 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgreeSum: Agreement-Oriented Multi-Document Summarization
Jun 04, 2021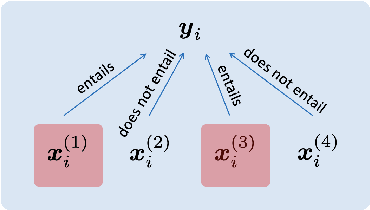

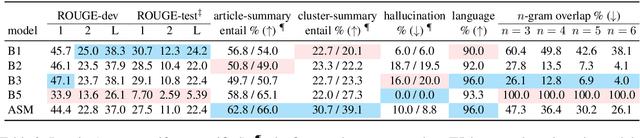
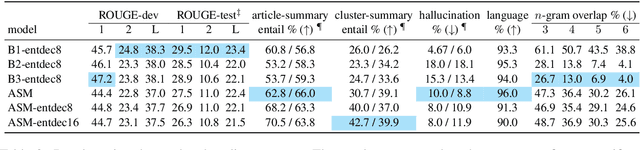
We aim to renew interest in a particular multi-document summarization (MDS) task which we call AgreeSum: agreement-oriented multi-document summarization. Given a cluster of articles, the goal is to provide abstractive summaries that represent information common and faithful to all input articles. Given the lack of existing datasets, we create a dataset for AgreeSum, and provide annotations on article-summary entailment relations for a subset of the clusters in the dataset. We aim to create strong baselines for the task by applying the top-performing pretrained single-document summarization model PEGASUS onto AgreeSum, leveraging both annotated clusters by supervised losses, and unannotated clusters by T5-based entailment-related and language-related losses. Compared to other baselines, both automatic evaluation and human evaluation show better article-summary and cluster-summary entailment in generated summaries. On a separate note, we hope that our article-summary entailment annotations contribute to the community's effort in improving abstractive summarization faithfulness.
Training ELECTRA Augmented with Multi-word Selection
May 31, 2021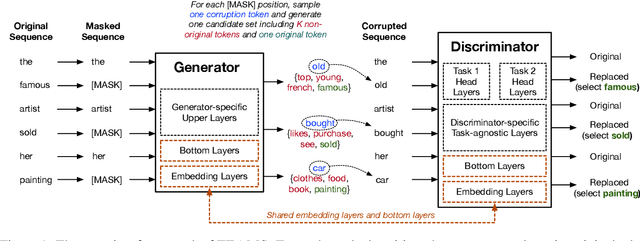
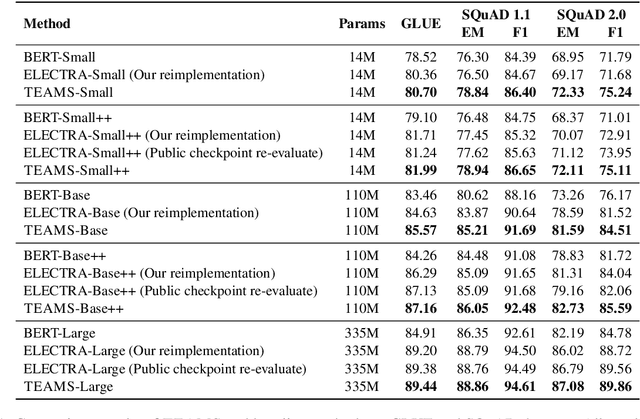
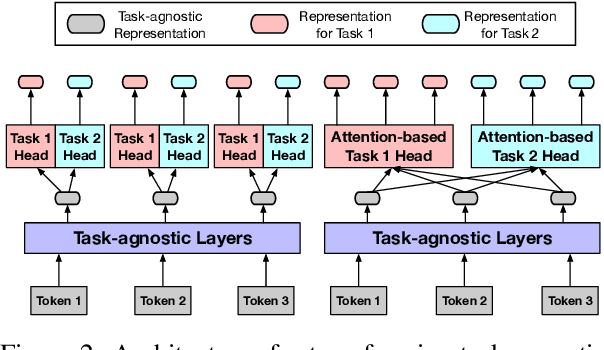
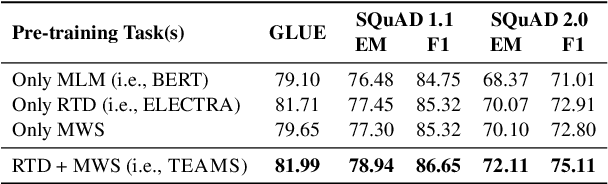
Pre-trained text encoders such as BERT and its variants have recently achieved state-of-the-art performances on many NLP tasks. While being effective, these pre-training methods typically demand massive computation resources. To accelerate pre-training, ELECTRA trains a discriminator that predicts whether each input token is replaced by a generator. However, this new task, as a binary classification, is less semantically informative. In this study, we present a new text encoder pre-training method that improves ELECTRA based on multi-task learning. Specifically, we train the discriminator to simultaneously detect replaced tokens and select original tokens from candidate sets. We further develop two techniques to effectively combine all pre-training tasks: (1) using attention-based networks for task-specific heads, and (2) sharing bottom layers of the generator and the discriminator. Extensive experiments on GLUE and SQuAD datasets demonstrate both the effectiveness and the efficiency of our proposed method.
