 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMeshFlow: Content Adaptive Mesh Deformation for Robust Image Registration
Dec 11, 2019
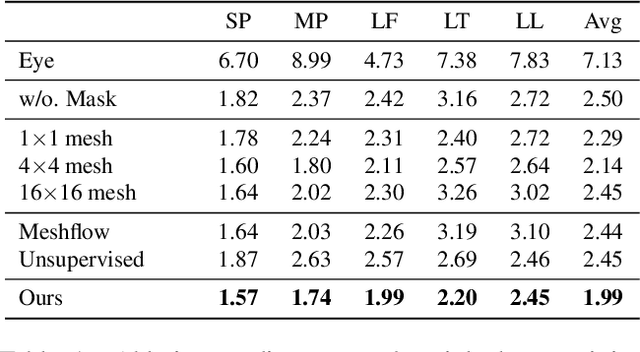
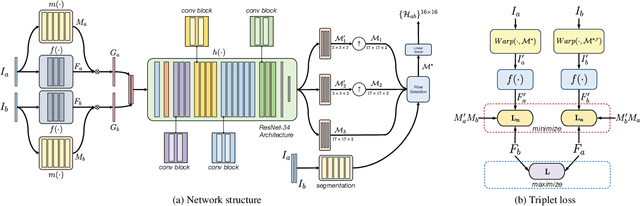

Image alignment by mesh warps, such as meshflow, is a fundamental task which has been widely applied in various vision applications(e.g., multi-frame HDR/denoising, video stabilization). Traditional mesh warp methods detect and match image features, where the quality of alignment highly depends on the quality of image features. However, the image features are not robust in occurrence of low-texture and low-light scenes. Deep homography methods, on the other hand, are free from such problem by learning deep features for robust performance. However, a homography is limited to plane motions. In this work, we present a deep meshflow motion model, which takes two images as input and output a sparse motion field with motions located at mesh vertexes. The deep meshflow enjoys the merics of meshflow that can describe nonlinear motions while also shares advantage of deep homography that is robust against challenging textureless scenarios. In particular, a new unsupervised network structure is presented with content-adaptive capability. On one hand, the image content that cannot be aligned under mesh representation are rejected by our learned mask, similar to the RANSAC procedure. On the other hand, we learn multiple mesh resolutions, combining to a non-uniform mesh division. Moreover, a comprehensive dataset is presented, covering various scenes for training and testing. The comparison between both traditional mesh warp methods and deep based methods show the effectiveness of our deep meshflow motion model.
Non-parametric Probabilistic Load Flow using Gaussian Process Learning
Nov 08, 2019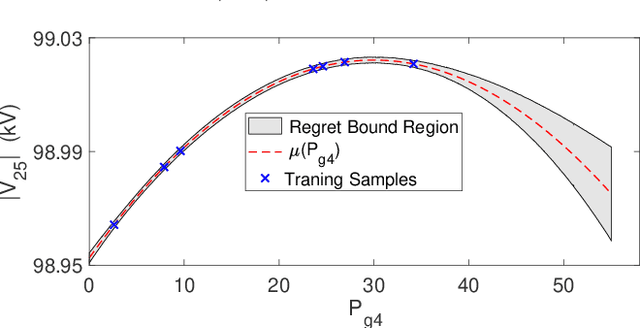
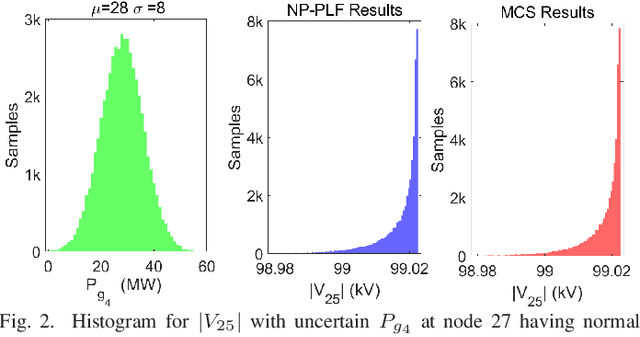
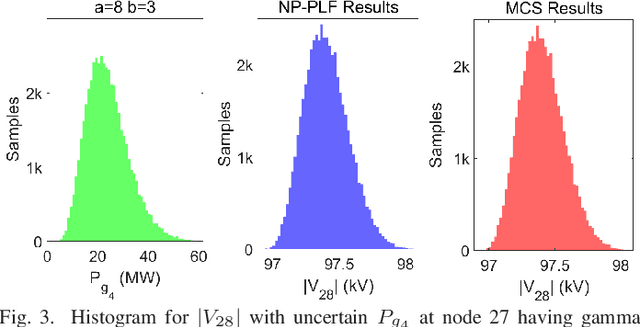
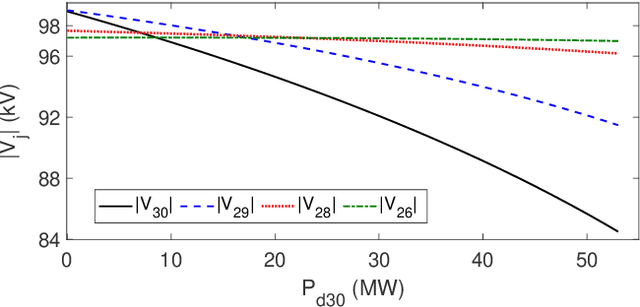
In this paper, we propose a non-parametric probabilistic load flow (NP-PLF) technique based on Gaussian process (GP) learning. The technique can provide "semi-explicit" power flow solutions by implementing learning step and testing step. The proposed NP-PLF leverages upon GP upper confidence bound (GP-UCB) sampling algorithm. The salient features of this NP-PLF method are: i) applicable for