 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthText3D: Synthesizing Scene Text Images from 3D Virtual Worlds
Jul 13, 2019
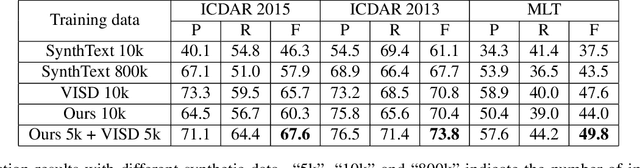
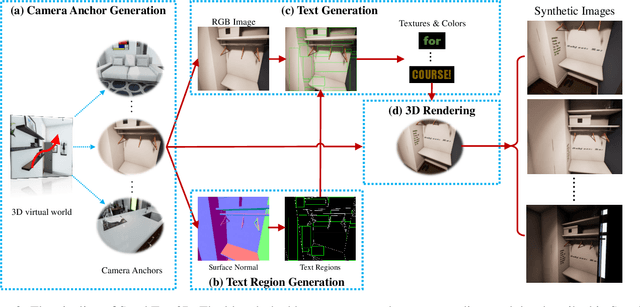
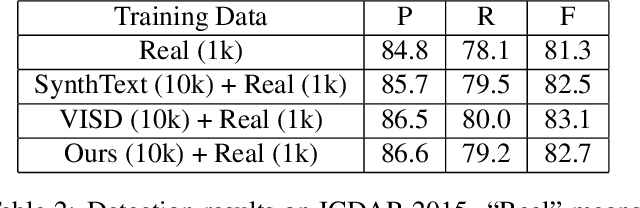
With the development of deep neural networks, the demand for a significant amount of annotated training data becomes the performance bottlenecks in many fields of research and applications. Image synthesis can generate annotated images automatically and freely, which gains increasing attention recently. In this paper, we propose to synthesize scene text images from the 3D virtual worlds, where the precise descriptions of scenes, editable illumination/visibility, and realistic physics are provided. Different from the previous methods which paste the rendered text on static 2D images, our method can render the 3D virtual scene and text instances as an entirety. In this way, complex perspective transforms, various illuminations, and occlusions can be realized in our synthesized scene text images. Moreover, the same text instances with various viewpoints can be produced by randomly moving and rotating the virtual camera, which acts as human eyes. The experiments on the standard scene text detection benchmarks using the generated synthetic data demonstrate the effectiveness and superiority of the proposed method. The code and synthetic data will be made available at https://github.com/MhLiao/SynthText3D