 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing long-form speech using streaming end-to-end models
Oct 24, 2019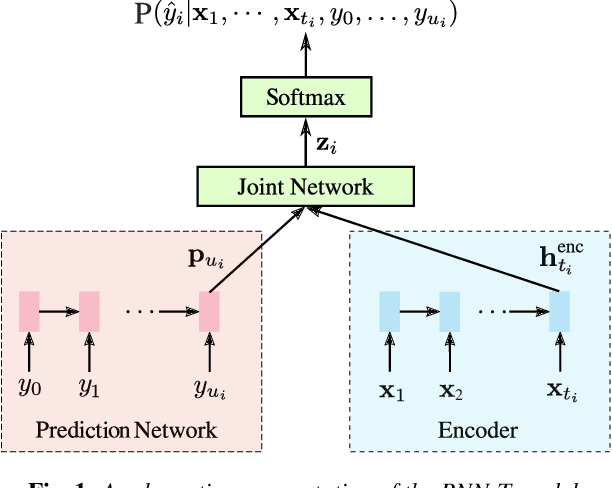
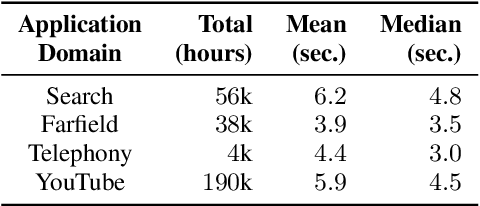
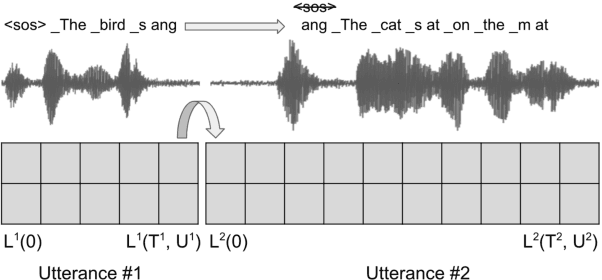
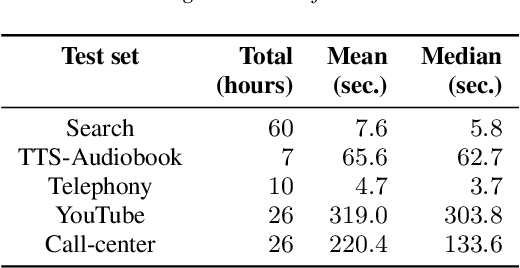
All-neural end-to-end (E2E) automatic speech recognition (ASR) systems that use a single neural network to transduce audio to word sequences have been shown to achieve state-of-the-art results on several tasks. In this work, we examine the ability of E2E models to generalize to unseen domains, where we find that models trained on short utterances fail to generalize to long-form speech. We propose two complementary solutions to address this: training on diverse acoustic data, and LSTM state manipulation to simulate long-form audio when training using short utterances. On a synthesized long-form test set, adding data diversity improves word error rate (WER) by 90% relative, while simulating long-form training improves it by 67% relative, though the combination doesn't improve over data diversity alone. On a real long-form call-center test set, adding data diversity improves WER by 40% relative. Simulating long-form training on top of data diversity improves performance by an additional 27% relative.
Two-Pass End-to-End Speech Recognition
Aug 29, 2019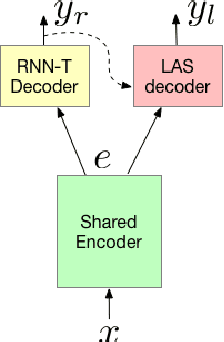

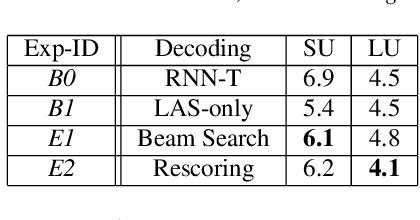
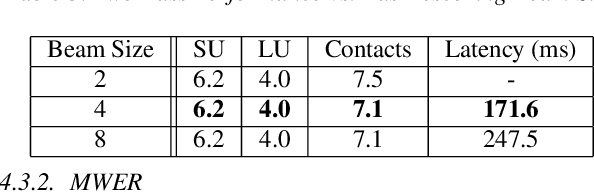
The requirements for many applications of state-of-the-art speech recognition systems include not only low word error rate (WER) but also low latency. Specifically, for many use-cases, the system must be able to decode utterances in a streaming fashion and faster than real-time. Recently, a streaming recurrent neural network transducer (RNN-T) end-to-end (E2E) model has shown to be a good candidate for on-device speech recognition, with improved WER and latency metrics compared to conventional on-device models [1]. However, this model still lags behind a large state-of-the-art conventional model in quality [2]. On the other hand, a non-streaming E2E Listen, Attend and Spell (LAS) model has shown comparable quality to large conventional models [3]. This work aims to bring the quality of an E2E streaming model closer to that of a conventional system by incorporating a LAS network as a second-pass component, while still abiding by latency constraints. Our proposed two-pass model achieves a 17%-22% relative reduction in WER compared to RNN-T alone and increases latency by a small fraction over RNN-T.
