 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D-CTC for Scene Text Recognition
Jul 23, 2019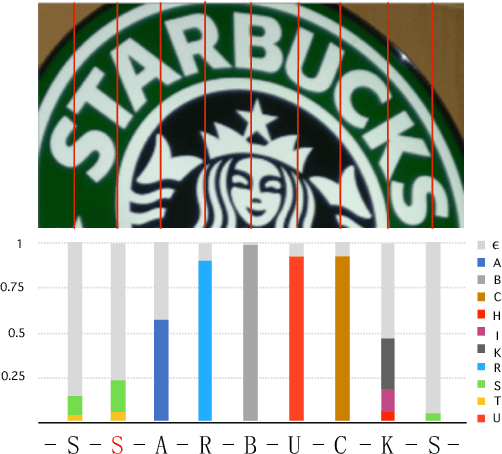
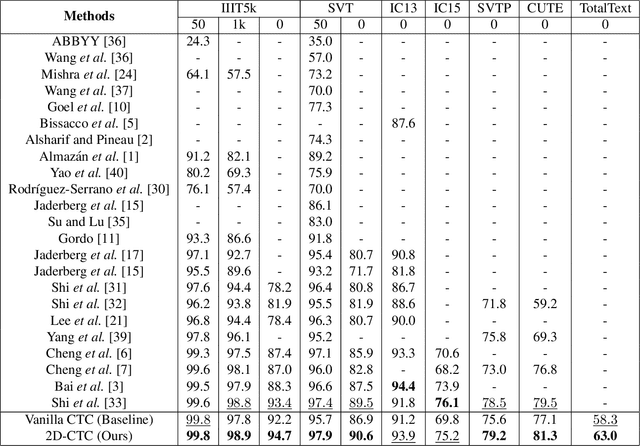
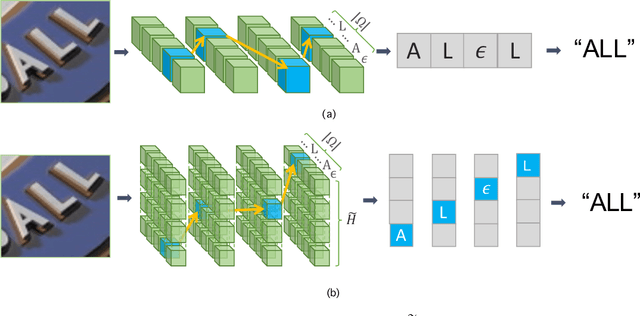

Scene text recognition has been an important, active research topic in computer vision for years. Previous approaches mainly consider text as 1D signals and cast scene text recognition as a sequence prediction problem, by feat of CTC or attention based encoder-decoder framework, which is originally designed for speech recognition. However, different from speech voices, which are 1D signals, text instances are essentially distributed in 2D image spaces. To adhere to and make use of the 2D nature of text for higher recognition accuracy, we extend the vanilla CTC model to a second dimension, thus creating 2D-CTC. 2D-CTC can adaptively concentrate on most relevant features while excluding the impact from clutters and noises in the background; It can also naturally handle text instances with various forms (horizontal, oriented and curved) while giving more interpretable intermediate predictions. The experiments on standard benchmarks for scene text recognition, such as IIIT-5K, ICDAR 2015, SVP-Perspective, and CUTE80, demonstrate that the proposed 2D-CTC model outperforms state-of-the-art methods on the text of both regular and irregular shapes. Moreover, 2D-CTC exhibits its superiority over prior art on training and testing speed. Our implementation and models of 2D-CTC will be made publicly available soon later.
