 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLBS: Loss-aware Bit Sharing for Automatic Model Compression
Feb 15, 2021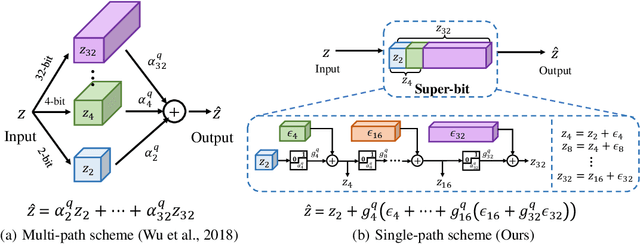
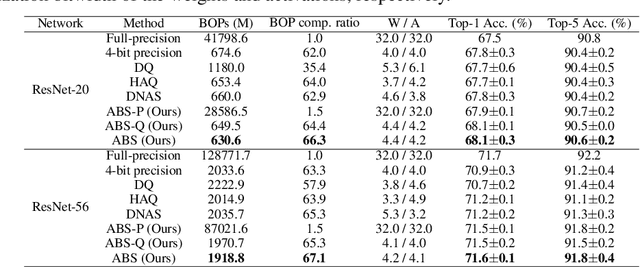
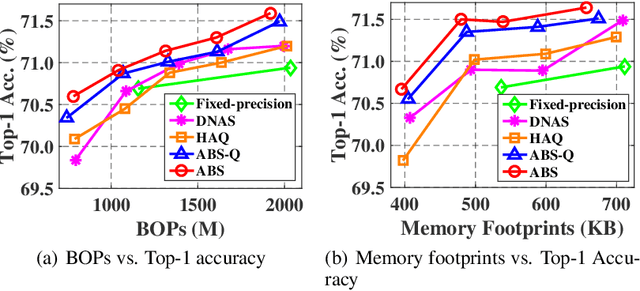
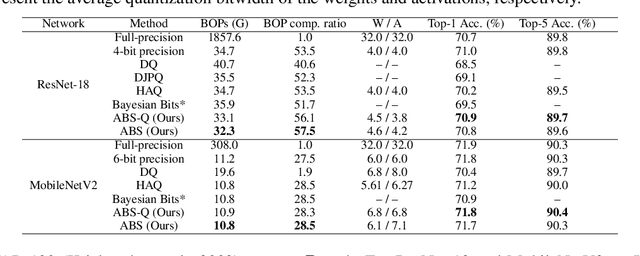
Low-bitwidth model compression is an effective method to reduce the model size and computational overhead. Existing compression methods rely on some compression configurations (such as pruning rates, and/or bitwidths), which are often determined manually and not optimal. Some attempts have been made to search them automatically, but the optimization process is often very expensive. To alleviate this, we devise a simple yet effective method named Loss-aware Bit Sharing (LBS) to automatically search for optimal model compression configurations. To this end, we propose a novel single-path model to encode all candidate compression configurations, where a high bitwidth quantized value can be decomposed into the sum of the lowest bitwidth quantized value and a series of re-assignment offsets. We then introduce learnable binary gates to encode the choice of bitwidth, including filter-wise 0-bit for filter pruning. By jointly training the binary gates in conjunction with network parameters, the compression configurations of each layer can be automatically determined. Extensive experiments on both CIFAR-100 and ImageNet show that LBS is able to significantly reduce computational cost while preserving promising performance.
