 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSSDF: Modality-Shared Self-supervised Distillation for High-Resolution Multi-modal Remote Sensing Image Learning
Jun 11, 2025



Remote sensing image interpretation plays a critical role in environmental monitoring, urban planning, and disaster assessment. However, acquiring high-quality labeled data is often costly and time-consuming. To address this challenge, we proposes a multi-modal self-supervised learning framework that leverages high-resolution RGB images, multi-spectral data, and digital surface models (DSM) for pre-training. By designing an information-aware adaptive masking strategy, cross-modal masking mechanism, and multi-task self-supervised objectives, the framework effectively captures both the correlations across different modalities and the unique feature structures within each modality. We evaluated the proposed method on multiple downstream tasks, covering typical remote sensing applications such as scene classification, semantic segmentation, change detection, object detection, and depth estimation. Experiments are conducted on 15 remote sensing datasets, encompassing 26 tasks. The results demonstrate that the proposed method outperforms existing pretraining approaches in most tasks. Specifically, on the Potsdam and Vaihingen semantic segmentation tasks, our method achieved mIoU scores of 78.30\% and 76.50\%, with only 50\% train-set. For the US3D depth estimation task, the RMSE error is reduced to 0.182, and for the binary change detection task in SECOND dataset, our method achieved mIoU scores of 47.51\%, surpassing the second CS-MAE by 3 percentage points. Our pretrain code, checkpoints, and HR-Pairs dataset can be found in https://github.com/CVEO/MSSDF.
On the Thinking-Language Modeling Gap in Large Language Models
May 19, 2025



System 2 reasoning is one of the defining characteristics of intelligence, which requires slow and logical thinking. Human conducts System 2 reasoning via the language of thoughts that organizes the reasoning process as a causal sequence of mental language, or thoughts. Recently, it has been observed that System 2 reasoning can be elicited from Large Language Models (LLMs) pre-trained on large-scale natural languages. However, in this work, we show that there is a significant gap between the modeling of languages and thoughts. As language is primarily a tool for humans to share knowledge and thinking, modeling human language can easily absorb language biases into LLMs deviated from the chain of thoughts in minds. Furthermore, we show that the biases will mislead the eliciting of "thoughts" in LLMs to focus only on a biased part of the premise. To this end, we propose a new prompt technique termed Language-of-Thoughts (LoT) to demonstrate and alleviate this gap. Instead of directly eliciting the chain of thoughts from partial information, LoT instructs LLMs to adjust the order and token used for the expressions of all the relevant information. We show that the simple strategy significantly reduces the language modeling biases in LLMs and improves the performance of LLMs across a variety of reasoning tasks.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Towards Cross-Modality Modeling for Time Series Analytics: A Survey in the LLM Era
May 05, 2025The proliferation of edge devices has generated an unprecedented volume of time series data across different domains, motivating various well-customized methods. Recently, Large Language Models (LLMs) have emerged as a new paradigm for time series analytics by leveraging the shared sequential nature of textual data and time series. However, a fundamental cross-modality gap between time series and LLMs exists, as LLMs are pre-trained on textual corpora and are not inherently optimized for time series. Many recent proposals are designed to address this issue. In this survey, we provide an up-to-date overview of LLMs-based cross-modality modeling for time series analytics. We first introduce a taxonomy that classifies existing approaches into four groups based on the type of textual data employed for time series modeling. We then summarize key cross-modality strategies, e.g., alignment and fusion, and discuss their applications across a range of downstream tasks. Furthermore, we conduct experiments on multimodal datasets from different application domains to investigate effective combinations of textual data and cross-modality strategies for enhancing time series analytics. Finally, we suggest several promising directions for future research. This survey is designed for a range of professionals, researchers, and practitioners interested in LLM-based time series modeling.
Efficient Multivariate Time Series Forecasting via Calibrated Language Models with Privileged Knowledge Distillation
May 04, 2025Multivariate time series forecasting (MTSF) endeavors to predict future observations given historical data, playing a crucial role in time series data management systems. With advancements in large language models (LLMs), recent studies employ textual prompt tuning to infuse the knowledge of LLMs into MTSF. However, the deployment of LLMs often suffers from low efficiency during the inference phase. To address this problem, we introduce TimeKD, an efficient MTSF framework that leverages the calibrated language models and privileged knowledge distillation. TimeKD aims to generate high-quality future representations from the proposed cross-modality teacher model and cultivate an effective student model. The cross-modality teacher model adopts calibrated language models (CLMs) with ground truth prompts, motivated by the paradigm of Learning Under Privileged Information (LUPI). In addition, we design a subtractive cross attention (SCA) mechanism to refine these representations. To cultivate an effective student model, we propose an innovative privileged knowledge distillation (PKD) mechanism including correlation and feature distillation. PKD enables the student to replicate the teacher's behavior while minimizing their output discrepancy. Extensive experiments on real data offer insight into the effectiveness, efficiency, and scalability of the proposed TimeKD.
LangCoop: Collaborative Driving with Language
Apr 21, 2025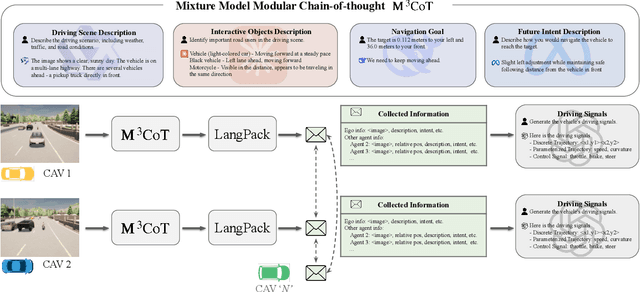