power flow problem having power injection uncertainty with unknown class of distribution; ii) providing probabilistic learning bound (PLB) provides control over the error and convergence; iii) capable of handling intermittent distributed generation as well as load uncertainties; and iv) applicable to both balanced and unbalanced power flow with different type and size of systems. The simulation results performed on IEEE 30-bus and IEEE 118-bus system show that the proposed method is able to learn the state variable function in the input subspace using a small number of training samples. Further, the testing with different distributions indicates that more complete statistical information can be obtained on probabilistic power flow problem using the proposed method.
Content-Aware Unsupervised Deep Homography Estimation
Sep 12, 2019
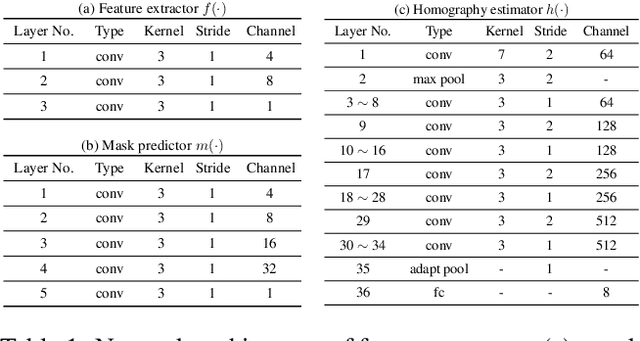
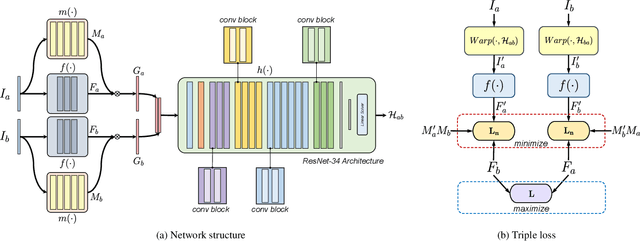
Robust homography estimation between two images is a fundamental task which has been widely applied to various vision applications. Traditional feature based methods often detect image features and fit a homography according to matched features with RANSAC outlier removal. However, the quality of homography heavily relies on the quality of image features, which are prone to errors with respect to low light and low texture images. On the other hand, previous deep homography approaches either synthesize images for supervised learning or adopt aerial images for unsupervised learning, both ignoring the importance of depth disparities in homography estimation. Moreover, they treat the image content equally, including regions of dynamic objects and near-range foregrounds, which further decreases the quality of estimation. In this work, to overcome such problems, we propose an unsupervised deep homography method with a new architecture design. We learn a mask during the estimation to reject outlier regions. In addition, we calculate loss with respect to our learned deep features instead of directly comparing the image contents as did previously. Moreover, a comprehensive dataset is presented, covering both regular and challenging cases, such as poor textures and non-planar interferences. The effectiveness of our method is validated through comparisons with both feature-based and previous deep-based methods. Code will be soon available at Github.