SynthText3D: Synthesizing Scene Text Images from 3D Virtual Worlds
Jul 13, 2019
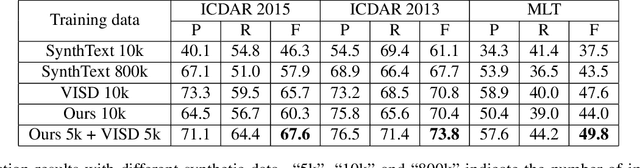
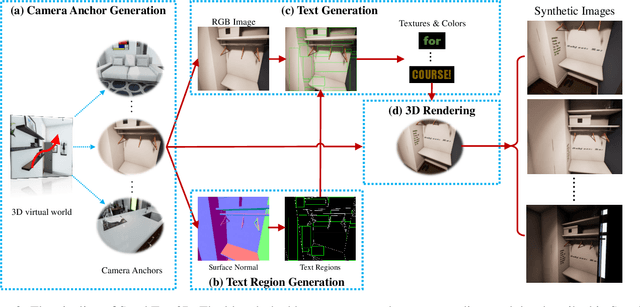
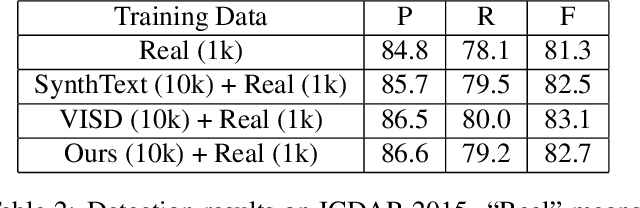
With the development of deep neural networks, the demand for a significant amount of annotated training data becomes the performance bottlenecks in many fields of research and applications. Image synthesis can generate annotated images automatically and freely, which gains increasing attention recently. In this paper, we propose to synthesize scene text images from the 3D virtual worlds, where the precise descriptions of scenes, editable illumination/visibility, and realistic physics are provided. Different from the previous methods which paste the rendered text on static 2D images, our method can render the 3D virtual scene and text instances as an entirety. In this way, complex perspective transforms, various illuminations, and occlusions can be realized in our synthesized scene text images. Moreover, the same text instances with various viewpoints can be produced by randomly moving and rotating the virtual camera, which acts as human eyes. The experiments on the standard scene text detection benchmarks using the generated synthetic data demonstrate the effectiveness and superiority of the proposed method. The code and synthetic data will be made available at https://github.com/MhLiao/SynthText3D