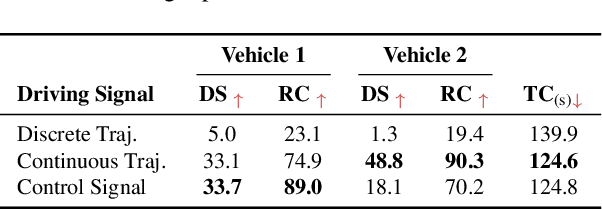
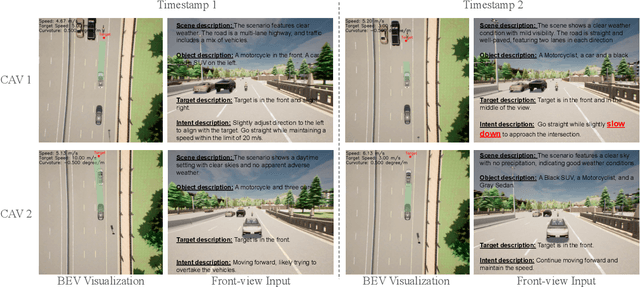
Multi-agent collaboration holds great promise for enhancing the safety, reliability, and mobility of autonomous driving systems by enabling information sharing among multiple connected agents. However, existing multi-agent communication approaches are hindered by limitations of existing communication media, including high bandwidth demands, agent heterogeneity, and information loss. To address these challenges, we introduce LangCoop, a new paradigm for collaborative autonomous driving that leverages natural language as a compact yet expressive medium for inter-agent communication. LangCoop features two key innovations: Mixture Model Modular Chain-of-thought (M$^3$CoT) for structured zero-shot vision-language reasoning and Natural Language Information Packaging (LangPack) for efficiently packaging information into concise, language-based messages. Through extensive experiments conducted in the CARLA simulations, we demonstrate that LangCoop achieves a remarkable 96\% reduction in communication bandwidth (< 2KB per message) compared to image-based communication, while maintaining competitive driving performance in the closed-loop evaluation. Our project page and code are at https://xiangbogaobarry.github.io/LangCoop/.
Can Large Language Models Help Experimental Design for Causal Discovery?
Mar 04, 2025



