 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIG-Bench Extra Hard
Feb 26, 2025Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8\% for the best general-purpose model and 44.8\% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
Tomato, Tomahto, Tomate: Measuring the Role of Shared Semantics among Subwords in Multilingual Language Models
Nov 07, 2024



Human understanding of language is robust to different word choices as far as they represent similar semantic concepts. To what extent does our human intuition transfer to language models, which represent all subwords as distinct embeddings? In this work, we take an initial step on measuring the role of shared semantics among subwords in the encoder-only multilingual language models (mLMs). To this end, we form "semantic tokens" by merging the semantically similar subwords and their embeddings, and evaluate the updated mLMs on 5 heterogeneous multilingual downstream tasks. Results show that the general shared semantics could get the models a long way in making the predictions on mLMs with different tokenizers and model sizes. Inspections on the grouped subwords show that they exhibit a wide range of semantic similarities, including synonyms and translations across many languages and scripts. Lastly, we found the zero-shot results with semantic tokens are on par or even better than the original models on certain classification tasks, suggesting that the shared subword-level semantics may serve as the anchors for cross-lingual transferring.
Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
Aug 29, 2024



Training on high-quality synthetic data from strong language models (LMs) is a common strategy to improve the reasoning performance of LMs. In this work, we revisit whether this strategy is compute-optimal under a fixed inference budget (e.g., FLOPs). To do so, we investigate the trade-offs between generating synthetic data using a stronger but more expensive (SE) model versus a weaker but cheaper (WC) model. We evaluate the generated data across three key metrics: coverage, diversity, and false positive rate, and show that the data from WC models may have higher coverage and diversity, but also exhibit higher false positive rates. We then finetune LMs on data from SE and WC models in different settings: knowledge distillation, self-improvement, and a novel weak-to-strong improvement setup where a weaker LM teaches reasoning to a stronger LM. Our findings reveal that models finetuned on WC-generated data consistently outperform those trained on SE-generated data across multiple benchmarks and multiple choices of WC and SE models. These results challenge the prevailing practice of relying on SE models for synthetic data generation, suggesting that WC may be the compute-optimal approach for training advanced LM reasoners.
Fractal Patterns May Unravel the Intelligence in Next-Token Prediction
Feb 02, 2024



We study the fractal structure of language, aiming to provide a precise formalism for quantifying properties that may have been previously suspected but not formally shown. We establish that language is: (1) self-similar, exhibiting complexities at all levels of granularity, with no particular characteristic context length, and (2) long-range dependent (LRD), with a Hurst parameter of approximately H=0.70. Based on these findings, we argue that short-term patterns/dependencies in language, such as in paragraphs, mirror the patterns/dependencies over larger scopes, like entire documents. This may shed some light on how next-token prediction can lead to a comprehension of the structure of text at multiple levels of granularity, from words and clauses to broader contexts and intents. We also demonstrate that fractal parameters improve upon perplexity-based bits-per-byte (BPB) in predicting downstream performance. We hope these findings offer a fresh perspective on language and the mechanisms underlying the success of LLMs.
How Does Generative Retrieval Scale to Millions of Passages?
May 19, 2023