Intra-Ensemble in Neural Networks
Apr 09, 2019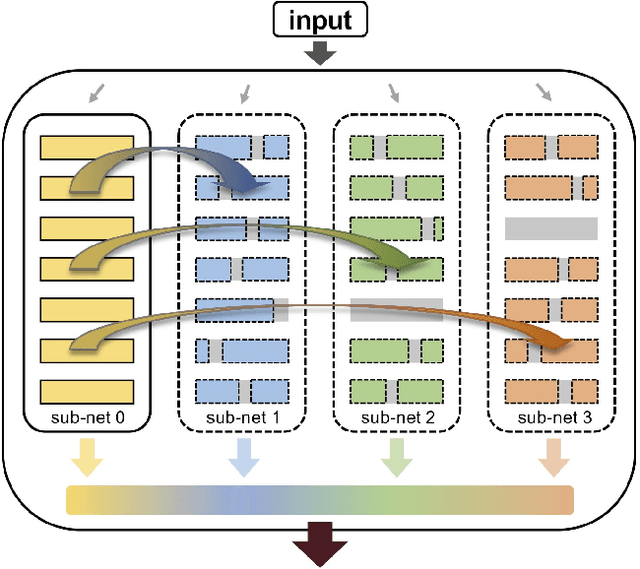
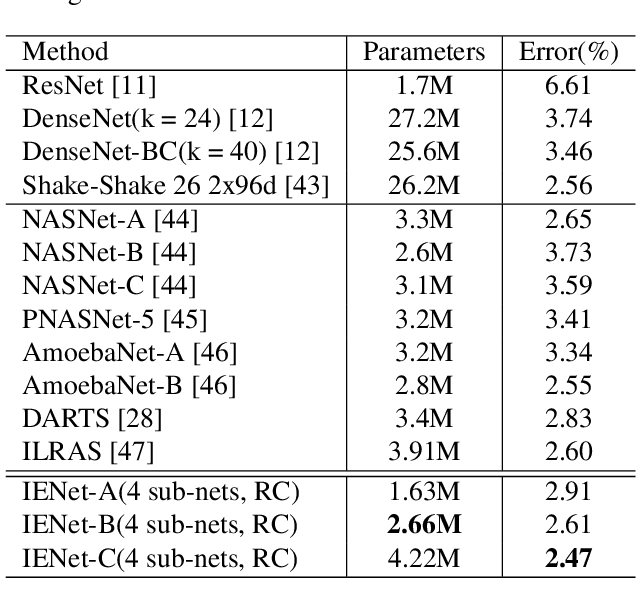
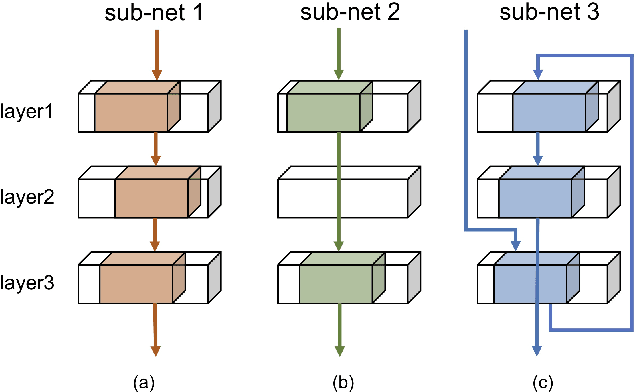
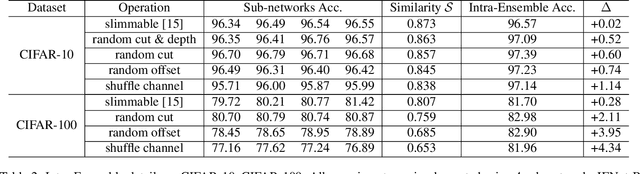
Improving model performance is always the key problem in machine learning including deep learning. However, stand-alone neural networks always suffer from marginal effect when stacking more layers. At the same time, ensemble is a useful technique to further enhance model performance. Nevertheless, training several independent stand-alone deep neural networks costs multiple resources. In this work, we propose Intra-Ensemble, an end-to-end strategy with stochastic training operations to train several sub-networks simultaneously within one neural network. Additional parameter size is marginal since the majority of parameters are mutually shared. Meanwhile, stochastic training increases the diversity of sub-networks with weight sharing, which significantly enhances intra-ensemble performance. Extensive experiments prove the applicability of intra-ensemble on various kinds of datasets and network architectures. Our models achieve comparable results with the state-of-the-art architectures on CIFAR-10 and CIFAR-100.