Monotonic Infinite Lookback Attention for Simultaneous Machine Translation
Jun 12, 2019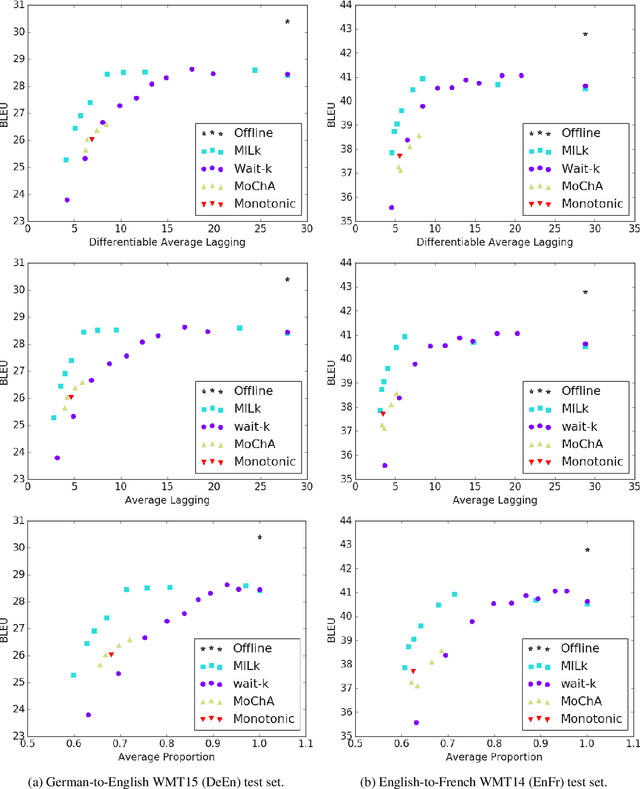
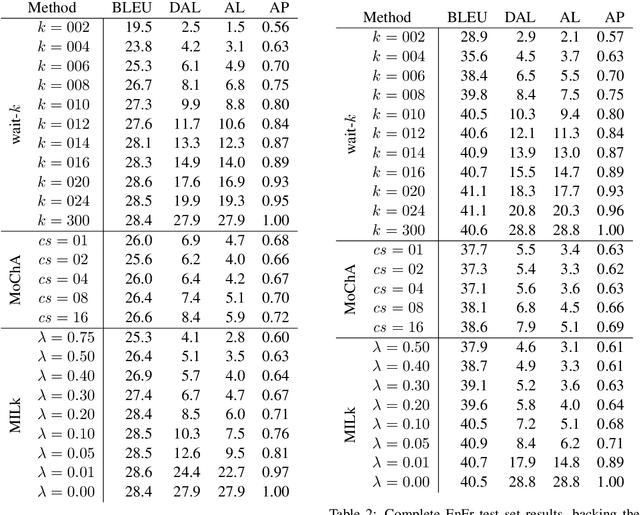
Simultaneous machine translation begins to translate each source sentence before the source speaker is finished speaking, with applications to live and streaming scenarios. Simultaneous systems must carefully schedule their reading of the source sentence to balance quality against latency. We present the first simultaneous translation system to learn an adaptive schedule jointly with a neural machine translation (NMT) model that attends over all source tokens read thus far. We do so by introducing Monotonic Infinite Lookback (MILk) attention, which maintains both a hard, monotonic attention head to schedule the reading of the source sentence, and a soft attention head that extends from the monotonic head back to the beginning of the source. We show that MILk's adaptive schedule allows it to arrive at latency-quality trade-offs that are favorable to those of a recently proposed wait-k strategy for many latency values.