Quiz-Style Question Generation for News Stories
Feb 18, 2021
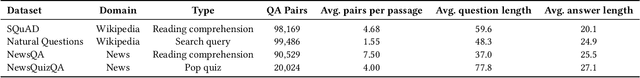
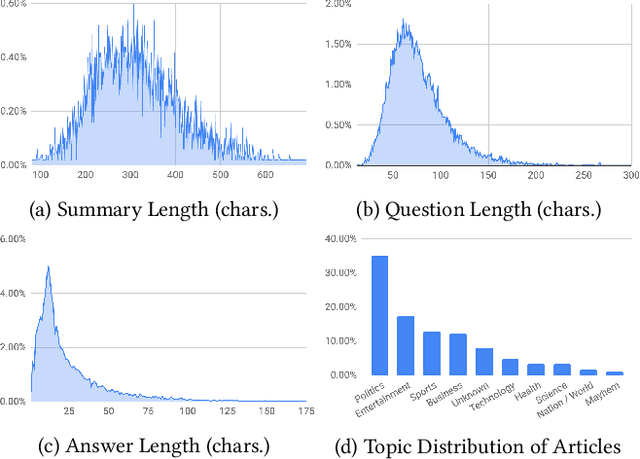
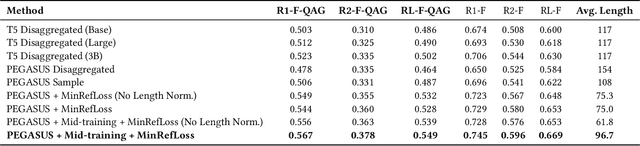
A large majority of American adults get at least some of their news from the Internet. Even though many online news products have the goal of informing their users about the news, they lack scalable and reliable tools for measuring how well they are achieving this goal, and therefore have to resort to noisy proxy metrics (e.g., click-through rates or reading time) to track their performance. As a first step towards measuring news informedness at a scale, we study the problem of quiz-style multiple-choice question generation, which may be used to survey users about their knowledge of recent news. In particular, we formulate the problem as two sequence-to-sequence tasks: question-answer generation (QAG) and distractor, or incorrect answer, generation (DG). We introduce NewsQuizQA, the first dataset intended for quiz-style question-answer generation, containing 20K human written question-answer pairs from 5K news article summaries. Using this dataset, we propose a series of novel techniques for applying large pre-trained Transformer encoder-decoder models, namely PEGASUS and T5, to the tasks of question-answer generation and distractor generation. We show that our models outperform strong baselines using both automated metrics and human raters. We provide a case study of running weekly quizzes on real-world users via the Google Surveys platform over the course of two months. We found that users generally found the automatically generated questions to be educational and enjoyable. Finally, to serve the research community, we are releasing the NewsQuizQA dataset.
