 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Dynamics for Full Body Avatar Animation
May 20, 2026Pose-driven full-body avatars built on neural rendering produce high-quality novel views of a captured subject. Yet loose clothing and other dynamic elements deform in ways pose alone cannot explain: the same pose can correspond to many different states, because their motion depends on history, inertia, and contact. Explicit simulation and layered-garment methods can model such dynamics, but they require either a dedicated garment template, which raw multi-view capture does not naturally provide, or a test-time physics simulator with non-trivial runtime cost. A parallel line of work learns data-driven clothing avatars that avoid explicit garment layers. These methods add an auxiliary latent for variation beyond pose; at inference, they fix it, regress it from pose, or retrieve it from training data, without explicitly modeling how the latent evolves with its own dynamics. Additionally, even in everyday motion with loose clothing, existing architectures often struggle to capture fine-grained detail, producing blurry renderings and temporal artifacts. We augment a pose-conditioned 3D Gaussian avatar with a transformer-based decoder and a dynamics residual latent that captures temporal appearance and geometry variation beyond the driving signals. At inference, a learned latent dynamics model evolves the residual latent from a short pose history and the previous latent state. The model decomposes each update into driving, restoring, and dissipative forces, producing temporally coherent, history-dependent rollouts with negligible added cost. Different initial conditions yield diverse yet plausible motion trajectories, and the force decomposition exposes controls such as stiffness. Across nine captured sequences of everyday motion with diverse loose garments, quantitative metrics and a perceptual user study show improved animation quality over recent data-driven baselines.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
FactorPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint
Dec 12, 2025We introduce FactorPortrait, a video diffusion method for controllable portrait animation that enables lifelike synthesis from disentangled control signals of facial expressions, head movement, and camera viewpoints. Given a single portrait image, a driving video, and camera trajectories, our method animates the portrait by transferring facial expressions and head movements from the driving video while simultaneously enabling novel view synthesis from arbitrary viewpoints. We utilize a pre-trained image encoder to extract facial expression latents from the driving video as control signals for animation generation. Such latents implicitly capture nuanced facial expression dynamics with identity and pose information disentangled, and they are efficiently injected into the video diffusion transformer through our proposed expression controller. For camera and head pose control, we employ Plücker ray maps and normal maps rendered from 3D body mesh tracking. To train our model, we curate a large-scale synthetic dataset containing diverse combinations of camera viewpoints, head poses, and facial expression dynamics. Extensive experiments demonstrate that our method outperforms existing approaches in realism, expressiveness, control accuracy, and view consistency.
Repurposing 2D Diffusion Models with Gaussian Atlas for 3D Generation
Mar 20, 2025Recent advances in text-to-image diffusion models have been driven by the increasing availability of paired 2D data. However, the development of 3D diffusion models has been hindered by the scarcity of high-quality 3D data, resulting in less competitive performance compared to their 2D counterparts. To address this challenge, we propose repurposing pre-trained 2D diffusion models for 3D object generation. We introduce Gaussian Atlas, a novel representation that utilizes dense 2D grids, enabling the fine-tuning of 2D diffusion models to generate 3D Gaussians. Our approach demonstrates successful transfer learning from a pre-trained 2D diffusion model to a 2D manifold flattened from 3D structures. To support model training, we compile GaussianVerse, a large-scale dataset comprising 205K high-quality 3D Gaussian fittings of various 3D objects. Our experimental results show that text-to-image diffusion models can be effectively adapted for 3D content generation, bridging the gap between 2D and 3D modeling.
Rethinking Video-Text Understanding: Retrieval from Counterfactually Augmented Data
Jul 18, 2024Recent video-text foundation models have demonstrated strong performance on a wide variety of downstream video understanding tasks. Can these video-text models genuinely understand the contents of natural videos? Standard video-text evaluations could be misleading as many questions can be inferred merely from the objects and contexts in a single frame or biases inherent in the datasets. In this paper, we aim to better assess the capabilities of current video-text models and understand their limitations. We propose a novel evaluation task for video-text understanding, namely retrieval from counterfactually augmented data (RCAD), and a new Feint6K dataset. To succeed on our new evaluation task, models must derive a comprehensive understanding of the video from cross-frame reasoning. Analyses show that previous video-text foundation models can be easily fooled by counterfactually augmented data and are far behind human-level performance. In order to narrow the gap between video-text models and human performance on RCAD, we identify a key limitation of current contrastive approaches on video-text data and introduce LLM-teacher, a more effective approach to learn action semantics by leveraging knowledge obtained from a pretrained large language model. Experiments and analyses show that our approach successfully learn more discriminative action embeddings and improves results on Feint6K when applied to multiple video-text models. Our Feint6K dataset and project page is available at https://feint6k.github.io.