Instance and Panoptic Segmentation Using Conditional Convolutions
Feb 11, 2021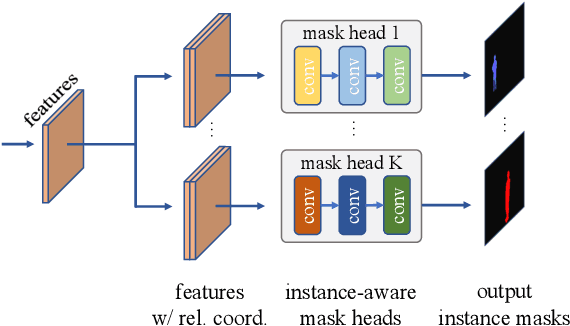


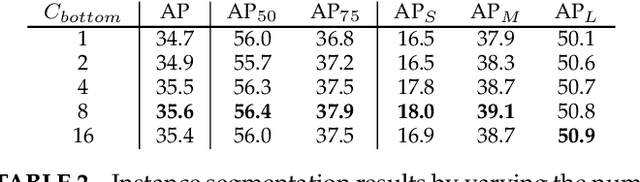
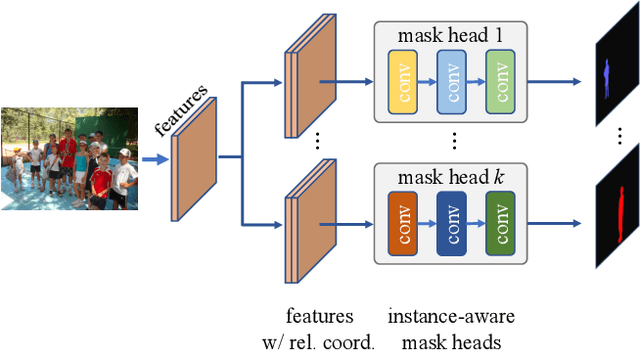
We propose a simple yet effective framework for instance and panoptic segmentation, termed CondInst (conditional convolutions for instance and panoptic segmentation). In the literature, top-performing instance segmentation methods typically follow the paradigm of Mask R-CNN and rely on ROI operations (typically ROIAlign) to attend to each instance. In contrast, we propose to attend to the instances with dynamic conditional convolutions. Instead of using instance-wise ROIs as inputs to the instance mask head of fixed weights, we design dynamic instance-aware mask heads, conditioned on the instances to be predicted. CondInst enjoys three advantages: 1.) Instance and panoptic segmentation are unified into a fully convolutional network, eliminating the need for ROI cropping and feature alignment. 2.) The elimination of the ROI cropping also significantly improves the output instance mask resolution. 3.) Due to the much improved capacity of dynamically-generated conditional convolutions, the mask head can be very compact (e.g., 3 conv. layers, each having only 8 channels), leading to significantly faster inference time per instance and making the overall inference time almost constant, irrelevant to the number of instances. We demonstrate a simpler method that can achieve improved accuracy and inference speed on both instance and panoptic segmentation tasks. On the COCO dataset, we outperform a few state-of-the-art methods. We hope that CondInst can be a strong baseline for instance and panoptic segmentation. Code is available at: https://git.io/AdelaiDet
Multi-intersection Traffic Optimisation: A Benchmark Dataset and a Strong Baseline
Jan 24, 2021
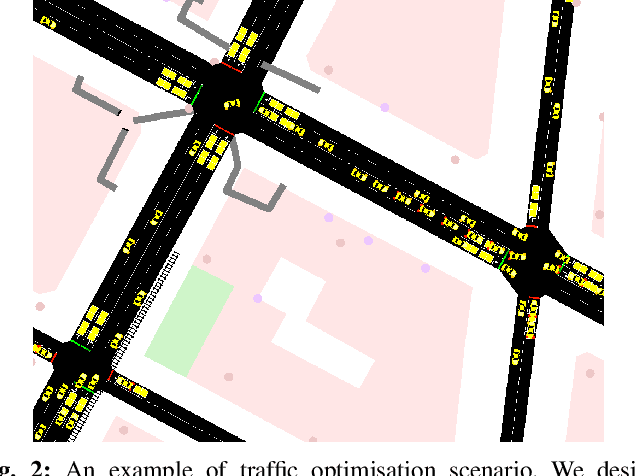
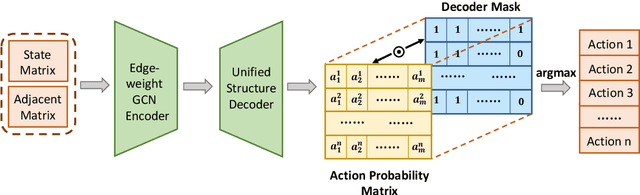
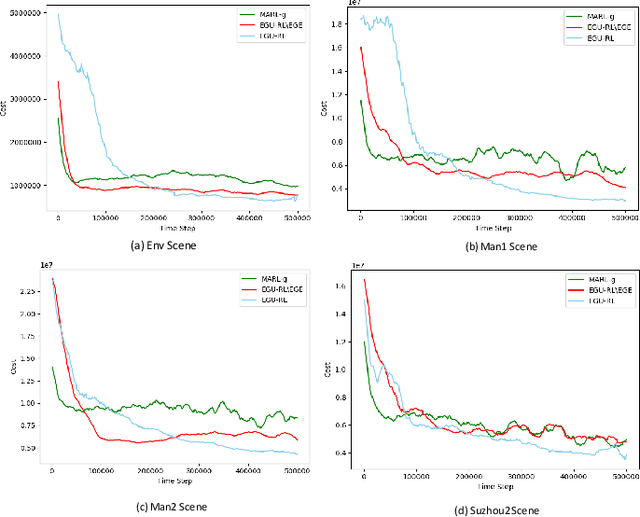
The control of traffic signals is fundamental and critical to alleviate traffic congestion in urban areas. However, it is challenging since traffic dynamics are complicated in real situations. Because of the high complexity of modelling the optimisation problem, experimental settings of current works are often inconsistent. Moreover, it is not trivial to control multiple intersections properly in real complex traffic scenarios due to its vast state and action space. Failing to take intersection topology relations into account