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
Apr 18, 2019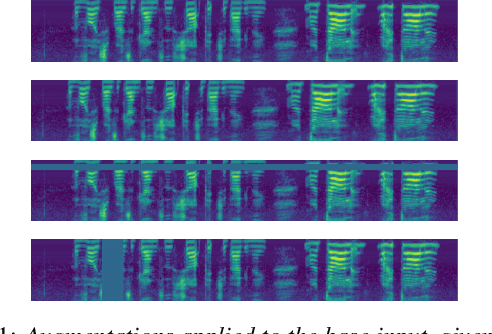
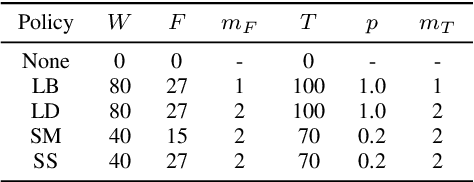
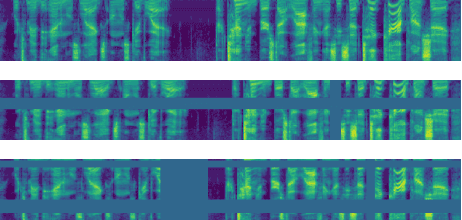
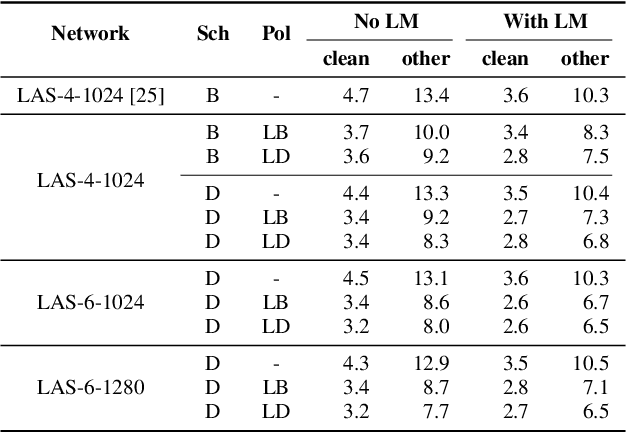
We present SpecAugment, a simple data augmentation method for speech recognition. SpecAugment is applied directly to the feature inputs of a neural network (i.e., filter bank coefficients). The augmentation policy consists of warping the features, masking blocks of frequency channels, and masking blocks of time steps. We apply SpecAugment on Listen, Attend and Spell networks for end-to-end speech recognition tasks. We achieve state-of-the-art performance on the LibriSpeech 960h and Swichboard 300h tasks, outperforming all prior work. On LibriSpeech, we achieve 6.8% WER on test-other without the use of a language model, and 5.8% WER with shallow fusion with a language model. This compares to the previous state-of-the-art hybrid system of 7.5% WER. For Switchboard, we achieve 7.2%/14.6% on the Switchboard/CallHome portion of the Hub5'00 test set without the use of a language model, and 6.8%/14.1% with shallow fusion, which compares to the previous state-of-the-art hybrid system at 8.3%/17.3% WER.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Leveraging Weakly Supervised Data to Improve End-to-End Speech-to-Text Translation
Nov 05, 2018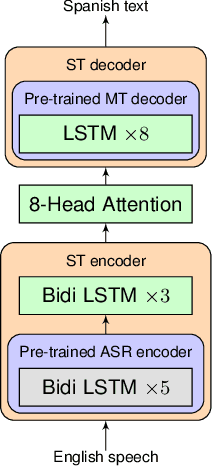

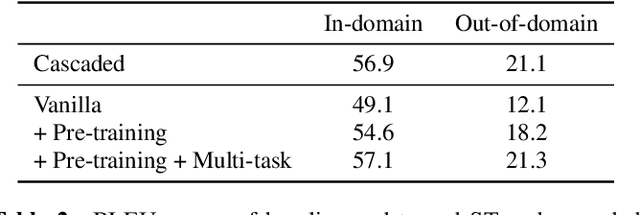
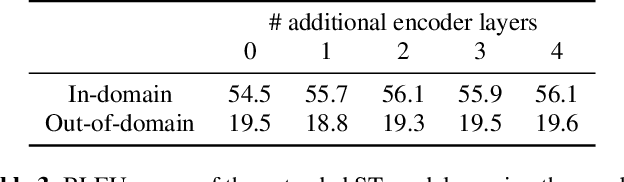
End-to-end Speech Translation (ST) models have many potential advantages when compared to the cascade of Automatic Speech Recognition (ASR) and text Machine Translation (MT) models, including lowered inference latency and the avoidance of error compounding. However, the quality of end-to-end ST is often limited by a paucity of training data, since it is difficult to collect large parallel corpora of speech and translated transcript pairs. Previous studies have proposed the use of pre-trained components and multi-task learning in order to benefit from weakly supervised training data, such as speech-to-transcript or text-to-foreign-text pairs. In this paper, we demonstrate that using pre-trained MT or text-to-speech (TTS) synthesis models to convert weakly supervised data into speech-to-translation pairs for ST training can be more effective than multi-task learning. Furthermore, we demonstrate that a high quality end-to-end ST model can be trained using only weakly supervised datasets, and that synthetic data sourced from unlabeled monolingual text or speech can be used to improve performance. Finally, we discuss methods for avoiding overfitting to synthetic speech with a quantitative ablation study.
