 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
On Relation-Specific Neurons in Large Language Models
Feb 24, 2025In large language models (LLMs), certain neurons can store distinct pieces of knowledge learned during pretraining. While knowledge typically appears as a combination of relations and entities, it remains unclear whether some neurons focus on a relation itself -- independent of any entity. We hypothesize such neurons detect a relation in the input text and guide generation involving such a relation. To investigate this, we study the Llama-2 family on a chosen set of relations with a statistics-based method. Our experiments demonstrate the existence of relation-specific neurons. We measure the effect of selectively deactivating candidate neurons specific to relation $r$ on the LLM's ability to handle (1) facts whose relation is $r$ and (2) facts whose relation is a different relation $r' \neq r$. With respect to their capacity for encoding relation information, we give evidence for the following three properties of relation-specific neurons. $\textbf{(i) Neuron cumulativity.}$ The neurons for $r$ present a cumulative effect so that deactivating a larger portion of them results in the degradation of more facts in $r$. $\textbf{(ii) Neuron versatility.}$ Neurons can be shared across multiple closely related as well as less related relations. Some relation neurons transfer across languages. $\textbf{(iii) Neuron interference.}$ Deactivating neurons specific to one relation can improve LLM generation performance for facts of other relations. We will make our code publicly available at https://github.com/cisnlp/relation-specific-neurons.
LM-CPPF: Paraphrasing-Guided Data Augmentation for Contrastive Prompt-Based Few-Shot Fine-Tuning
Jun 13, 2023



In recent years, there has been significant progress in developing pre-trained language models for NLP. However, these models often struggle when fine-tuned on small datasets. To address this issue, researchers have proposed various adaptation approaches. Prompt-based tuning is arguably the most common way, especially for larger models. Previous research shows that adding contrastive learning to prompt-based fine-tuning is effective as it helps the model generate embeddings that are more distinguishable between