CHOSEN: Contrastive Hypothesis Selection for Multi-View Depth Refinement
Apr 02, 2024



We propose CHOSEN, a simple yet flexible, robust and effective multi-view depth refinement framework. It can be employed in any existing multi-view stereo pipeline, with straightforward generalization capability for different multi-view capture systems such as camera relative positioning and lenses. Given an initial depth estimation, CHOSEN iteratively re-samples and selects the best hypotheses, and automatically adapts to different metric or intrinsic scales determined by the capture system. The key to our approach is the application of contrastive learning in an appropriate solution space and a carefully designed hypothesis feature, based on which positive and negative hypotheses can be effectively distinguished. Integrated in a simple baseline multi-view stereo pipeline, CHOSEN delivers impressive quality in terms of depth and normal accuracy compared to many current deep learning based multi-view stereo pipelines.
OmniSyn: Synthesizing 360 Videos with Wide-baseline Panoramas
Feb 22, 2022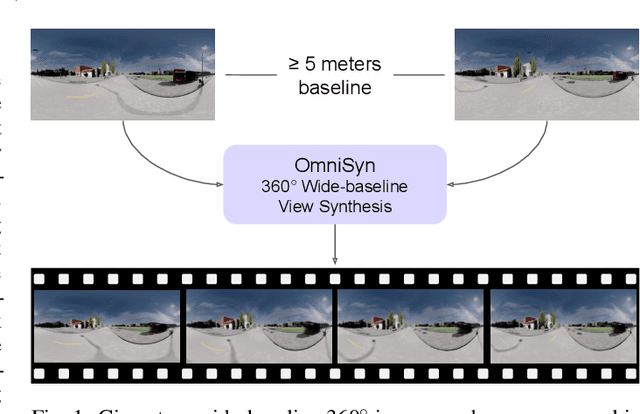


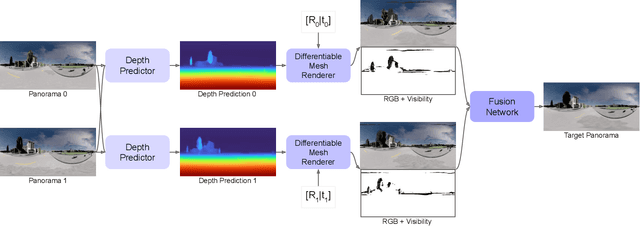
Immersive maps such as Google Street View and Bing Streetside provide true-to-life views with a massive collection of panoramas. However, these panoramas are only available at sparse intervals along the path they are taken, resulting in visual discontinuities during navigation. Prior art in view synthesis is usually built upon a set of perspective images, a pair of stereoscopic images, or a monocular image, but barely examines wide-baseline panoramas, which are widely adopted in commercial platforms to optimize bandwidth and storage usage. In this paper, we leverage the unique characteristics of wide-baseline panoramas and present OmniSyn, a novel pipeline for 360{\deg} view synthesis between wide-baseline panoramas. OmniSyn predicts omnidirectional depth maps using a spherical cost volume and a monocular skip connection, renders meshes in 360{\deg} images, and synthesizes intermediate views with a fusion network. We demonstrate the effectiveness of OmniSyn via comprehensive experimental results including comparison with the state-of-the-art methods on CARLA and Matterport datasets, ablation studies, and generalization studies on street views. We envision our work may inspire future research for this unheeded real-world task and eventually produce a smoother experience for navigating immersive maps.
HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching
Jul 23, 2020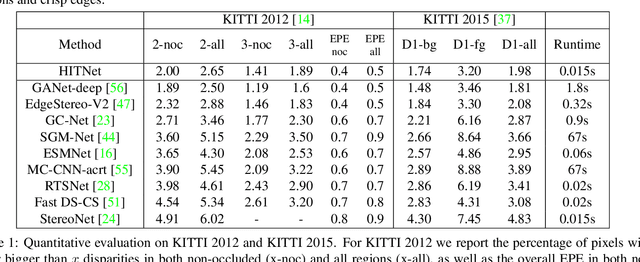
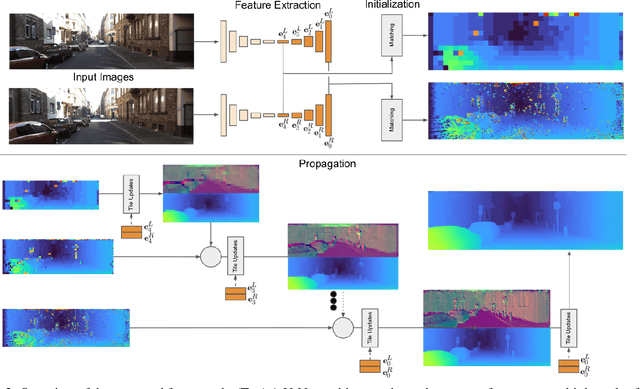


This paper presents HITNet, a novel neural network architecture for real-time stereo matching. Contrary to many recent neural network approaches that operate on a full cost volume and rely on 3D convolutions, our approach does not explicitly build a volume and instead relies on a fast multi-resolution initialization step, differentiable 2D geometric propagation and warping mechanisms to infer disparity hypotheses. To achieve a high level of accuracy, our network not only geometrically reasons about disparities but also infers slanted plane hypotheses allowing to more accurately perform geometric warping and upsampling operations. Our architecture is inherently multi-resolution allowing the propagation of information at different levels. Multiple experiments prove the effectiveness of the proposed approach at a fraction of the computation required by recent state-of-the-art methods. At time of writing, HITNet ranks 1st-3rd on all the metrics published on the ETH3D website for two view stereo and ranks 1st on the popular KITTI 2012 and 2015 benchmarks among the published methods faster than 100ms.