A Comparison of Techniques for Language Model Integration in Encoder-Decoder Speech Recognition
Jul 27, 2018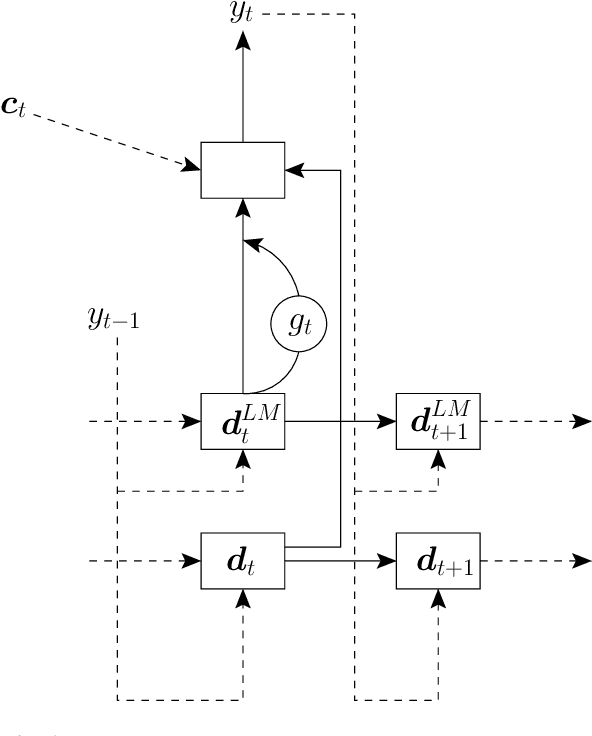
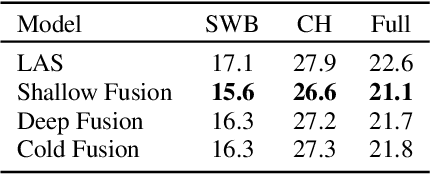
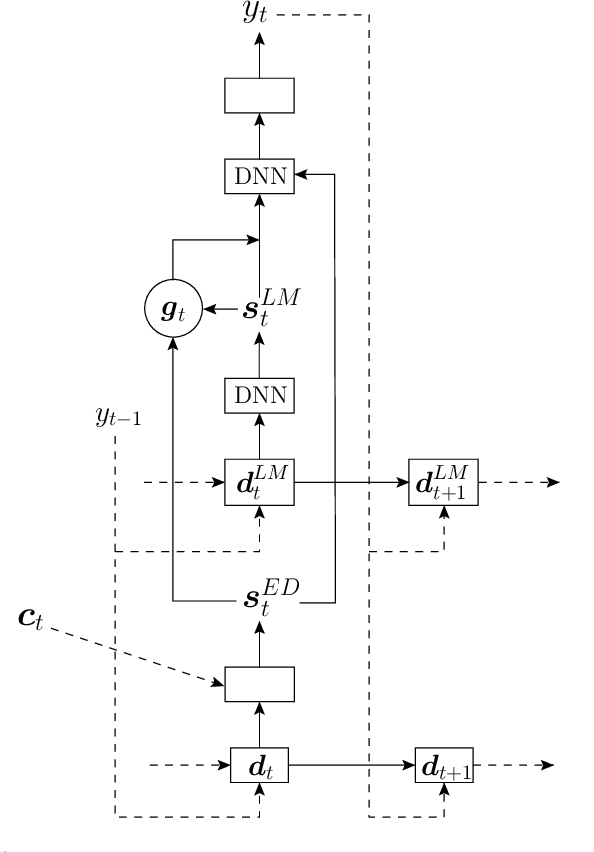

Attention-based recurrent neural encoder-decoder models present an elegant solution to the automatic speech recognition problem. This approach folds the acoustic model, pronunciation model, and language model into a single network and requires only a parallel corpus of speech and text for training. However, unlike in conventional approaches that combine separate acoustic and language models, it is not clear how to use additional (unpaired) text. While there has been previous work on methods addressing this problem, a thorough comparison among methods is still lacking. In this paper, we compare a suite of past methods and some of our own proposed methods for using unpaired text data to improve encoder-decoder models. For evaluation, we use the medium-sized Switchboard data set and the large-scale Google voice search and dictation data sets. Our results confirm the benefits of using unpaired text across a range of methods and data sets. Surprisingly, for first-pass decoding, the rather simple approach of shallow fusion performs best across data sets. However, for Google data sets we find that cold fusion has a lower oracle error rate and outperforms other approaches after second-pass rescoring on the Google voice search data set.