classes, and it can also be more sample-efficient as the model learns from positive and negative examples simultaneously. One of the most important components of contrastive learning is data augmentation, but unlike computer vision, effective data augmentation for NLP is still challenging. This paper proposes LM-CPPF, Contrastive Paraphrasing-guided Prompt-based Fine-tuning of Language Models, which leverages prompt-based few-shot paraphrasing using generative language models, especially large language models such as GPT-3 and OPT-175B, for data augmentation. Our experiments on multiple text classification benchmarks show that this augmentation method outperforms other methods, such as easy data augmentation, back translation, and multiple templates.
Zero-Shot Retrieval with Search Agents and Hybrid Environments
Sep 30, 2022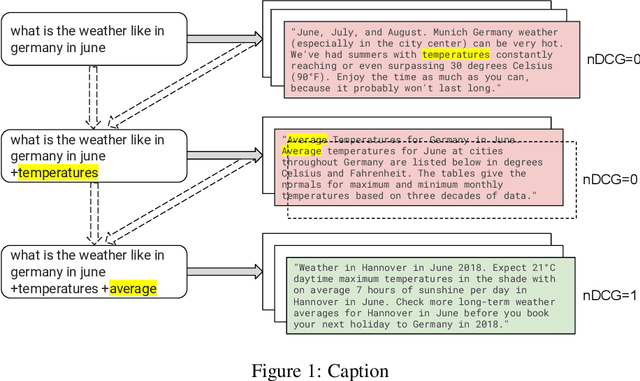
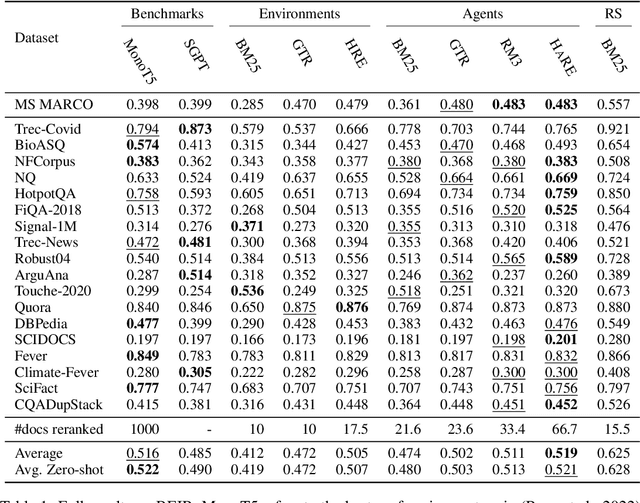
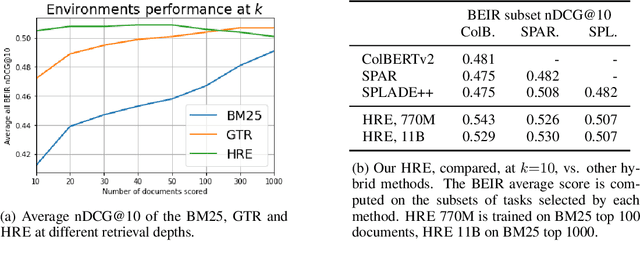
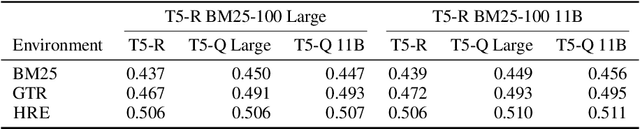
Learning to search is the task of building artificial agents that learn to autonomously use a search box to find information. So far, it has been shown that current language models can learn symbolic query reformulation policies, in combination with traditional term-based retrieval, but fall short of outperforming neural retrievers. We extend the previous learning to search setup to a hybrid environment, which accepts discrete query refinement operations, after a first-pass retrieval step performed by a dual encoder. Experiments on the BEIR task show that search agents, trained via behavioral cloning, outperform the underlying search system based on a combined dual encoder retriever and cross encoder reranker. Furthermore, we find that simple heuristic Hybrid Retrieval Environments (HRE) can improve baseline performance by several nDCG points. The search agent based on HRE (HARE) produces state-of-the-art performance on both zero-shot and in-domain evaluations. We carry out an extensive qualitative analysis to shed light on the agents policies.
A Simple Recipe for Multilingual Grammatical Error Correction
Jun 07, 2021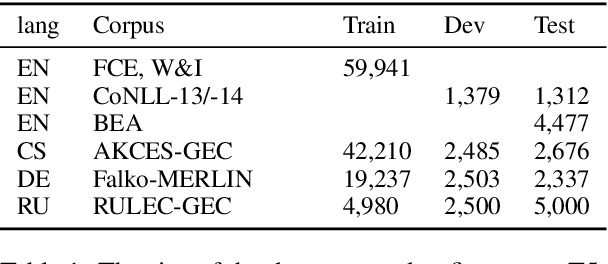
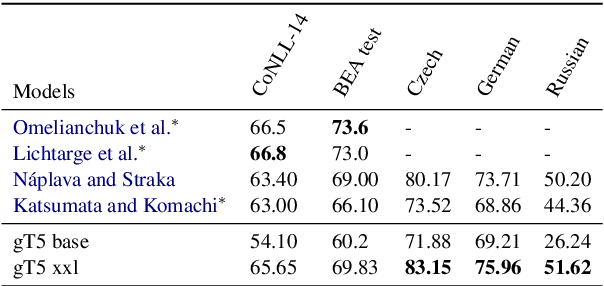
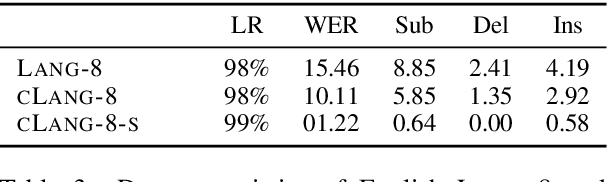
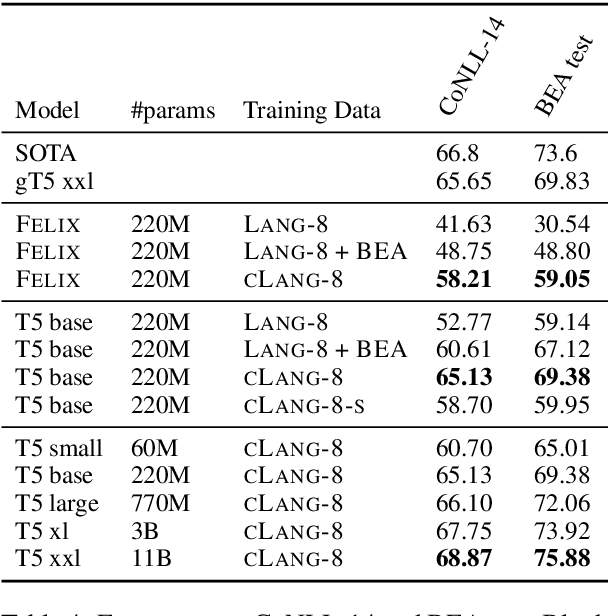