Scene Text Detection and Recognition: The Deep Learning Era
Dec 06, 2018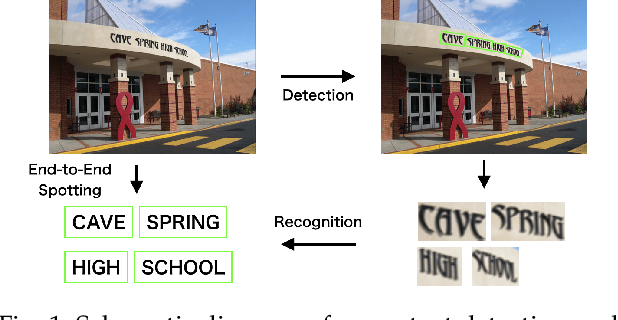
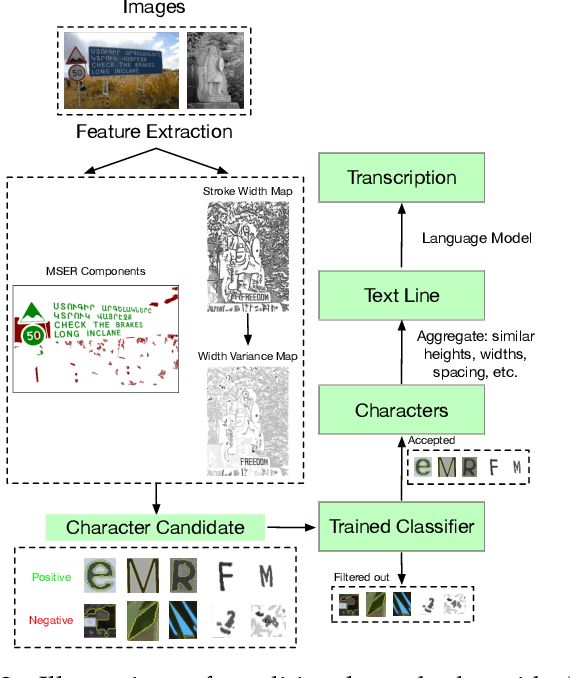
With the rise and development of deep learning, computer vision has been tremendously transformed and reshaped. As an important research area in computer vision, scene text detection and recognition has been inescapably influenced by this wave of revolution, consequentially entering the era of deep learning. In recent years, the community has witnessed substantial advancements in mindset, approach and performance. This survey is aimed at summarizing and analyzing the major changes and significant progresses of scene text detection and recognition in the deep learning era. Through this article, we devote to: (1) introduce new insights and ideas; (2) highlight recent techniques and benchmarks; (3) look ahead into future trends. Specifically, we will emphasize the dramatic differences brought by deep learning and the grand challenges still remained. We expect that this review paper would serve as a reference book for researchers in this field. Related resources are also collected and compiled in our Github repository: https://github.com/Jyouhou/SceneTextPapers.
Scene Text Detection with Supervised Pyramid Context Network
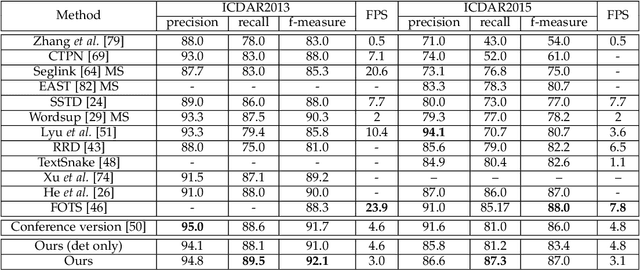
Nov 21, 2018
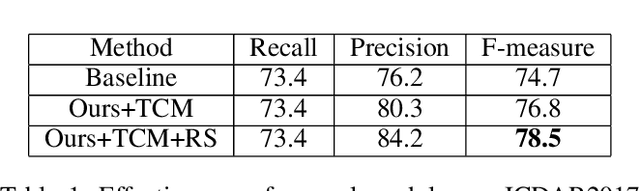
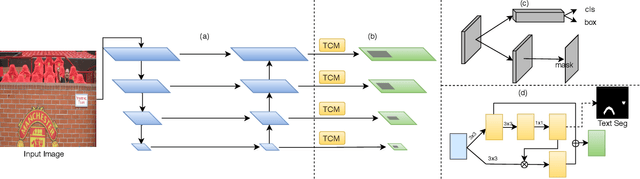
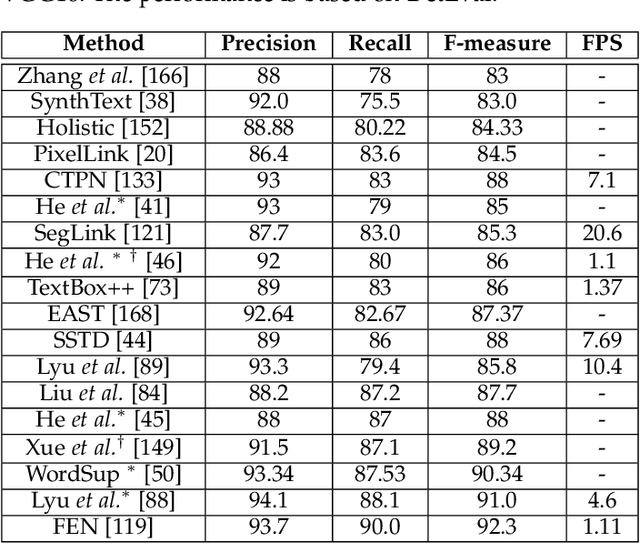
