 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities
May 28, 2025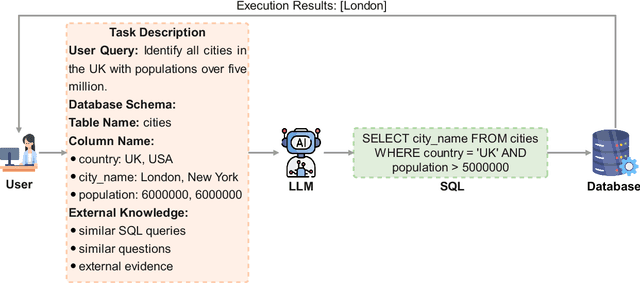
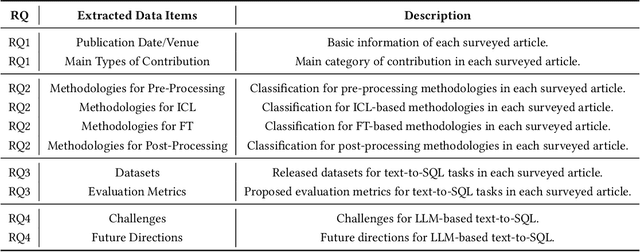
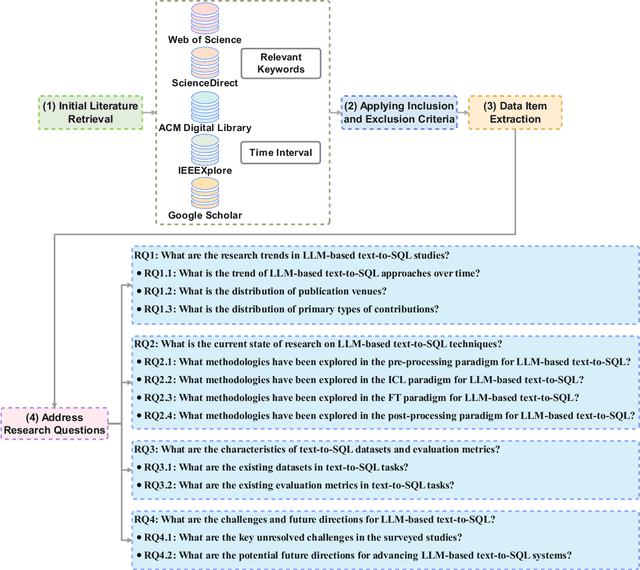
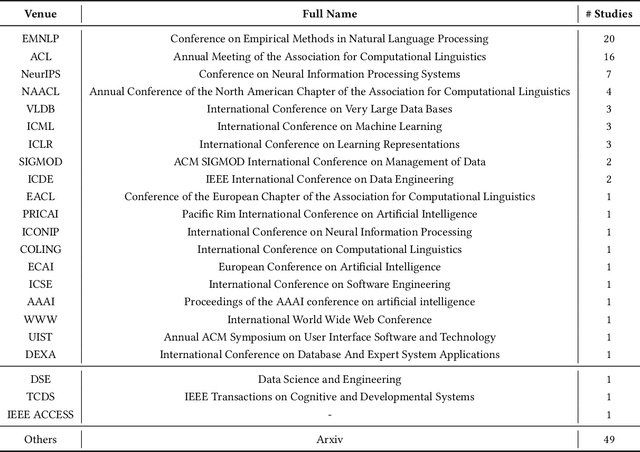
Converting natural language (NL) questions into SQL queries, referred to as Text-to-SQL, has emerged as a pivotal technology for facilitating access to relational databases, especially for users without SQL knowledge. Recent progress in large language models (LLMs) has markedly propelled the field of natural language processing (NLP), opening new avenues to improve text-to-SQL systems. This study presents a systematic review of LLM-based text-to-SQL, focusing on four key aspects: (1) an analysis of the research trends in LLM-based text-to-SQL; (2) an in-depth analysis of existing LLM-based text-to-SQL techniques from diverse perspectives; (3) summarization of existing text-to-SQL datasets and evaluation metrics; and (4) discussion on potential obstacles and avenues for future exploration in this domain. This survey seeks to furnish researchers with an in-depth understanding of LLM-based text-to-SQL, sparking new innovations and advancements in this field.
JIANG: Chinese Open Foundation Language Model
Aug 01, 2023



With the advancements in large language model technology, it has showcased capabilities that come close to those of human beings across various tasks. This achievement has garnered significant interest from companies and scientific research institutions, leading to substantial investments in the research and development of these models. While numerous large models have emerged during this period, the majority of them have been trained primarily on English data. Although they exhibit decent performance in other languages, such as Chinese, their potential remains limited due to factors like vocabulary design and training corpus. Consequently, their ability to fully express their capabilities in Chinese falls short. To address this issue, we introduce the model named JIANG (Chinese pinyin of ginger) specifically designed for the Chinese language. We have gathered a substantial amount of Chinese corpus to train the model and have also optimized its structure. The extensive experimental results demonstrate the excellent performance of our model.