This paper presents a simple recipe to train state-of-the-art multilingual Grammatical Error Correction (GEC) models. We achieve this by first proposing a language-agnostic method to generate a large number of synthetic examples. The second ingredient is to use large-scale multilingual language models (up to 11B parameters). Once fine-tuned on language-specific supervised sets we surpass the previous state-of-the-art results on GEC benchmarks in four languages: English, Czech, German and Russian. Having established a new set of baselines for GEC, we make our results easily reproducible and accessible by releasing a cLang-8 dataset. It is produced by using our best model, which we call gT5, to clean the targets of a widely used yet noisy lang-8 dataset. cLang-8 greatly simplifies typical GEC training pipelines composed of multiple fine-tuning stages -- we demonstrate that performing a single fine-tuning step on cLang-8 with the off-the-shelf language models yields further accuracy improvements over an already top-performing gT5 model for English.
Focus Attention: Promoting Faithfulness and Diversity in Summarization
May 25, 2021

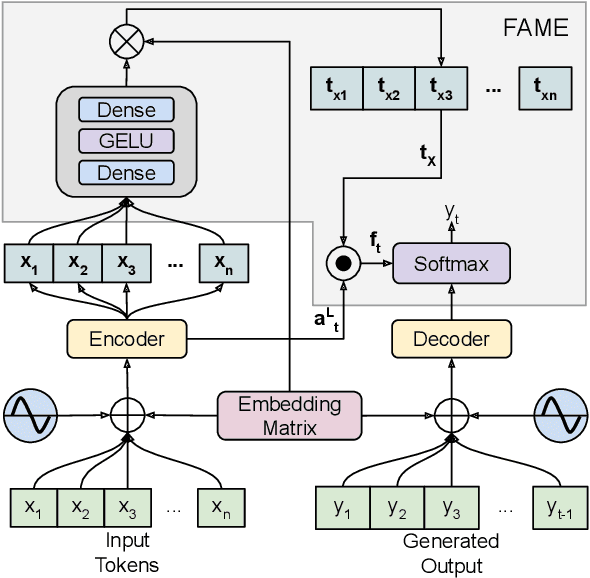
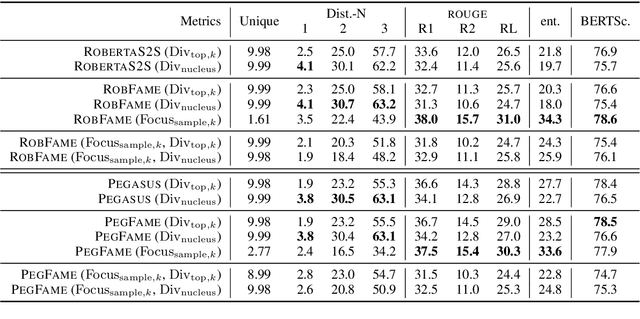
Professional summaries are written with document-level information, such as the theme of the document, in mind. This is in contrast with most seq2seq decoders which simultaneously learn to focus on salient content, while deciding what to generate, at each decoding step. With the motivation to narrow this gap, we introduce Focus Attention Mechanism, a simple yet effective method to encourage decoders to proactively generate tokens that are similar or topical to the input document. Further, we propose a Focus Sampling method to enable generation of diverse summaries, an area currently understudied in summarization. When evaluated on the BBC extreme summarization task, two state-of-the-art models augmented with Focus Attention generate summaries that are closer to the target and more faithful to their input documents, outperforming their vanilla counterparts on \rouge and multiple faithfulness measures. We also empirically demonstrate that Focus Sampling is more effective in generating diverse and faithful summaries than top-$k$ or nucleus sampling-based decoding methods.