Scene text detection methods based on deep learning have achieved remarkable results over the past years. However, due to the high diversity and complexity of natural scenes, previous state-of-the-art text detection methods may still produce a considerable amount of false positives, when applied to images captured in real-world environments. To tackle this issue, mainly inspired by Mask R-CNN, we propose in this paper an effective model for scene text detection, which is based on Feature Pyramid Network (FPN) and instance segmentation. We propose a supervised pyramid context network (SPCNET) to precisely locate text regions while suppressing false positives. Benefited from the guidance of semantic information and sharing FPN, SPCNET obtains significantly enhanced performance while introducing marginal extra computation. Experiments on standard datasets demonstrate that our SPCNET clearly outperforms start-of-the-art methods. Specifically, it achieves an F-measure of 92.1% on ICDAR2013, 87.2% on ICDAR2015, 74.1% on ICDAR2017 MLT and 82.9% on Total-Text.
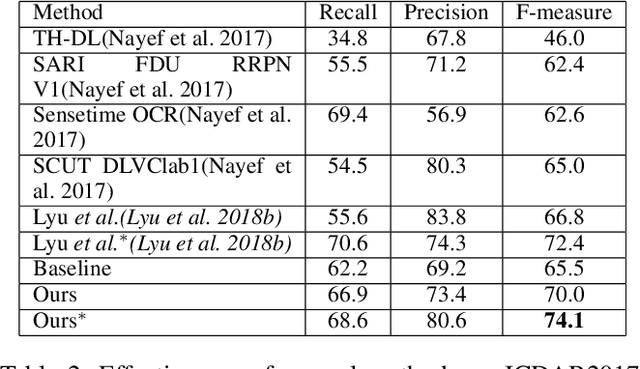
ICDAR2017 Competition on Reading Chinese Text in the Wild (RCTW-17)
Sep 26, 2018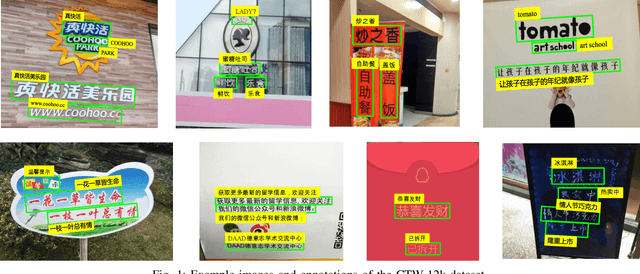
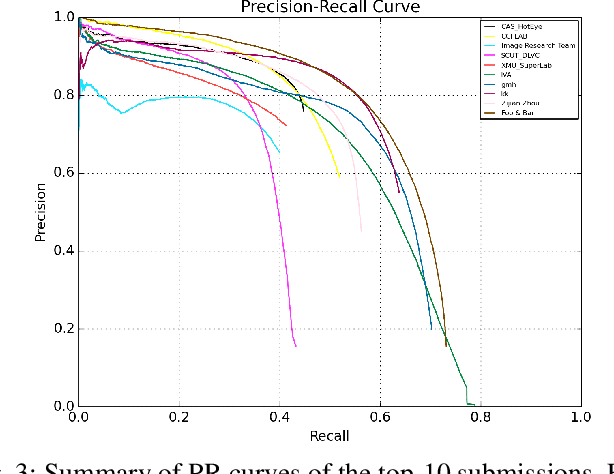

Chinese is the most widely used language in the world. Algorithms that read Chinese text in natural images facilitate applications of various kinds. Despite the large potential value, datasets and competitions in the past primarily focus on English, which bares very different characteristics than Chinese. This report introduces RCTW, a new competition that focuses on Chinese text reading. The competition features a large-scale dataset with 12,263 annotated images. Two tasks, namely text localization and end-to-end recognition, are set up. The competition took place from January 20 to May 31, 2017. 23 valid submissions were received from 19 teams. This report includes dataset description, task definitions, evaluation protocols, and results summaries and analysis. Through this competition, we call for more future research on the Chinese text reading problem. The official website for the competition is http://rctw.vlrlab.net