TURL: Table Understanding through Representation Learning
Jun 26, 2020

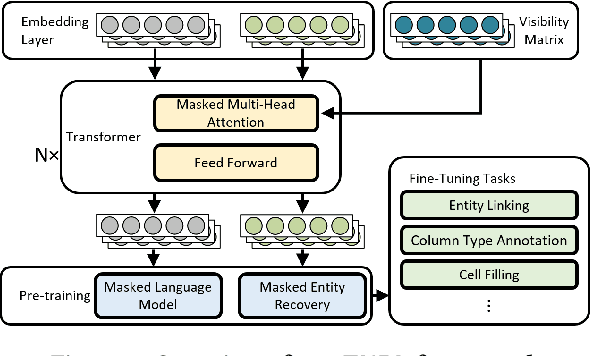
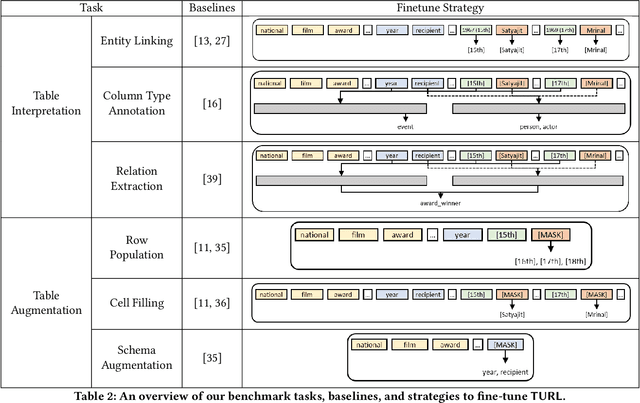
Relational tables on the Web store a vast amount of knowledge. Owing to the wealth of such tables, there has been tremendous progress on a variety of tasks in the area of table understanding. However, existing work generally relies on heavily-engineered task specific features and model architectures. In this paper, we present TURL, a novel framework that introduces the pre-training/finetuning paradigm to relational Web tables. During pre-training, our framework learns deep contextualized representations on relational tables in an unsupervised manner. Its universal model design with pre-trained representations can be applied to a wide range of tasks with minimal task-specific fine-tuning. Specifically, we propose a structure-aware Transformer encoder to model the row-column structure of relational tables, and present a new Masked Entity Recovery (MER) objective for pre-training to capture the semantics and knowledge in large-scale unlabeled data. We systematically evaluate TURL with a benchmark consisting of 6 different tasks for table understanding (e.g., relation extraction, cell filling). We show that TURL generalizes well to all tasks and substantially outperforms existing methods in almost all instances.