Unsupervised Text Style Transfer with Padded Masked Language Models
Oct 02, 2020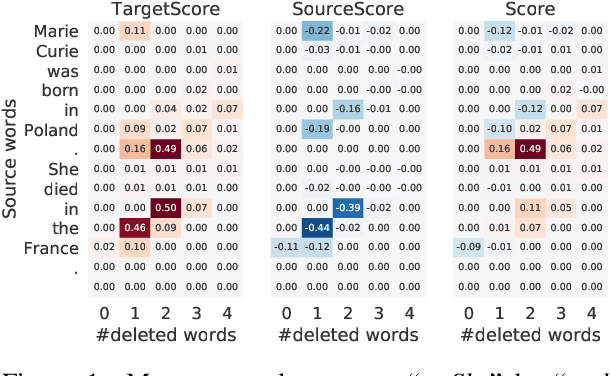
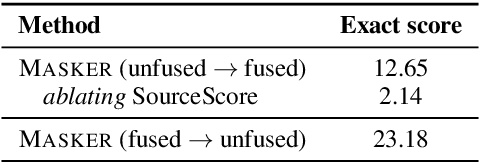
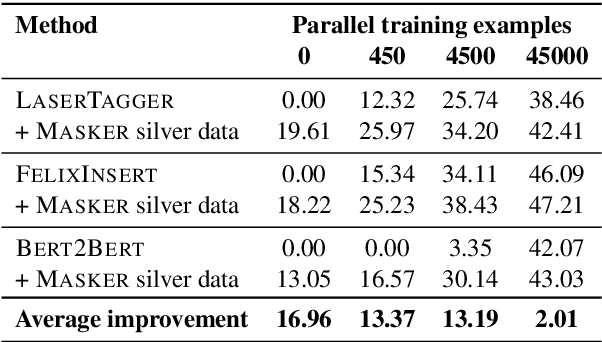
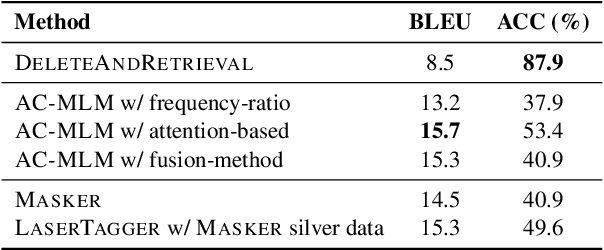
We propose Masker, an unsupervised text-editing method for style transfer. To tackle cases when no parallel source-target pairs are available, we train masked language models (MLMs) for both the source and the target domain. Then we find the text spans where the two models disagree the most in terms of likelihood. This allows us to identify the source tokens to delete to transform the source text to match the style of the target domain. The deleted tokens are replaced with the target MLM, and by using a padded MLM variant, we avoid having to predetermine the number of inserted tokens. Our experiments on sentence fusion and sentiment transfer demonstrate that Masker performs competitively in a fully unsupervised setting. Moreover, in low-resource settings, it improves supervised methods' accuracy by over 10 percentage points when pre-training them on silver training data generated by Masker.