also results in inferior traffic condition. To address these issues, in this work we carefully design our settings and propose new data including both synthetic and real traffic data in more complex scenarios. Additionally, we propose a novel and strong baseline model based on deep reinforcement learning with the encoder-decoder structure: an edge-weighted graph convolutional encoder to excavate multi-intersection relations; and a unified structure decoder to jointly model multiple junctions in a comprehensive manner, which significantly reduces the number of the model parameters. By doing so, the proposed model is able to effectively deal with multi-intersection traffic optimisation problems. Models have been trained and tested on both synthetic and real maps and traffic data with the Simulation of Urban Mobility (SUMO) simulator. Experimental results show that the proposed model surpasses existing methods in the literature.
Memory-Efficient Hierarchical Neural Architecture Search for Image Restoration
Dec 28, 2020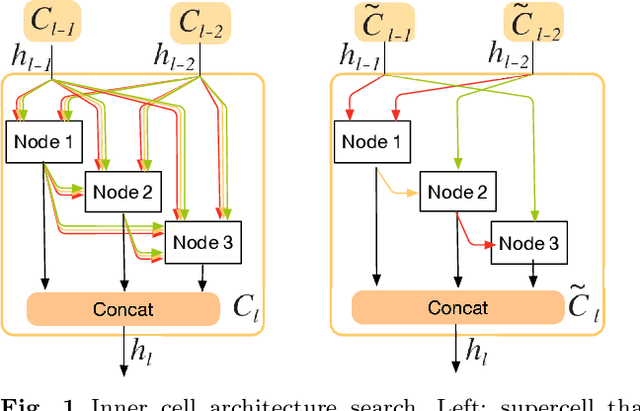

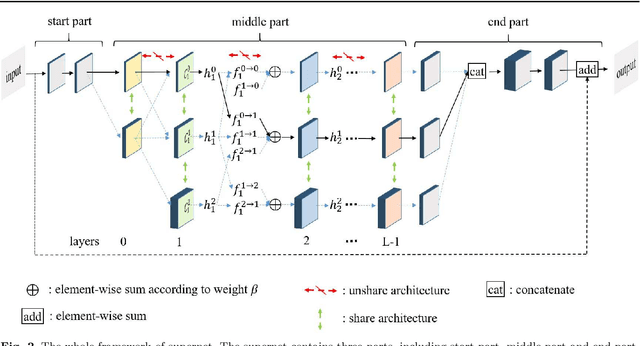

Recently, much attention has been spent on neural architecture search (NAS) approaches, which often outperform manually designed architectures on highlevel vision tasks. Inspired by this, we attempt to leverage NAS technique to automatically design efficient network architectures for low-level image restoration tasks. In this paper, we propose a memory-efficient hierarchical NAS HiNAS (HiNAS) and apply to two such tasks: image denoising and image super-resolution. HiNAS adopts gradient based search strategies and builds an flexible hierarchical search space, including inner search space and outer search space, which in charge of designing cell architectures and deciding cell widths, respectively. For inner search space, we propose layerwise architecture sharing strategy (LWAS), resulting in more flexible architectures and better performance. For outer search space, we propose cell sharing strategy to save memory, and considerably accelerate the search speed. The proposed HiNAS is both memory and computation efficient. With a single GTX1080Ti GPU, it takes only about 1 hour for searching for denoising network on BSD 500 and 3.5 hours for searching for the super-resolution structure on DIV2K. Experimental results show that the architectures found by HiNAS have fewer parameters and enjoy a faster inference speed, while achieving highly competitive performance compared with state-of-the-art methods.
