 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtually Being: Customizing Camera-Controllable Video Diffusion Models with Multi-View Performance Captures
Oct 16, 2025We introduce a framework that enables both multi-view character consistency and 3D camera control in video diffusion models through a novel customization data pipeline. We train the character consistency component with recorded volumetric capture performances re-rendered with diverse camera trajectories via 4D Gaussian Splatting (4DGS), lighting variability obtained with a video relighting model. We fine-tune state-of-the-art open-source video diffusion models on this data to provide strong multi-view identity preservation, precise camera control, and lighting adaptability. Our framework also supports core capabilities for virtual production, including multi-subject generation using two approaches: joint training and noise blending, the latter enabling efficient composition of independently customized models at inference time; it also achieves scene and real-life video customization as well as control over motion and spatial layout during customization. Extensive experiments show improved video quality, higher personalization accuracy, and enhanced camera control and lighting adaptability, advancing the integration of video generation into virtual production. Our project page is available at: https://eyeline-labs.github.io/Virtually-Being.
Just KIDDIN: Knowledge Infusion and Distillation for Detection of INdecent Memes
Nov 19, 2024Toxicity identification in online multimodal environments remains a challenging task due to the complexity of contextual connections across modalities (e.g., textual and visual). In this paper, we propose a novel framework that integrates Knowledge Distillation (KD) from Large Visual Language Models (LVLMs) and knowledge infusion to enhance the performance of toxicity detection in hateful memes. Our approach extracts sub-knowledge graphs from ConceptNet, a large-scale commonsense Knowledge Graph (KG) to be infused within a compact VLM framework. The relational context between toxic phrases in captions and memes, as well as visual concepts in memes enhance the model's reasoning capabilities. Experimental results from our study on two hate speech benchmark datasets demonstrate superior performance over the state-of-the-art baselines across AU-ROC, F1, and Recall with improvements of 1.1%, 7%, and 35%, respectively. Given the contextual complexity of the toxicity detection task, our approach showcases the significance of learning from both explicit (i.e. KG) as well as implicit (i.e. LVLMs) contextual cues incorporated through a hybrid neurosymbolic approach. This is crucial for real-world applications where accurate and scalable recognition of toxic content is critical for creating safer online environments.
A PCA based Keypoint Tracking Approach to Automated Facial Expressions Encoding
Jun 13, 2024The Facial Action Coding System (FACS) for studying facial expressions is manual and requires significant effort and expertise. This paper explores the use of automated techniques to generate Action Units (AUs) for studying facial expressions. We propose an unsupervised approach based on Principal Component Analysis (PCA) and facial keypoint tracking to generate data-driven AUs called PCA AUs using the publicly available DISFA dataset. The PCA AUs comply with the direction of facial muscle movements and are capable of explaining over 92.83 percent of the variance in other public test datasets (BP4D-Spontaneous and CK+), indicating their capability to generalize facial expressions. The PCA AUs are also comparable to a keypoint-based equivalence of FACS AUs in terms of variance explained on the test datasets. In conclusion, our research demonstrates the potential of automated techniques to be an alternative to manual FACS labeling which could lead to efficient real-time analysis of facial expressions in psychology and related fields. To promote further research, we have made code repository publicly available.
Unsupervised learning of Data-driven Facial Expression Coding System (DFECS) using keypoint tracking
Jun 08, 2024



The development of existing facial coding systems, such as the Facial Action Coding System (FACS), relied on manual examination of facial expression videos for defining Action Units (AUs). To overcome the labor-intensive nature of this process, we propose the unsupervised learning of an automated facial coding system by leveraging computer-vision-based facial keypoint tracking. In this novel facial coding system called the Data-driven Facial Expression Coding System (DFECS), the AUs are estimated by applying dimensionality reduction to facial keypoint movements from a neutral frame through a proposed Full Face Model (FFM). FFM employs a two-level decomposition using advanced dimensionality reduction techniques such as dictionary learning (DL) and non-negative matrix factorization (NMF). These techniques enhance the interpretability of AUs by introducing constraints such as sparsity and positivity to the encoding matrix. Results show that DFECS AUs estimated from the DISFA dataset can account for an average variance of up to 91.29 percent in test datasets (CK+ and BP4D-Spontaneous) and also surpass the variance explained by keypoint-based equivalents of FACS AUs in these datasets. Additionally, 87.5 percent of DFECS AUs are interpretable, i.e., align with the direction of facial muscle movements. In summary, advancements in automated facial coding systems can accelerate facial expression analysis across diverse fields such as security, healthcare, and entertainment. These advancements offer numerous benefits, including enhanced detection of abnormal behavior, improved pain analysis in healthcare settings, and enriched emotion-driven interactions. To facilitate further research, the code repository of DFECS has been made publicly accessible.