Scene Text Recognition from Two-Dimensional Perspective
Sep 18, 2018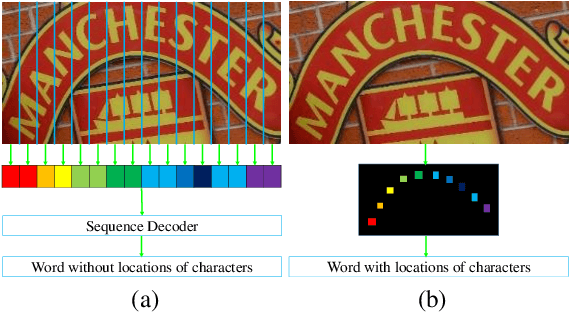
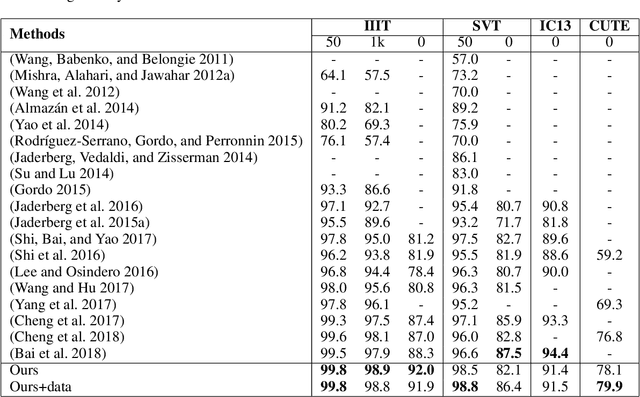
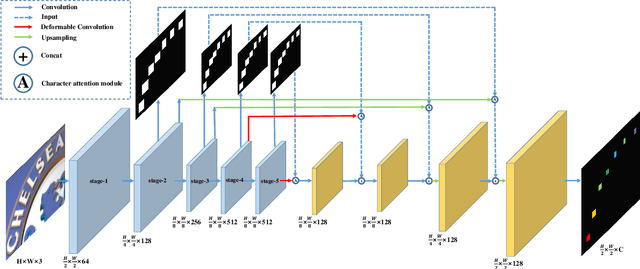

Inspired by speech recognition, recent state-of-the-art algorithms mostly consider scene text recognition as a sequence prediction problem. Though achieving excellent performance, these methods usually neglect an important fact that text in images are actually distributed in two-dimensional space. It is a nature quite different from that of speech, which is essentially a one-dimensional signal. In principle, directly compressing features of text into a one-dimensional form may lose useful information and introduce extra noise. In this paper, we approach scene text recognition from a two-dimensional perspective. A simple yet effective model, called Character Attention Fully Convolutional Network (CA-FCN), is devised for recognizing text of arbitrary shapes. Scene text recognition is realized with a semantic segmentation network, where an attention mechanism for characters is adopted. Combined with a word formation module, CA-FCN can simultaneously recognize the script and predict the position of each character. Experiments demonstrate that the proposed algorithm outperforms previous methods on both regular and irregular text datasets. Moreover, it is proven to be more robust to imprecise localizations in the text detection phase, which are very common in practice.
Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
Aug 01, 2018
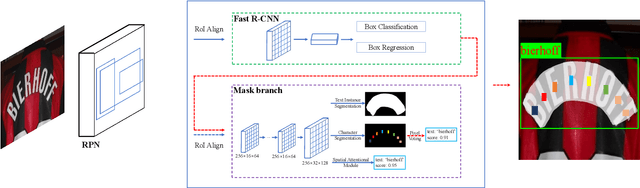
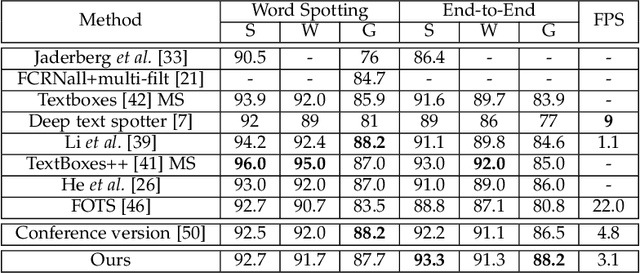
Recently, models based on deep neural networks have dominated the fields of scene text detection and recognition. In this paper, we investigate the problem of scene text spotting, which aims at simultaneous text detection and recognition in natural images. An end-to-end trainable neural network model for scene text spotting is proposed. The proposed model, named as Mask TextSpotter, is inspired by the newly published work Mask R-CNN. Different from previous methods that also accomplish text spotting with end-to-end trainable deep neural networks, Mask TextSpotter takes advantage of simple and smooth end-to-end learning procedure, in which precise text detection and recognition are acquired via semantic segmentation. Moreover, it is superior to previous methods in handling text instances of irregular shapes, for example, curved text. Experiments on ICDAR2013, ICDAR2015 and Total-Text demonstrate that the proposed method achieves state-of-the-art results in both scene text detection and end-to-end text recognition tasks.
TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes
Jul 04, 2018
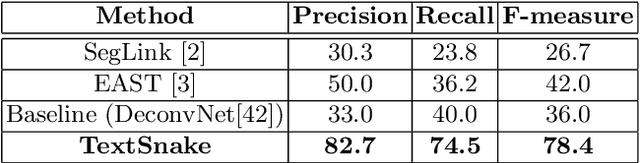
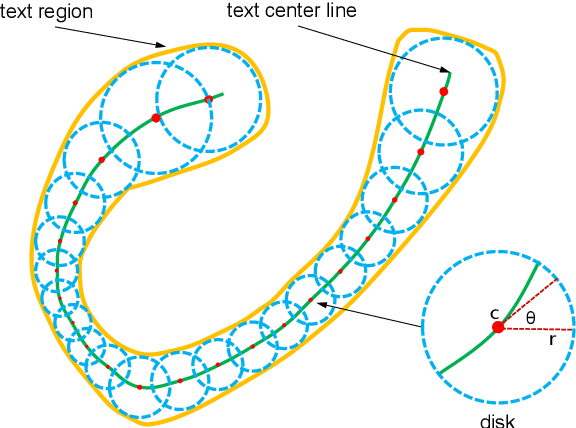
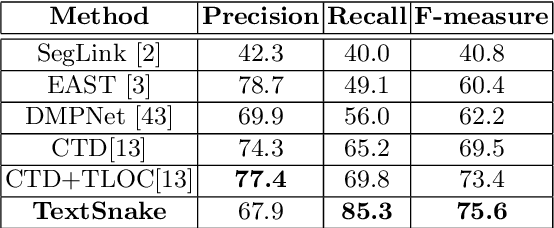
Driven by deep neural networks and large scale datasets, scene text detection methods have progressed substantially over the past years, continuously refreshing the performance records on various standard benchmarks. However, limited by the representations (axis-aligned rectangles, rotated rectangles or quadrangles) adopted to describe text, existing methods may fall short when dealing with much more free-form text instances, such as curved text, which are actually very common in real-world scenarios. To tackle this problem, we propose a more flexible representation for scene text, termed as TextSnake, which is able to effectively represent text instances in horizontal, oriented and curved forms. In TextSnake, a text instance is described as a sequence of ordered, overlapping disks centered at symmetric axes, each of which is associated with potentially variable radius and orientation. Such geometry attributes are estimated via a Fully Convolutional Network (FCN) model. In experiments, the text detector based on TextSnake achieves state-of-the-art or comparable performance on Total-Text and SCUT-CTW1500, the two newly published benchmarks with special emphasis on curved text in natural images, as well as the widely-used datasets ICDAR 2015 and MSRA-TD500. Specifically, TextSnake outperforms the baseline on Total-Text by more than 40% in F-measure.
Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
Feb 27, 2018
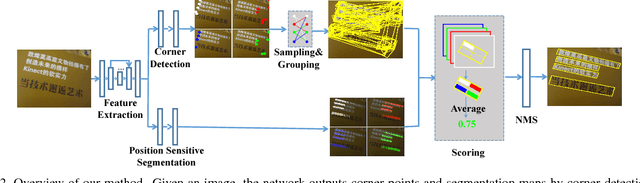
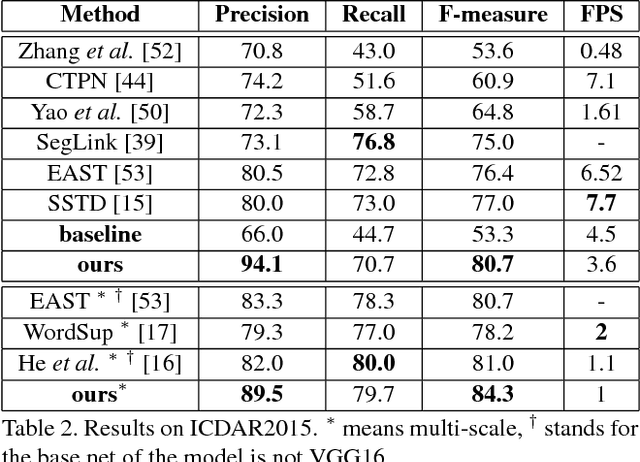
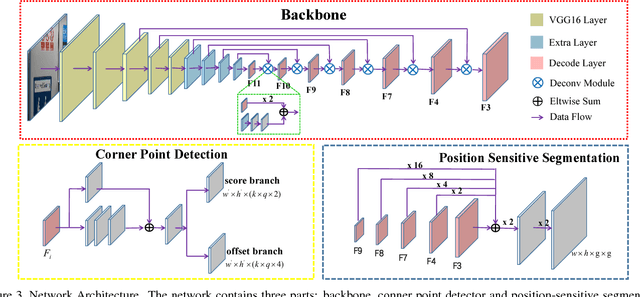
Previous deep learning based state-of-the-art scene text detection methods can be roughly classified into two categories. The first category treats scene text as a type of general objects and follows general object detection paradigm to localize scene text by regressing the text box locations, but troubled by the arbitrary-orientation and large aspect ratios of scene text. The second one segments text regions directly, but mostly needs complex post processing. In this paper, we present a method that combines the ideas of the two types of methods while avoiding their shortcomings. We propose to detect scene text by localizing corner points of text bounding boxes and segmenting text regions in relative positions. In inference stage, candidate boxes are generated by sampling and grouping corner points, which are further scored by segmentation maps and suppressed by NMS. Compared with previous methods, our method can handle long oriented text naturally and doesn't need complex post processing. The experiments on ICDAR2013, ICDAR2015, MSRA-TD500, MLT and COCO-Text demonstrate that the proposed algorithm achieves better or comparable results in both accuracy and efficiency. Based on VGG16, it achieves an F-measure of 84.3% on ICDAR2015 and 81.5% on MSRA-TD500.