Designing proper experiments and selecting optimal intervention targets is a longstanding problem in scientific or causal discovery. Identifying the underlying causal structure from observational data alone is inherently difficult. Obtaining interventional data, on the other hand, is crucial to causal discovery, yet it is usually expensive and time-consuming to gather sufficient interventional data to facilitate causal discovery. Previous approaches commonly utilize uncertainty or gradient signals to determine the intervention targets. However, numerical-based approaches may yield suboptimal results due to the inaccurate estimation of the guiding signals at the beginning when with limited interventional data. In this work, we investigate a different approach, whether we can leverage Large Language Models (LLMs) to assist with the intervention targeting in causal discovery by making use of the rich world knowledge about the experimental design in LLMs. Specifically, we present Large Language Model Guided Intervention Targeting (LeGIT) -- a robust framework that effectively incorporates LLMs to augment existing numerical approaches for the intervention targeting in causal discovery. Across 4 realistic benchmark scales, LeGIT demonstrates significant improvements and robustness over existing methods and even surpasses humans, which demonstrates the usefulness of LLMs in assisting with experimental design for scientific discovery.
SenseRAG: Constructing Environmental Knowledge Bases with Proactive Querying for LLM-Based Autonomous Driving
Jan 08, 2025



This study addresses the critical need for enhanced situational awareness in autonomous driving (AD) by leveraging the contextual reasoning capabilities of large language models (LLMs). Unlike traditional perception systems that rely on rigid, label-based annotations, it integrates real-time, multimodal sensor data into a unified, LLMs-readable knowledge base, enabling LLMs to dynamically understand and respond to complex driving environments. To overcome the inherent latency and modality limitations of LLMs, a proactive Retrieval-Augmented Generation (RAG) is designed for AD, combined with a chain-of-thought prompting mechanism, ensuring rapid and context-rich understanding. Experimental results using real-world Vehicle-to-everything (V2X) datasets demonstrate significant improvements in perception and prediction performance, highlighting the potential of this framework to enhance safety, adaptability, and decision-making in next-generation AD systems.
A LoRA is Worth a Thousand Pictures
Dec 16, 2024Recent advances in diffusion models and parameter-efficient fine-tuning (PEFT) have made text-to-image generation and customization widely accessible, with Low Rank Adaptation (LoRA) able to replicate an artist's style or subject using minimal data and computation. In this paper, we examine the relationship between LoRA weights and artistic styles, demonstrating that LoRA weights alone can serve as an effective descriptor of style, without the need for additional image generation or knowledge of the original training set. Our findings show that LoRA weights yield better performance in clustering of artistic styles compared to traditional pre-trained features, such as CLIP and DINO, with strong structural similarities between LoRA-based and conventional image-based embeddings observed both qualitatively and quantitatively. We identify various retrieval scenarios for the growing collection of customized models and show that our approach enables more accurate retrieval in real-world settings where knowledge of the training images is unavailable and additional generation is required. We conclude with a discussion on potential future applications, such as zero-shot LoRA fine-tuning and model attribution.
A Watermark for Order-Agnostic Language Models
Oct 17, 2024



Statistical watermarking techniques are well-established for sequentially decoded language models (LMs). However, these techniques cannot be directly applied to order-agnostic LMs, as the tokens in order-agnostic LMs are not generated sequentially. In this work, we introduce Pattern-mark, a pattern-based watermarking framework specifically designed for order-agnostic LMs. We develop a Markov-chain-based watermark generator that produces watermark key sequences with high-frequency key patterns. Correspondingly, we propose a statistical pattern-based detection algorithm that recovers the key sequence during detection and conducts statistical tests based on the count of high-frequency patterns. Our extensive evaluations on order-agnostic LMs, such as ProteinMPNN and CMLM, demonstrate Pattern-mark's enhanced detection efficiency, generation quality, and robustness, positioning it as a superior watermarking technique for order-agnostic LMs.