A Generative Approach to Titling and Clustering Wikipedia Sections
May 22, 2020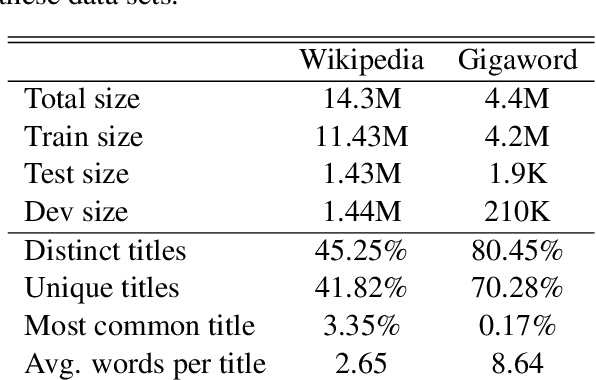
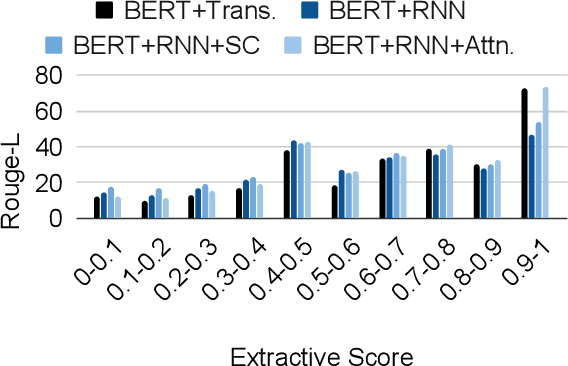
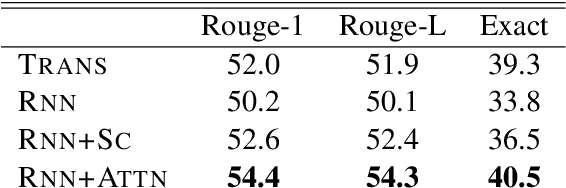
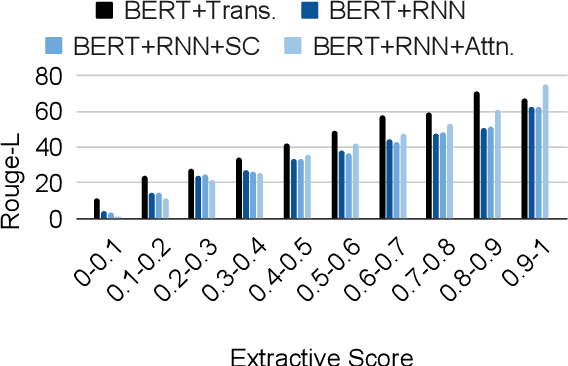
We evaluate the performance of transformer encoders with various decoders for information organization through a new task: generation of section headings for Wikipedia articles. Our analysis shows that decoders containing attention mechanisms over the encoder output achieve high-scoring results by generating extractive text. In contrast, a decoder without attention better facilitates semantic encoding and can be used to generate section embeddings. We additionally introduce a new loss function, which further encourages the decoder to generate high-quality embeddings.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020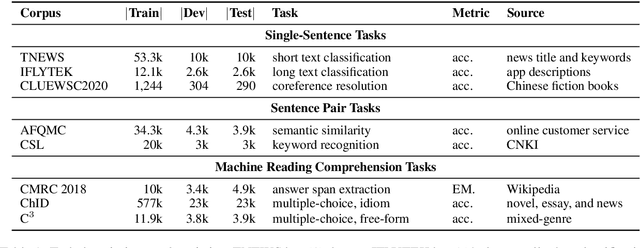
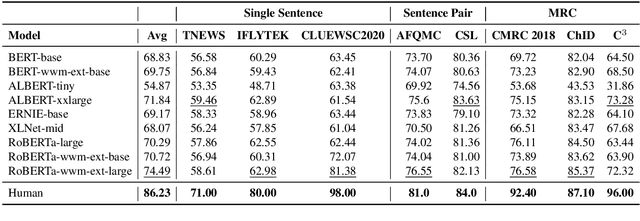
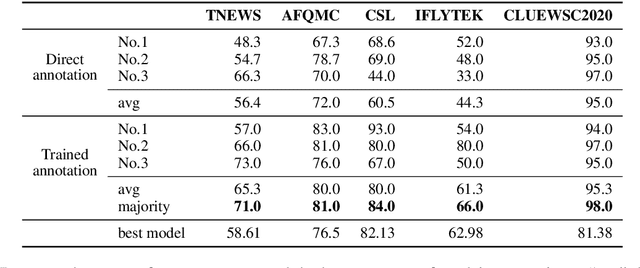
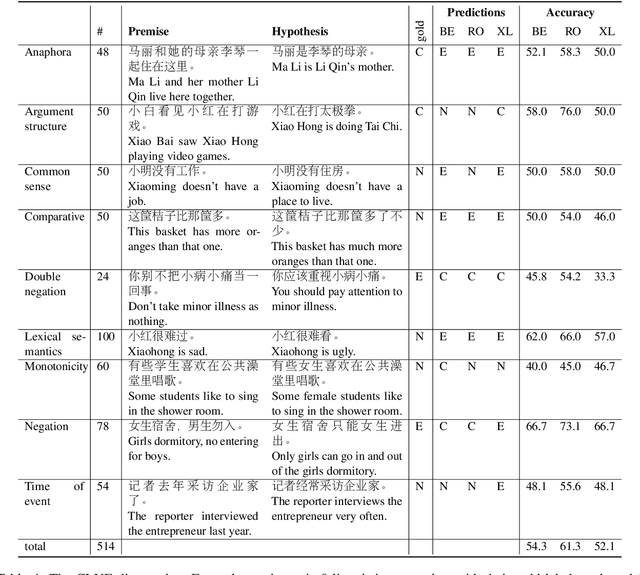
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.