Diverse Knowledge Distillation for End-to-End Person Search
Dec 21, 2020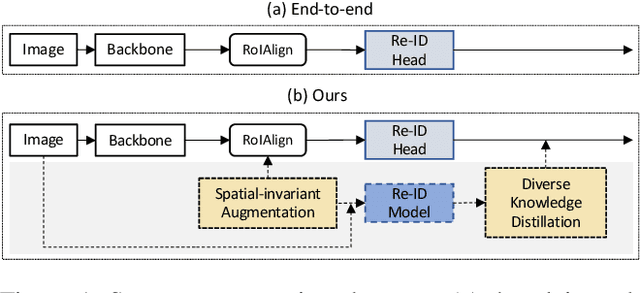
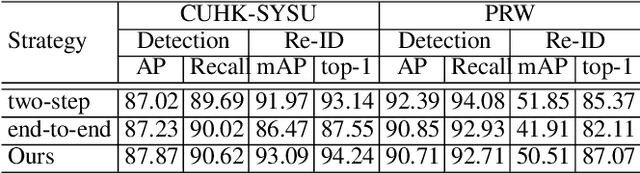
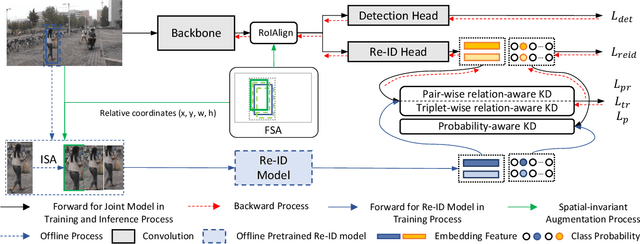
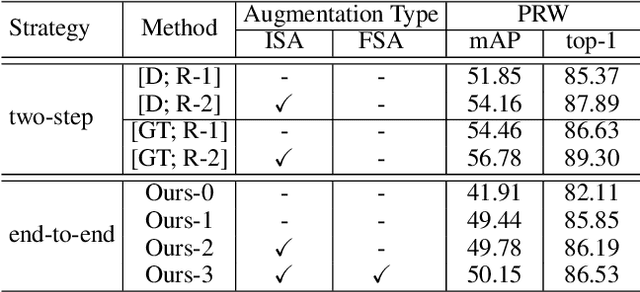
Person search aims to localize and identify a specific person from a gallery of images. Recent methods can be categorized into two groups, i.e., two-step and end-to-end approaches. The former views person search as two independent tasks and achieves dominant results using separately trained person detection and re-identification (Re-ID) models. The latter performs person search in an end-to-end fashion. Although the end-to-end approaches yield higher inference efficiency, they largely lag behind those two-step counterparts in terms of accuracy. In this paper, we argue that the gap between the two kinds of methods is mainly caused by the Re-ID sub-networks of end-to-end methods. To this end, we propose a simple yet strong end-to-end network with diverse knowledge distillation to break the bottleneck. We also design a spatial-invariant augmentation to assist model to be invariant to inaccurate detection results. Experimental results on the CUHK-SYSU and PRW datasets demonstrate the superiority of our method against existing approaches -- it achieves on par accuracy with state-of-the-art two-step methods while maintaining high efficiency due to the single joint model. Code is available at: https://git.io/DKD-PersonSearch.