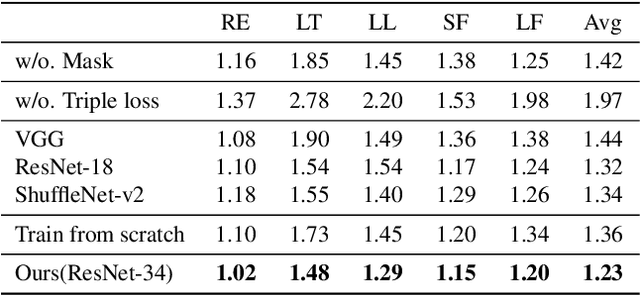
Recognition of Ischaemia and Infection in Diabetic Foot Ulcers: Dataset and Techniques
Sep 11, 2019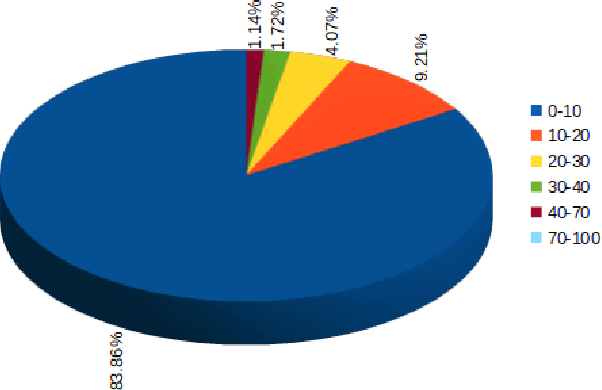
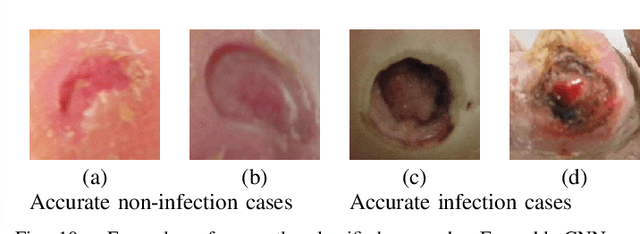
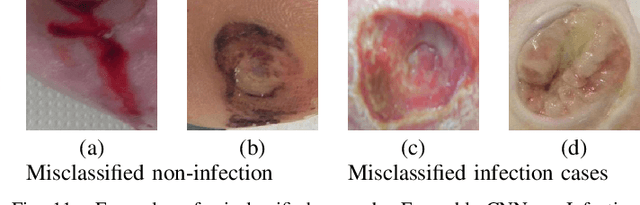

Diabetic Foot Ulcers (DFU) detection using computerized methods is an emerging research area with the evolution of machine learning algorithms. However, existing research focuses on detecting and segmenting the ulcers. According to DFU medical classification systems, i.e. University of Texas Classification and SINBAD Classification, the presence of infection (bacteria in the wound) and ischaemia (inadequate blood supply) has important clinical implication for DFU assessment, which were used to predict the risk of amputation. In this work, we propose a new dataset and novel techniques to identify the presence of infection and ischaemia. We introduce a very comprehensive DFU dataset with ground truth labels of ischaemia and infection cases. For hand-crafted machine learning approach, we propose new feature descriptor, namely Superpixel Color Descriptor. Then, we propose a technique using Ensemble Convolutional Neural Network (CNN) model for ischaemia and infection recognition. The novelty lies in our proposed natural data-augmentation method, which clearly identifies the region of interest on foot images and focuses on finding the salient features existing in this area. Finally, we evaluate the performance of our proposed techniques on binary classification, i.e. ischaemia versus non-ischaemia and infection versus non-infection. Overall, our proposed method performs better in the classification of ischaemia than infection. We found that our proposed Ensemble CNN deep learning algorithms performed better for both classification tasks than hand-crafted machine learning algorithms, with 90% accuracy in ischaemia classification and 73% in infection classification.
