invocations, and sessions. Organization-Bound systems maintain source grounding, provenance, scope, and admissibility across knowledge and authority boundaries. For each class, we analyze handoff contracts, handoff objects, coordination mechanisms, and open questions. These analyses motivate a five-layer EDA agent communication protocol (EACP), covering the agent discovery, agent message, tool invocation, workflow orchestration, and security and IP protocols. We aim to provide a common vocabulary and research agenda for trustworthy agentic EDA.
SPFT-SQL: Enhancing Large Language Model for Text-to-SQL Parsing by Self-Play Fine-Tuning
Sep 04, 2025Despite the significant advancements of self-play fine-tuning (SPIN), which can transform a weak large language model (LLM) into a strong one through competitive interactions between models of varying capabilities, it still faces challenges in the Text-to-SQL task. SPIN does not generate new information, and the large number of correct SQL queries produced by the opponent model during self-play reduces the main model's ability to generate accurate SQL queries. To address this challenge, we propose a new self-play fine-tuning method tailored for the Text-to-SQL task, called SPFT-SQL. Prior to self-play, we introduce a verification-based iterative fine-tuning approach, which synthesizes high-quality fine-tuning data iteratively based on the database schema and validation feedback to enhance model performance, while building a model base with varying capabilities. During the self-play fine-tuning phase, we propose an error-driven loss method that incentivizes incorrect outputs from the opponent model, enabling the main model to distinguish between correct SQL and erroneous SQL generated by the opponent model, thereby improving its ability to generate correct SQL. Extensive experiments and in-depth analyses on six open-source LLMs and five widely used benchmarks demonstrate that our approach outperforms existing state-of-the-art (SOTA) methods.
Exploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities
May 28, 2025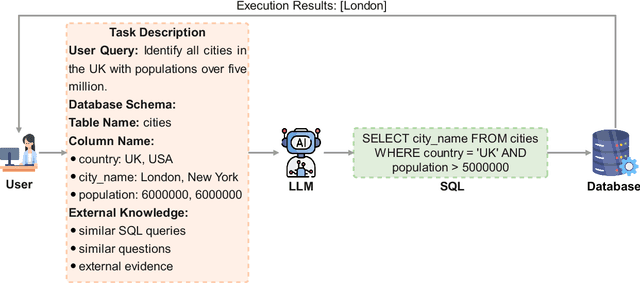
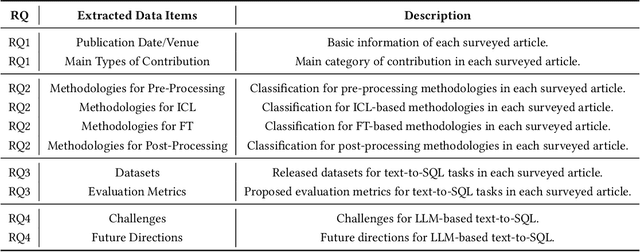
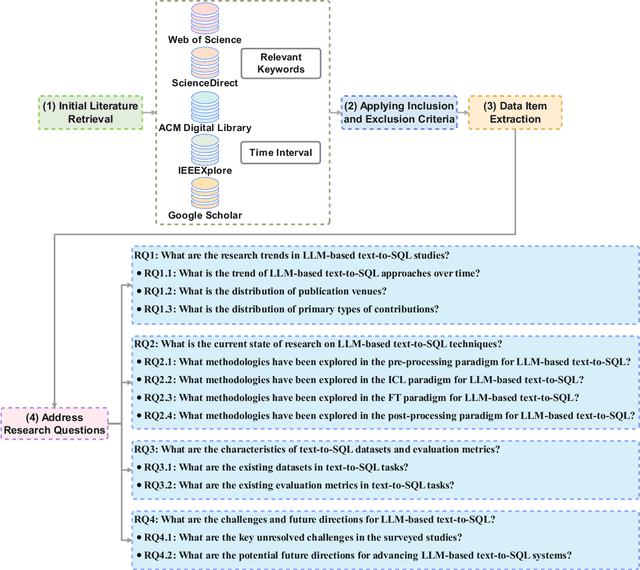
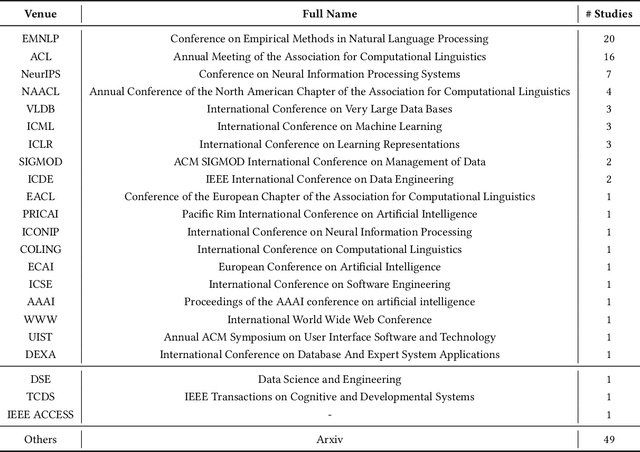
Converting natural language (NL) questions into SQL queries, referred to as Text-to-SQL, has emerged as a pivotal technology for facilitating access to relational databases, especially for users without SQL knowledge. Recent progress in large language models (LLMs) has markedly propelled the field of natural language processing (NLP), opening new avenues to improve text-to-SQL systems. This study presents a systematic review of LLM-based text-to-SQL, focusing on four key aspects: (1) an analysis of the research trends in LLM-based text-to-SQL; (2) an in-depth analysis of existing LLM-based text-to-SQL techniques from diverse perspectives; (3) summarization of existing text-to-SQL datasets and evaluation metrics; and (4) discussion on potential obstacles and avenues for future exploration in this domain. This survey seeks to furnish researchers with an in-depth understanding of LLM-based text-to-SQL, sparking new innovations and advancements in this field.