Learning to Recover 3D Scene Shape from a Single Image
Dec 17, 2020
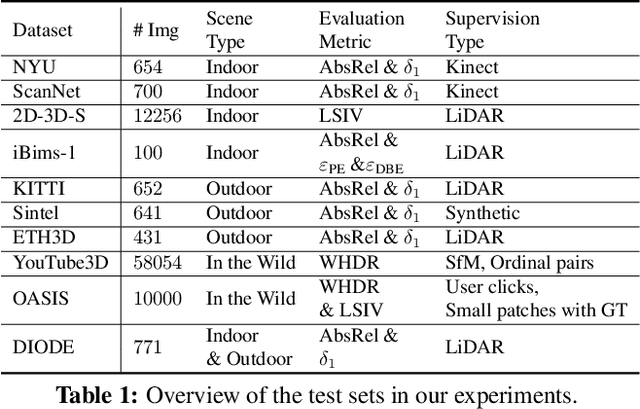
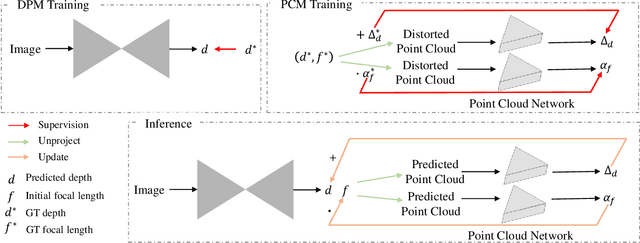
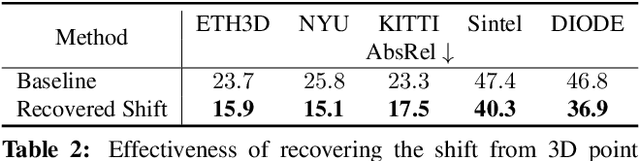
Despite significant progress in monocular depth estimation in the wild, recent state-of-the-art methods cannot be used to recover accurate 3D scene shape due to an unknown depth shift induced by shift-invariant reconstruction losses used in mixed-data depth prediction training, and possible unknown camera focal length. We investigate this problem in detail, and propose a two-stage framework that first predicts depth up to an unknown scale and shift from a single monocular image, and then use 3D point cloud encoders to predict the missing depth shift and focal length that allow us to recover a realistic 3D scene shape. In addition, we propose an image-level normalized regression loss and a normal-based geometry loss to enhance depth prediction models trained on mixed datasets. We test our depth model on nine unseen datasets and achieve state-of-the-art performance on zero-shot dataset generalization. Code is available at: https://git.io/Depth
Hyperspectral Classification Based on Lightweight 3-D-CNN With Transfer Learning
Dec 07, 2020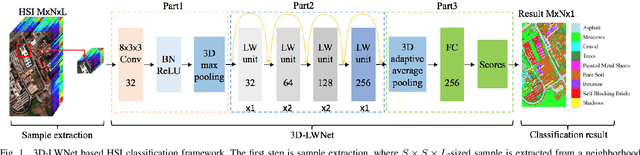
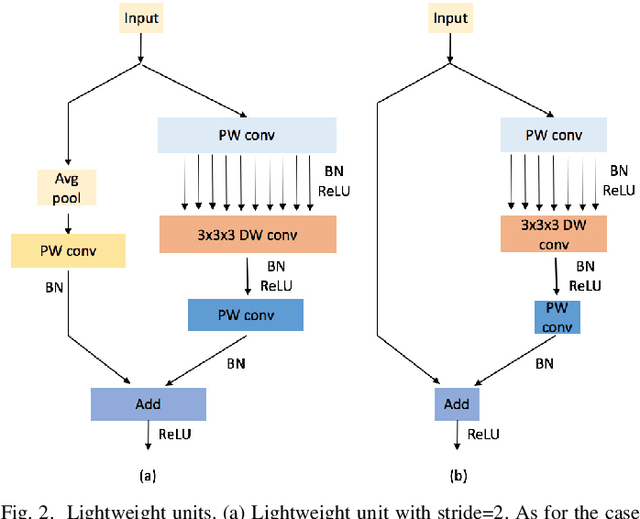
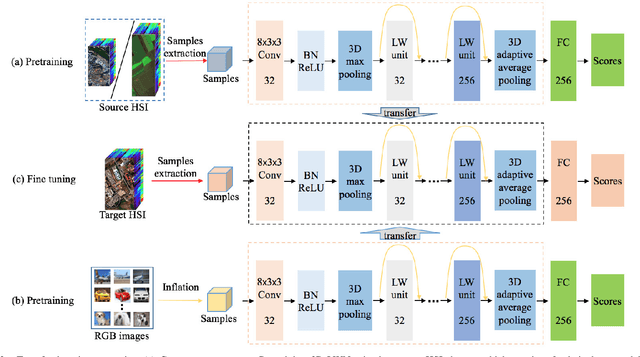