Semi-Supervised Video Salient Object Detection Using Pseudo-Labels
Aug 12, 2019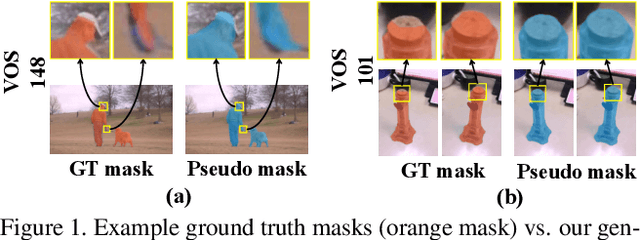

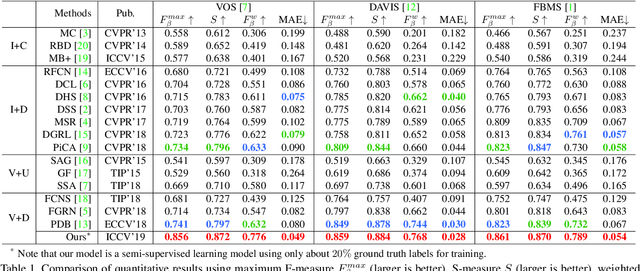
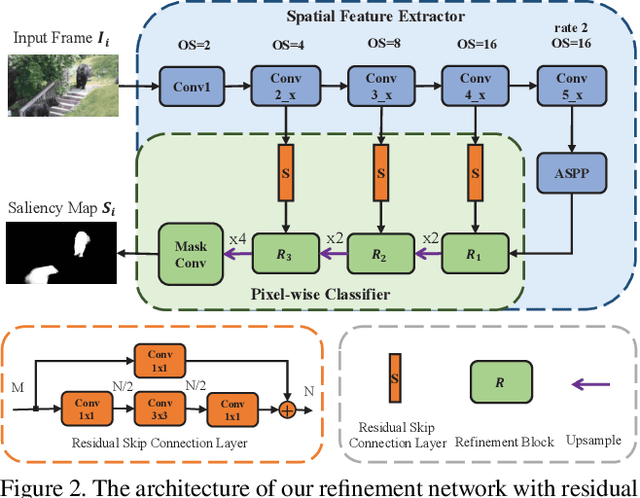
Deep learning-based video salient object detection has recently achieved great success with its performance significantly outperforming any other unsupervised methods. However, existing data-driven approaches heavily rely on a large quantity of pixel-wise annotated video frames to deliver such promising results. In this paper, we address the semi-supervised video salient object detection task using pseudo-labels. Specifically, we present an effective video saliency detector that consists of a spatial refinement network and a spatiotemporal module. Based on the same refinement network and motion information in terms of optical flow, we further propose a novel method for generating pixel-level pseudo-labels from sparsely annotated frames. By utilizing the generated pseudo-labels together with a part of manual annotations, our video saliency detector learns spatial and temporal cues for both contrast inference and coherence enhancement, thus producing accurate saliency maps. Experimental results demonstrate that our proposed semi-supervised method even greatly outperforms all the state-of-the-art fully supervised methods across three public benchmarks of VOS, DAVIS, and FBMS.