Generating Representative Headlines for News Stories
Feb 01, 2020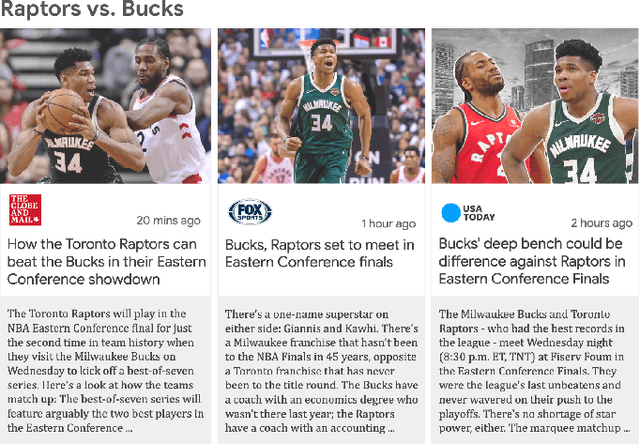
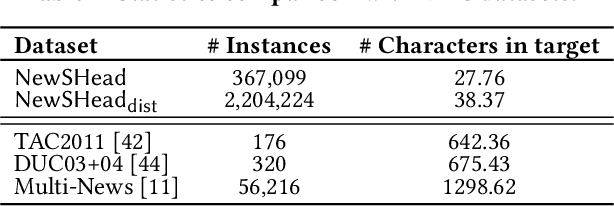
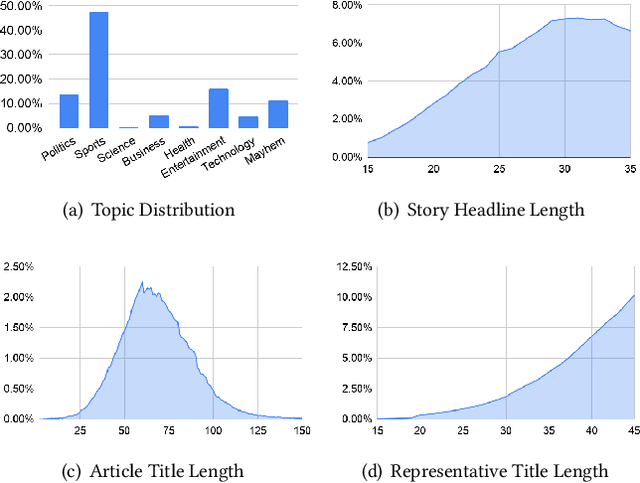

Millions of news articles are published online every day, which can be overwhelming for readers to follow. Grouping articles that are reporting the same event into news stories is a common way of assisting readers in their news consumption. However, it remains a challenging research problem to efficiently and effectively generate a representative headline for each story. Automatic summarization of a document set has been studied for decades, while few studies have focused on generating representative headlines for a set of articles. Unlike summaries, which aim to capture most information with least redundancy, headlines aim to capture information jointly shared by the story articles in short length, and exclude information that is too specific to each individual article. In this work, we study the problem of generating representative headlines for news stories. We develop a distant supervision approach to train large-scale generation models without any human annotation. This approach centers on two technical components. First, we propose a multi-level pre-training framework that incorporates massive unlabeled corpus with different quality-vs.-quantity balance at different levels. We show that models trained within this framework outperform those trained with pure human curated corpus. Second, we propose a novel self-voting-based article attention layer to extract salient information shared by multiple articles. We show that models that incorporate this layer are robust to potential noises in news stories and outperform existing baselines with or without noises. We can further enhance our model by incorporating human labels, and we show our distant supervision approach significantly reduces the demand on labeled data.