Recently, hyperspectral image (HSI) classification approaches based on deep learning (DL) models have been proposed and shown promising performance. However, because of very limited available training samples and massive model parameters, DL methods may suffer from overfitting. In this paper, we propose an end-to-end 3-D lightweight convolutional neural network (CNN) (abbreviated as 3-D-LWNet) for limited samples-based HSI classification. Compared with conventional 3-D-CNN models, the proposed 3-D-LWNet has a deeper network structure, less parameters, and lower computation cost, resulting in better classification performance. To further alleviate the small sample problem, we also propose two transfer learning strategies: 1) cross-sensor strategy, in which we pretrain a 3-D model in the source HSI data sets containing a greater number of labeled samples and then transfer it to the target HSI data sets and 2) cross-modal strategy, in which we pretrain a 3-D model in the 2-D RGB image data sets containing a large number of samples and then transfer it to the target HSI data sets. In contrast to previous approaches, we do not impose restrictions over the source data sets, in which they do not have to be collected by the same sensors as the target data sets. Experiments on three public HSI data sets captured by different sensors demonstrate that our model achieves competitive performance for HSI classification compared to several state-of-the-art methods
* 16 pages. Accepted to IEEE Trans. Geosci. Remote Sens. Code is available at: https://github.com/hkzhang91/LWNet
End-to-End Video Instance Segmentation with Transformers
Dec 04, 2020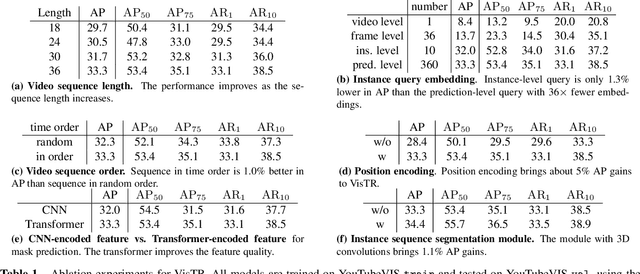
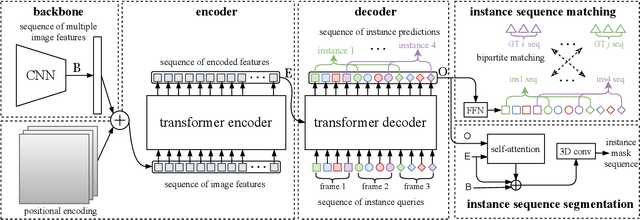
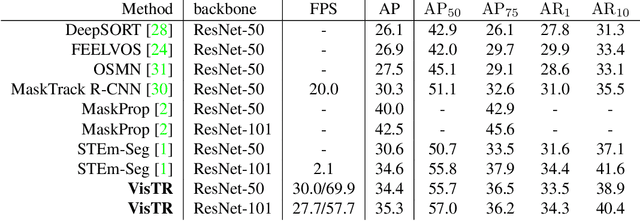

Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.