ReBotNet: Fast Real-time Video Enhancement
Mar 23, 2023Most video restoration networks are slow, have high computational load, and can't be used for real-time video enhancement. In this work, we design an efficient and fast framework to perform real-time video enhancement for practical use-cases like live video calls and video streams. Our proposed method, called Recurrent Bottleneck Mixer Network (ReBotNet), employs a dual-branch framework. The first branch learns spatio-temporal features by tokenizing the input frames along the spatial and temporal dimensions using a ConvNext-based encoder and processing these abstract tokens using a bottleneck mixer. To further improve temporal consistency, the second branch employs a mixer directly on tokens extracted from individual frames. A common decoder then merges the features form the two branches to predict the enhanced frame. In addition, we propose a recurrent training approach where the last frame's prediction is leveraged to efficiently enhance the current frame while improving temporal consistency. To evaluate our method, we curate two new datasets that emulate real-world video call and streaming scenarios, and show extensive results on multiple datasets where ReBotNet outperforms existing approaches with lower computations, reduced memory requirements, and faster inference time.
A View Independent Classification Framework for Yoga Postures
Jun 27, 2022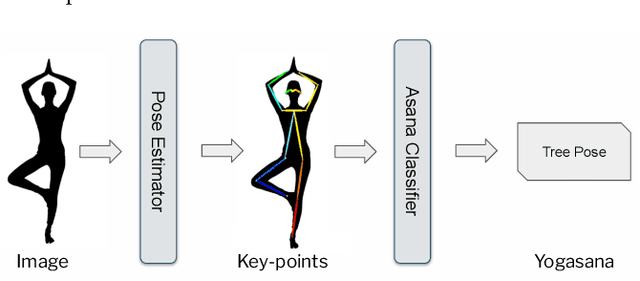
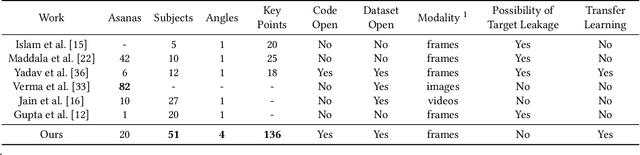
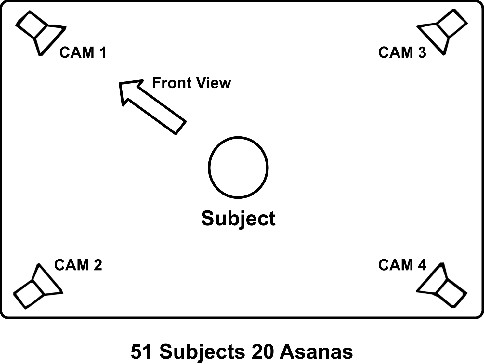
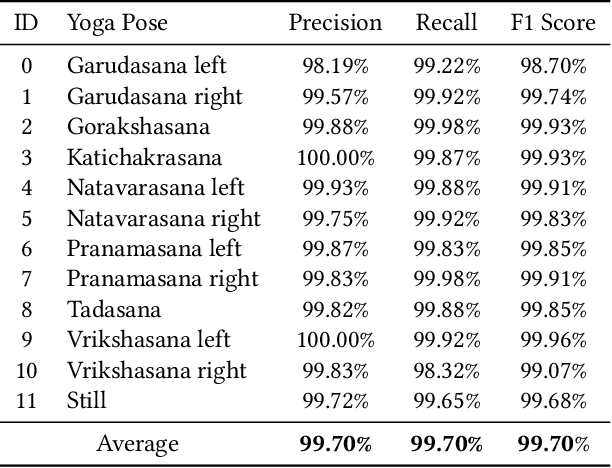
Yoga is a globally acclaimed and widely recommended practice for a healthy living. Maintaining correct posture while performing a Yogasana is of utmost importance. In this work, we employ transfer learning from Human Pose Estimation models for extracting 136 key-points spread all over the body to train a Random Forest classifier which is used for estimation of the Yogasanas. The results are evaluated on an in-house collected extensive yoga video database of 51 subjects recorded from 4 different camera angles. We propose a 3 step scheme for evaluating the generalizability of a Yoga classifier by testing it on 1) unseen frames, 2) unseen subjects, and 3) unseen camera angles. We argue that for most of the applications, validation accuracies on unseen subjects and unseen camera angles would be most important. We empirically analyze over three public datasets, the advantage of transfer learning and the possibilities of target leakage. We further demonstrate that the classification accuracies critically depend on the cross validation method employed and can often be misleading. To promote further research, we have made key-points dataset and code publicly available.
Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image
Oct 12, 2021
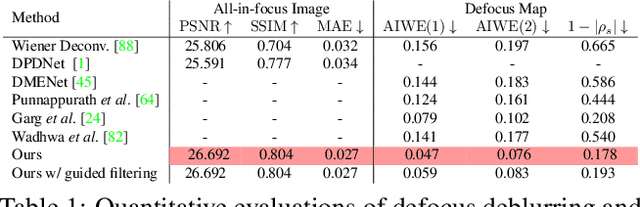
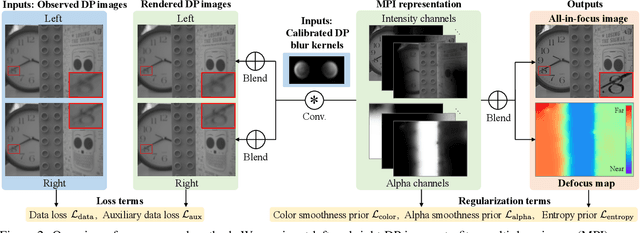
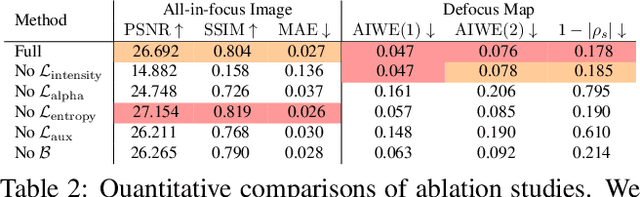
We present a method that takes as input a single dual-pixel image, and simultaneously estimates the image's defocus map -- the amount of defocus blur at each pixel -- and recovers an all-in-focus image. Our method is inspired from recent works that leverage the dual-pixel sensors available in many consumer cameras to assist with autofocus, and use them for recovery of defocus maps or all-in-focus images. These prior works have solved the two recovery problems independently of each other, and often require large labeled datasets for supervised training. By contrast, we show that it is beneficial to treat these two closely-connected problems simultaneously. To this end, we set up an optimization problem that, by carefully modeling the optics of dual-pixel images, jointly solves both problems. We use data captured with a consumer smartphone camera to demonstrate that, after a one-time calibration step, our approach improves upon prior works for both defocus map estimation and blur removal, despite being entirely unsupervised.
Zoom-to-Inpaint: Image Inpainting with High Frequency Details
Dec 17, 2020

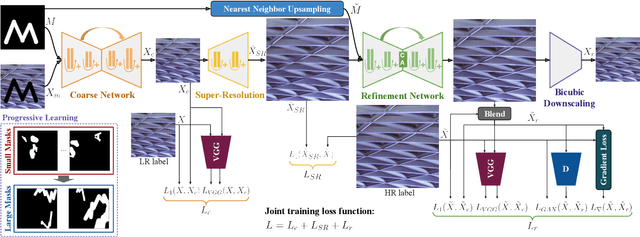
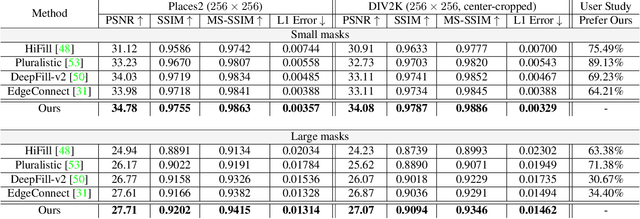
Although deep learning has enabled a huge leap forward in image inpainting, current methods are often unable to synthesize realistic high-frequency details. In this paper, we propose applying super resolution to coarsely reconstructed outputs, refining them at high resolution, and then downscaling the output to the original resolution. By introducing high-resolution images to the refinement network, our framework is able to reconstruct finer details that are usually smoothed out due to spectral bias - the tendency of neural networks to reconstruct low frequencies better than high frequencies. To assist training the refinement network on large upscaled holes, we propose a progressive learning technique in which the size of the missing regions increases as training progresses. Our zoom-in, refine and zoom-out strategy, combined with high-resolution supervision and progressive learning, constitutes a framework-agnostic approach for enhancing high-frequency details that can be applied to other inpainting methods. We provide qualitative and quantitative evaluations along with an ablation analysis to show the effectiveness of our approach, which outperforms state-of-the-art inpainting methods.