Speech recognition for medical conversations
Jun 20, 2018
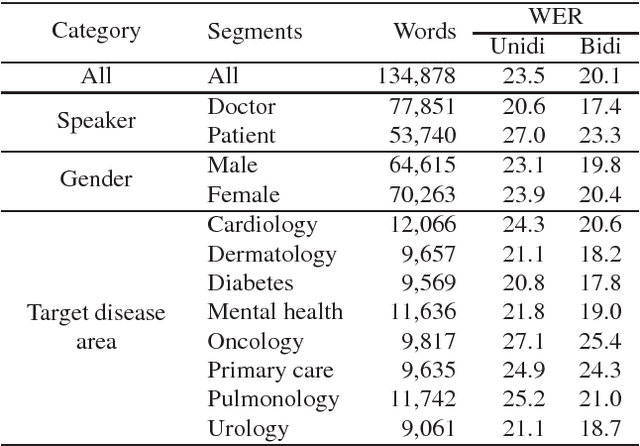
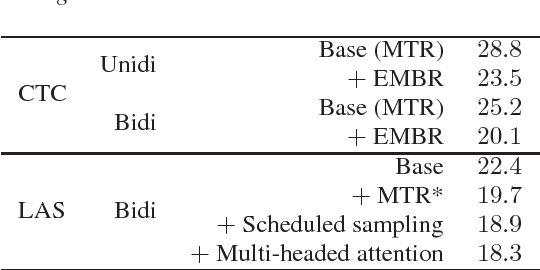
In this work we explored building automatic speech recognition models for transcribing doctor patient conversation. We collected a large scale dataset of clinical conversations ($14,000$ hr), designed the task to represent the real word scenario, and explored several alignment approaches to iteratively improve data quality. We explored both CTC and LAS systems for building speech recognition models. The LAS was more resilient to noisy data and CTC required more data clean up. A detailed analysis is provided for understanding the performance for clinical tasks. Our analysis showed the speech recognition models performed well on important medical utterances, while errors occurred in causal conversations. Overall we believe the resulting models can provide reasonable quality in practice.