Generative Data Augmentation for Non-IID Problem in Decentralized Clinical Machine Learning
Dec 02, 2022



Swarm learning (SL) is an emerging promising decentralized machine learning paradigm and has achieved high performance in clinical applications. SL solves the problem of a central structure in federated learning by combining edge computing and blockchain-based peer-to-peer network. While there are promising results in the assumption of the independent and identically distributed (IID) data across participants, SL suffers from performance degradation as the degree of the non-IID data increases. To address this problem, we propose a generative augmentation framework in swarm learning called SL-GAN, which augments the non-IID data by generating the synthetic data from participants. SL-GAN trains generators and discriminators locally, and periodically aggregation via a randomly elected coordinator in SL network. Under the standard assumptions, we theoretically prove the convergence of SL-GAN using stochastic approximations. Experimental results demonstrate that SL-GAN outperforms state-of-art methods on three real world clinical datasets including Tuberculosis, Leukemia, COVID-19.
Fed-TDA: Federated Tabular Data Augmentation on Non-IID Data
Nov 22, 2022



Non-independent and identically distributed (non-IID) data is a key challenge in federated learning (FL), which usually hampers the optimization convergence and the performance of FL. Existing data augmentation methods based on federated generative models or raw data sharing strategies for solving the non-IID problem still suffer from low performance, privacy protection concerns, and high communication overhead in decentralized tabular data. To tackle these challenges, we propose a federated tabular data augmentation method, named Fed-TDA. The core idea of Fed-TDA is to synthesize tabular data for data augmentation using some simple statistics (e.g., distributions of each column and global covariance). Specifically, we propose the multimodal distribution transformation and inverse cumulative distribution mapping respectively synthesize continuous and discrete columns in tabular data from a noise according to the pre-learned statistics. Furthermore, we theoretically analyze that our Fed-TDA not only preserves data privacy but also maintains the distribution of the original data and the correlation between columns. Through extensive experiments on five real-world tabular datasets, we demonstrate the superiority of Fed-TDA over the state-of-the-art in test performance and communication efficiency.