Semi-supervised Skin Detection by Network with Mutual Guidance
Aug 06, 2019
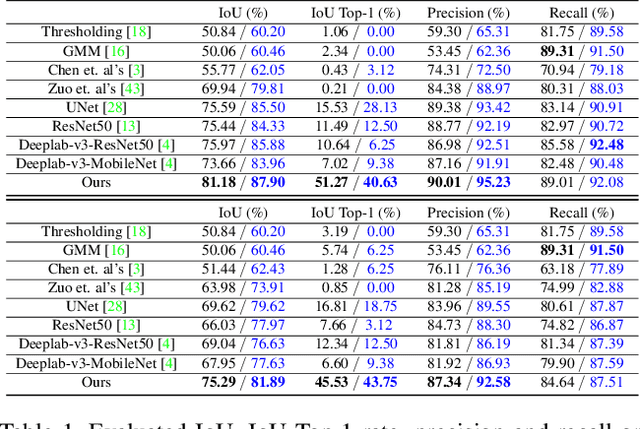
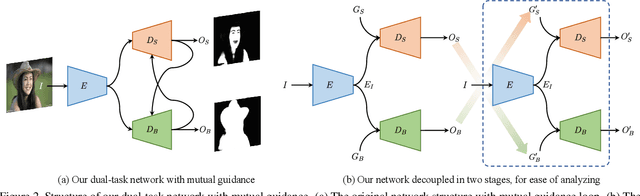
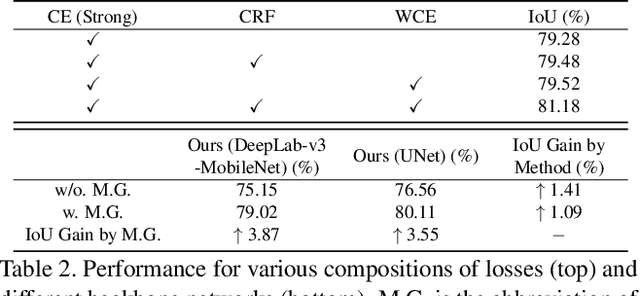
In this paper we present a new data-driven method for robust skin detection from a single human portrait image. Unlike previous methods, we incorporate human body as a weak semantic guidance into this task, considering acquiring large-scale of human labeled skin data is commonly expensive and time-consuming. To be specific, we propose a dual-task neural network for joint detection of skin and body via a semi-supervised learning strategy. The dual-task network contains a shared encoder but two decoders for skin and body separately. For each decoder, its output also serves as a guidance for its counterpart, making both decoders mutually guided. Extensive experiments were conducted to demonstrate the effectiveness of our network with mutual guidance, and experimental results show our network outperforms the state-of-the-art in skin detection.
Frame-Recurrent Video Inpainting by Robust Optical Flow Inference
May 08, 2019
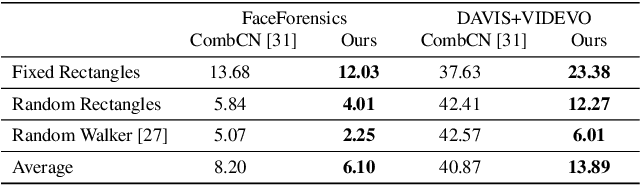
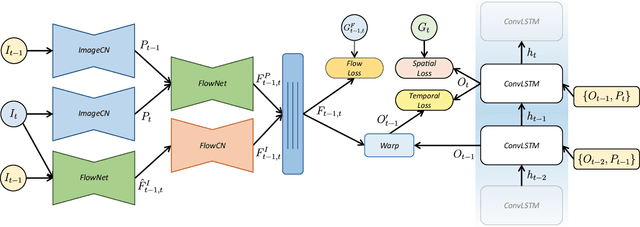
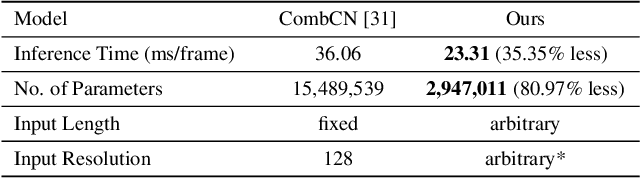
In this paper, we present a new inpainting framework for recovering missing regions of video frames. Compared with image inpainting, performing this task on video presents new challenges such as how to preserving temporal consistency and spatial details, as well as how to handle arbitrary input video size and length fast and efficiently. Towards this end, we propose a novel deep learning architecture which incorporates ConvLSTM and optical flow for modeling the spatial-temporal consistency in videos. It also saves much computational resource such that our method can handle videos with larger frame size and arbitrary length streamingly in real-time. Furthermore, to generate an accurate optical flow from corrupted frames, we propose a robust flow generation module, where two sources of flows are fed and a flow blending network is trained to fuse them. We conduct extensive experiments to evaluate our method in various scenarios and different datasets, both qualitatively and quantitatively. The experimental results demonstrate the superior of our method compared with the state-of-the-art inpainting approaches.