A Generative Approach to Titling and Clustering Wikipedia Sections
May 22, 2020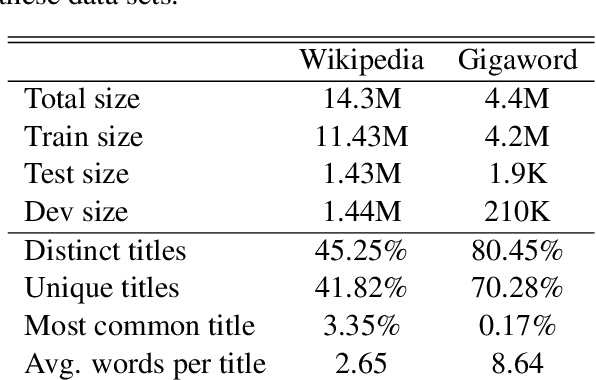
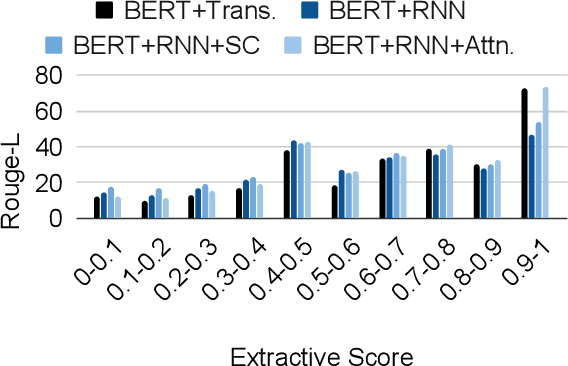
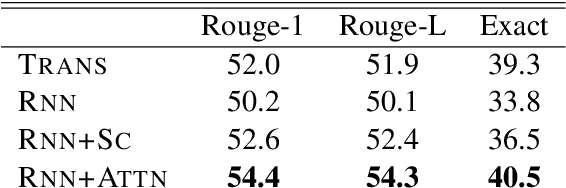
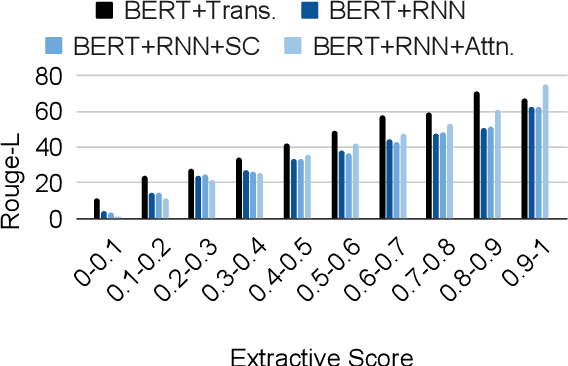
We evaluate the performance of transformer encoders with various decoders for information organization through a new task: generation of section headings for Wikipedia articles. Our analysis shows that decoders containing attention mechanisms over the encoder output achieve high-scoring results by generating extractive text. In contrast, a decoder without attention better facilitates semantic encoding and can be used to generate section embeddings. We additionally introduce a new loss function, which further encourages the decoder to generate high-quality embeddings.
Encode, Tag, Realize: High-Precision Text Editing
Sep 03, 2019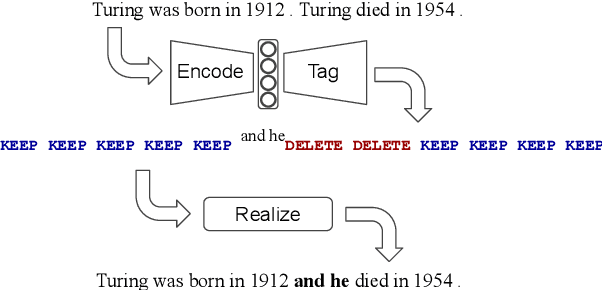

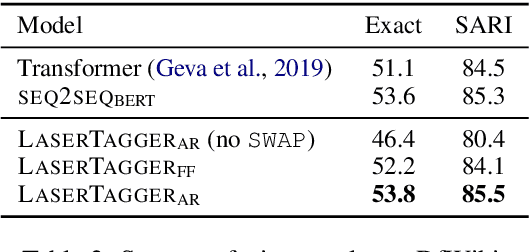
We propose LaserTagger - a sequence tagging approach that casts text generation as a text editing task. Target texts are reconstructed from the inputs using three main edit operations: keeping a token, deleting it, and adding a phrase before the token. To predict the edit operations, we propose a novel model, which combines a BERT encoder with an autoregressive Transformer decoder. This approach is evaluated on English text on four tasks: sentence fusion, sentence splitting, abstractive summarization, and grammar correction. LaserTagger achieves new state-of-the-art results on three of these tasks, performs comparably to a set of strong seq2seq baselines with a large number of training examples, and outperforms them when the number of examples is limited. Furthermore, we show that at inference time tagging can be more than two orders of magnitude faster than comparable seq2seq models, making it more attractive for running in a live environment.