Popularized by the Differentiable Search Index, the emerging paradigm of generative retrieval re-frames the classic information retrieval problem into a sequence-to-sequence modeling task, forgoing external indices and encoding an entire document corpus within a single Transformer. Although many different approaches have been proposed to improve the effectiveness of generative retrieval, they have only been evaluated on document corpora on the order of 100k in size. We conduct the first empirical study of generative retrieval techniques across various corpus scales, ultimately scaling up to the entire MS MARCO passage ranking task with a corpus of 8.8M passages and evaluating model sizes up to 11B parameters. We uncover several findings about scaling generative retrieval to millions of passages; notably, the central importance of using synthetic queries as document representations during indexing, the ineffectiveness of existing proposed architecture modifications when accounting for compute cost, and the limits of naively scaling model parameters with respect to retrieval performance. While we find that generative retrieval is competitive with state-of-the-art dual encoders on small corpora, scaling to millions of passages remains an important and unsolved challenge. We believe these findings will be valuable for the community to clarify the current state of generative retrieval, highlight the unique challenges, and inspire new research directions.
Recommender Systems with Generative Retrieval
May 08, 2023Modern recommender systems leverage large-scale retrieval models consisting of two stages: training a dual-encoder model to embed queries and candidates in the same space, followed by an Approximate Nearest Neighbor (ANN) search to select top candidates given a query's embedding. In this paper, we propose a new single-stage paradigm: a generative retrieval model which autoregressively decodes the identifiers for the target candidates in one phase. To do this, instead of assigning randomly generated atomic IDs to each item, we generate Semantic IDs: a semantically meaningful tuple of codewords for each item that serves as its unique identifier. We use a hierarchical method called RQ-VAE to generate these codewords. Once we have the Semantic IDs for all the items, a Transformer based sequence-to-sequence model is trained to predict the Semantic ID of the next item. Since this model predicts the tuple of codewords identifying the next item directly in an autoregressive manner, it can be considered a generative retrieval model. We show that our recommender system trained in this new paradigm improves the results achieved by current SOTA models on the Amazon dataset. Moreover, we demonstrate that the sequence-to-sequence model coupled with hierarchical Semantic IDs offers better generalization and hence improves retrieval of cold-start items for recommendations.
DSI++: Updating Transformer Memory with New Documents
Dec 19, 2022



Differentiable Search Indices (DSIs) encode a corpus of documents in the parameters of a model and use the same model to map queries directly to relevant document identifiers. Despite the strong performance of DSI models, deploying them in situations where the corpus changes over time is computationally expensive because reindexing the corpus requires re-training the model. In this work, we introduce DSI++, a continual learning challenge for DSI to incrementally index new documents while being able to answer queries related to both previously and newly indexed documents. Across different model scales and document identifier representations, we show that continual indexing of new documents leads to considerable forgetting of previously indexed documents. We also hypothesize and verify that the model experiences forgetting events during training, leading to unstable learning. To mitigate these issues, we investigate two approaches. The first focuses on modifying the training dynamics. Flatter minima implicitly alleviate forgetting, so we optimize for flatter loss basins and show that the model stably memorizes more documents (+12\%). Next, we introduce a generative memory to sample pseudo-queries for documents and supplement them during continual indexing to prevent forgetting for the retrieval task. Extensive experiments on novel continual indexing benchmarks based on Natural Questions (NQ) and MS MARCO demonstrate that our proposed solution mitigates forgetting by a significant margin. Concretely, it improves the average Hits@10 by $+21.1\%$ over competitive baselines for NQ and requires $6$ times fewer model updates compared to re-training the DSI model for incrementally indexing five corpora in a sequence.
Dense Feature Memory Augmented Transformers for COVID-19 Vaccination Search Classification
Dec 16, 2022