BoxInst: High-Performance Instance Segmentation with Box Annotations
Dec 03, 2020
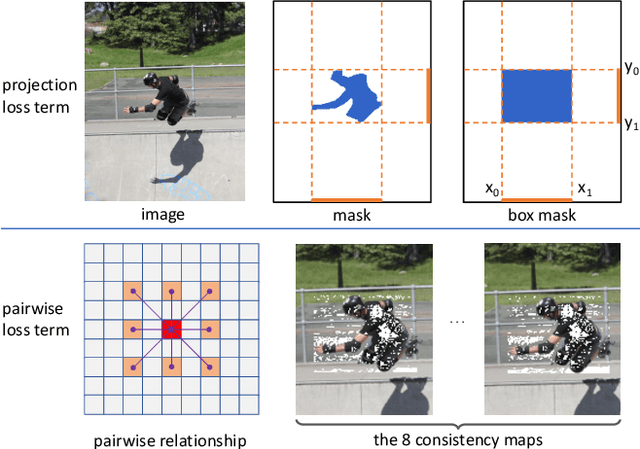
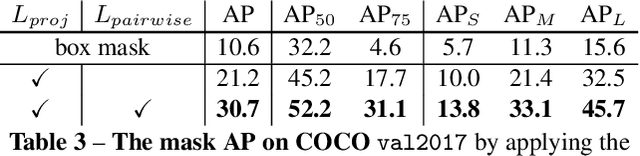
We present a high-performance method that can achieve mask-level instance segmentation with only bounding-box annotations for training. While this setting has been studied in the literature, here we show significantly stronger performance with a simple design (e.g., dramatically improving previous best reported mask AP of 21.1% in Hsu et al. (2019) to 31.6% on the COCO dataset). Our core idea is to redesign the loss of learning masks in instance segmentation, with no modification to the segmentation network itself. The new loss functions can supervise the mask training without relying on mask annotations. This is made possible with two loss terms, namely, 1) a surrogate term that minimizes the discrepancy between the projections of the ground-truth box and the predicted mask; 2) a pairwise loss that can exploit the prior that proximal pixels with similar colors are very likely to have the same category label. Experiments demonstrate that the redesigned mask loss can yield surprisingly high-quality instance masks with only box annotations. For example, without using any mask annotations, with a ResNet-101 backbone and 3x training schedule, we achieve 33.2% mask AP on COCO test-dev split (vs. 39.1% of the fully supervised counterpart). Our excellent experiment results on COCO and Pascal VOC indicate that our method dramatically narrows the performance gap between weakly and fully supervised instance segmentation. Code is available at: https://git.io/AdelaiDet
Learning Affinity-Aware Upsampling for Deep Image Matting
Nov 29, 2020
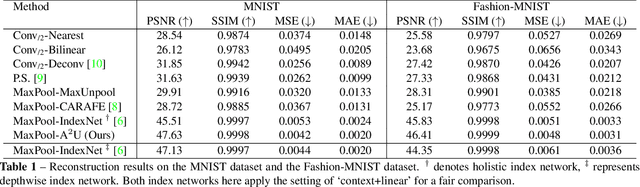
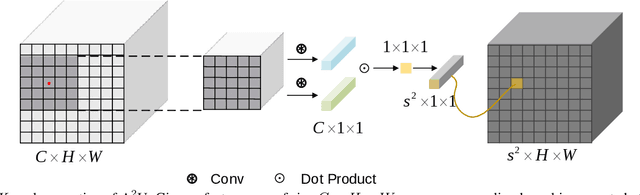
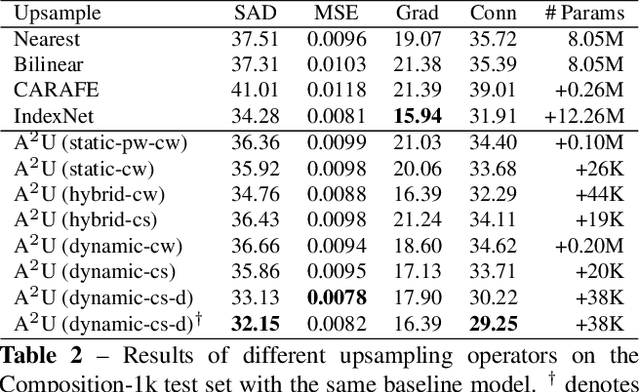
We show that learning affinity in upsampling provides an effective and efficient approach to exploit pairwise interactions in deep networks. Second-order features are commonly used in dense prediction to build adjacent relations with a learnable module after upsampling such as non-local blocks. Since upsampling is essential, learning affinity in upsampling can avoid additional propagation layers, offering the potential for building compact models. By looking at existing upsampling operators from a unified mathematical perspective, we generalize them into a second-order form and introduce Affinity-Aware Upsampling (A2U) where upsampling kernels are generated using a light-weight lowrank bilinear model and are conditioned on second-order features. Our upsampling operator can also be extended to downsampling. We discuss alternative implementations of A2U and verify their effectiveness on two detail-sensitive tasks: image reconstruction on a toy dataset; and a largescale image matting task where affinity-based ideas constitute mainstream matting approaches. In particular, results on the Composition-1k matting dataset show that A2U achieves a 14% relative improvement in the SAD metric against a strong baseline with negligible increase of parameters (<0.5%). Compared with the state-of-the-art matting network, we achieve 8% higher performance with only 40% model complexity.