CLUENER2020: Fine-grained Named Entity Recognition Dataset and Benchmark for Chinese
Jan 20, 2020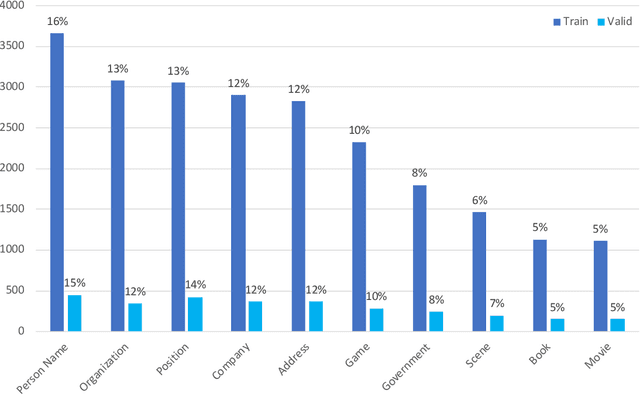

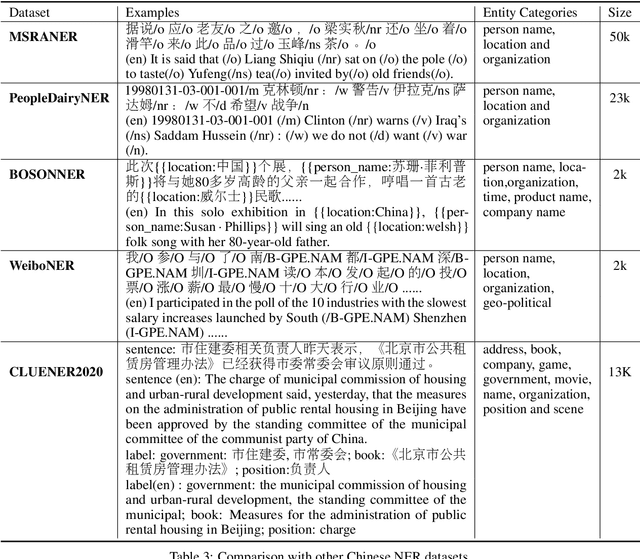
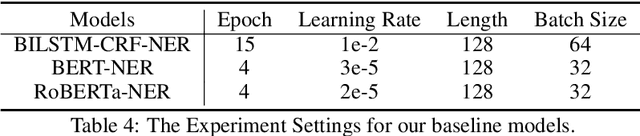
In this paper, we introduce the NER dataset from CLUE organization (CLUENER2020), a well-defined fine-grained dataset for named entity recognition in Chinese. CLUENER2020 contains 10 categories. Apart from common labels like person, organization, and location, it contains more diverse categories. It is more challenging than current other Chinese NER datasets and could better reflect real-world applications. For comparison, we implement several state-of-the-art baselines as sequence labeling tasks and report human performance, as well as its analysis. To facilitate future work on fine-grained NER for Chinese, we release our dataset, baselines, and leader-board.
Title Generation for Web Tables
Jun 30, 2018

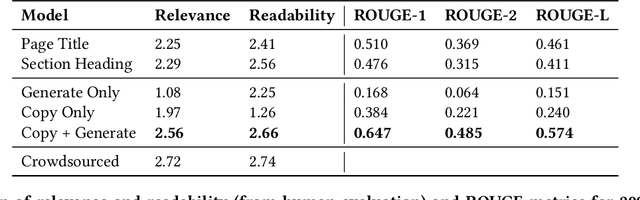
Descriptive titles provide crucial context for interpreting tables that are extracted from web pages and are a key component of table-based web applications. Prior approaches have attempted to produce titles by selecting existing text snippets associated with the table. These approaches, however, are limited by their dependence on suitable titles existing a priori. In our user study, we observe that the relevant information for the title tends to be scattered across the page, and often---more than 80% of time---does not appear verbatim anywhere in the page. We propose instead the application of a sequence-to-sequence neural network model as a more generalizable means of generating high-quality titles. This is accomplished by extracting many text snippets that have potentially relevant information to the table, encoding them into an input sequence, and using both copy and generation mechanisms in the decoder to balance relevance and readability of the generated title. We validate this approach with human evaluation on sample web tables and report that while sequence models with only a copy mechanism or only a generation mechanism are easily outperformed by simple selection-based baselines, the model with both capabilities outperforms them all, approaching the quality of crowdsourced titles while training on fewer than ten thousand examples. To the best of our knowledge, the proposed technique is the first to consider text-generation methods for table titles, and establishes a new state of the art.