With the devastating outbreak of COVID-19, vaccines are one of the crucial lines of defense against mass infection in this global pandemic. Given the protection they provide, vaccines are becoming mandatory in certain social and professional settings. This paper presents a classification model for detecting COVID-19 vaccination related search queries, a machine learning model that is used to generate search insights for COVID-19 vaccinations. The proposed method combines and leverages advancements from modern state-of-the-art (SOTA) natural language understanding (NLU) techniques such as pretrained Transformers with traditional dense features. We propose a novel approach of considering dense features as memory tokens that the model can attend to. We show that this new modeling approach enables a significant improvement to the Vaccine Search Insights (VSI) task, improving a strong well-established gradient-boosting baseline by relative +15% improvement in F1 score and +14% in precision.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
Transcending Scaling Laws with 0.1% Extra Compute
Oct 20, 2022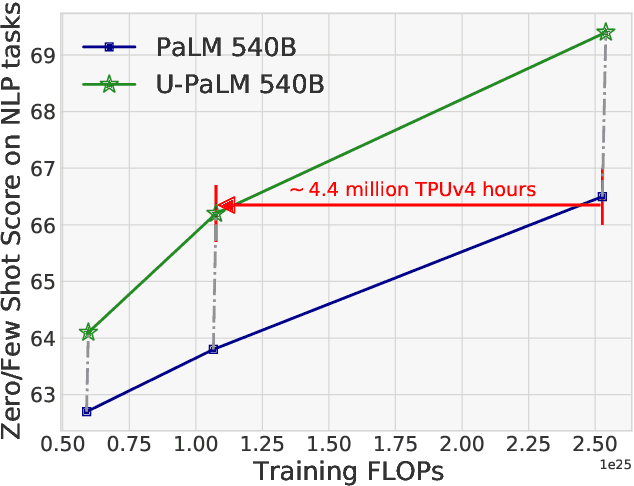
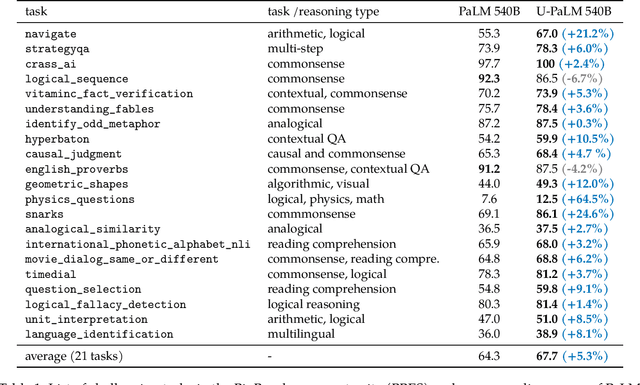
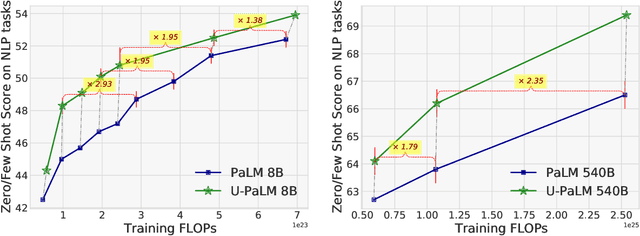
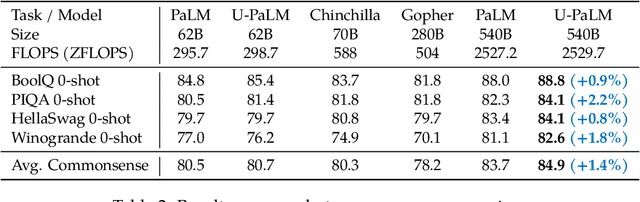
Scaling language models improves performance but comes with significant computational costs. This paper proposes UL2R, a method that substantially improves existing language models and their scaling curves with a relatively tiny amount of extra compute. The key idea is to continue training a state-of-the-art large language model (e.g., PaLM) on a few more steps with UL2's mixture-of-denoiser objective. We show that, with almost negligible extra computational costs and no new sources of data, we are able to substantially improve the scaling properties of large language models on downstream metrics. In this paper, we continue training PaLM with UL2R, introducing a new set of models at 8B, 62B, and 540B scale which we call U-PaLM. Impressively, at 540B scale, we show an approximately 2x computational savings rate where U-PaLM achieves the same performance as the final PaLM 540B model at around half its computational budget (i.e., saving $\sim$4.4 million TPUv4 hours). We further show that this improved scaling curve leads to 'emergent abilities' on challenging BIG-Bench tasks -- for instance, U-PaLM does much better than PaLM on some tasks or demonstrates better quality at much smaller scale (62B as opposed to 540B). Overall, we show that U-PaLM outperforms PaLM on many few-shot setups, i.e., English NLP tasks (e.g., commonsense reasoning, question answering), reasoning tasks with chain-of-thought (e.g., GSM8K), multilingual tasks (MGSM, TydiQA), MMLU and challenging BIG-Bench tasks. Finally, we provide qualitative examples showing the new capabilities of U-PaLM for single and multi-span infilling.