State-of-the-art Speech Recognition With Sequence-to-Sequence Models
Feb 23, 2018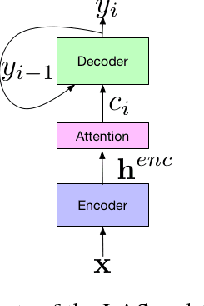
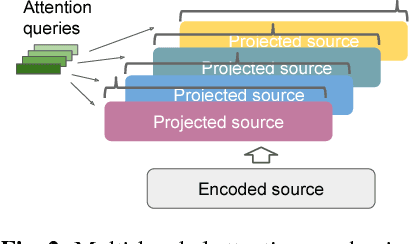
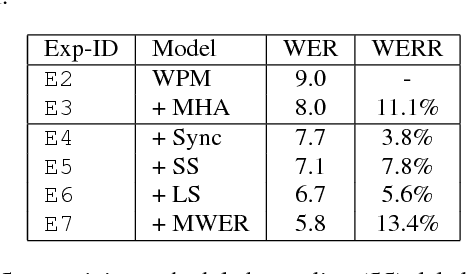
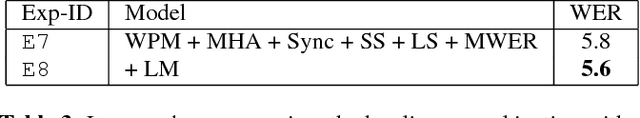
Attention-based encoder-decoder architectures such as Listen, Attend, and Spell (LAS), subsume the acoustic, pronunciation and language model components of a traditional automatic speech recognition (ASR) system into a single neural network. In previous work, we have shown that such architectures are comparable to state-of-theart ASR systems on dictation tasks, but it was not clear if such architectures would be practical for more challenging tasks such as voice search. In this work, we explore a variety of structural and optimization improvements to our LAS model which significantly improve performance. On the structural side, we show that word piece models can be used instead of graphemes. We also introduce a multi-head attention architecture, which offers improvements over the commonly-used single-head attention. On the optimization side, we explore synchronous training, scheduled sampling, label smoothing, and minimum word error rate optimization, which are all shown to improve accuracy. We present results with a unidirectional LSTM encoder for streaming recognition. On a 12, 500 hour voice search task, we find that the proposed changes improve the WER from 9.2% to 5.6%, while the best conventional system achieves 6.7%; on a dictation task our model achieves a WER of 4.1% compared to 5% for the conventional system.
Monotonic Chunkwise Attention
Feb 23, 2018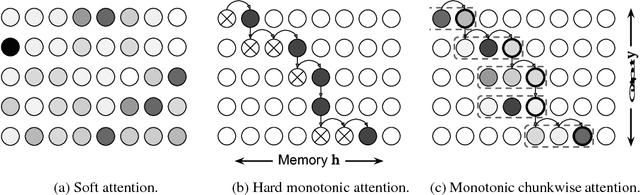
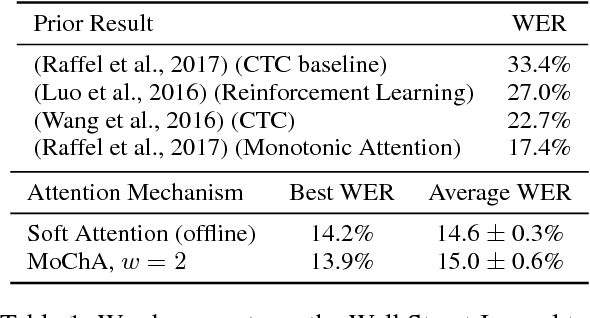
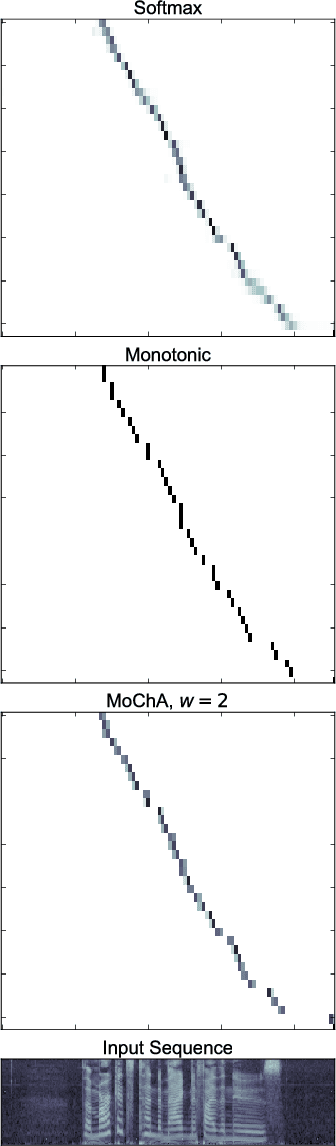

Sequence-to-sequence models with soft attention have been successfully applied to a wide variety of problems, but their decoding process incurs a quadratic time and space cost and is inapplicable to real-time sequence transduction. To address these issues, we propose Monotonic Chunkwise Attention (MoChA), which adaptively splits the input sequence into small chunks over which soft attention is computed. We show that models utilizing MoChA can be trained efficiently with standard backpropagation while allowing online and linear-time decoding at test time. When applied to online speech recognition, we obtain state-of-the-art results and match the performance of a model using an offline soft attention mechanism. In document summarization experiments where we do not expect monotonic alignments, we show significantly improved performance compared to a baseline monotonic attention-based model.