Learning Raw Image Denoising with Bayer Pattern Unification and Bayer Preserving Augmentation
Apr 29, 2019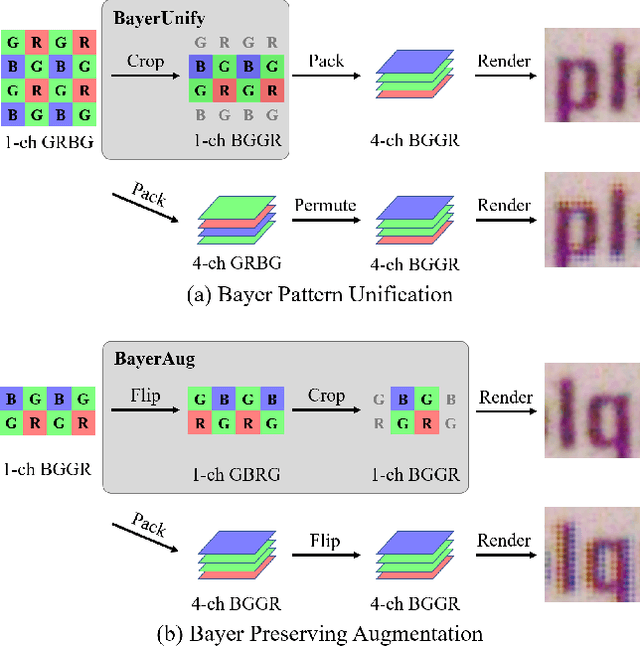



In this paper, we present new data pre-processing and augmentation techniques for DNN-based raw image denoising. Compared with traditional RGB image denoising, performing this task on direct camera sensor readings presents new challenges such as how to effectively handle various Bayer patterns from different data sources, and subsequently how to perform valid data augmentation with raw images. To address the first problem, we propose a Bayer pattern unification (BayerUnify) method to unify different Bayer patterns. This allows us to fully utilize a heterogeneous dataset to train a single denoising model instead of training one model for each pattern. Furthermore, while it is essential to augment the dataset to improve model generalization and performance, we discovered that it is error-prone to modify raw images by adapting augmentation methods designed for RGB images. Towards this end, we present a Bayer preserving augmentation (BayerAug) method as an effective approach for raw image augmentation. Combining these data processing technqiues with a modified U-Net, our method achieves a PSNR of 52.11 and a SSIM of 0.9969 in NTIRE 2019 Real Image Denoising Challenge, demonstrating the state-of-the-art performance.