Du$^2$Net: Learning Depth Estimation from Dual-Cameras and Dual-Pixels
Mar 31, 2020
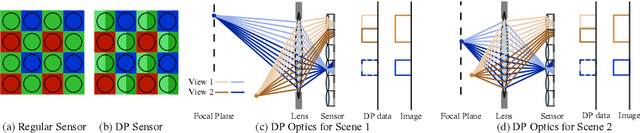
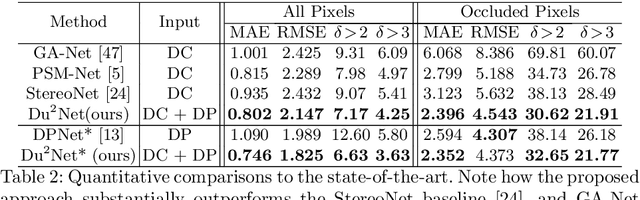
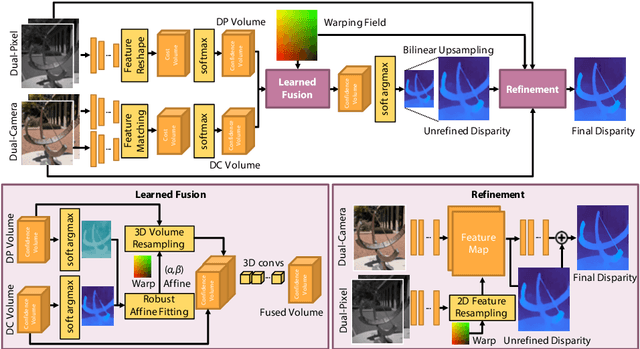
Computational stereo has reached a high level of accuracy, but degrades in the presence of occlusions, repeated textures, and correspondence errors along edges. We present a novel approach based on neural networks for depth estimation that combines stereo from dual cameras with stereo from a dual-pixel sensor, which is increasingly common on consumer cameras. Our network uses a novel architecture to fuse these two sources of information and can overcome the above-mentioned limitations of pure binocular stereo matching. Our method provides a dense depth map with sharp edges, which is crucial for computational photography applications like synthetic shallow-depth-of-field or 3D Photos. Additionally, we avoid the inherent ambiguity due to the aperture problem in stereo cameras by designing the stereo baseline to be orthogonal to the dual-pixel baseline. We present experiments and comparisons with state-of-the-art approaches to show that our method offers a substantial improvement over previous works.
Cost-Sensitive Active Learning for Intracranial Hemorrhage Detection
Sep 08, 2018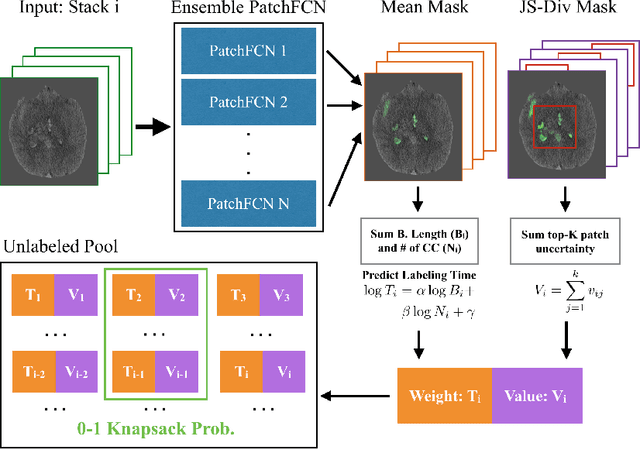

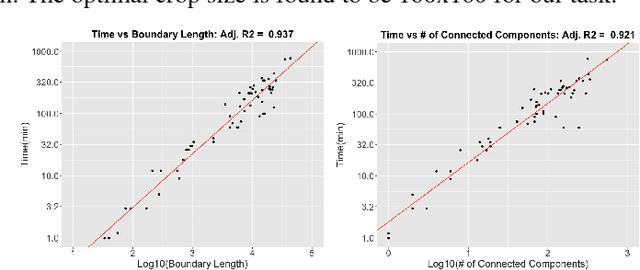
Deep learning for clinical applications is subject to stringent performance requirements, which raises a need for large labeled datasets. However, the enormous cost of labeling medical data makes this challenging. In this paper, we build a cost-sensitive active learning system for the problem of intracranial hemorrhage detection and segmentation on head computed tomography (CT). We show that our ensemble method compares favorably with the state-of-the-art, while running faster and using less memory. Moreover, our experiments are done using a substantially larger dataset than earlier papers on this topic. Since the labeling time could vary tremendously across examples, we model the labeling time and optimize the return on investment. We validate this idea by core-set selection on our large labeled dataset and by growing it with data from the wild.