Single-Image Lens Flare Removal
Nov 26, 2020
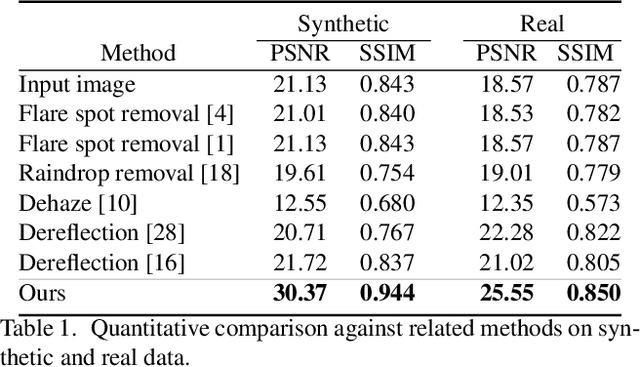
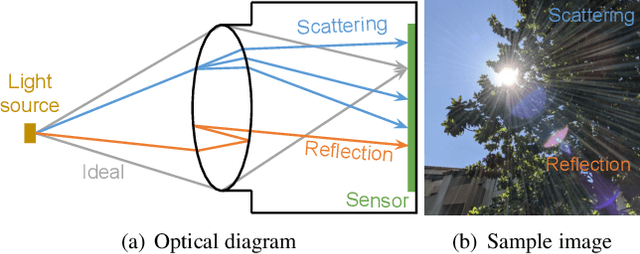
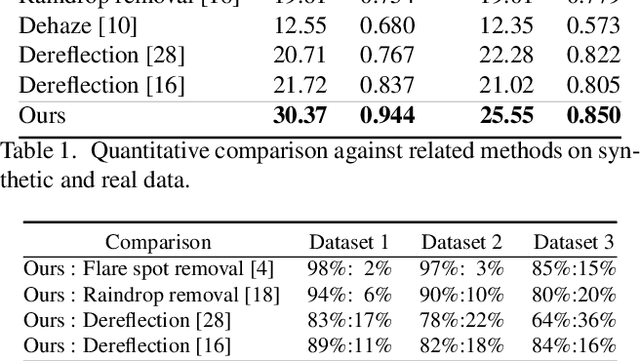
Lens flare is a common artifact in photographs occurring when the camera is pointed at a strong light source. It is caused by either multiple reflections within the lens or scattering due to scratches or dust on the lens, and may appear in a wide variety of patterns: halos, streaks, color bleeding, haze, etc. The diversity in its appearance makes flare removal extremely challenging. Existing software methods make strong assumptions about the artifacts' geometry or brightness, and thus only handle a small subset of flares. We take a principled approach to explicitly model the optical causes of flare, which leads to a novel semi-synthetic pipeline for generating flare-corrupted images from both empirical and wave-optics-simulated lens flares. Using the semi-synthetic data generated by this pipeline, we build a neural network to remove lens flare. Experiments show that our model generalizes well to real lens flares captured by different devices, and outperforms start-of-the-art methods by 3dB in PSNR.
Learned Dual-View Reflection Removal
Oct 01, 2020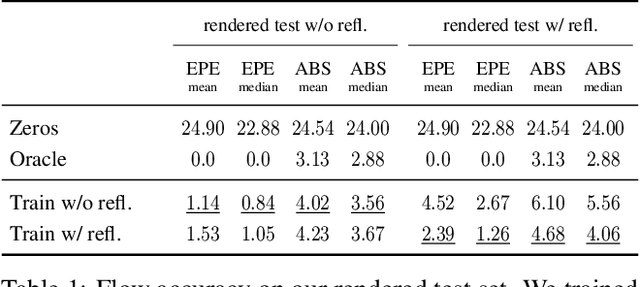

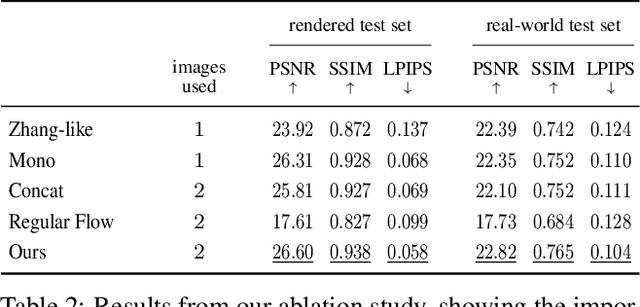

Traditional reflection removal algorithms either use a single image as input, which suffers from intrinsic ambiguities, or use multiple images from a moving camera, which is inconvenient for users. We instead propose a learning-based dereflection algorithm that uses stereo images as input. This is an effective trade-off between the two extremes: the parallax between two views provides cues to remove reflections, and two views are easy to capture due to the adoption of stereo cameras in smartphones. Our model consists of a learning-based reflection-invariant flow model for dual-view registration, and a learned synthesis model for combining aligned image pairs. Because no dataset for dual-view reflection removal exists, we render a synthetic dataset of dual-views with and without reflections for use in training. Our evaluation on an additional real-world dataset of stereo pairs shows that our algorithm outperforms existing single-image and multi-image dereflection approaches.