Two-phase Hair Image Synthesis by Self-Enhancing Generative Model
Feb 28, 2019
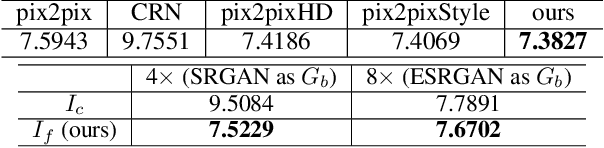
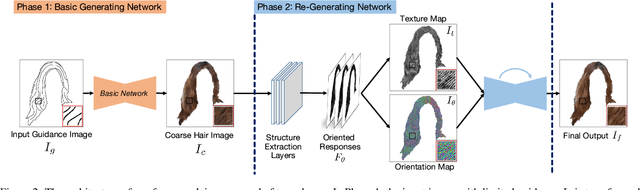

Generating plausible hair image given limited guidance, such as sparse sketches or low-resolution image, has been made possible with the rise of Generative Adversarial Networks (GANs). Traditional image-to-image translation networks can generate recognizable results, but finer textures are usually lost and blur artifacts commonly exist. In this paper, we propose a two-phase generative model for high-quality hair image synthesis. The two-phase pipeline first generates a coarse image by an existing image translation model, then applies a re-generating network with self-enhancing capability to the coarse image. The self-enhancing capability is achieved by a proposed structure extraction layer, which extracts the texture and orientation map from a hair image. Extensive experiments on two tasks, Sketch2Hair and Hair Super-Resolution, demonstrate that our approach is able to synthesize plausible hair image with finer details, and outperforms the state-of-the-art.
Visual Reasoning of Feature Attribution with Deep Recurrent Neural Networks
Jan 17, 2019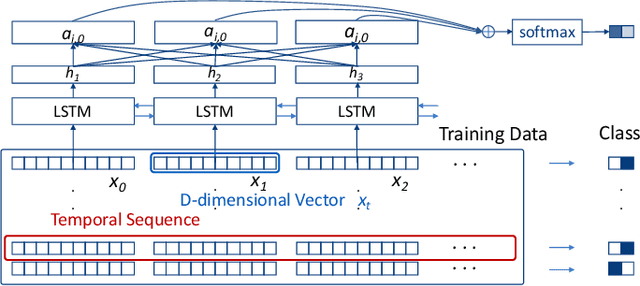

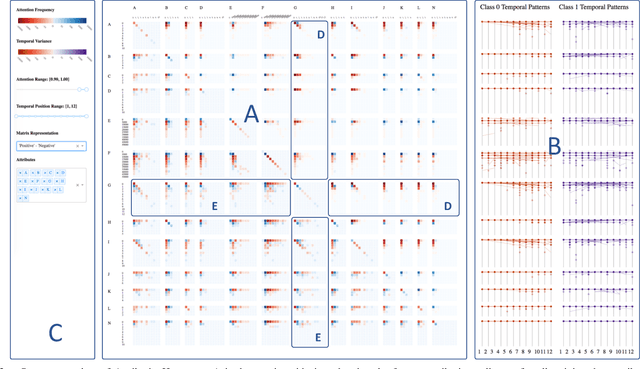
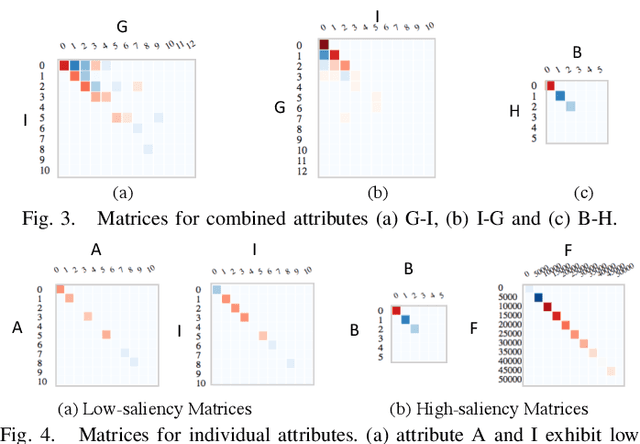
Deep Recurrent Neural Network (RNN) has gained popularity in many sequence classification tasks. Beyond predicting a correct class for each data instance, data scientists also want to understand what differentiating factors in the data have contributed to the classification during the learning process. We present a visual analytics approach to facilitate this task by revealing the RNN attention for all data instances, their temporal positions in the sequences, and the attribution of variables at each value level. We demonstrate with real-world datasets that our approach can help data scientists to understand such dynamics in deep RNNs from the training results, hence guiding their modeling process.