Leveraging Pre-trained Checkpoints for Sequence Generation Tasks
Jul 29, 2019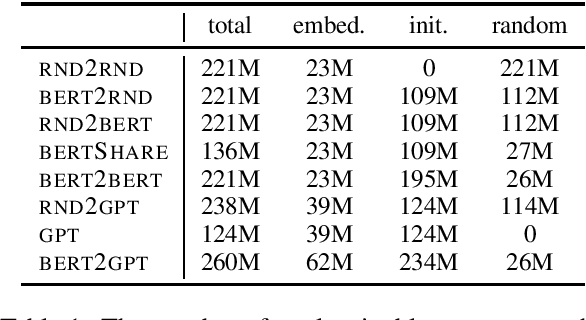
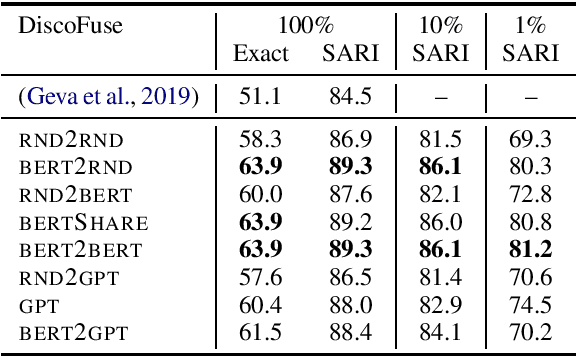
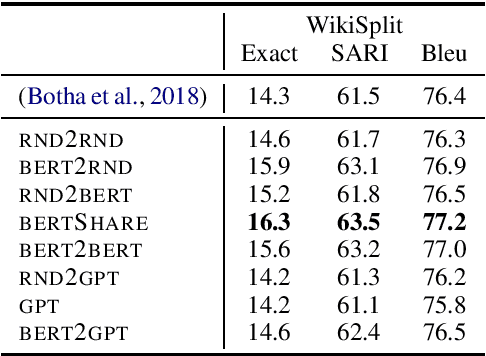
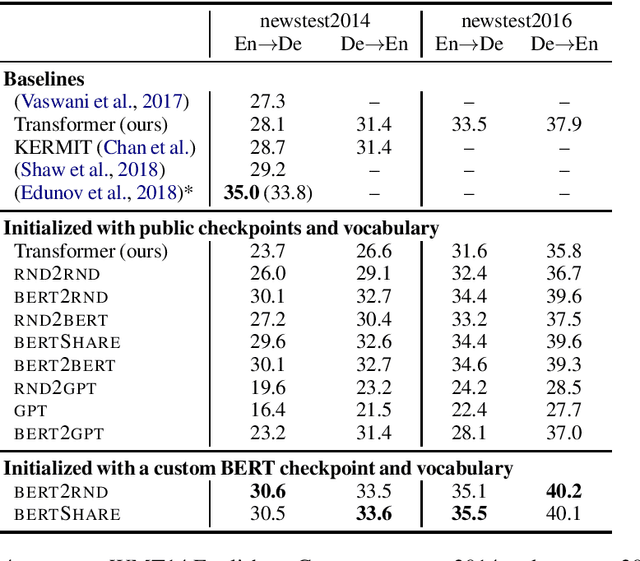
Unsupervised pre-training of large neural models has recently revolutionized Natural Language Processing. Warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language Understanding tasks. In this paper, we present an extensive empirical study on the utility of initializing large Transformer-based sequence-to-sequence models with the publicly available pre-trained BERT and GPT-2 checkpoints for sequence generation. We have run over 300 experiments spending thousands of TPU hours to find the recipe that works best and demonstrate that it results in new state-of-the-art results on Machine Translation, Summarization, Sentence Splitting and Sentence Fusion.